
みなさんこんにちは。先月購入した3Dプリンタを使って新しく3Dプリンタをつくり始めました。何を(ry という感じですが、ソフトウェアとちがって現物がガシャコンガシャコンと動く機械をつくるのは楽しいです。まずは既存のものをほぼそのままつくってみて、そこから自分なりに改良していけたらいいなと目論んでいます。皆さんも一丁、マィ・3Dプリンタ製作に挑戦してみませんか!?
TEXT_痴山紘史 / Hiroshi Chiyama(日本CGサービス)
EDIT_尾形美幸 / Miyuki Ogata(CGWORLD)

使いやすいプログラムのつくり方
前回は、良いプログラムを書くってどういうこと? という具体例を、既存コードのリファクタリングを通してご紹介しました。今回は、使ったときに不安にならない、ストレスの元にならないプログラムのつくり方をまとめていきます。
ユーザーへのフィードバック
長い時間がかかる処理を行う際、ユーザーに対して定期的に何らかのフィードバックを返してプログラムが生きていることを伝えるのはとても大事なことです。アプリケーションの操作中にGUIが固まってしまったものの、CPUの使用率は高いままなので、不安は棚上げしてとりあえず放置するという経験を誰もがしたことがあるでしょう。せめて、このときに何かログがながれて処理が進んでいることが確認できれば、不安感を大幅に軽減することができます。可能であれば、全体に対し、どの程度まで処理が進んでいるのかを確認できるようになっていれば、ユーザーは安心して待つことができます。
ただし、伝える情報は必要十分なものにして、伝える順番も気を付けます。
例として、ディレクトリにあるファイルの名前がルールに沿っているかチェックするプログラムを作成するとします。
for f in os.listdir(path):
if check_filename(f) == False:
print('invalid filename : %s' % f)
else:
print('valid filename : %s' % f)
これはユーザーにプログラムが死んでいないことを知らせるという目的は果たしていますが、あまり良くない例です。最終的にユーザーが必要としているのは不正なファイル名はどれかという情報なのに、正常なものも同列に表示してしまっているため、エラーがあるのかどうか、ログを見ただけで把握するのは難しくなっています。もしディレクトリに十万個のファイルがあって、その中にひとつだけ問題のあるファイルが含まれていた場合、ユーザーは高い確率でエラーを見逃してしまうでしょう。これでは本末転倒です。
そこで、ユーザーに伝える情報を絞ってエラーだけ出力するようにしてみます。
for f in os.listdir(path):
if check_filename(f) == False:
print('invalid filename : %s' % f)
もし、check_filename が非常に重たい処理で、かつファイルが大量にある場合はどうでしょうか?
不正なファイルがあった場合は、ファイルが不正だという表示が出るのでプログラムが実行されていることはわかりますが、それ以外のときには何のフィードバックもありません。1分くらいで処理が終わるのならいいですが、数十分もかかるようなものの場合、とてもではないですが待っていられません。
このような場合、進捗状況がわかるようにした上で、最後に必要な情報を提示するようにします。
errors = []
files = os.listdir(path)
for i,f in enumerate(files):
print('check file [%.2f%%]: %s' % (i*100.0 / len(files), f))
if check_filename(f) == False:
print(' invalid!!')
errors.append(f)
print( 'invalid files:')
print( '\n'.join(errors))
そうすれば、全体に対し、どのくらい処理が進んでいるのか、どの程度エラーになっているのかがリアルタイムにわかり、かつログの最後を見るだけで不正なファイルを把握することができます。
ユーザーはリアルタイムに状況を把握できるため、場合によっては処理を途中で停止して問題を修正した上で再度実行することもできます。
レスポンスタイムの改善
長時間の事前処理を行なってから本番処理を行うようなケースでは、事前処理に時間をとられ、本番処理の確認が進まないことがあります。 このような状態は大きなストレスになるため、処理を組み替えて早い段階で結果を取得できるようにします。
図にすると以下のようになります。

事前処理を一度に行うようなプログラムのつくり方をしてしまうと、肝心の本番処理でエラーになったときに、事前処理の時間が丸々無駄になってしまいます。 更に、エラーを修正して二度目の実行を行うときに大きなちがいが出てきます。
