みなさんこんにちは。先日開催されたCGWORLD 2019 クリエイティブカンファレンスにて、「ウォーターフォール型パイプラインの問題点と、コンカレント型パイプラインの将来性」と題したセッションを実施し、本連載に関係する内容のお話をさせていただきました。おかげさまで満員御礼で、セッションの内容についても良い反応をいただけたようでホッと一安心しました。来場いただいた方はありがとうございました。
本セッションの資料はこちらで公開しているので、興味のある方はご覧になってください。また、セッション中にお見せしたGafferの操作ムービーも公開しています。映像だけでコメントなどは一切入っておらず、わかりづらくて申し訳ないのですが、Gafferがどのようなソフトウェアなのか雰囲気は伝わると思います。
TEXT_痴山紘史 / Hiroshi Chiyama(日本CGサービス)
EDIT_尾形美幸 / Miyuki Ogata(CGWORLD)
クラウド環境上のネットワーク構築
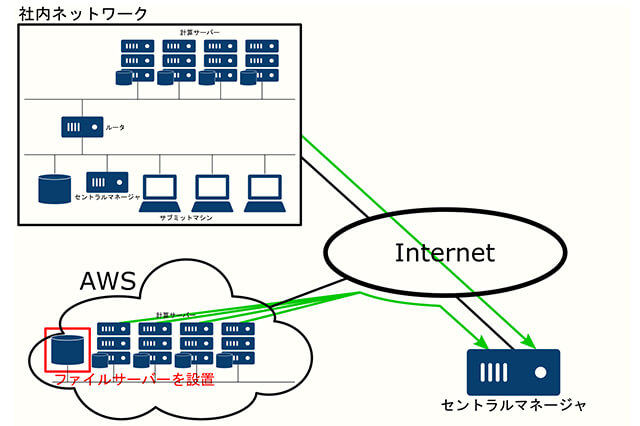
前回までで、HTCondor Annexのcondor_annexと、自分がカスタマイズしたイメージを使用して、AWS上にインスタンスを立ち上げることができるようになりました。計算サーバを単独で動かすだけなら今の環境でも十分ジョブの投入・実行ができますが、このままではジョブを実行するたびに、ローカル環境からクラウド環境に必要なファイルを全て転送してから計算を行う必要があります。
さらにインスタンス間ではデータ共有ができないため、同じシーンを複数のインスタンスで計算するような場合でも、全てのインスタンスに対して全てのデータを転送する必要があります。これはとても効率がよくないです。
そこで、クラウド環境上にもネットワークを構築し、そこにファイルサーバを置いて全てのインスタンスからファイルサーバ上にあるファイルにアクセスできるようにします。プロジェクトを通して共有されるようなアセットは事前にファイルサーバ上にアップロードしておくことで、データの転送時間や転送量、ディスクの使用量を軽減することができます。
AWS上でのネットワーク構築
AWSでは、ネットワークを構築をするための機能としてAmazon Virtual Private Cloud(VPC)があります。VPCを使うと驚くほど簡単に必要なネットワークを構築することができます。また、condor_annexを使用して作成したインスタンスは、AWS標準で作成されているデフォルトVPCに接続されています。
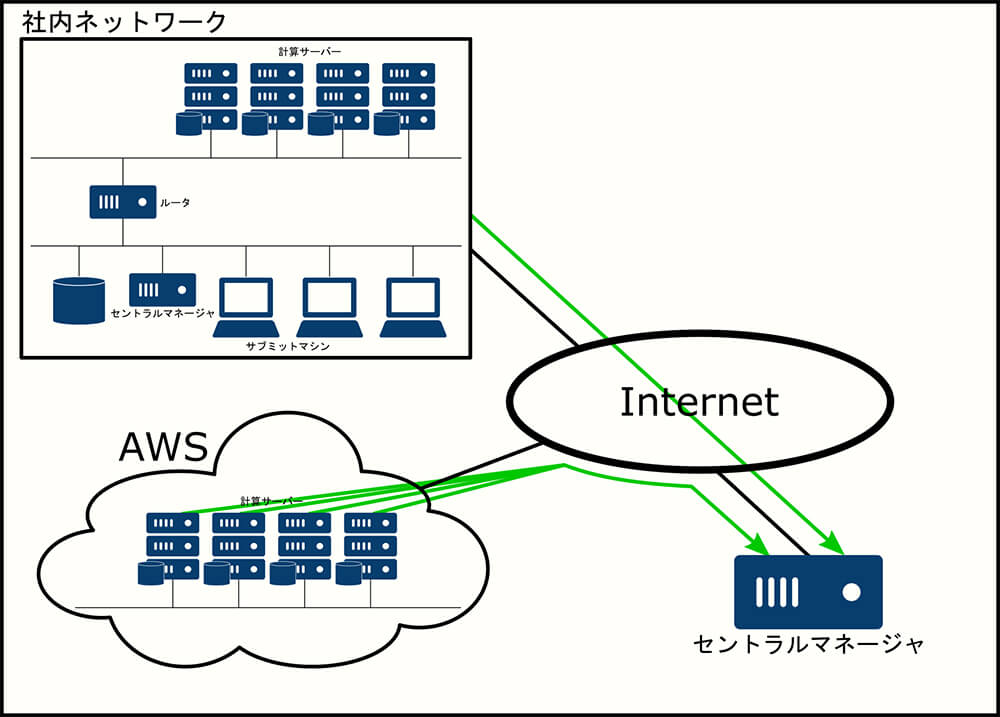
