Windows PC/ワークステーション/サーバー向けの二大CPUメーカーの1つであり、GPUメーカーとしても二大巨頭の1つであるAMDは、2017年、様々な製品を発表した。ここ最近の最新動向をカテゴリ別に整理してまとめてみることにしたい。
TEXT & PHOTO_西川善司(トライゼット)
EDIT_沼倉有人 / Arihito Numakura(CGWORLD)
<1>久しぶりのアーキテクチャ刷新の新CPU「Ryzen」が発表に
これまで、開発コードネーム「Zen」コアとして開発が進んでいることを定期的にアナウンスしていたAMDだったが、2016年12月14日に0217年中に正式リリースする情報と共に、製品名が「Ryzen」となったことを発表した。Zenは、最初デスクトップPC向けのCPUとして投入される。

ZenアーキテクチャCPUのデスクトップ版製品ブランドが「Ryzen」となった
Introducing AMD Ryzen
Ryzenは、8コアの64ビットx86系CPUで、1コアあたりがSimultaneous Multithreading(SMT)に対応するため、OSからはRyzen全体で16コアあるように見える。コアクロックは3.4GHz以上と予告されており、L2キャッシュとL3キャッシュを合わせた容量は20MBとなるという。

Ryzen自体はもともと「Summit Ridge」という開発コードネームで開発されてきたCPUである
先代の開発コードネーム「Bulldozer」アーキテクチャでは、各CPUコアは整数演算ユニットは専用ユニットが搭載されていたものの、浮動小数点演算ユニットは「2コアで共有する」というアーキテクチャとなっていた。これは「一般的なソフトウェアは整数命令実行が主体となるから」という設計思想に基づくものだったが、各コアに整数演算ユニットも浮動小数点ユニットも内包する同世代のインテル製Coreプロセッサと比較するとピーク性能で及ばないと言われることもあった。Zenアーキテクチャではこの点を改良。Zenでは整数/浮動小数点演算ユニットの両方を各コアに搭載しており、しかも、SMTにも対応するため、競合に引け目を感じることがなくなった格好だ。
また、条件分岐の際の分岐予測機構に、自己学習機能を加えた「Neural Net Prediction」を搭載することもホットトピックだ。さらに実行命令がメモリ読み出しを伴う際、事前にその読み込み対象メモリを先読みしておく「Smart Prefetch」機能も搭載される。これらの工夫は1クロックあたりの命令実行効率(IPC:Instruction per Cycle)の向上に大きく貢献することが期待されている。
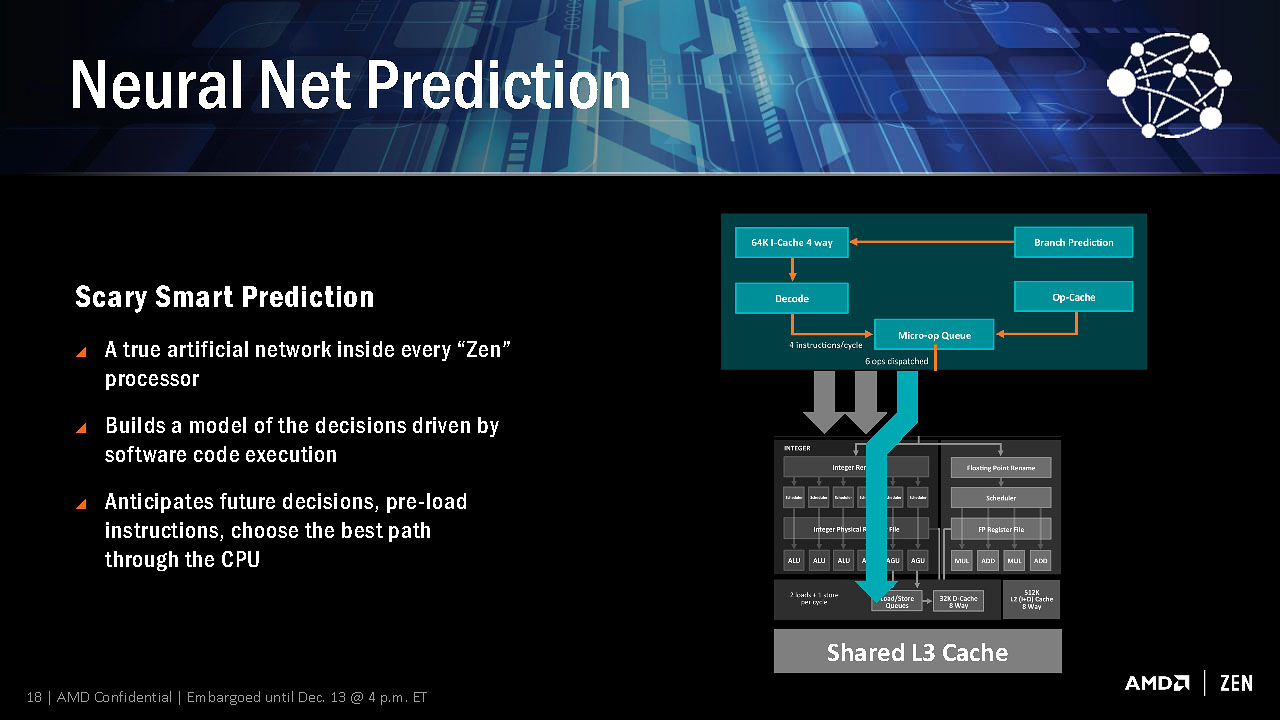
条件分岐命令の実行予測に学習機能「Neural Net Prediction」が盛り込まれることとなった。近代CPUにおいてパイプライン実行を崩さないためには高精度な分岐予測が求められているため、効果には大きな期待が掛かる