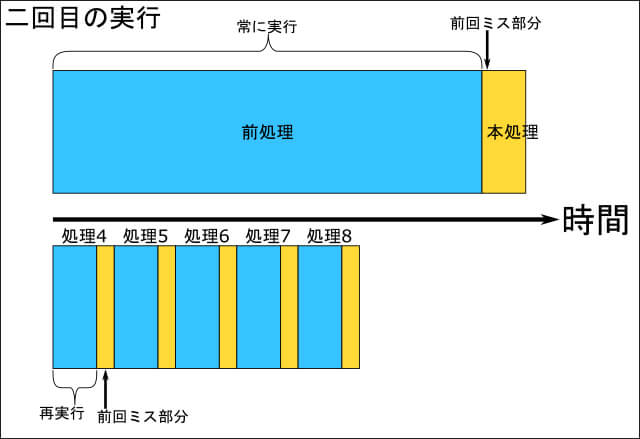
長時間の事前処理を行うプログラムの場合、再度事前処理が実行されてしまいます。こうなってしまうと、問題修正→確認というサイクルを高速に回すことができません。
これに対して、内容を分割して順番に処理するようにしたプログラムでは、既に処理が終了している部分は全てスキップして、エラーになったところから実行できます。このような構成になっていれば、たとえ再度エラーになったとしても即座に結果がわかり、早いサイクルで問題対応ができます。事前処理に20分かかり、本番処理のチェックは1分で済むような場合には、分割して処理した場合との差は非常に大きなものとなります。
さらにプログラムを改良して高速化しようとした場合、処理内容が整理されて分割されていれば、個々の処理を複数同時に実行して全体の処理速度を稼ぐといった工夫も可能です。
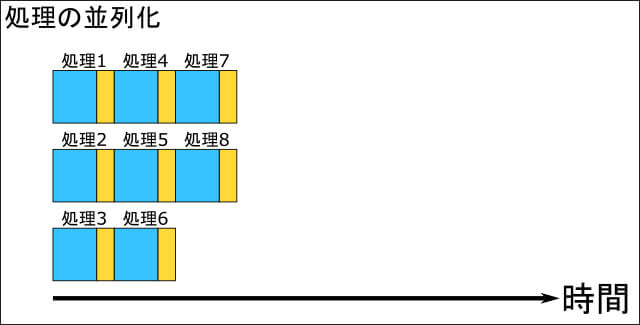
処理内容が整理されていれば、処理の組み換えや整理をして、さらなる高速化を図ることも簡単に行えます。
[[SplitPage]]
不幸な事例
プログラムの動作確認をするための事前準備に30分程かかった挙句、本番処理の凡ミスで一瞬でエラーになった不幸な例がこちらです。
D:\xlgan> D:\xlgan\getPlayListMovie.py
Shotgun related transactions start in shortly.
project name: XXXXXX
dest dir: C:\temp\review
mode: fetching all playlists mode.
start to fetch 32 play lists.
phase 1: retrieve play list information!
[FETCH LIST][0001/0032]: XXXXXXXXXXXXXXXXXXXXX
[FETCH LIST][0002/0032]: XXXXX
[FETCH LIST][0003/0032]: XXXXXXXXXXX
[FETCH LIST][0004/0032]: XXXXXXXXXXXXXXXXXXXXX
[FETCH LIST][0005/0032]: XXXXXX
[FETCH LIST][0006/0032]: XXXXXXXX
[FETCH LIST][0007/0032]: XXXX
[FETCH LIST][0008/0032]: XXXXX
[FETCH LIST][0009/0032]: XXXXXXXXXX
[FETCH LIST][0010/0032]: XXXXXXXXXXXXXXXXXXXXX
[FETCH LIST][0011/0032]: XXXXXXXXXXXXXXXXXXXXX
[FETCH LIST][0012/0032]: XXXXXXXXXXXXXXXXXXXXX
[FETCH LIST][0013/0032]: XXXXXXXXXXXXXXXXXXXXX
[FETCH LIST][0014/0032]: XXXXXXXXXXXXXXXXXXXXX
[FETCH LIST][0015/0032]: XXXXXXXXXXXXXXXXXXXXX
[FETCH LIST][0016/0032]: XXXXXXXXXXXXXXXXXXXXX
[FETCH LIST][0017/0032]: XXXXXXX
[FETCH LIST][0018/0032]: XXXX
[FETCH LIST][0019/0032]: XXXXXXXXXX
[FETCH LIST][0020/0032]: XXXXXXX
[FETCH LIST][0021/0032]: XXXXXX
[FETCH LIST][0022/0032]: XXXXX
[FETCH LIST][0023/0032]: XXXXXXXXX
[FETCH LIST][0024/0032]: XXXXXX
[FETCH LIST][0025/0032]: XXXXXXXXXX
[FETCH LIST][0026/0032]: XXXXXXXXXXXXXXXXXXXXX
[FETCH LIST][0027/0032]: XXXXXXXXXXXXXXXXXXXXX
[FETCH LIST][0028/0032]: XXXXXXXXXXXXXXXXXXXXX
[FETCH LIST][0029/0032]: XXXXX
[FETCH LIST][0030/0032]: XXXXXXXX
[FETCH LIST][0031/0032]: XXXXXX
[FETCH LIST][0032/0032]: XXXXXXXXXXXXXXXXXXXXX
phase 2: prepare destination folder!
done!
phase 3: download movies!
[LOAD][Movie #0001/3910]: XXXXXXXXXXXXXXXXXXXXXX.mov is downloading ...