そのため、このネットワーク上にファイルサーバを構築すればアセットを共有することができます。
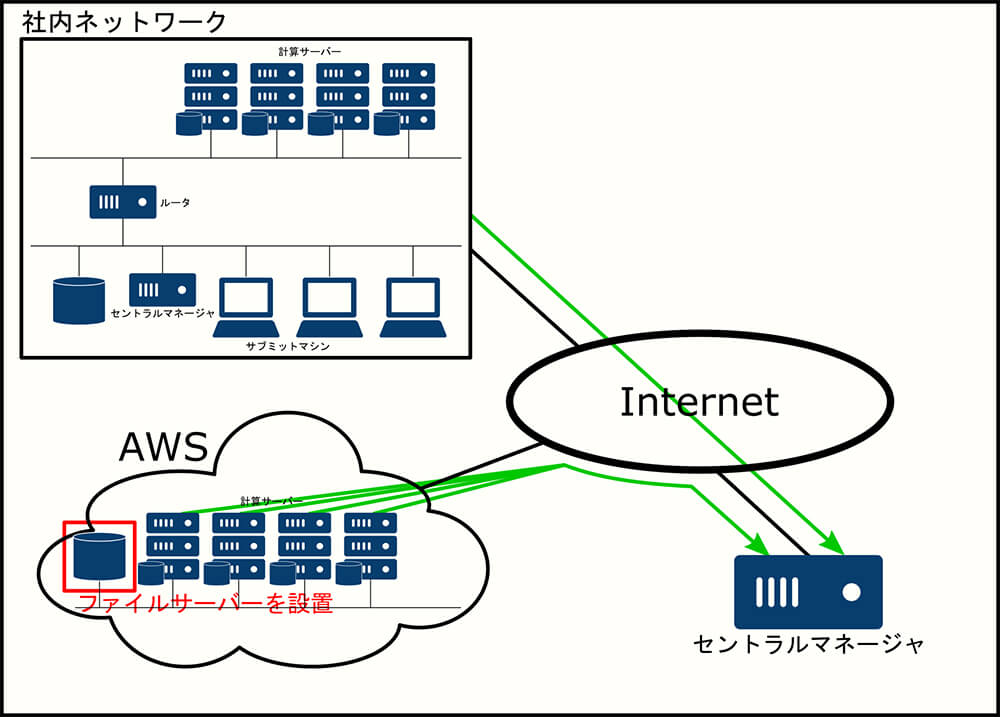
といわけで、最低限のネットワークは勝手につくられるので、われわれは何もしなくていいということになります。
注意点として、AWS上でVPCは複数作成することができるのですが、condor_annexを使用した場合はデフォルトVPCしか使用することができません。これは気を付けてください。
AWSが提供するクラウドストレージ
続いて、 AWS上にファイルサーバを構築します(結果的には"サーバ"ではないのですが)。AWSが提供するクラウドストレージに使用可能なストレージの種類がまとまっているので、これを元にどのような構成にするか検討します。
ざっくりと内容を見ていきましょう。
Amazon Elastic Block Store(EBS)
「EBSは、単一のEC2インスタンスからアクセスする永続的ストレージが必要なワークロード向けに設計されています」ということなので、PCに接続しているHDD(SDD)と似たようなイメージで使用することができます。反面、ネットワーク上の共有ファイルシステムとして使用する場合は、それ用のしくみを自分で構築する必要があります。
Amazon Elastic File System(EFS)
「何千ものAmazon EC2インスタンスに対して大規模な並列共有アクセスを提供するように設計されており、アプリケーションが一貫した低レイテンシーで高レベルの集約スループットとIOPSを実現できるようにします」。 ほうほう。これは何だか今回の用途に向きそうですね。
Amazon S3(S3)
「S3は、バックアップと復旧、階層化されたアーカイブ、ユーザー主導コンテンツ(写真、動画、音楽、ファイルなど)、ビッグデータ分析やデータウェアハウスプラットフォームのためのデータレイク、またはサーバレスコンピューティング設計の基盤として使用されます」。大量のデータを安全に保存できるようです。もしかしたら目的にマッチするかもしれません。
Amazon FSx for Lustre(FSx)
「Amazon FSxの使用により、毎秒最大数百ギガバイトのスループット、百万単位のIOPS、およびミリ秒未満のレイテンシーで大量のデータセットを処理できるLustreファイルシステムを起動し、実行することが可能になります」。ものすごく速いようです。大量のサーバから一気にアクセスするような今回の例にとてもマッチしそうです。とりあえずLustre使ってみたいですよね~(よね?
