みなさんこんにちは。今年も早いものでもう4月です。原稿執筆時点ではまだまだ桜は咲いていないですが、記事が公開される頃には満開で皆さんお花見三昧な日々を過ごしているでしょうか。年に一度のこの季節、桜の花びらの落ちる速度が本当に秒速5センチメートルなのか議論に花を咲かせましょう。
TEXT_痴山紘史 / Hiroshi Chiyama(日本CGサービス)
EDIT_尾形美幸 / Miyuki Ogata(CGWORLD)
Logstashによるデータの収集
前回の記事で、grafanaやElasticsearchにデータを格納する際に以下のながれをとっていました。
・CPU使用率をgrafanaに登録:sarコマンド → head,tail,awkで整形 → ncでgrafanaに格納
・記事をElasticsearchに登録:記事をコピー → エディタでJSON形式のデータを作成 → curlでElasticsearchに格納
ここで、CPU使用率をElasticsearchに格納したくなった場合にはどうすればいいでしょうか。このままでは、新たに
・CPU使用率をElasticsearchに登録:sarコマンド → JSON形式のデータを作成 → curlでElasticsearchに格納
という処理を用意しなければいけなくなってしまいます。
このように、情報源と格納先の組み合わせごとに個別の処理を行なってしまうと、それぞれのケースごとにツールを用意しなければいけなくなってしまいます。情報源が10種類、格納先が3種類あれば30通りの組み合わせについてそれぞれ微妙に異なるツールが存在することになります。
さらにレンダーサーバのように、大量の計算機から定期的に情報収集を行うようなしくみも必要になってくると、どんどん複雑になっていきます。これは悪夢です。
そこで、このような情報の収集・整形・格納を行うためのしくみをまとめたのがLogstashです。
Logstashで行う処理は、Logstashのインストールと起動時に作成した/root/pipeline以下に定義します。Dockerコンテナ起動時に/root/pipelineを/usr/share/logstash/pipelineとしてマウントしていますね。
Logstash内ではデータの取得・編集・整形・出力をそれぞれinput、filter、codec、outputと呼びます。これらの処理をプラグインとして実装し、プラグインの組み合わせで全体の処理を定義できるようになっています。
まずはシンプルな例で、標準入力の内容を取得して整形後、標準出力に出力するようにしてみます。
[root@docker pipeline]# cat /root/pipeline/stdinout.conf
input {
stdin {}
}
output {
stdout {}
}
[root@docker pipeline]#
先ほど立ち上げたLogstashは、設定ファイルがひとつもないため終了してしまっているかもしれません。その場合は立ち上げ直します。
$ sudo docker run -d --name logstash --rm -it -v /root/pipeline/:/usr/share/logstash/pipeline/ docker.elastic.co/logstash/logstash:6.6.0
コンテナにアタッチします。
[chiyama@docker ~]$ sudo docker attach logstash
Sending Logstash logs to /usr/share/logstash/logs which is now configured via log4j2.properties
[2019-02-18T05:28:47,858][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.queue", :path=>"/usr/share/logstash/data/queue"}
[2019-02-18T05:28:47,867][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/share/logstash/data/dead_letter_queue"}
(中略)
[2019-02-18T05:35:01,130][ERROR][logstash.licensechecker.licensereader] Unable to retrieve license information from license server {:message=>"No Available connections"}
[2019-02-18T05:35:01,187][WARN ][logstash.licensechecker.licensereader] Attempted to resurrect connection to dead ES instance, but got an error. {:url=>"http://elasticsearch:9200/", :error_type=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError, :error=>"Elasticsearch Unreachable: [http://elasticsearch:9200/][Manticore::ResolutionFailure] elasticsearch: Name or service not known"}
