
動画生成のための3次元顔変形モデル

楊 興超氏(株式会社サイバーエージェントAI Lab)
www.cyberagent.co.jp/techinfo/labo/ai/
VCショート発表賞を受賞した論文「動画生成のための3次元顔変形モデル」は、サイバーエージェントAI Labの楊 興超氏と山口 光太氏、南カリフォルニア大学の齋藤 隼介氏による共同研究の成果である。楊氏らは広告クリエイティブ制作支援となる技術開発に取り組んでおり、この研究を通じて、ある特定人物が出演する映像を自在に合成できるような映像制作環境の実現を目指している。つまり、多様な収録パターンをそれぞれ個別に撮影することなく、特定人物の複数の表情パターンを一回撮影するだけで、あとは任意の表情や動きの事後的な合成を可能とするための技術を研究している。本受賞論文ではその1つの成果として、特定人物の顔の向きや表情を編集可能な3次元顔変形モデル(3D Morphable Model、以降3DMM)を構築したうえで、別の演者の表情変化に追従するような顔映像を合成する技術が発表された。

この研究背景として、広告のように大量の動画制作が求められる現場において、実在人物の映像撮影と編集に費やされるコストの大きさが挙げられた。一般的に撮影パターンの数や尺の長さが大きくなるほど、最終的な映像を選るまでに要する時間的、金銭的コストは増加する。特に著名人を起用した動画制作において、再撮影を要するほどの修正が生じた場合には深刻なコスト増加を招く。そこで揚氏らは、著名人などの特定人物が登場する映像制作を容易に行うための手段として、撮影されたデータを用いて任意の表情変化を事後合成できる技術の確立を目指している。特に、複数の被写体人物が示す様々な3D顔表情スキャンデータを用いて構築される、3DMMと呼ばれる統計的モデルについて研究している。この技術を応用することで、様々な見た目のデジタルアバターを対象として、任意の感情や発話内容に対応する3D顔形状を合成できることから、国内外で近年目覚ましく発展している。その中でも本論文では、日本人女性を対象として構築された3DMMを映像制作に応用した結果について報告している。
頭部や顔を扱う動画の制作や編集を目的とした手法は数多くの先行研究例がある。例えば、3DMMを用いた顔入れ替え(Face Replacement)と表情転写に基づいた顔再現(Face Reenactment)が代表例として挙げられる(文献「3D Morphable Face Models -- Past, Present and Future」)。3DMM研究のためのデータセットとして、これまでの研究では主に欧米系の人物を中心に多様な性別や年齢層のデータを集めたBasel Face Model(文献「Morphable Face Models - An Open Framework」)がよく利用されている。しかし、精確な3DMMを構築するためには、データセットに含まれる人種、性別、年齢の分布が、撮影対象人物に近いことが望ましい。極端な例を挙げれば、老齢の欧米人男性のみが含まれるデータを用いても、若年の日本人女性の顔表情を再現するのは極めて困難である。そこで楊氏らは日本国内における活用を念頭に、日本人女性に特化したデータセットの構築と、それらを用いた3DMMの構築に取り組んでいる。