Amazon FSx for Windows ファイルサーバー
FSxのWindows版のようです。FSxがあるのでそちらでよさそうです。
Amazon S3 Glacier と S3 Glacier Deep Archive
「データのアーカイブや長期バックアップに使用できます」。バックアップ用途なので今回の目的には合わなさそうです。
AWS Backup
バックアップ用途なので今回の目的には合わなさそうです。
AWS Storage Gateway、データ転送サービス
データの保存場所ではなく、転送を支援するためのシステムのようです。
どのような種類のストレージがあるのかはわかりました。これだけだと具体的に何がどのようなケースに向いているのかイメージがわきづらいです。そこで、もうひとつ別の資料を見てみます。こちらでは、AWSで使用できるストレージをそれぞれどのように使い分けるかが詳細に解説されています。
こちらを穴が開くほど眺めながら、自分の環境と照らし合わせて最適なストレージタイプを選ぶのがよさそうです。資料の詳細は各自見ていただくとして、典型的なケースでの技術の採択例が表になっています。
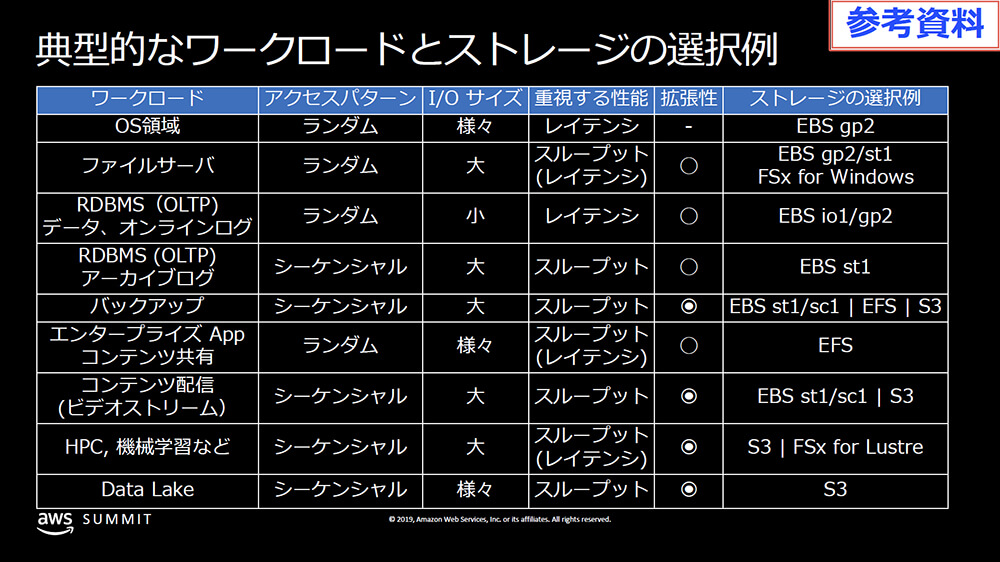
※ AWS ストレージサービスの特性理解と選択指針より引用
これらの資料をざっくりと見た感じ、EFS、S3、FSxあたりが候補に挙がってきそうです。その中で、今回はS3を使用してみます。
S3を使用する理由は以下の通りです。
・安価
・ローカル→クラウドへの手軽なデータ転送手段がある
・多くの計算機からアクセスしたときにも問題が少なそう
なお、S3を使用する際の不安点としては、以下のようなものがあります。
・アクセスに対しても課金されるので、コスト感がわかりづらい
・十分な速度が出るのかわからない
