みなさんこんにちは。本連載でHTCondorをご紹介しているのに刺激されたのか、GoogleとSony Pictures Imageworksがレンダーファーム管理システムOpenCueをオープンソースとして公開しました。記事執筆時点でもWikiにはインストールやCueGUIを使用したジョブの投入といった内容が詳細に書かれているため、手元に環境をつくるのも容易そうです。既に試された方もいらっしゃるのではないでしょうか。
もうひとつ気になるニュースがありました。オープンソースのコンポジットソフトウェア、NATRONが開発者を募集しています。いつからトップページにMaintainer Needed ! という表記がされていたのかは定かではないですが、Natron development status?を見た感じ、メインの開発者があまりNATRONに時間を割くことができなくなってしまっているようです。我こそは!という方は参加してみるのはいかがでしょうか。NATRONもちょっと調べると面白くて、INRIA(フランス国立情報学自動制御研究所)の研究者が開発を行い、INRIAも公式にサポートをしている(いた?)ようです。HTCondorといいNATRONといい、研究機関の中でこういう動きがあるのは面白いです。
TEXT_痴山紘史 / Hiroshi Chiyama(日本CGサービス)
EDIT_尾形美幸 / Miyuki Ogata(CGWORLD)
HTCondorのモニタリング環境の構築
今回から数回に渡ってHTCondorの各種状態をモニタリングするための環境をつくっていきます。
まずは、先行事例を調べます。
最も詳細な情報が公開されているのが Fifemonのようです。これは HTCondor Week 2016でもComprehensive Grid and Job Monitoring with Fifemonと題して発表が行われています。また、同日にCERNもMonitoring HTCondor: A commonone-stop solution?と題して発表を行なっています。
さらに、HTCondor Week 2017でもMonitoring Primer HTCondor Week 2017、Monitoring and Analytics with HTCondor Data、Monitoring HTCondor A Marriage of Open Source and Customの3セッションが設けられています。
そして、DreamWorks AnimationでもHTCondorを使用しているようで、HTCondor Week 2017でHTCondor at DreamWorksと題して発表が行われています。これは私も最近まで知らなかったのでこの資料を見つけたときは驚きました。
これらの資料を見ていると、大体の傾向がわかります。まず、HTCondor poolの状態を監視するためにはGraphiteやElasticsearchを使ってデータを蓄積し、Grafanaを使って可視化をするのが流行りで、HTCondorのモニタリングをするなら、とりあえずFifemonを使っておきましょうという感じのようです。
そのため、われわれもとりあえずこのながれに乗ってみることにします。Fifemonを使用して構築した場合、最終的なシステム構成は以下のようになります。
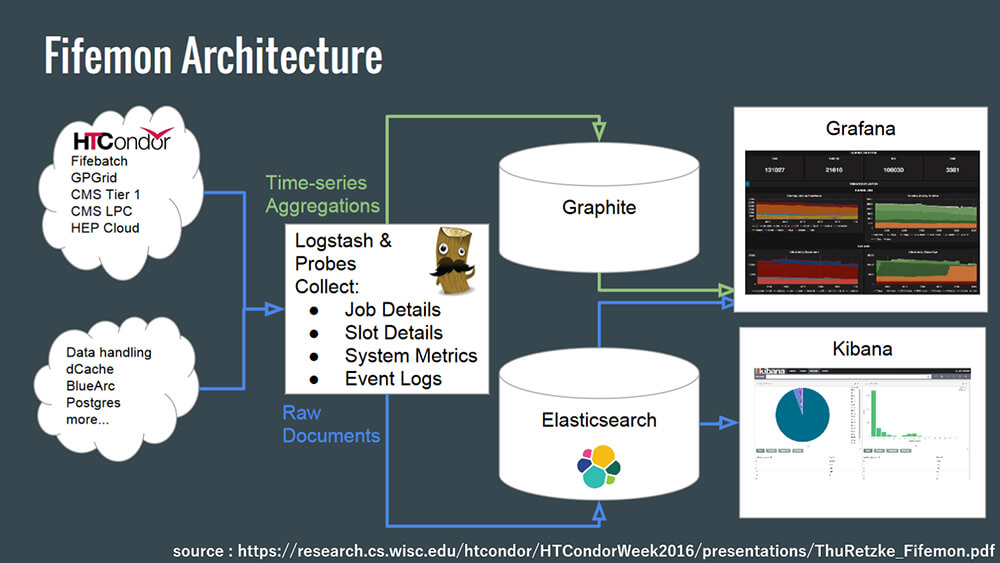
※上図はComprehensive Grid and Job Monitoring with Fifemonから引用しています。
システムの構築手順はFifemonのマニュアルに載っているので、そこを手がかりに始めます。
まず、以下のものが動作している必要があります。
・Python 2.6 or greater recommended.