foo ←キーボードから入力した文字列
{
"message" => "foo",
"@version" => "1",
"host" => "9bab5036365a",
"@timestamp" => 2019-02-18T05:35:13.796Z
}
fooと入力したことがLogstashに検出され、整形された結果が出力されました。では、sarの実行結果を標準出力に出力するようにしてみます。
標準で使用できるinput pluginは公式ドキュメントにまとまっているので眺めてみます。リストアップされているものを見るだけで夢が広がりますね。
コマンドの実行結果を取得するのはexec pluginが使用できそうです。
ここでハタと気づいたのですが、sarはLogstashコンテナにインストールされていないのでそのままで使うことはできません。インストールをして使うか別の方法を用いるか迷ったのですが、今回は別の方法を用いるようにします。同様な情報を取得するのにvmstatコマンドがあります。
[chiyama@docker ~]$ vmstat 1 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 3962624 7936076 96 5575208 0 0 0 4 0 1 4 7 90 0 0
1 0 3962624 7934712 96 5575212 0 0 0 16 3954 8385 5 13 81 0 0
[chiyama@docker ~]$
vmstatのusが、ユーザープロセスがCPUを使用した割合になります。これを使用します。
Logstash用設定ファイルを作成します。
[root@docker pipeline]# cat /root/pipeline/vmstat.conf
input {
exec {
command => "vmstat 1 2 | tail -n 1"
interval => 10
}
}
output {
stdout {}
}
Logstashを再起動します。
[chiyama@docker ~]$ sudo docker restart logstash
[sudo] password for chiyama:
logstash
[chiyama@docker ~]$ sudo docker attach logstash
Sending Logstash logs to /usr/share/logstash/logs which is now configured via log4j2.properties
[2019-02-18T06:54:33,792][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.6.0"}
[2019-02-18T06:54:34,438][WARN ][logstash.monitoringextension.pipelineregisterhook] xpack.monitoring.enabled has not been defined, but found elasticsearch configuration. Please explicitly set `xpack.monitoring.enabled: true` in logstash.yml
(中略)
The stdin plugin is now waiting for input:
[2019-02-18T06:54:41,440][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2019-02-18T06:54:41,639][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
{
"message" => " 2 0 3962624 7861804 96 5583916 0 0 0 0 5132 9309 21 14 65 0 0\n",
"@version" => "1",
"@timestamp" => 2019-02-18T06:54:42.475Z,
"command" => "vmstat 1 2 | tail -n 1",
"host" => "16aca7f9a9e7"
}
これで、十秒ごとにvmstatが実行されて標準出力に情報が出力されるようになりました。
このままではメトリクスとして扱いづらいので、データを整形します。これはfilter pluginの役割です。こちらも公式ドキュメントを眺めながら作戦を練ります。今回はcsv filter pluginが使用できそうです。
[root@docker pipeline]# cat /root/pipeline/vmstat.conf
input {
exec {
command => "vmstat 1 2 | tail -n 1"
interval => 10
}
}
filter {
csv {
separator => ' '