このあたりは環境や条件によって異なるので、本番環境を構築する際にはきちんと検証を行なっておく必要があります。多少金額が高くてもパフォーマンスを稼ぎたい場合はFSxも選択肢に入ってくるでしょう。
[[SplitPage]]S3バケットの準備
まずは、データを格納する先(S3ではバケットと言います)を用意します。
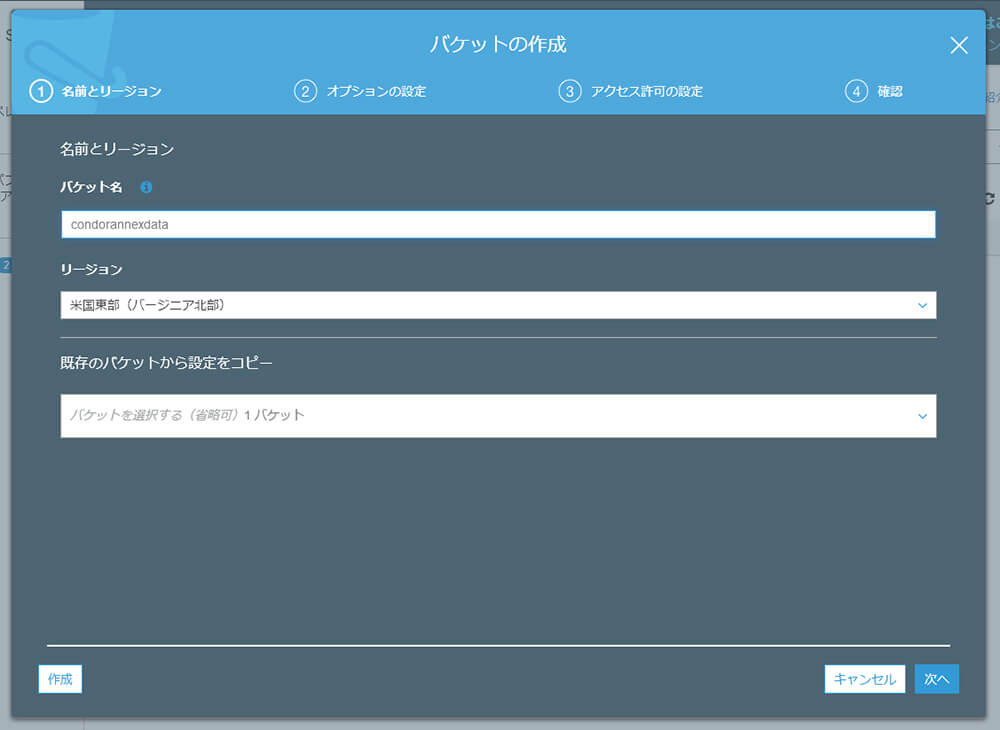
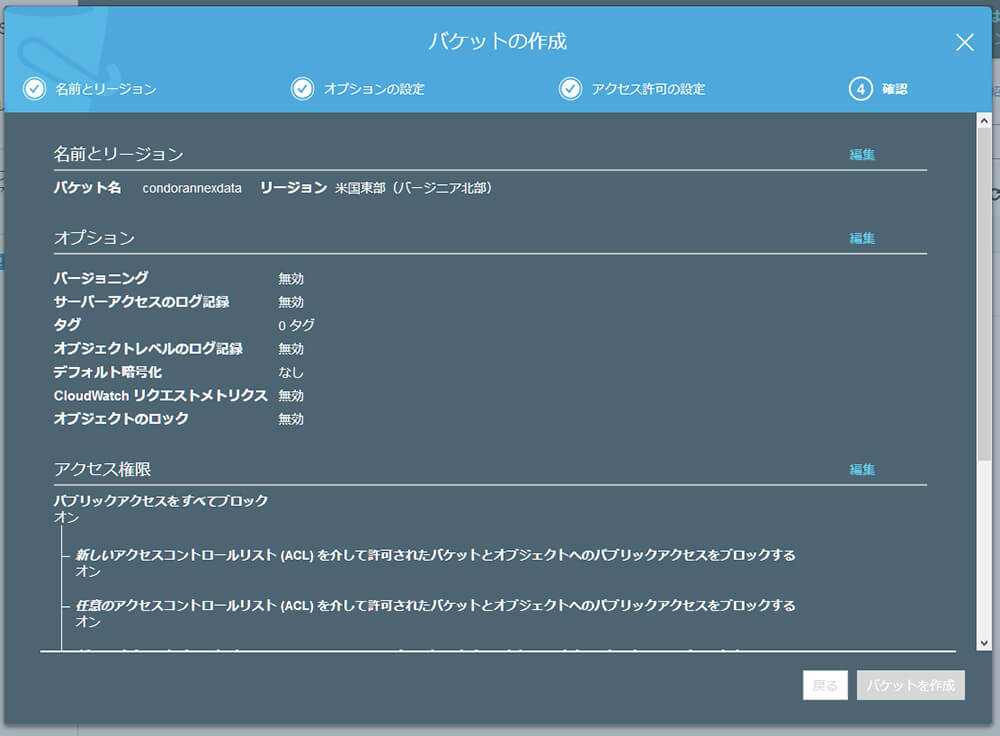
AWSマネージメントコンソールからS3サービスを選び、"バケットを作成する"をクリックします。

バケット名をcondorannexdata、リージョンを米国東部(EC2インスタンスを立ち上げるのと同じ場所)に指定します。 それ以外はデフォルトのまま作成します。
s3fsのインストール
LinuxのインスタンスからS3バケットにアクセスするにはs3fsが便利です。
インスタンスの立ち上げ後、SSHでログインしてインストールします。
$ sudo yum update
$ sudo yum install automake fuse fuse-devel gcc-c++ git libcurl-devel libxml2-devel make openssl-devel
$ git clone https://github.com/s3fs-fuse/s3fs-fuse.git
$ cd s3fs-fuse/
$ ./autogen.sh
$ ./configure -prefix=/usr -with-openssl
$ make
$ sudo make install
アクセスキーの設定
s3fsでS3バケットにアクセスするためにはアクセスキーの設定が必要です。
$ sudo vi /etc/passwd-s3fs
AWS_ACCESS_KEY_ID:AWS_SECRET_ACCESS_KEY
S3バケットのマウント
準備ができたのでS3バケットをマウントします。
