オープンソース×ローカル環境で挑むAI動画制作 CGクリエイターとAIの共創実録

モーショングラフィックスやCGアニメーション制作を手がけるマウンテンスタジオ。
After Effects、Blender、Cinema4Dなどを使用するクリエイターであり、同社の代表・宮本清春氏が新たに挑んだのは、オープンソースかつローカル環境によるAI動画制作だった。
なぜオープンソースなのか、なぜローカル環境にこだわるのか?
開発経験ゼロから試行錯誤の連続で得た知見、クリエイターが新たに挑む、AIとの共創現場を追った。
こだわりは「オープンソースかつローカル環境」
CGWORLD(以下、CGW):まずは、簡単な自己紹介と、普段の担当業務・制作環境を教えてください。
宮本清春(以下、宮本):マウンテンスタジオ代表の宮本清春です。業務では3DCGアニメーションや映像の制作を行っており、After Effects、Blender、Cinema 4Dなどをメインに使用しています。
作業マシンのCPUは8〜32コア構成、GPUにはNVIDIA GeForce RTX 3060や4060を使用しています。

マウンテンスタジオ
1995年にデザイン事務所として発足し、1997年に法人化。現在はモーショングラフィックスを主軸としつつ、ゲーム関係の映像や3DCGアニメーション制作、Webデザインなども手がける。現在のスタッフ数は7名。
ホームページ:mountain-st.com
X:@studio_mountain
CGW:普段はBlenderやCinema 4DといったDCCツールを使用されている中で、なぜローカル環境で動作するオープンソースのAI動画制作に取り組もうと考えたのでしょうか?
宮本:もともと数年前からオープンソースでのAI動画生成に注目していたのですが、自分自身での動画を生成することに興味を持ったのは、オンライン上で公開されている生成サービスをいくつか試してみたことがきっかけでした。ただ、思い通りの結果を得るには、何度もプロンプトを調整して生成を繰り返す必要があることを実感しました。
また、クラウドベースのサービスでは学習モデルにどのようなデータが使われているか不明瞭なので、著作権上のリスクも感じていました。
そこで、自分の手元の環境でAIモデルを動かし、制御しながら制作ができるローカル環境での取り組みに可能性を感じました。
商用利用可能な学習モデルを選んでローカルにインストールすることで、何度も生成できるうえ、生成結果のコントロールや権利面を自分で確認・管理しやすいと感じています。もちろん、AIモデルは利用規約が変更になる場合もあるので、ライセンス条件の確認は都度必要になりますが。
はじめてのオープンソース、はじめての開発環境

CGW:AIを使用しての制作を始めるにあたり戸惑ったことや、壁に感じたことは何でしたか?
宮本:私は「そもそも、オープンソースとは何か」というのを学ぶことから始めました。