・HTCondor libraries and Python bindings
research.cs.wisc.edu/htcondor/downloads/
・A running Graphit server (available in EPEL or via PIP)
graphite.readthedocs.org/en/latest/
また、ジョブとスロットの状態を監視するために以下の2つも必要です。
・A running Elasticsearch cluster
www.elastic.co/products/elasticsearch
・Logstash (tested with v2.0.0+)
www.elastic.co/downloads/logstash
PythonとHTCondorはいいでしょう。Graphite serverのインストールが必要なので、指定されたページのドキュメントを参考にインストールします。
・Graphiteのインストールと起動
ドキュメントを参考に進めます。GraphiteはDockerイメージが公開されているようなので、それを使用します。ただし、ドキュメントのままだとport 80を使用されてしまうので、9080を使用するようにします。
$ sudo docker run -d --name graphite --restart=always -p 9080:80 -p 2003-2004:2003-2004 -p 2023-2024:2023-2024 -p 8125:8125/udp -p 8126:8126 graphiteapp/graphite-statsd
ブラウザでアクセスすると、Graphiteのページが表示されます。拍子抜けするほど簡単です。
あわせてGrafanaもインストールしておきます。
ドキュメントによるとDockerイメージが用意されているのでこれを使います。
$ sudo docker run -d --name=grafana -p 3000:3000 grafana/grafana

続けてInstalling using Dockerも参考にして設定を行います。
管理者用のパスワードはconf/grafana.iniでも設定できますが、コンテナ起動時にも指定できるようなのでパスワードを指定してコンテナを起動しなおします。