$ sudo mkdir /var/s3fs
$ sudo s3fs condorannexdata /var/s3fs -o passwd_file=/etc/passwd-s3fs
マウントされたか確認します。
$ mount
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
(中略)
s3fs on /var/s3fs type fuse.s3fs (rw,nosuid,nodev,relatime,user_id=0,group_id=0)
$ sudo touch /var/s3fs/foobar
$ sudo ls /var/s3fs
foobar
$
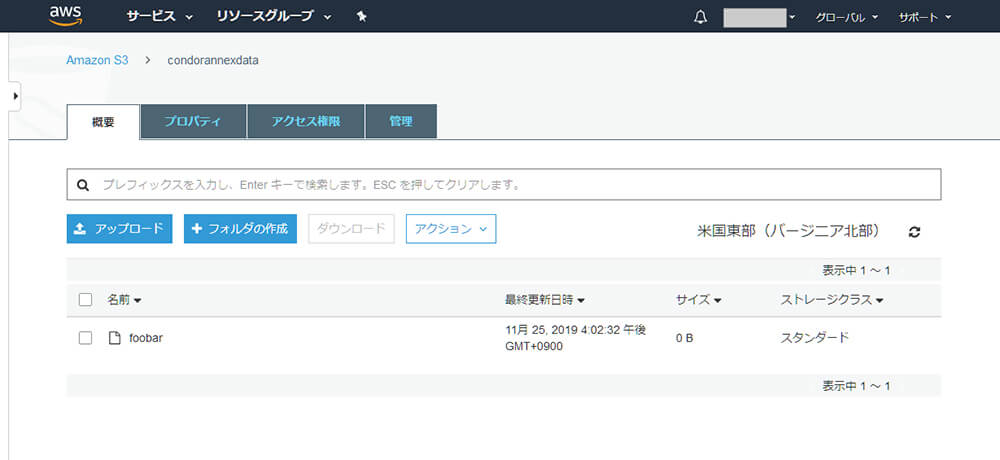
S3 Management Console上で、バケットにファイルが作成されたことも確認します。
このままでは毎回手動でマウントする必要があるので、自動的にマウントされるようにします。
$ sudo umount /var/s3fs
$ sudo mkdir /tmp/cache
$ sudo chmod 777 /tmp/cache /var/s3fs
$ sudo vi /etc/fstab
$ sudo mount -a
$ ls /var/s3fs/
foobar
$
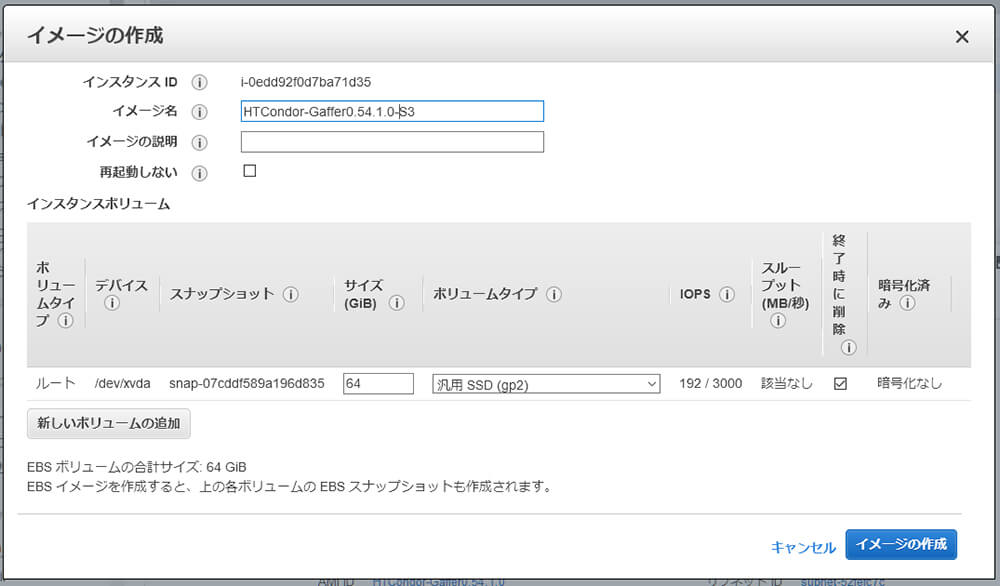
これでインスタンス側の設定は一通り終わったので、イメージを保存します。
ローカル環境からのマウント
S3バケットへの接続はEC2インスタンスに限らず、ローカル環境からも行うことができます。これは先ほど行なったのと同じく、s3fsを使用します。
AWSのインスタンスと同様、ローカル環境で/var/s3fsにマウントして確認します。
[chiyama@docker s3fs-fuse]$ ls /var/s3fs