ですが、はじめは正直まったく理解が追いつきませんでした。AI生成に用いるインターフェイス自体が複数あって、その上に世界中の開発者が作成した様々な拡張機能(スクリプトやノードなど)を追加していくという仕組みがあります。しかもツール自体、オリジナルのツールを開発した人のものと、それを誰かがカスタマイズした派生ツールがあり、さらにその中に、特定のソフトウェア上で動くもの、単体で動くものがあって……と非常に複雑で(笑)。
宮本:いざ、インストールとなっても、Pythonの黒いコマンド画面に何を打ち込めば良いのかさっぱりわかりませんでした。丁寧な解説サイトを渡り歩いて、書かれている通りにコマンドを入力し、ファイルをひとつずつ配置してようやく動かすことができた、というような状態です。
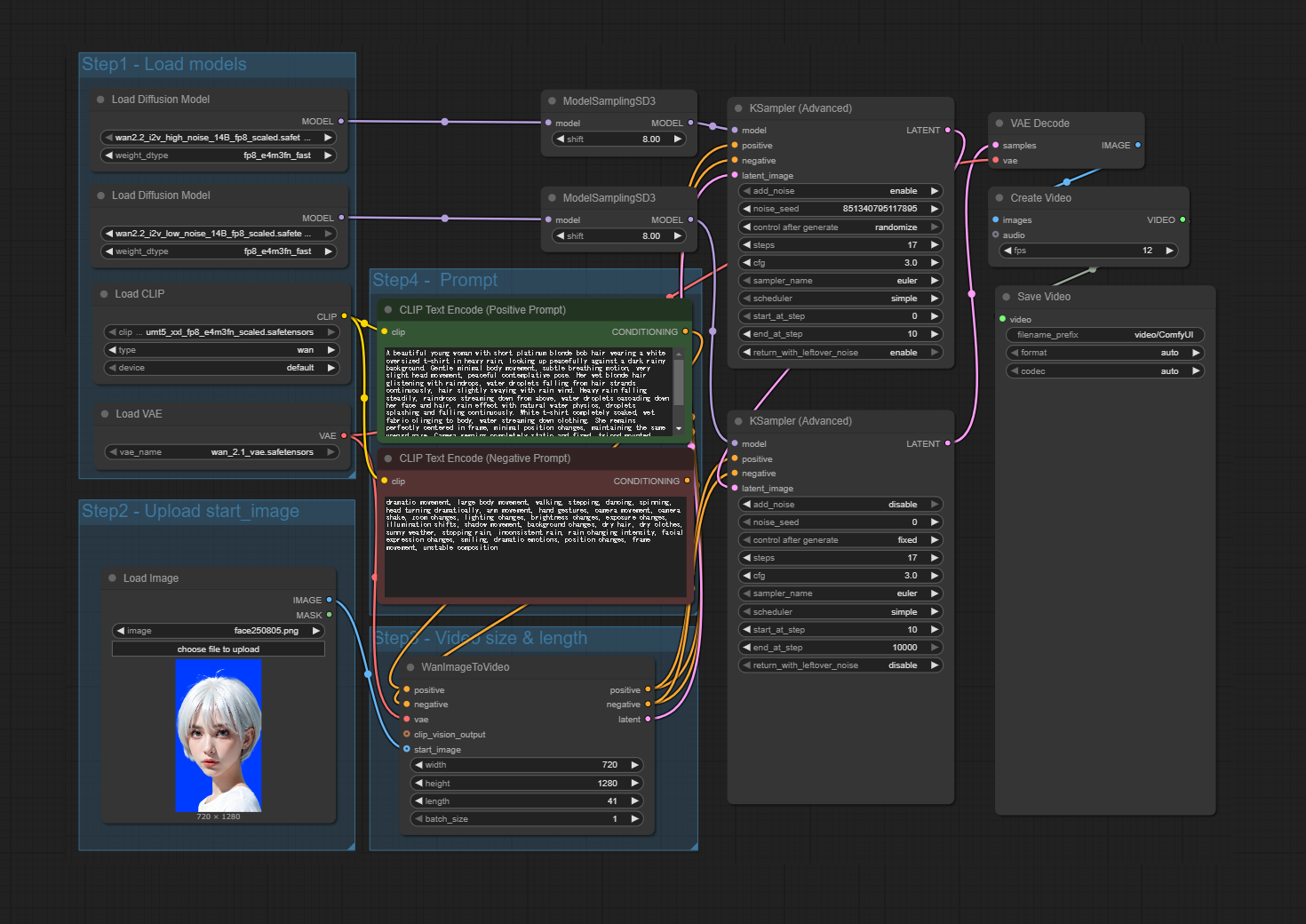
余談ですが、最近登場したComfyUI Desktop版によってインストールが劇的に楽になりました。
ノードベースで操作できるので、Blenderなどでノードになじみのある人はとっつきやすいと思います。あらかじめノードが組まれたテンプレートの種類も豊富なので、初学者にもおすすめです。
ただ、一部のツールでは解説サイトの手順通りにインストールしたのに動かないということもありました。そこで、対話型AIに「動かないんだけど、どうしたらいい?」と聞くと「これはこのモデル用ではありません」と言われてびっくり。
CGW:困った際には対話型のAIを使用されたりもしていたんですね。
宮本:そうですね。何も知らない自分にとって、今回の制作におけるもっとも重要なツールは対話型AIです。
先ほどのようなトラブルでも活用していますし、「苦節の末、やっとツールが動いたのに、出力結果が全然思うようにならない」なんてこともよくあるので、私は普段からClaude(Anthropicの対話型AI)にプロンプト生成を手伝ってもらっています。
入力するプロンプトもツールによって単語ベース・文章ベースと様々ですが、どちらの場合も、自分の要望を箇条書きでClaudeで伝えると、それを最適化したプロンプトに整えてくれるんです。生成結果も劇的に良くなります。そのうえで「もうちょっとこうしたいんだよね」と、自分の中のイメージや意図が形になるまで、何度もトライアンドエラーを繰り返していきます。
また、対話型AIの活用においては「一緒にやる」というのが重要だと感じています。
例えば、自分でも問題解決になりそうなサイトの記述を探してClaudeに「こんなサイトの記事を見つけたんだけど役に立つかな?」と聞くとその記事を元にClaudeが具体的な解決策を提示してくれます。
自分の中にあるイメージを具現化するための補助としても、問題解決においても、私ができることや得意なことと、AIの得意なことを連携していくことで、より良い結果に繋げられているように思います。
CGW:gitやpipを扱うような開発者向けの環境構築には苦労されたとのことでしたが、Pythonの勉強などはどう取り組まれましたか?