楊氏らが提案する 3DMM構築の処理手順は、図に示すとおり、顔表情の3Dスキャンデータ収録、顔以外の領域のトリミング、ランドマーク推定、顔の向きや大きさの正規化(レジストレーション)、3DMM の生成、そして平均顔からブレンドシェイプの追加という 6ステップで構成されている。
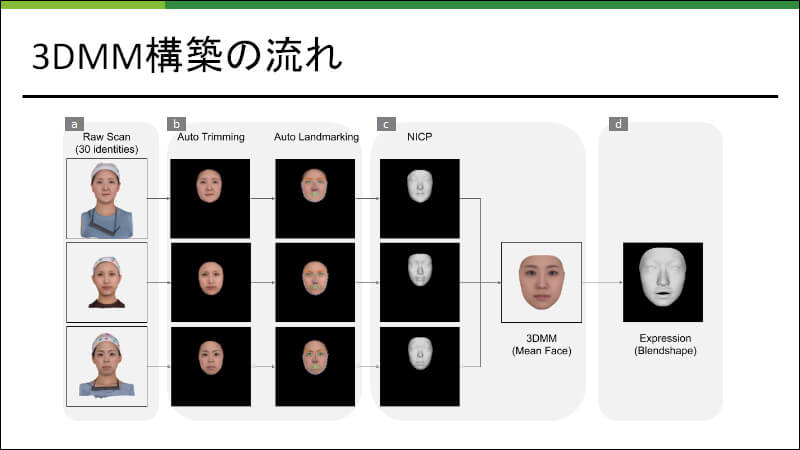
実験データとしては、20代から40代の日本人女性30人を対象に、無表情の頭部3D形状スキャンデータを収集している。マルチビュー3次元復元スキャンシステムを利用し、異なる視点から撮影された複数枚の頭部画像を用いて、各人物の3次元メッシュデータを構成する。このとき、図に示すように、被写体となる人物の身長や姿勢に応じてデータの位置や向きが異なり、またメッシュのトポロジーは不揃いになるため、以降に述べる正規化処理を施す。
まず、スキャンデータから顔領域の自動抽出を行う。ここでは図に示すように、3次元空間上顔モデルの正面と側面に置かれたバーチャルカメラを用いて2次元画像をレンダリングする。次に、レンダリングされた顔画像に対して二次元領域分割(文献「Bisenet: Bilateral Segmentation Network for Real-Time Semantic Segmentation」)を施した後、顔以外の耳や髪、帽子などと判定された領域を3次元空間に逆投影し、対応するポリゴンを除去する。そして、穴埋め処理を施すことでスキャンデータの欠損部分を補う。
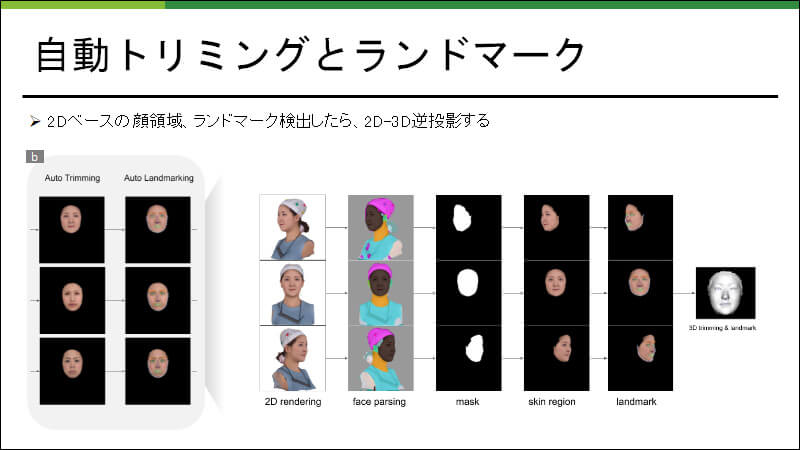
続いて、自動トリミングと類似した処理手順を通じて、スキャンデータ上の顔ランドマーク位置を推定する。図に示すように、まず仮想カメラからみたレンダリング画像上で 68個の顔ランドマーク位置を推定する(文献「How Far Are We from Solving the 2d & 3d Face Alignment Problem?(and a Dataset of 230,000 3d Facial Landmarks)」)。そして、それらを 3次元スキャンデータ上に逆投影することで3次元ランドマーク位置を推定する。
そして、複数のメッシュデータの位置合わせと形状合わせを行う。楊氏らは、手動でトリミングしたBasel Face Modelの平均顔をテンプレートメッシュとして利用する方法を採っている。まず、3次元ランドマーク位置を参照し、顔モデルをテンプレートメッシュの向きと位置に合わせる。次に、顔モデルの形状に合致するようにテンプレートメッシュを自動変形する。この処理を全てのスキャンデータに対して施すことで、トポロジーが共通な3次元メッシュデータが得られる。

最後に、全ての顔メッシュの頂点座標を対象として主成分分析を施し、3DMMの形状と色の変化パラメータを推定することで、3DMMを構築する。そして全ての顔メッシュの中間形状を平均顔として算出し、その平均顔をベースとすることで図に示すような130 パターンの表情ブレンドシェイプを作成する。これらには口、鼻に関する表情が90 パターン、目に関する表情が40パターン含まれる。なお、推定された3DMMパラメータは、動画の表情生成や表情転写のためにも利用される。