foobar
[chiyama@docker s3fs-fuse]$
先ほど作成したfoobarが見えています。
これで、ローカル環境からAWS環境にファイルをアップロードして、AWS上でファイルを共有する手段ができました。
s3fsを使用してファイルをアップロードする方法が遅いと感じた場合はAWS DataSyncやAWS Transfer for SFTPといったソリューションがあるので、こちらを検討してみるのもいいかもしれません。
実際のところどうなのか確認してみましょう。PIXAR USDのサンプルデータ、Kitchen_setをローカル環境からs3fsでマウントしたS3 バケットに転送してみます。
$ du -sm Kitchen_set
12 Kitchen_set
$ time cp -Rp Kitchen_set /var/s3fs
real 35m23.298s
user 0m0.024s
sys 0m0.188s
$
ほほう(; ・`д・´)。12MBのファイルで35分とはなかなかシブい結果が出ましたね。これはこのままだと辛いので、別の手段を考える必要がありそうです。今回は、先ほどのAWS Transfer for SFTPを使用してみます。
[[SplitPage]]AWS SFTPサーバの構築
まずはAWS SFTPサーバを立てます。AWSマネージメントコンソールからAWS Transfer for SFTPを選び、Create serverを押します。
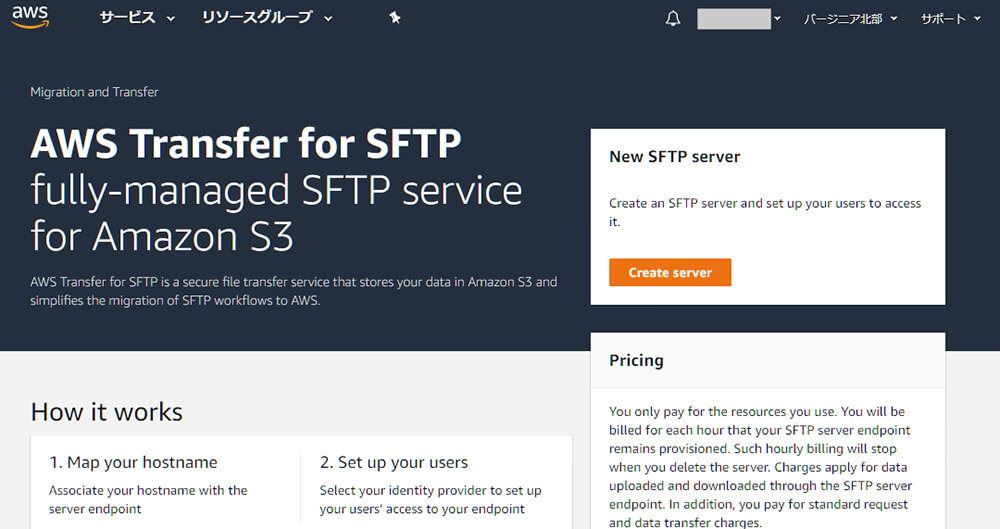
とりあえずオプションは全てデフォルトで実行します。DNSや認証関連の設定を行うので、本番運用する場合はきちんと設定する必要があります。
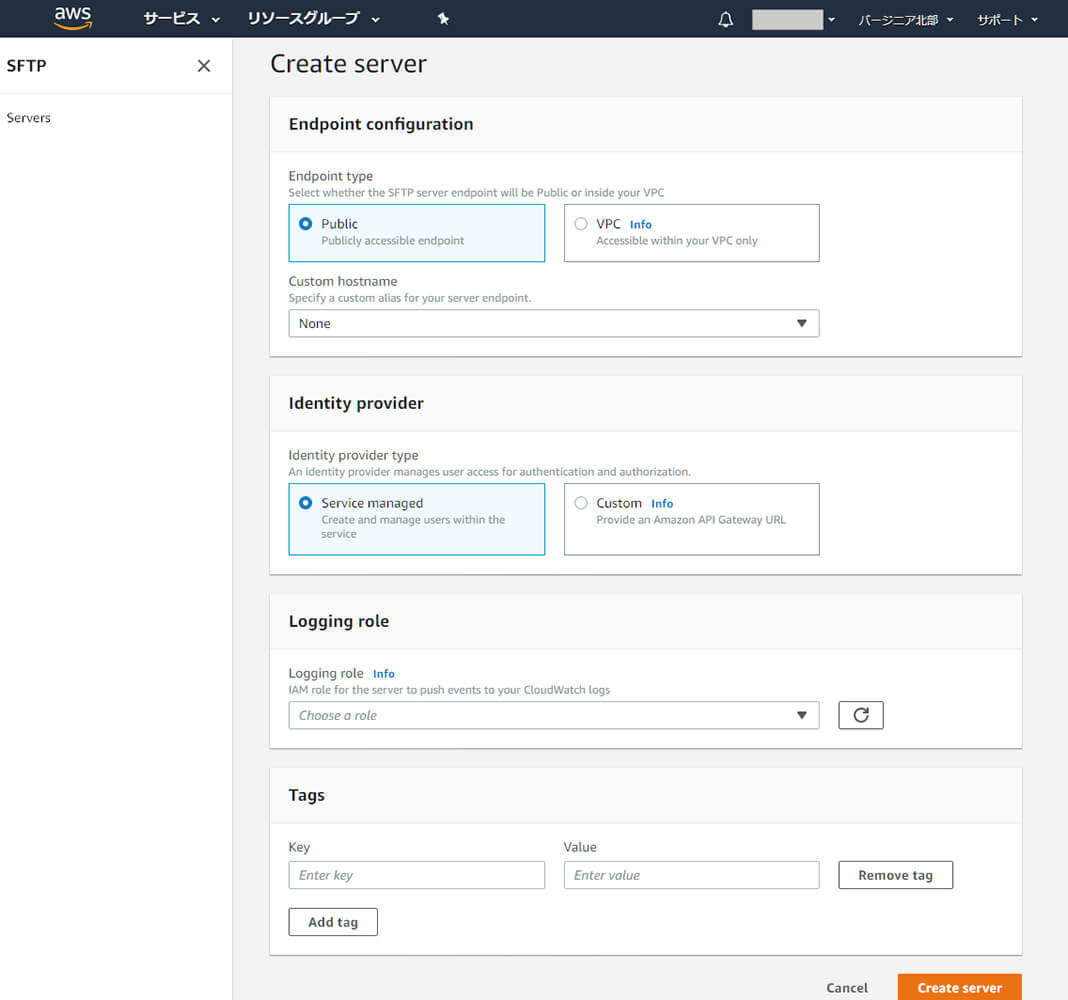
これでCreate serverを押すとサーバが立ち上がります。なんて簡単!!