宮本:まだまだ理解が追いついておらず、今でも対話型AIに教えてもらっていることがたくさんあります(笑)。
はじめは、Pythonのことをあまりに知らないので、子供向けの絵本のような入門書を買って勉強しました。「2行のプログラムからスタートして、最後はディープラーニングのAIをつくる」というような内容でした。その中で知ったのが、「PyPI(Python Package Index)」というPythonの公式パッケージリポジトリの存在です。そこには世界中の開発者が共有してくれたコードがたくさん公開されていて、それを使うことで初学者でもAIを動かすことができるというのを知り、驚きました。
またGitHubのように、世界中の開発者がつくった様々なツールやコードを公開・共有する場所を実際に見てみて、「こうやって世界の技術の進化が支えているのだ」と痛感しました。ツールを開発して共有してくれる人、そしてそれを実際に活用してアウトプットする人、その双方がテクノロジーの進化の一翼を担っているのだと、とても感動しました。
CGW:ComfyUIなどの拡張機能は非常に多岐にわたると思いますが、どのように選定していますか?
宮本:最初はもうとにかく片っ端からインストールしてみました。ただ、気がついたらComfyUIのフォルダ容量が200GBくらいに膨れ上がっていて……(笑)。現在は用途に応じて整理しつつ、動画の生成では「Wan 2.2」と「Hunyuan」だけを使い続けています。
中でもWanについては、バージョン2.2へのアップデートで、画質や動きの自然さなどが一気に向上したと感じています。
また、SNS上では学習モデルをいちから自作しているクリエイターもいて、そうしたオリジナルモデルによる非常にアーティスティックな作品がたくさんシェアされています。学習モデルそのものをつくるのは簡単ではなさそうですが、LoRA(学習済みモデルに対して軽量な追加学習を行う手法)はいずれ挑戦してみたいと思っています。
CGW:GPUはどのようなものを使用していますか?
宮本:「オススメは?」と聞かれると、やはり最新のCPUと、大容量VRAMを搭載したハイエンドGPUを積んだマシンが理想的ということになってしまいます。
ただし、まずは試してみたいという段階では、古いPCに比較的手頃なGPUを載せ替えるという選択肢も十分にアリだと思っています。
例えば今回、
・32コアCPU+NVIDIA GeForce RTX 3090(VRAM 24GB)
・6コアCPU+NVIDIA GeForce RTX 3060(VRAM 12GB)
の2台でWan2.2による動画生成の処理速度を比べてみたんですが、私の環境では後者のモデルでも、前者の半分くらいのパフォーマンスは出ました。
あくまで個人環境での簡易的な比較ではありますが、VRAM容量が生成速度に与える影響は思った以上に大きいのかもしれません。
AIシンガー・ヤフミを通じて考える、「クリエイターとAI」
CGW:実際にAIを活用してつくられたAIシンガー・ヤフミについて教えてください。
宮本:ヤフミは音楽家・山口義史さんと共同でプロデュースしているAIシンガーです。私はビジュアル面を担当しており、MVの制作などを行っています。顔や雰囲気の一貫性に苦労しており、彼女の個性がぶれないよう、生成結果の微調整を何度も重ねて“ヤフミらしさ”をつくっています。

CGW:投稿されているMVは、どのような手順で作成されているのでしょうか?