$ sudo docker run -d -p 3000:3000 -e "GF_SECURITY_ADMIN_PASSWORD=secret" grafana/grafana
ユーザー名admin、パスワードsecretでログインできれば成功です。
※ もちろん、本番運用する場合はきちんと設定を行いましょう。
続いてElasticsearchのインストールと起動をします。
これもDockerイメージがあるので、ありがたく使わせていただきます。
$ sudo docker pull docker.elastic.co/elasticsearch/elasticsearch:6.6.0
$ sudo docker run -d --name elasticsearch --restart=always -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:6.6.0
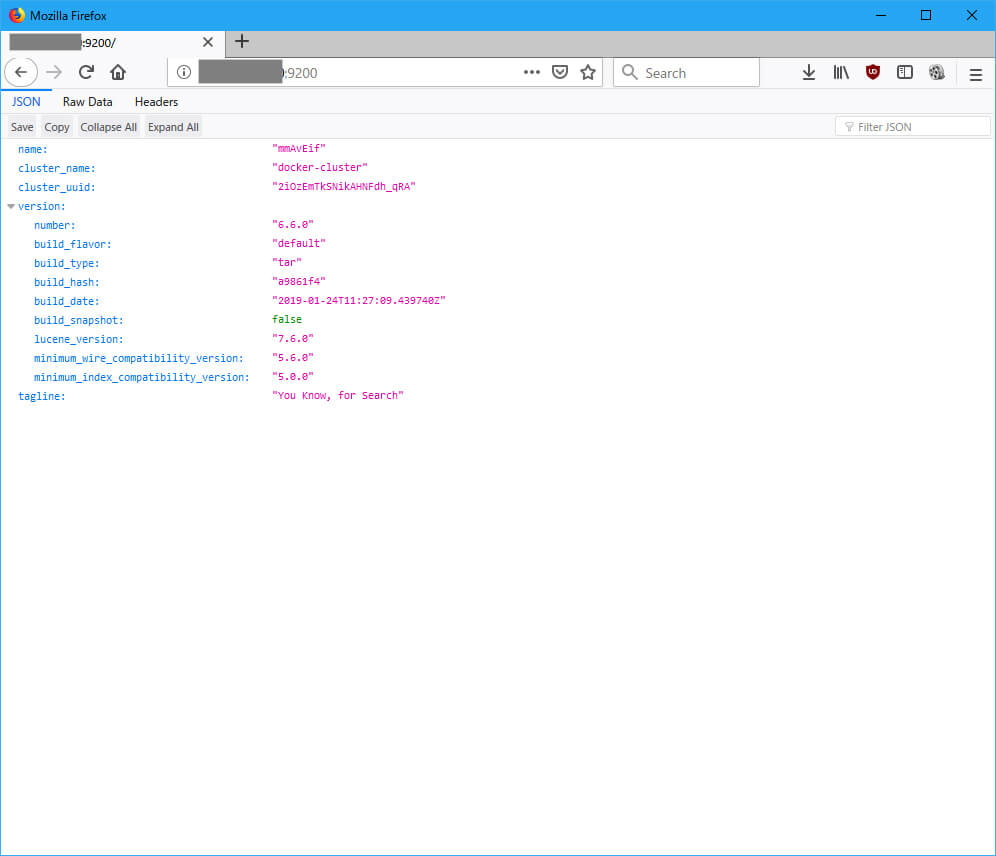
・Logstashのインストールと起動
$ sudo docker pull docker.elastic.co/logstash/logstash:6.6.0
$ sudo mkdir /root/pipeline
$ sudo docker run -d --name logstash --rm -it -v /root/pipeline/:/usr/share/logstash/pipeline/ docker.elastic.co/logstash/logstash:6.6.0
何と、これだけで環境構築に必要なソフトウェアの多くがインストールできてしまいました。昔ならこれだけで半月くらいはウンウン唸りながら試行錯誤したものなのですが、いい時代になったものです。もちろんここから業務で運用するとなるといろいろキッチリと構築する必要があり、その苦労は昔から変わらないんですけどね。それでも初手の速さは本当にありがたいです。
[[SplitPage]]使用するソフトウェアの概要確認
とりあえずインストールしてみたものの、それぞれがどのようなソフトウェアで何をするためのものなのかまだわからないです。そこで、それぞれ軽く触りながら概要を確認していきます。