少し待つと、StateがOnlineに変わります。
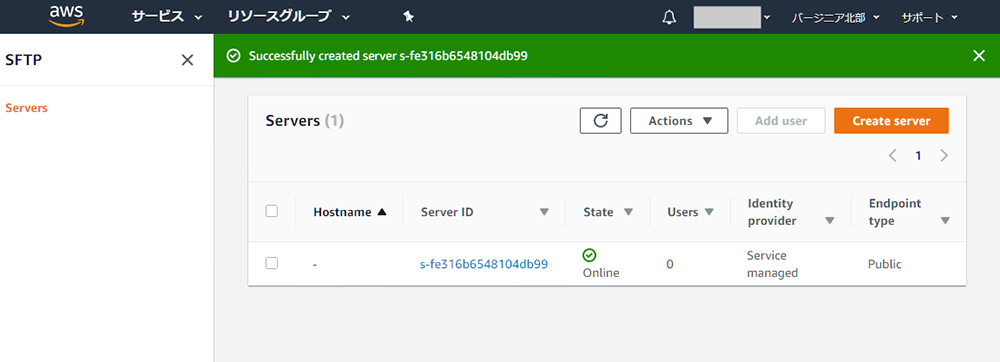
ユーザーの登録
続いて、ユーザーの登録をします。Server IDをクリックするとサーバの詳細が表示されるので、Add userをクリックします。ユーザー名はインスタンス同様ec2-userとしておきます。
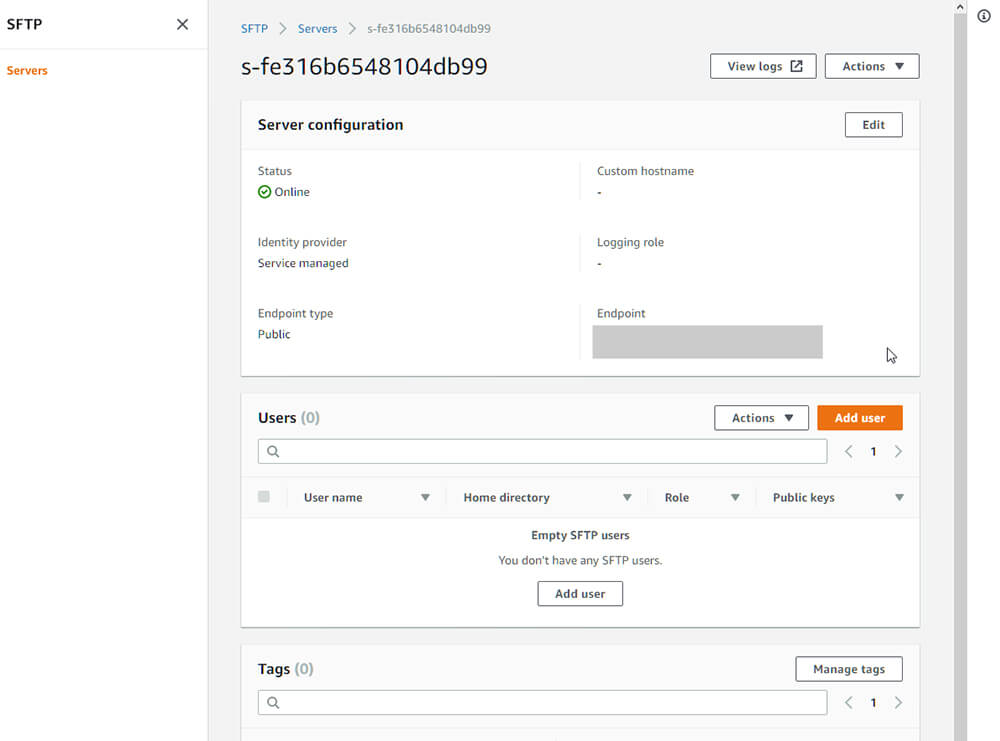
さらに各種権限の設定を行う必要があります。ここは、SFTPのためのIAMポリシーおよびロールの作成を参考に作業を進めます。一見ゴチャゴチャしていますが、このドキュメントの通りに進めれば簡単に設定できます。アクセス権の制限などについても記述されているので、目を通すといいでしょう。この設定をうまく使うことで、ユーザー毎にアクセスするディレクトリを変えるということもできるようになります。今回はフルアクセス可能な状態にし、ポリシーの名前はAWS-SFTP-S3、ロールの名前はAWS-SFTP-S3-Roleとしました。
ポリシーとロールの作成ができたら、ユーザー登録画面に戻ってそれぞれを指定します。
Home directoryは先ほど作成したS3バケット、condorannexdataを指定します。
SSH Public Keyはインスタンスに接続するために使用しているものがあるはずなので、それをそのまま使います。
ここまで入力できたらユーザーの作成をします。
AWS SFTPサーバに接続してみる
さて、準備ができたのでSFTP経由でS3バケットにアクセスしてみます。
ホスト名はEndpoint名、ユーザー名は先ほど作成したec2-userです。
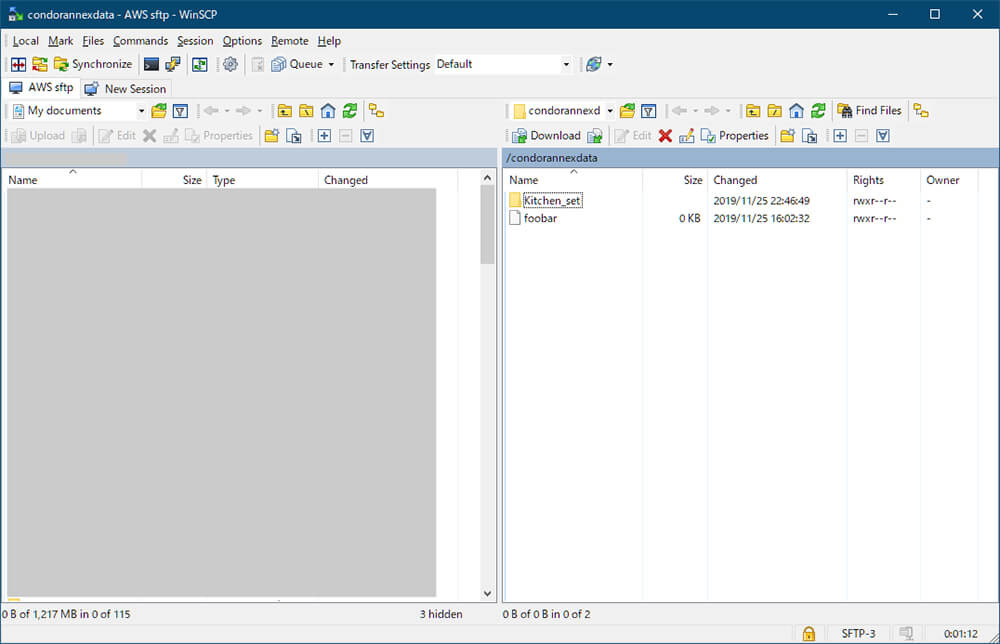
つながりました!!事前に作成したfoobarファイルやKitchen_setも見えています。