Traceback (most recent call last):
File "D:\xlgan\getPlayListMovie.py", line 392, in
dispatcher(sys.argv)
File "D:\xlgan\getPlayListMovie.py", line 374, in dispatcher
main(arg_dict)
File "D:\xlgan\getPlayListMovie.py", line 349, in main
tf2 = retriever.download()
File "D:\xlgan\getPlayListMovie.py", line 218, in download
self.adjust_file_time_stamp(fname, mov['updated_at'])
File "D:\xlgan\getPlayListMovie.py", line 169, in adjust_file_time_stamp
os.utime(path, (atime, mtime))
WindowsError: [Error 2] 指定されたファイルが見つかりません。: u'C:\\temp\\review\\XXXXXXXXXXXXXXXXXXXXX\\XXXXXXXXXXXXXXXXXXXXXX.mov'
Traceback (most recent call last):
File "D:\JCGSLauncher\JCGSLauncherCmd.py", line 66, in
arg=sys.argv[4:])
File "D:\JCGSLauncher\JCGSLauncherCore.py", line 989, in run
self.logger.info('\n'.join(msg))
TypeError: can only join an iterable
D:\xlgan>
このときは、phase 1 のリストの取得で30分ほどかかった後にエラーになっています。そして、このプログラムの次の動作確認には、また30分の準備時間が必要になります。正直、これは心が折れます......。自分がつくったプログラムなら自分の不注意を呪いながら修正するだけですが、他人がつくったプログラムでこれが起きたらデスノート行きですね。
エラーは可能な限りまとめて伝える
プログラムの実行中にエラーが起きても、その場ですぐに処理を終了してしまうのではなく、可能な限り処理を継続して、情報を収集するようにします。
例えば、100個のファイルに対して何か処理を行う場合、不親切なプログラムだと最初のエラーが出た時点で処理を終えてしまいます。 その場合、ユーザーはエラーになったファイルに対して修正を行い、再度プログラムを実行します。しかし、プログラムは次に見つかったエラーの時点で終了してしまいます。 ユーザーは、最終的にいくつのファイルを修正しなければいけないのかわからないですし、新しいエラーを見つけるために毎回プログラムを実行し、ひとつ、ひとつ対応しなければなりません。これはとても不便です。
このような場合、エラーが起こっても、エラーの情報は保持しながら別のファイルの処理を続け、一通りの処理が終わった段階でエラーになったファイルのリストとエラーの内容をユーザーに知らせるようにします。 そうすることで少なくとも全てのファイルが処理されるまではユーザーは別の作業ができますし、一度実行しただけで多くの情報を得られるので、一度に対応できることも増えます。 結果、実行する回数も必要な時間も削減できます。
さらに言うと、ひとつのファイルに対する処理の中でも同様の対応ができます。ひとつの処理を行う際に複数のチェック項目があった場合、ひとつの項目がエラーになっただけでその処理を終えてしまうのではなく、可能な限りチェック項目を実行してエラーを洗い出してから処理を戻すようにします。
このように、とにかく一度の実行で情報を絞り出せるだけ絞り出すことで、ユーザーにかかる負担を大幅に軽減することができます。
dryRun モードを用意する
データを更新するような処理をする場合、その処理を実行することで何が起きるのかわからず、不安になることがあります。 そのようなとき、データの更新を行わないまま処理を進める dryRun モードを用意すると便利です。dryRun モードがあれば、実際にはデータを更新せずに動作をシミュレーションし、予想外の事態が起きないか確認することができます。
この機能は、特に開発途中などでプログラムが安定していないときに威力を発揮します。データ更新部分以外のバグを早い段階で潰すことができるので、開発効率の点でも、精神衛生の点でも良いことしかありません。
良いコードを書く(再)
最近はCPUのコア数を増やすことで処理速度を上げるのが主流になってきている反面、どうしてもひとつのコアでしか処理できない内容も存在します。そのような場合でも、小さな処理を同時に大量に実行することで、全てのコアを効率的に使用して、十倍以上のスループットを出すことが可能になります。これを実現するためには、処理の内容を分解・整理して、一塊の大きなプログラムではなく、小さな処理の連なりとしてプログラムを構成する必要があります。これは正に前回コードを整理するときに行なった内容そのものです。ぜひ今回の内容を念頭に前回の記事を読み直してみてくだざい。きっと、得られるものがあるはずです。
まとめ
今回はユーザー(ライブラリを使ってプログラムを書くプログラマーも含む)が使う際に、ストレスを感じないプログラムを書くための考え方をご紹介しました。いずれもちょっとした心遣いであり、仕様書やカタログスペックとして現れづらいものなので、見落とされがちな部分です。また、ベースに良いコードがあって初めて実践できることなので、今書いているコードは良いコードなのか? 使いやすいプログラムなのか? ということを常日頃から意識する習慣を身に付けましょう。
第36回の公開は、2021年8月を予定しております。
プロフィール