columns => ['r', 'b', 'swpd', 'free', 'buff', 'cache', 'si', 'so', 'bi', 'bo', 'in', 'cs', 'us', 'sy', 'id', 'wa', 'st']
convert => {
"r" => "integer"
"b" => "integer"
"swpd" => "integer"
"free" => "integer"
"buff" => "integer"
"cache" => "integer"
"si" => "integer"
"so" => "integer"
"bi" => "integer"
"bo" => "integer"
"in" => "integer"
"cs" => "integer"
"us" => "integer"
"sy" => "integer"
"id" => "integer"
"wa" => "integer"
"st" => "integer"
}
}
}
output {
stdout {}
}
[root@docker pipeline]#
filterを定義したのでLogstashを再起動します。
[chiyama@docker ~]$ sudo docker restart logstash
logstash
[chiyama@docker ~]$ sudo docker attach logstash
Sending Logstash logs to /usr/share/logstash/logs which is now configured via log4j2.properties
[2019-02-18T07:16:51,844][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.6.0"}
(中略)
[2019-02-18T07:17:00,311][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2019-02-18T07:17:00,561][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
{
"b" => 0,
"buff" => 96,
"id" => 69,
"message" => " 3 0 3962624 8701292 96 5629096 0 0 0 20 4895 9473 17 14 69 0 0\n",
"host" => "16aca7f9a9e7",
"bi" => 0,
"@timestamp" => 2019-02-18T07:17:01.343Z,
"@version" => "1",
"so" => 0,
"cs" => 9473,
"wa" => 0,
"us" => 17,
"sy" => 14,
"in" => 4895,
"st" => 0,
"command" => "vmstat 1 2 | tail -n 1",
"free" => 8701292,
"si" => 0,
"swpd" => 3962624,
"cache" => 5629096,
"bo" => 20,
"r" => 3
}
filterで定義したヘッダ名に整数値として値が格納されています。また、vmstatの情報を使用しているため、CPUの使用率だけではなくそのほかのシステムの情報も一緒に取得できています。
では、この結果をElasticsearchに登録してみます。公式ドキュメントを見るとElasticsearch用のoutput pluginが存在します。ありがたやありがたや~。
まずはindexを作成します。前回は日本語対応をするために設定用JSONファイルを用意しましたが、今回はその必要もないので簡単です。
[chiyama@docker ~]$ curl -XPUT 'docker.XXX.XXX.XXX:9200/vmstat'
{"acknowledged":true,"shards_acknowledged":true,"index":"vmstat"}[chiyama@docker ~]$
outputにElasticsearchを指定します............が、ここでちょっと注意が必要です。
これまではホストマシンや外部のマシンからDockerコンテナにアクセスするながれだったのですが、今回はDockerコンテナ内で動いているLogstashから別のDockerコンテナ内で動いているElasticsearchにアクセスする必要があります。このような場合、これまで通りホストマシン名やホストのIPアドレスを指定してアクセスすることができません。
諸々きちんと環境をつくればDockerコンテナ起動時に指定した名前でアクセスできるようになるのですが、ちょっと話が長くなってしまいそうなのでここでは割愛してDockerコンテナのIPアドレスでアクセスするようにしてしまいます。Dockerコンテナ・ネットワークについてのざっくりとした内容は記事の最後に軽くご説明します。
DockerコンテナのIPアドレスを確認するにはdocker inspectを使用します。
[chiyama@docker HTCondor]$ sudo docker inspect elasticsearch --format "{{.NetworkSettings.Networks.bridge.IPAddress}}"
172.17.0.3