sftpを使用したファイルのアップロードも試してみます。ファイルアップロード時に転送先のファイルのタイムスタンプを転送元のものと同じにする機能はサポートされていないようなので、クライアントによっては明示的にオフにしておかないとエラーになるようです。WinSCPではPreserve timestampをオフにすることで解決できました。
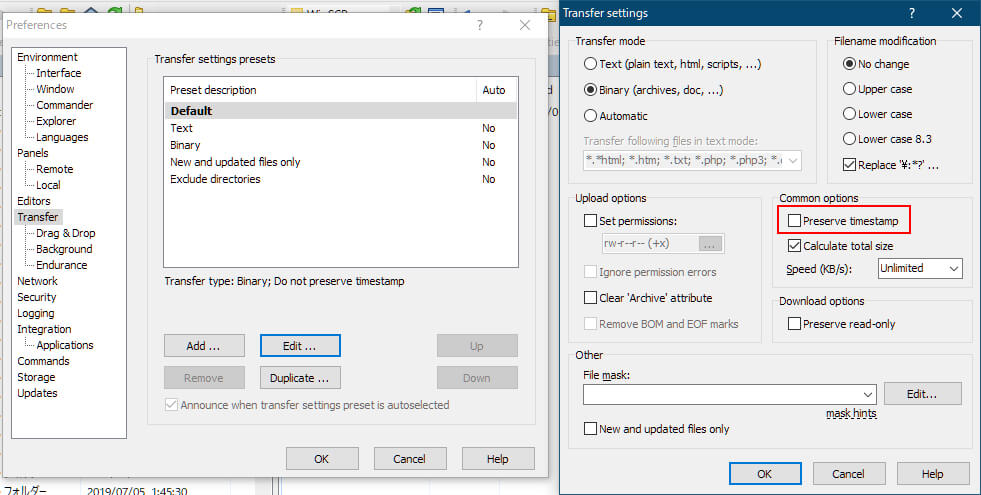
先ほどと同じKitchen_setを転送したところ、4分30秒ほどで完了しました。まだかなり遅いですが、かなり改善されています。参考までに、ひとつで22MBのファイルを転送したら20秒ほどで終わったので、細かいファイルを個別に送るのにはあまり向いていなさそうということはわかります。実際に使用する際はアーカイブファイルにまとめてから転送し、転送先で展開するような処理をした方がいいかもしれないです。
ちなみに、S3→EC2インスタンスのコピーも試してみました。
[ec2-user@ip-172-31-92-46 ~]$ time cp -Rp /var/s3fs/Kitchen_set .
real 0m15.673s
user 0m0.012s
sys 0m0.040s
[ec2-user@ip-172-31-92-46 ~]$
細かいファイルが多くあることを考えれば、決して速くはないですが驚異的に遅いということもなさそうです。
次回予告
これでかなりクラウド側の環境を整えることができました。次回からはこの環境の上で各種ジョブを実行できる環境をつくっていきます。本連載のクラウド編も佳境ですので引き続きよろしくおねがいします!!
そして、クラウド編終了後の次のネタも絶賛大募集中なのです!!
第19回の公開は、2019年12月を予定しております。
プロフィール