・メトリクスとは?
まず、これらのツールを使用していると頻繁に出てくる「メトリクス」という言葉があります。これは、測定したデータを定量化し、分析や評価を行いやすいように加工したもののことです。具体例で言うと気温を定期的に測ったデータだったり、計算機のCPUの使用率をまとめたデータのことです。
例えば、計算機のCPU使用率をモニタリングしたいとします。Linuxで情報を取得する場合、sarを使用します。
※ sar(sysstat)はとても便利なのですが、標準ではインストールされていないため別途インストールが必要です。vmstatなど別のコマンドでも同様のことをする方法はあります。
[chiyama@docker ~]$ sar -u 1 1
Linux 3.10.0-957.1.3.el7.x86_64 (docker.XXX.XXX.XXX) 02/18/2019 _x86_64_ (8 CPU)
03:47:21 PM CPU %user %nice %system %iowait %steal %idle
03:47:22 PM all 5.24 0.37 12.61 0.00 0.00 81.77
Average: all 5.24 0.37 12.61 0.00 0.00 81.77
[chiyama@docker ~]$
これでも人間が確認するには十分ですが、定期的に観測してデータベースに登録し、後から集計するには向いていないです。そこで、得られた情報を加工して、ユーザーCPU時間だけを取得します。
[chiyama@docker ~]$ sar -u 1 1 | tail -n 1 | awk '{print $4}'
4.64
[chiyama@docker ~]$
これで、単なる4.64という数値になりましたね。このような数値を溜めておけば、グラフ化したり何か問題があったときに警告を出すことも簡単にできます。
・Graphiteの概要
Graphiteはメトリクスを蓄積・グラフ化するためのソフトウェアです。
メトリクスを蓄積する方法はいろいろありますが、最も簡単なのはソケット経由でGraphiteにデータを送る方法です。
先ほど取得したユーザーCPU時間の情報を1秒ごとに送る場合、以下のようになります。
