・Elasticsearchの概要
続いてElasticsearchです。ElasticsearchはElasticが開発している分散型RESTful検索/分析エンジンです。すごくざっくり言うと、大量のドキュメントから目的の単語を含むドキュメントを探すためのエンジンです。例えば、何百何千というファイルの中から目的の言葉が含まれている文章を探すためにひとつひとつ目視で確認するわけにもいかないですし、grepなどを駆使して探しても膨大な時間がかかってしまいます。そのようなケースでも、Elasticsearchを使用することで高速に検索することができます。また、REST APIを使用して簡単にアクセスできるのも魅力です。
・Elasticsearchの日本語対応
ソフトウェアにとって日本語処理はとても大変なことです。標準のElasticsearch環境では日本語文章をきちんと認識して扱うことができません。そこで、Japanese (kuromoji) Analysis Plugin(以下、kuromoji)をインストールして日本語文章をきちんと単語ごとに区切ることができるようにします。
・kuromojiのインストール
[chiyama@docker ~]$ sudo docker exec -it elasticsearch bash
[root@305ef1f43db6 elasticsearch]# elasticsearch-plugin install analysis-kuromoji
-> Downloading analysis-kuromoji from elastic
[=================================================] 100%??
-> Installed analysis-kuromoji
・Dockerコンテナを再起動
[root@305ef1f43db6 elasticsearch]# exit
exit
[chiyama@docker ~]$ sudo docker restart elasticsearch
elasticsearch
[chiyama@docker ~]$
・kuromojiを使用するindexを作成
kuromojiを使用するようにしたindexを作成します。設定用JSONファイルを用意して、REST API経由で登録を行います。
[chiyama@docker ~]$ cat kuromoji.json
{
"settings": {
"index":{
"analysis":{
"tokenizer" : {
"kuromoji" : {
"type":"kuromoji_tokenizer",
"mode":"search"
}
},
"analyzer" : {
"default" : {
"type" : "custom",
"tokenizer" : "kuromoji_tokenizer"
}
}
}
}
}
}
[chiyama@docker ~]$ curl -H "Content-Type: application/json" -XPUT docker.XXX.XXX.XXX:9200/articles --data-binary @kuromoji.json
{"acknowledged":true,"shards_acknowledged":true,"index":"articles"}[chiyama@docker ~]$
これでkuromojiが有効になったindexが作成されました。確認してみます。
[chiyama@docker ~]$ curl -XGET http://docker.XXX.XXX.XXX:9200/articles?pretty
{
"articles" : {
"aliases" : { },
"mappings" : { },
"settings" : {
"index" : {
"number_of_shards" : "5",
"provided_name" : "articles",
"creation_date" : "1550391403665",
"analysis" : {
"analyzer" : {
"default" : {
"type" : "custom",
"tokenizer" : "kuromoji_tokenizer"
}
},
"tokenizer" : {
"kuromoji" : {
"mode" : "search",
"type" : "kuromoji_tokenizer"
}
}
},
"number_of_replicas" : "1",
"uuid" : "L5daMZdgQO6BQ4VQn0Va4w",
"version" : {
"created" : "6060099"
}
}
}
}
}
[chiyama@docker ~]$
analyzerとtokenizerにkuromoji_tokenizerが指定されています。試しに、きちんと処理ができるか確認します。
[chiyama@docker ~]$ curl -H "Content-Type: application/json" -XGET http://docker.XXX.XXX.XXX:9200/articles/_analyze?pretty -d '{"text" : "東京スカイツリー"}'
{
"tokens" : [
{
"token" : "東京",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "スカイ",
"start_offset" : 2,
"end_offset" : 5,
"type" : "word",
"position" : 1
},
{
"token" : "ツリー",
"start_offset" : 5,
"end_offset" : 8,
"type" : "word",
"position" : 2
}
]
}
[chiyama@docker ~]$
公式ドキュメントのようにユーザー辞書を用意して個別の単語を登録すれば「スカイツリー」もひとつの単語として認識されますが、今回はこれでよしとしておきます。
準備ができたので、検索用の文章を登録します。
[chiyama@docker Elasticsearch]$ cat 008.json
{
"title" : "HTCondorの概要 ",
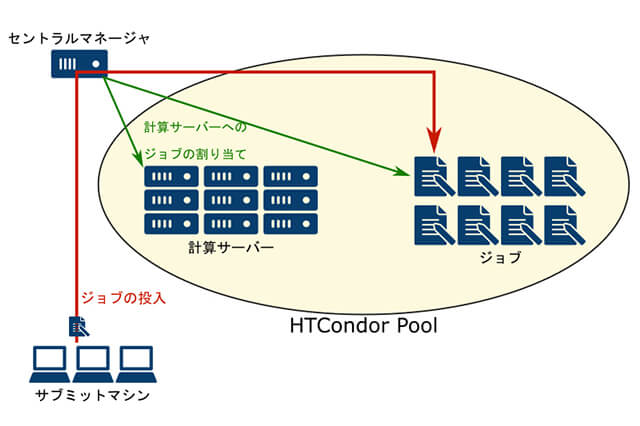
"text" : "HTCondorは、アメリカのウィスコンシン大学で開発が行われており、ネットワーク上にある計算機の有効利用を目的としていることが特徴です。通常、シミュレーションやレンダリングといった計算はレンダーファームにある計算機に行わせますが、スタジオ内にはそれ以外にも多くの計算機が存在します。一番多いのはアーティストが使用するPCですね。これらのPCは多くの能力があるにも関わらず、夜間や昼食、会議など、人が使用していないときには待機状態になってしまいます。HTCondorは、そのような資源を有効利用することを主目的に開発されました。HTCondorの大まかな構成は下図の通りです。 "
}
[chiyama@docker Elasticsearch]$ curl -H "Content-Type: application/json" -XPUT docker.XXX.XXX.XXX:9200/articles/cgwjp/1?pretty --data-binary @008.json
{
"_index" : "articles",
"_type" : "cgwjp",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
[chiyama@docker Elasticsearch]$
検索してみます。
[chiyama@docker Elasticsearch]$ curl -H "Content-Type: application/json" -XGET docker.XXX.XXX.XXX:9200/articles/_search?pretty -d '{"query":{"match":{"text":"ウィスコンシン"}}}'
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.29191685,
"hits" : [
{
"_index" : "articles",
"_type" : "cgwjp",
"_id" : "1",
"_score" : 0.29191685,
"_source" : {
"title" : "HTCondorの概要 ",
"text" : "HTCondorは、アメリカのウィスコンシン大学で開発が行われており、ネットワーク上にある計算機の有効利用を目的としていることが特徴です。通常、シミュレーションやレンダリングといった計算はレンダーファームにある計算機に行わせますが、スタジオ内にはそれ以外にも多くの計算機が存在します。一番多いのはアーティストが使用するPCですね。これらのPCは多くの能力があるにも関わらず、夜間や昼食、会議など、人が使用していないときには待機状態になってしまいます。HTCondorは、そのような資源を有効利用することを主目的に開発されました。HTCondorの大まかな構成は下図の通りです。 "
}
}
]
}
}
[chiyama@docker Elasticsearch]$
無事に日本語も検索できています。日本語対応でちょっと準備が大変でしたが、これを応用すれば社内システムに検索エンジンを乗せることができるようになるわけです。
次回予告
ここまでで、データ処理の後半に当たるGraphite、Grafana、Easticsearchがどのようなものかという確認ができました。次回はデータ収集を効率的に行うためのツール、Logstashの解説と本命のFifemon環境の構築へと進んでいきます。
第11回の公開は、2019年4月を予定しております。
プロフィール