近代CPUの命令実行において条件分岐実行に列んで「厄介ごと」とされるのがメモリアクセスだ。演算サイクルに対して数百倍の時間が掛かるメモリアクセスの隠蔽を行うのが「Smart Prefetch」機能
また、ピーク性能重視のユーザーに訴求される「Extended Frequency Range」という機能も独特だ。最近のCPUでは、定格動作クロックとは別に、最大性能を発揮する「ブーストクロック」が設定されることが多くなってきた。Ryzenでは、自身の冷却条件が良好であれば、自発的に、そのブーストクロックを上回る周波数で動作するのだ。大型冷却ファンや水冷システムなど、よりアグレッシブな冷却を行えば、その冷却に見合った高性能が得られるというのはいわば「メーカー謹製のオーバークロック」ということであり、性能重視のワークステーション製品などでは引き合いが強くなりそうだ。
Ryzenを迎えるにあたり1点注意しなければならないのは、これまで長らく使い続けられてきた「AM3」系プラットフォームが使えなくなるということだ。
Ryzenに対応するプラットフォームとしては「AM4」が適合する。なお、AM4プラットフォームは、最新APUの開発コードネーム「Bristol Ridge」対応品として、2016年後半に登場しているが、実はもともとはZen系CPUをターゲットにしていたものであった。2017年以降は、AMDプラットフォームの主軸は「AM4」となることには留意しておきたい。

RyzenはAM4プラットフォームに適合する。AMDの最新APUもAM4に対応するため、今年以降、AMDのプラットフォームはAM4に移行する...という認識でいいだろう
次ページ:
<2>AMD、メモリアーキテクチャを刷新させたハイエンドGPU、VEGA(開発コードネーム)を発表
<2>メモリアーキテクチャを刷新させたハイエンドGPU、VEGA(開発コードネーム)を発表
AMDは2016年中頃に開発コードネーム「Polaris」こと、RADEON RX400シリーズを発表し、リリース。しかし、RADEON RX400シリーズはいわゆるコストパフォーマンス重視のGPUで、ハイエンドモデルは後に登場する開発コードネーム「VEGA」になることが確実視されていた。