3DMMを用いて生成される顔の品質を評価するため、いくつかの実験結果が示された。まず、図に示すように、日本人女性3DMMを用いて生成される顔形状の例が示された。これらは3DMMパラメータを様々に変化させることで合成された表情であるが、いずれもデータセットに含まれる日本人女性の特徴が反映された自然な結果が得られている。
次に、日本人女性の無表情顔画像を入力として、その表情に最も類似した3次元顔形状を推定する実験結果が示された。200人の欧米系人物を被写体とするBasel Face Modelに対して、提案法のほうが良好な映像品質を与えることが確認されている。これは、Basel Face Model を構築した顔データベースは男性のモデルも含まれているため、日本人女性の写真に対して復元しようとしても、欧米人男性の特徴が現れてしまうためである。一方、日本人女性3DMMを用いて3次元復元する場合には、人種や年齢層が近い人物のデータを参照することになるため、高品質な結果が得られやすいことが示された。

次に、表情転写の実験結果が示された。この実験では、3DMMに含まれる被写体人物の表情を、別の役者の表情変化によって操作している。まず、役者の2次元入力画像を近似するような3DMMパラメータを推定する。次に、顔形状の個人性および照明条件に対応する3DMMパラメータを、出演者の数値によって置き換える。その結果、出演者の見た目を保ちながら、役者の表情と頭部の運動が転写された3次元顔形状を合成している。さらに、役者の動画映像から検知される目線に応じて3DMMの目線を調整することで、あたかも役者の挙動や表情を出演者が模したような新しい映像が生成されていた。


楊氏らが提案する3DMMのもう1つの特長として、構築した3DMM の表情のパラメータがブレンドシェイプとして表されている点が挙げられる。つまり、3DMMパラメータを直接的、間接的に調整することでアニメーションを作成することもできる。さらに、自動生成した動画の表情にアーティストの編集を加えることで、効率良く品質な動画生成することも可能であろう。このように、さまざまな応用が期待される将来性の高い技術であるが、現時点では基礎研究の段階に留まっているため、今後はさらに容易に利用できるシステムの開発など、現場での環境整備を進める予定とのことである。
企業研究者による応用論文
ここまで紹介した2本の受賞論文以外にも、論文セッションでは多様な研究成果が発表されたが、本稿では特に、シンポジウム招待枠として発表された応用論文について簡潔に紹介したい。VC2020では、デジタル・フロンティアの後藤浩之氏らによる「Hair for Digital Human: 不気味の谷を越えるために」、奈良先端科学技術大学院大学の品川政太朗氏らによる「セマンティックセグメンテーションに基づくアニメ作品の自動彩色」、華為技術日本の岩本尚也氏らによる「3D LIVE MAKER: 好きなキャラクタに命を吹き込むまで」の3件の応用論文が、VC2020委員会からの招待として執筆・発表された。各社における製品開発における学術研究成果の応用をテーマとして、例えばインハウスツールや技術デモの開発において参照した研究例や、それらの実装結果と検証結果、実用化に向けて施された現場での工夫などがまとめられた論文である。現場での要求に即した学術研究成果を調査、選定する過程が、実際の採用に至らなかった研究例も含めて紹介されるとともに、実用にたる品質や性能を得るための拡張方法など、実践的な話題がまとめられていた。それらの中では、学術研究成果が現場での実用化に至らない一因として、製品開発で求められる品質水準の高さやワークフローとの兼ね合いがあることなどが示唆されていた。そうした制作者や開発者としては当たり前のことながら、大学などの研究機関に所属する研究者にとっては肌感覚としての理解が難しい内容も取り上げられていた点が特徴的であった。
VC2021に向けて
Visual Computingは今後も学術論文発表をメインセッションに据え、学術研究の場から広く情報発信する場として開催される予定である。本年のVC2021は、本稿の執筆時点では、9月下旬開催を念頭に計画されている。研究者や学生のみならず、映像制作に携わる多くの方、とくに技術者・開発者にとっても有意義なイベントになるよう、各種企画やスケジュール策定について検討されている。ぜひ、プロやアマ、デザイナーや技術者などの区分を問わず、コンピュータグラフィックスに関心がある多くの方に参加いただき、その生の声を研究者や学生に遠慮なく投げかけていただきたい。そうした契機を通じた交流の促進、より一層スムーズな産学連携のために、Visual Computingをはじめとする学会の場も活用していただければ幸いである。



