[chiyama@docker HTCondor]$
私の環境ではelasticsearchは172.17.0.3でした。Logstashの設定でoutputを設定します。最終的には以下のようになりました。
[root@docker pipeline]# cat /root/pipeline/vmstat.conf
input {
exec {
command => "vmstat 1 2 | tail -n 1"
interval => 10
}
}
filter {
csv {
separator => ' '
columns => ['r', 'b', 'swpd', 'free', 'buff', 'cache', 'si', 'so', 'bi', 'bo', 'in', 'cs', 'us', 'sy', 'id', 'wa', 'st']
convert => {
"r" => "integer"
"b" => "integer"
"swpd" => "integer"
"free" => "integer"
"buff" => "integer"
"cache" => "integer"
"si" => "integer"
"so" => "integer"
"bi" => "integer"
"bo" => "integer"
"in" => "integer"
"cs" => "integer"
"us" => "integer"
"sy" => "integer"
"id" => "integer"
"wa" => "integer"
"st" => "integer"
}
}
}
output {
elasticsearch {
hosts => ['172.17.0.3:9200']
index => "vmstat"
}
}
[root@docker pipeline]#
Logstashを再起動します。
[chiyama@docker ~]$ sudo docker restart logstash
コンテナにアタッチして、エラーが出ていなければ次に進みます。
[[SplitPage]]Grafanaでの可視化
Elasticsearchにデータが登録されているはずなので、Grafanaで可視化してみます。基本的なながれは前回graphiteのデータをGrafanaで表示したのと同じなので、サクサク進めましょう。
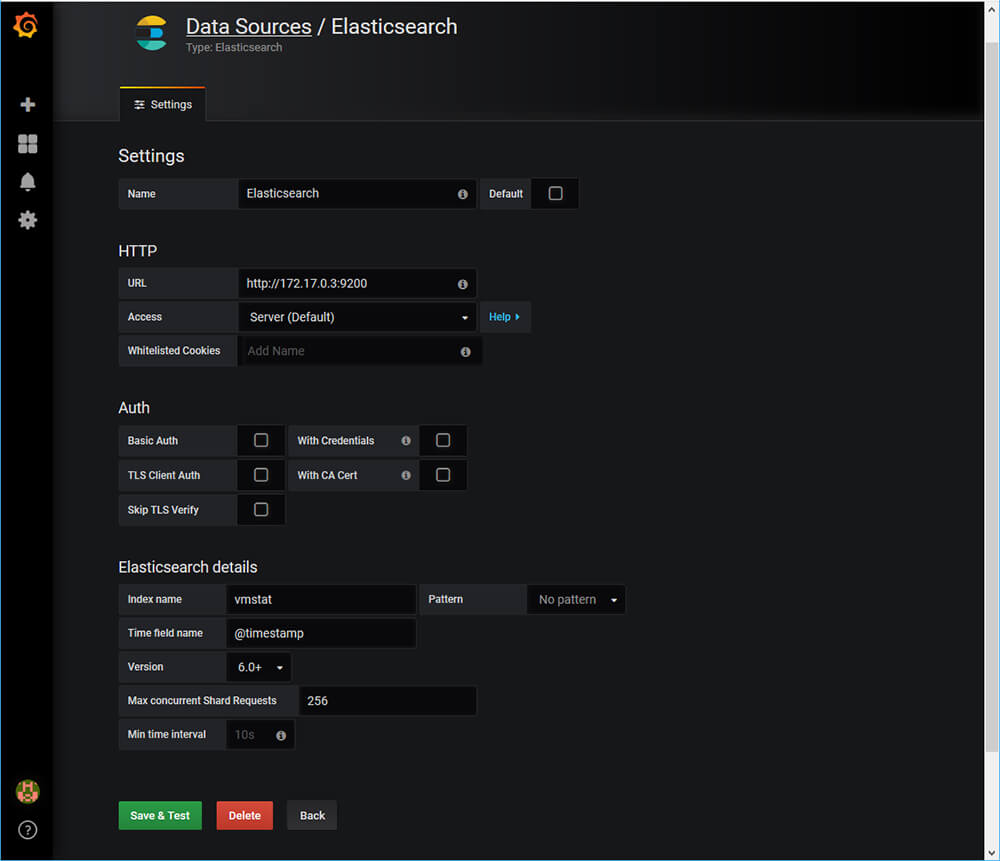
まずはData sourceを追加します。Elasticsearchを選んで、IP アドレスは先ほど確認したものを指定します。
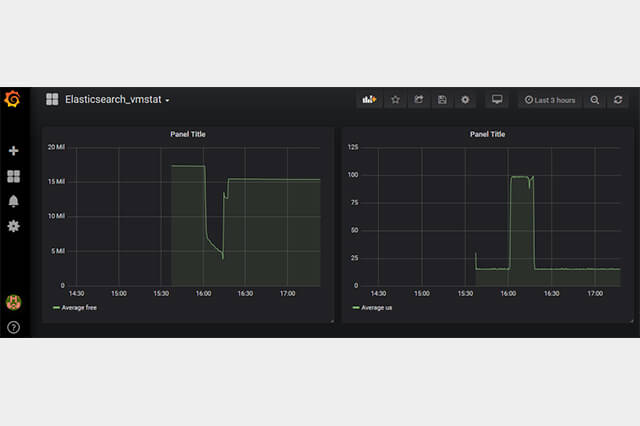
続いて新しくダッシュボードを作成してその中にパネルを追加します。グラフの編集でData SourceにElasticsearchを選び、MetricでAverage、フィールドでusを選びます。フィールドはプルダウンで選ぶことができ、Logstashのfilter pluginを使って整形した項目が対象になります。

ついでにもうひとつパネルを追加し、そちらはfreeを表示します。
これで、Logstash経由でElasticsearchに格納されたデータを使用してCPU使用率とメモリの空き具合をグラフ化することができました。
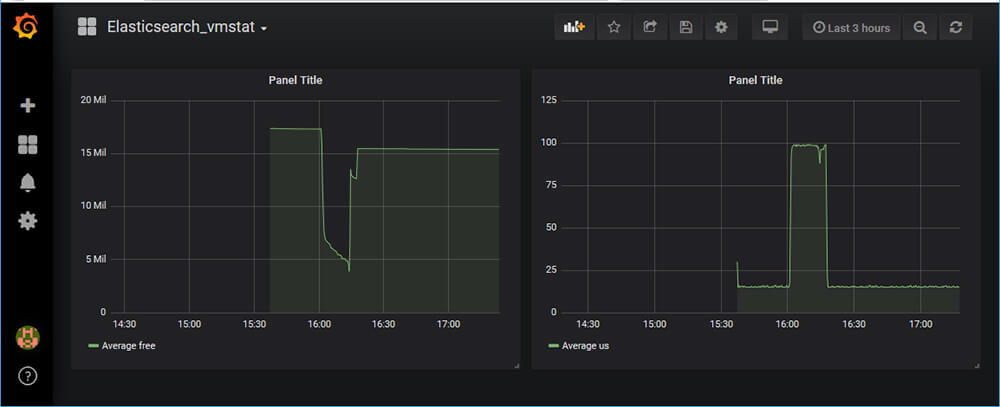
これ以外にもvmstatで取得できる情報がElasticsearchに蓄積されているので、必要な情報を簡単に可視化することができます。
Dockerコンテナ・ネットワークについて
LogstashからElasticsearchにアクセスする際に、コンテナに対して割り当てられたIPアドレスを使用してアクセスしました。何故こうする必要があったのか、何故これまではここを意識しないでブラウザからElasticsearchやGrafana、graphiteにアクセスできたのかを理解するには、Dockerコンテナ・ネットワークについて知る必要があります。
詳しくは公式ドキュメントを読んでいただくのがいいかと思いますが、英語辛い!!っていう方はちょっと古いですが有志の方が日本語訳されたドキュメントがあります。ただ、ちょっと日本語としてこなれていないなぁと感じる部分もあるので、同じバージョンの英語ドキュメントを合わせて読み進めるのが良さそうです。
また、さくらインターネットさんのさくらのナレッジで詳しく解説されているので、そちらも読んでみてください。というか、これを読めばとりあえずやりたいことは一通りできるんじゃないかと思います。
結局、ざっくり言うとDockerコンテナはデフォルトではDocker環境内につくられたbridgeという名前のネットワークに接続されるのですが、このbridgeネットワークはDNSが有効になっていないのでコンテナ間ではIPアドレスを使用した接続しかできなかったということです。外部から接続する場合は起動時に-pオプションでホスト側のポートをコンテナ側のポートにつなげているため、ホスト側に接続すれば良かったということになります。
次回予告
長かったですがこれでベースになるシステムを一通り体験することができました。次回はいよいよ本命・Fifemonの環境構築を行なっていきます。
第12回の公開は、2019年5月を予定しております。
プロフィール