VEGAを発表するRaja Koduri/ラジャ・コドゥリ氏(Senior Vice President and Chief Architect, Radeon Technologies Group, AMD)
そして年が開けての1月5日。AMDは、この開発コードネーム「VEGA」の存在を正式に認め、このGPUに搭載されている注目すべき技術ポイントを4つ発表した。しかし、AMD製GPUの製品シリーズ名であるRADEONとしての型式番は明かさず、また、内包されるシェーダプロセッサ数も非公開とし、事実上の予告的な発表となっていた。4つのポイントのうち1つは、新プログラマブルシェーダとして「Primitive Shader」(プリミティヴシェーダ)が新設されるということだ。これはこれまで存在した「頂点シェーダ」と「ジオメトリシェーダ」、そしてGPGPU的な処理を行うComputeShaderを統合したようなものになるという。
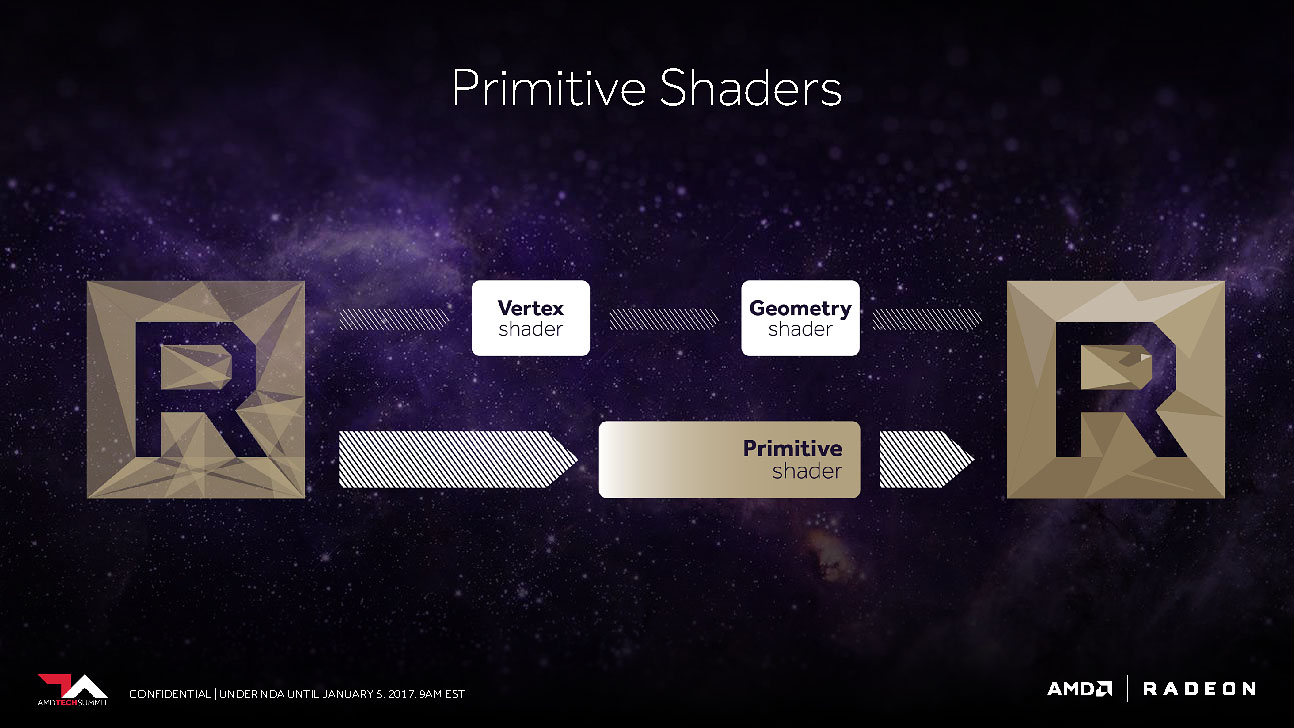
新プログラマブルシェーダ「Primitive Shader」の新設。基本的には頂点シェーダとジオメトリシェーダ、ComputeShaderを統合させたようなものだが、現状でDirectX,OpenGLでもサポートされていない新シェーダである
2つめは「Intelligent Workgroup Distributor」(以下、IWD)と呼ばれるもので、具体的には頂点単位のジオメトリタスクを高効率で実行できるよう制御する仕組みとなる。
3つめは、半精度浮動小数点(FP16)や8ビット整数(INT8)を、シェーダプロセッサがPacked実行できるようになった点だ。Packed実行とは、1つのレジスタに複数のデータを入れ込んで、演算器で一括実行させる仕組み。もともとRADEON HD 7000系の「Graphics Core Next」(以下、GCN)アーキテクチャでは、単精度浮動小数点(FP32)を演算の基本単位としており、処理対象のデータがFP16でもINT8でも演算時間はFP32と同じになっていた。これがVEGAでは、FP16であれぱ、32ビットレジスタに2つ、INT8であれば4つ入れ込んで、これらを一遍に演算して結果を返す仕組み(これがPacked実行)にしたということだ。