宮本:まず、Photoshopでベースとなる静止画を作成します。次に、Stable Diffusion WebUI(AUTOMATIC1111版)であらかじめインストールしてある学習モデルを選択し、「Image to Image」機能(画像から画像を生成する機能)を使って、目指すイメージに近づくまで何度も生成を繰り返します。
その後、手作業で少し調整をしたら、今度はComfyUIのWan2.2モデルで「Image to Video」で動画を生成します。
そうして出力された動画をPNG連番に変換して、スケールアップ。
ちなみに自分はStable Diffusion WebUI(AUTOMATIC1111)の「Extras」タブで連番処理をしています。
画角が大きくなった動画を、After Effectsに取り込み、タイムワープ機能などを使って尺を適度に伸ばします。そしてさらにPremiere Proの「AI生成延長ツール」を繰り返し使用することで求める長さまで伸ばしています。
これで、1カットにつき数秒ずつのモーショングラフィックス用素材が完成します。
ただ、複数カットの中で、同じ顔を生成し続けるのが非常に難しいですね。

元画像の印象に近づけたいときには、Stable Diffusion WebUI(AUTOMATIC1111)やFluxを使い、主に「Denoising strength(変化の強さ)」の値を下げることで調整しています。
逆に、プロンプトに忠実な画像を生成したい場合は、「CFG Scale(プロンプトの強度)」を上げるようにしていて、今回のように同じ顔を保ちたい場合は下記のようなパラメータをよく使っています。
- Denoising strength: 0.5-0.6
- CFG Scale: 5-6
ここでもヤフミらしい顔に近づくまで数値を変えたりしながら何十枚も生成していきます。
CGW:ヤフミのMV制作ではどのようなことを意識してAIを活用されていますか?
宮本:心がけているのは、あくまでも「今までの制作の延長線でAIを取り入れていくこと」です。
生成AIの使い方は人それぞれだと思いますが、私の場合は明確で、「自分ではつくれない部分や、つくれたとしてもあまりに時間がかかってしまう部分をサポートしてもらうこと」が目的です。

たとえばヤフミのように、映像に登場する人物のビジュアルを描く技術を私は持っていないので、その部分をAIの画像生成で補完しています。
とはいえ、作品の世界観や演出はこれまで通り手づくりです。
このMVも主人公のヤフミはAIで生成されたキャラクターですが、背景にある夜の街並みなどは今まで通り、私自身がDCCツールを用いて自分の手でつくっています。
あとは、AIの話題からは逸れてしまいますが、あくまでもMVは音楽の引き立て役なのでなるべくシンプルな画づくりを心がけています。AIを使っている・いないにかかわらず「良い曲だなあ」と思ってもらえるような映像が理想ですね。
効率化としてのAI活用と、広がるクリエイターの表現
CGW:クリエイターの視点から、AIと人間の役割分担について、現時点でのご自身の考えを聞かせてください。
宮本:繰り返しになってしまいますが、「今までの制作の延長線でAIを取り入れていくこと」だと思います。
先ほどのように、「自分ではつくれないものをお願いする」というのもひとつですし、最近では「自分でつくれるけど、時間がかかるものを依頼する」という試みも行っています。
たとえば流体シミュレーション系のCGは制作・レンダリングともに時間がかかるので、AIでの生成を試しました。
しかし現状では私が手作業のほうが納得のいくクオリティに仕上がり、AIによる生成のほうがかえって非効率になってしまいました。
その他、フレーム単位で動くモーショングラフィックスや、2Dテイストと3DCGを組み合わせたデザイン的な画づくりも現状では手づくりの方が良い味が出る印象ですね。
また、今回のようなオープンソース×ローカル環境でのAI生成という取り組みそのものについても、業務のワークフローに取り入れるにはまだまだ課題がありそうです。実際、今回の制作でもトラブル解決に膨大な時間を費やしました。
CGW:最後にメッセージをお願いします。
宮本:AIというものは、かなり一般に利用されるようになってきていますし、担う領域も広がり続けるでしょう。
ですが、SNSで見るAI生成の動画が日々派手でハイレベルになっている一方、見ている人はそういった動画に満腹感を感じ始めているのではないかとも思います。
「クリエイターとAI」という視点では、今回のヤフミの事例でもAIが担っている作業と、私自身がやっている作業が混在しているように、「AIを活用していかに制作の工数削減ができるか」に集約していくと予想しています。
私自身も今後、オリジナルの学習モデル作成にチャレンジしたいと思っていますが、普段から作品をつくってきたクリエイターたちが、自身の学習モデルを使用したAIを活用することができれば、さらに表現を広げることにつながっていくと思います。
CGW:ありがとうございました。
TEXT&EDIT_遠藤佳乃(CGWORLD)、kagaya(ハリんち)












