<2>メモリアーキテクチャを刷新させたハイエンドGPU、VEGA(開発コードネーム)を発表
AMDは2016年中頃に開発コードネーム「Polaris」こと、RADEON RX400シリーズを発表し、リリース。しかし、RADEON RX400シリーズはいわゆるコストパフォーマンス重視のGPUで、ハイエンドモデルは後に登場する開発コードネーム「VEGA」になることが確実視されていた。


VEGAを発表するRaja Koduri/ラジャ・コドゥリ氏(Senior Vice President and Chief Architect, Radeon Technologies Group, AMD)
そして年が開けての1月5日。AMDは、この開発コードネーム「VEGA」の存在を正式に認め、このGPUに搭載されている注目すべき技術ポイントを4つ発表した。しかし、AMD製GPUの製品シリーズ名であるRADEONとしての型式番は明かさず、また、内包されるシェーダプロセッサ数も非公開とし、事実上の予告的な発表となっていた。4つのポイントのうち1つは、新プログラマブルシェーダとして「Primitive Shader」(プリミティヴシェーダ)が新設されるということだ。これはこれまで存在した「頂点シェーダ」と「ジオメトリシェーダ」、そしてGPGPU的な処理を行うComputeShaderを統合したようなものになるという。
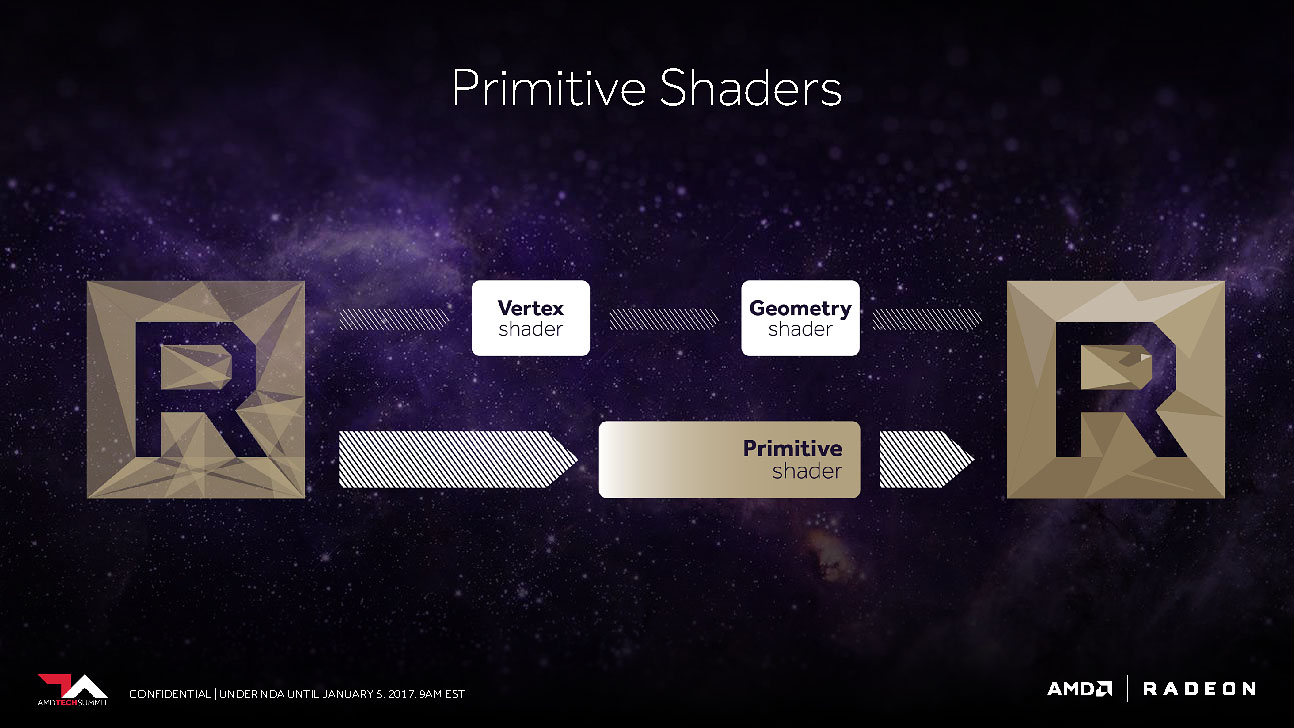
新プログラマブルシェーダ「Primitive Shader」の新設。基本的には頂点シェーダとジオメトリシェーダ、ComputeShaderを統合させたようなものだが、現状でDirectX,OpenGLでもサポートされていない新シェーダである
2つめは「Intelligent Workgroup Distributor」(以下、IWD)と呼ばれるもので、具体的には頂点単位のジオメトリタスクを高効率で実行できるよう制御する仕組みとなる。
3つめは、半精度浮動小数点(FP16)や8ビット整数(INT8)を、シェーダプロセッサがPacked実行できるようになった点だ。Packed実行とは、1つのレジスタに複数のデータを入れ込んで、演算器で一括実行させる仕組み。もともとRADEON HD 7000系の「Graphics Core Next」(以下、GCN)アーキテクチャでは、単精度浮動小数点(FP32)を演算の基本単位としており、処理対象のデータがFP16でもINT8でも演算時間はFP32と同じになっていた。これがVEGAでは、FP16であれぱ、32ビットレジスタに2つ、INT8であれば4つ入れ込んで、これらを一遍に演算して結果を返す仕組み(これがPacked実行)にしたということだ。