VEGAのシェーダプロセッサはPacked実行に対応する
4つ目は、ピクセルシェーダ側の実行効率の改善だ。具体的には、後段で別のポリゴンの描画によって上書きされてしまうピクセルの早期破棄、ピクセルを実際にメモリへの書き出す際のキャッシュメモリ管理の最適化などがこれに当たる。
これら4つの進化ポイントとは別に、VEGAではメモリアーキテクチャが一新されたこともホットトピックである。VEGAでは、グラフィックスボードの基板側ではなく、GPUチップ上に「HBM2」(High Bandwidth Memory2)と呼ばれる高速メモリが実装される。HBMとはメモリチップを高層ビルのように積み上げて(=スタックさせて)配置し、それを「TSV」(Through Silicon Via:シリコン貫通ビア)技術によって串刺しに貫通させて配線するメモリ実装技術で、省スペースかつ高帯域なメモリ性能を発揮できる新世代のメモリ技術である。
HBM2はこのHBMの2世代目のものになる。「HBM2を搭載したGPU」というだけでもユニークだが、それ以上に、業界を驚かせたのは、このHBM2が、グラフィックスメモリとしてではなく、巨大なキャッシュメモリとして採用されているという点だ。つまり、VEGAでは、レンダリングの際に本当に高速性が必要なデータだけをキャッシュメモリとしてのHBM2に載せて、それほどでもないデータは、システムメインメモリや場合によってはハードディスクやSSDに退避してしまうような仕組みを採用したのだ。この発想はCPUではお馴染みの仮想メモリの仕組みと同じだ。つまり、VEGAでは、ついにGPUにも仮想メモリの概念を導入してきたというわけだ。

オンダイ搭載されるHBM2はキャッシュメモリ扱いに。VEGAのメモリアーキテクチャでは、CPU並の仮想メモリアーキテクチャが本格導入されることになる
AMD側の発表では、VEGAの有効仮想アドレスは49ビットだそうで、この仕組みで利用できる仮想メモリ空間は512TB(テラバイト)となる。ちなみに、64ビット版Windows 10がサポートする仮想アドレス空間は48ビットで256TB(ユーザー領域とシステム領域の総和)のため、当面、この仕組みで実用上の支障が出ることはない。
これまでHBM2の容量自体は非公開とされたが、HBM2チップ自体の現状仕様から推察すると少なくて4GB、多くて8GBになると見られる。となると、アーキテクチャ上の動作は大部変わることになるが、GPUハードウェア自身が行う実作業/データのやりとりの実体はそれほど従来GPUと大差はないと言える。
しかし、こうした「完全なる仮想アドレスの仕組み」の導入は、「CPUとGPUが共通のメモリ空間にアクセスしつつ、演算処理も協調して行っていく」ような近代コンピューティングパラダイムにおいては重要視されているため、業界的にはこのAMDのメモリアーキテクチャ刷新に対しては概ね賛同の声が多いようだ。
次ページ:
<3>機械学習型AI向けGPGPU製品「RADEON INSTINCT」シリーズ
<3>機械学習型AI向けGPGPU製品「RADEON INSTINCT」シリーズ
VEGAに関連して、AMDは、機械学習(Machine Learning)向けのGPGPU(General Purpose GPU)製品として「RADEON INSTINCT」シリーズも発表した。AMDは、機械学習型AIを実践するためのGPGPU製品分野の市場シェアにおいて、競合のNVIDIA「TESLA」シリーズに後塵を拝している現状があるが、これを打開するための施策を講じてきた格好だ。
NVIDIAがこの分野で成功している背景には、「CUDA」(Compute Unified Device Architecture)と呼ばれるGPGPUプラットフォームの成功があるわけだが、AMDは「RADEON INSTINCT」の投入と同時に、このプラットフォーム面(ソフトウェアエコシステム)においてもテコ入れを行うようだ。
ハードウェアとしては、2016年12月にRADEON INSTINCTシリーズとして3製品「MI6」「MI8」「MI25」を発表した。製品型番のMIはMachine Intelligenceから、数字は半精度(FP16)のTFLOPS性能値から来ている。MI6のGPUコアはPolaris(RADEON RX400系)、MI8はFiji(RADEON R9 Fury系)、そしてMI25がVEGAを採用するものになる。

製品型番のMIはMachine Intelligenceから、数字はTFLOPS性能値から来ている機械学習向けGPGPU製品「RADEON INSTINCT」シリーズ