VEGAのシェーダプロセッサはPacked実行に対応する
4つ目は、ピクセルシェーダ側の実行効率の改善だ。具体的には、後段で別のポリゴンの描画によって上書きされてしまうピクセルの早期破棄、ピクセルを実際にメモリへの書き出す際のキャッシュメモリ管理の最適化などがこれに当たる。
これら4つの進化ポイントとは別に、VEGAではメモリアーキテクチャが一新されたこともホットトピックである。VEGAでは、グラフィックスボードの基板側ではなく、GPUチップ上に「HBM2」(High Bandwidth Memory2)と呼ばれる高速メモリが実装される。HBMとはメモリチップを高層ビルのように積み上げて(=スタックさせて)配置し、それを「TSV」(Through Silicon Via:シリコン貫通ビア)技術によって串刺しに貫通させて配線するメモリ実装技術で、省スペースかつ高帯域なメモリ性能を発揮できる新世代のメモリ技術である。
HBM2はこのHBMの2世代目のものになる。「HBM2を搭載したGPU」というだけでもユニークだが、それ以上に、業界を驚かせたのは、このHBM2が、グラフィックスメモリとしてではなく、巨大なキャッシュメモリとして採用されているという点だ。つまり、VEGAでは、レンダリングの際に本当に高速性が必要なデータだけをキャッシュメモリとしてのHBM2に載せて、それほどでもないデータは、システムメインメモリや場合によってはハードディスクやSSDに退避してしまうような仕組みを採用したのだ。この発想はCPUではお馴染みの仮想メモリの仕組みと同じだ。つまり、VEGAでは、ついにGPUにも仮想メモリの概念を導入してきたというわけだ。

オンダイ搭載されるHBM2はキャッシュメモリ扱いに。VEGAのメモリアーキテクチャでは、CPU並の仮想メモリアーキテクチャが本格導入されることになる
AMD側の発表では、VEGAの有効仮想アドレスは49ビットだそうで、この仕組みで利用できる仮想メモリ空間は512TB(テラバイト)となる。ちなみに、64ビット版Windows 10がサポートする仮想アドレス空間は48ビットで256TB(ユーザー領域とシステム領域の総和)のため、当面、この仕組みで実用上の支障が出ることはない。
これまでHBM2の容量自体は非公開とされたが、HBM2チップ自体の現状仕様から推察すると少なくて4GB、多くて8GBになると見られる。となると、アーキテクチャ上の動作は大部変わることになるが、GPUハードウェア自身が行う実作業/データのやりとりの実体はそれほど従来GPUと大差はないと言える。
しかし、こうした「完全なる仮想アドレスの仕組み」の導入は、「CPUとGPUが共通のメモリ空間にアクセスしつつ、演算処理も協調して行っていく」ような近代コンピューティングパラダイムにおいては重要視されているため、業界的にはこのAMDのメモリアーキテクチャ刷新に対しては概ね賛同の声が多いようだ。