RADEON INSTINCT「MI25」を掲げるコドゥリ氏
RADEON INSTINCTはGPU製品ではあるが、HDMIやDisplayPortなどの映像出力端子を持たない、純粋な演算利用目的のGPUで、パッシブ冷却システム(電動ファンなし)を採用し、複数GPU搭載に対応し、ハードウェアレベルでの仮想化(SRIOV)にも対応する。機械学習においては、長大なデータを取り扱うことが必然であり、そのためには前述したようなCPU並の仮想メモリアーキテクチャが有効に効いてくるというわけだ。
また、現在、機械学習型AIはクラウド側で仮想化されたサービスとして提供される事例も増えてきているわけだが、その際にスケーラブルにハードウェア増強が行えることが重要になる。その面において、RADEON INSTINCTは、マルチGPU環境をハードウェアレベルで仮想化することにも対応しているため優位だとAMDは主張している。

RADEON INSTINCTの特徴

RADEON INSTINCTはマルチGPUの仮想化にハードウェアレベルで対応する
GPGUプラットフォーム、ソフトウェアエコシステムとしては、ROCm(RADEON OPEN COMPUTE)をオープンソースプロジェクトとしてスタートさせており、機械学習向けのミドルウェアしてはMIOpen(Machine Intelligence Open)も公開にふみきっている。ROCm層は、競合NVIDIAのもので喩えればCUDA層に相当するもので、AMD側の説明によれば、サードパーティなどの手によってROCmとCUDAのラッパー(相互変換層)が提供されれば、競合NVIDIAのCUDAアプリケーションも動作させることができるだろうとのことだ。

ROCmのソフトウェアスタック構造
<4>オフラインレンダリングのためのグラフィックワークステーション向けGPU製品「RADEON PRO SSG」シリーズも発表
2016年夏、「SSD搭載のグラフィックワークステーション向けGPU」というコンセプトだけが発表され、その素性がよくわかっていなかった製品「RADEON PRO SSG」が、実はVEGAベースだったということも、VEGAの発表とと同時に明かされた。

ユニークなSSD搭載のワークステーション向けグラフィックスボード「RADEON PRO SSG」。実はVEGA搭載製品であった
前述したようにVEGAでは、直近のレンダリングに必要なデータだけをキャッシュとして利用される高速なHBM2上に載せ、それ以外のデータを仮想メモリとしてその他の種別の記憶領域に置いておけるアーキテクチャが採用されたわけだが、その「その他の種別の記憶領域」を「GPUカード上に搭載したSSD」とした製品が「RADEON PRO SSG」なのである。SSD容量は現時点では非公開だが、VEGA発表時には、事前計算した20GBもの大局照明情報をこのSSD上に置いてのリアルタイムレイトレーシングデモが実機上で公開された。
20GBもの事前計算データをSSD上に載せ、リアルタイムレイトレーシングをRADEON PRO SSGで実践したデモの様子。映像は実機からのキャプチャ

実演デモに用いられたシーンの画面ショット
<5>おわりに〜CESではRyzen搭載製品の展示や新作デモも公開に
2017年1月5日(木)から8日(日)まで、ラスベガスで開催された家電ショウ「CES 2017」のAMDブースでは、前出のRADEON PRO SSGを用いてのリアルタイムレイトレーシングのデモの新バージョンを公開。新デモでは事前計算データ量が200GBとなり、より規模の大きいシーンでのリアルタイムレイトレーシングを実践していた。
「SSD搭載のグラフィックスボード」というと、奇妙な製品に思えるかも知れないが、VEGAアーキテクチャに鑑みればかなり理に叶った製品であり、実際のレンダリングファームでの採用が進めば、レンダリング速度の劇的な向上だけでなく、ネットワークトラフィックの削減にも結びつきそうだ。

CESではRADEON PRO SSG 4枚挿しマシンにて、200GBもの事前計算データを用いてリアルタイムレイトレーシングをデモ
また、AMDはRyzen搭載の各社デスクトップPC製品群やRyzen対応のマザーボード製品群も展示しており、より具体的な製品情報の開示や、実際の製品発売の日が近づいていることを予感させた。


Ryzen搭載デスクトップPCやRyzen対応マザーボード製品が多数展示された「CES 2017」のAMDブース