[chiyama@docker ~]$ while true; do sar -u 1 1 | tail -n 1 | awk '{printf "user_cpu:%s|c\n", $4}' | nc -w 1 -u 127.0.0.1 8125; done
このコマンドを実行しながら、前回行なったHTCondor上でのレンダリング処理を実行してみます。
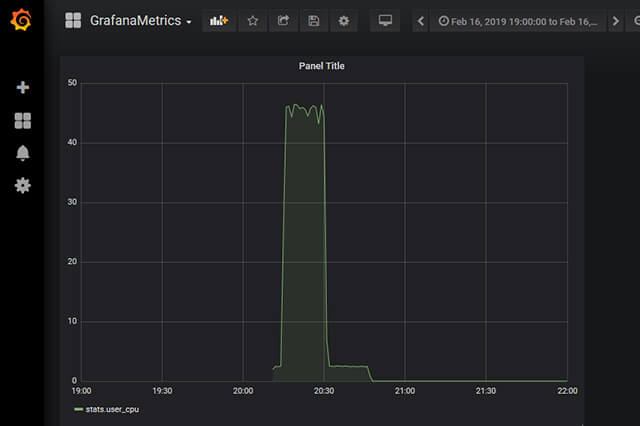
結果をGraphiteの画面で確認します。Metricsからstats/user_cpuを選ぶと以下のグラフが表示されます。
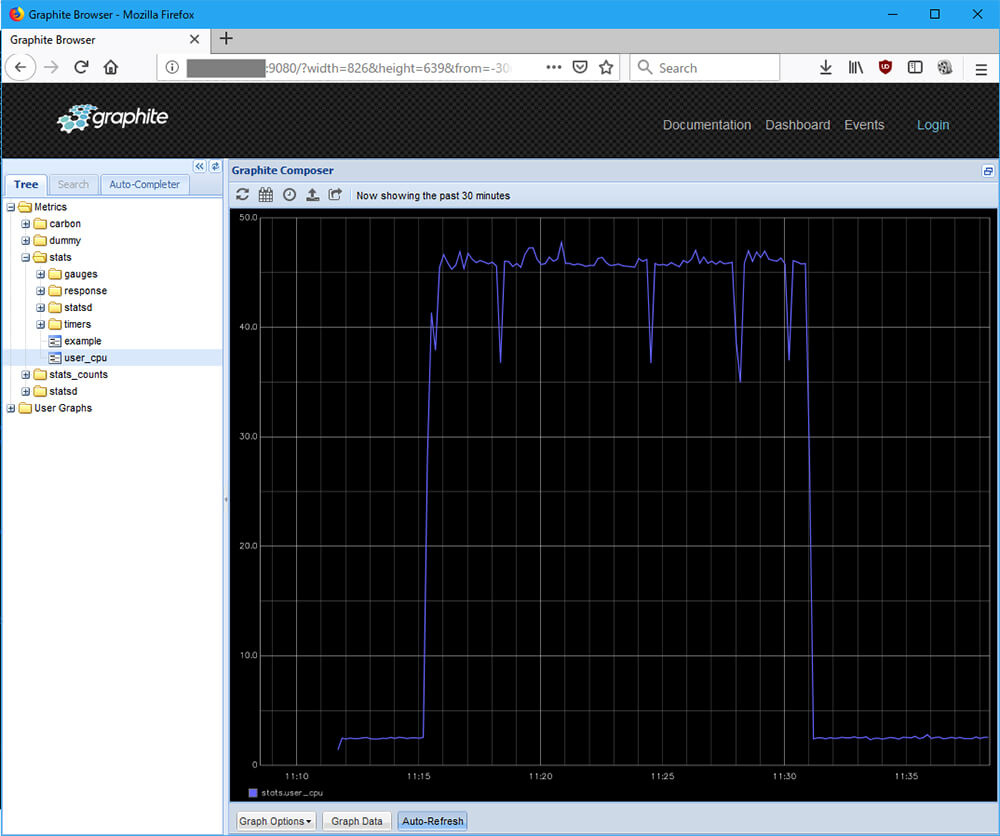
見ての通り、レンダリング中に値が高くなっていることがわかります。このようにして、Graphiteを用いることで簡単にメトリクスの蓄積とグラフ化を行うことができます。
・Grafanaの概要
Graphiteに限らず、各種バックエンドに蓄積されたメトリクスをイケてる感じに可視化してくれるのがGrafanaです。先ほど収集したGraphiteのデータをGrafanaで可視化してみます。
以降はGrafanaにログイン済であることが前提になります。
まず、Data SourcesとしてGraphiteを登録します。
Choose data source typeからGraphiteを選びます。

Graphiteの設定画面になるので、URLを入力(今回の場合、9080番ポートでアクセスできるようにしているのでそれも指定しています)し、AccessはBrowserを指定します。
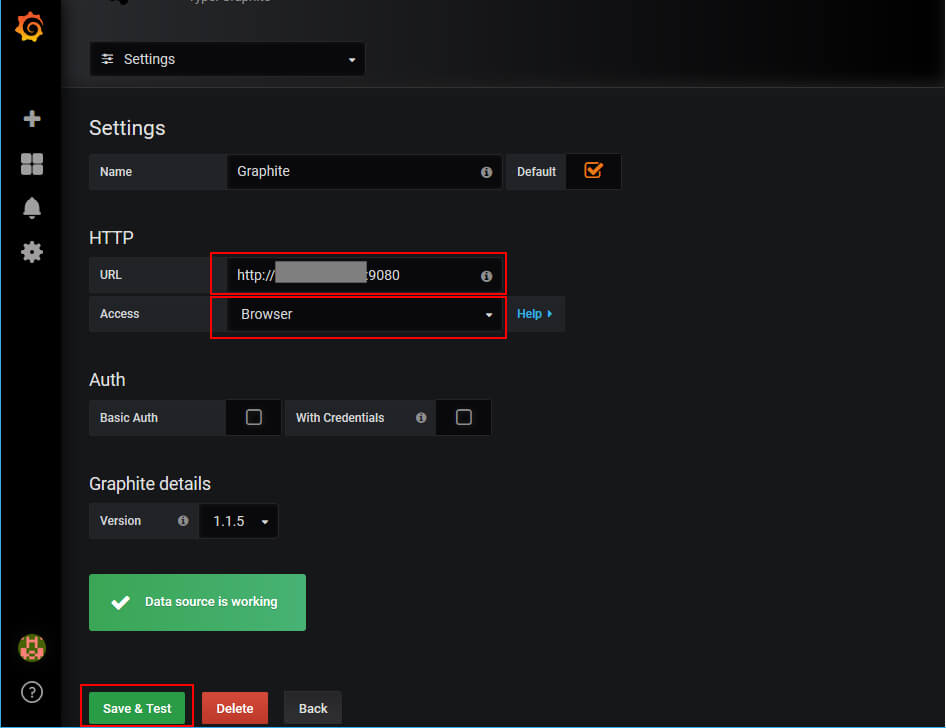
これでGrafanaからGraphiteの情報にアクセスする準備ができました。
続いてダッシュボードを作成します。

New PanelでGraphを選びます。
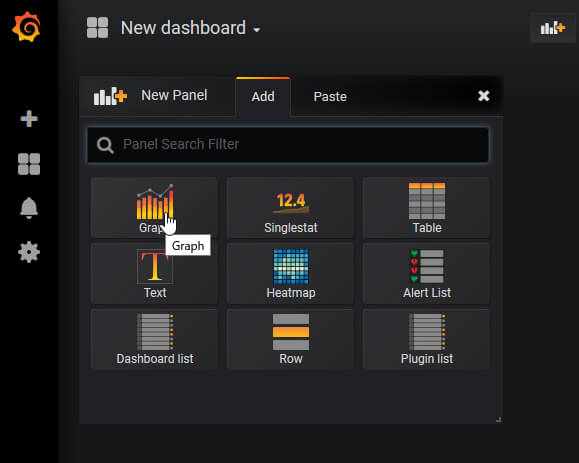
Metricsでstats.user_cpuを選びます。

Save Asで名前をつけて保存します。
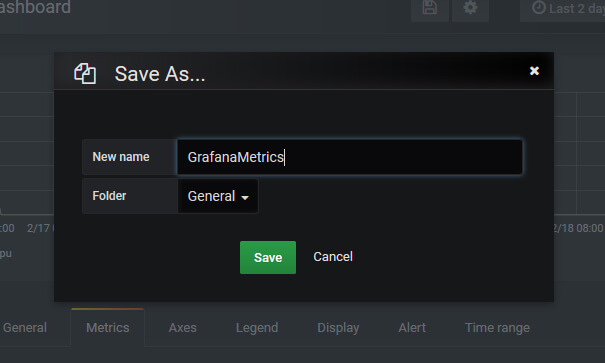
これで、Grafana上でGraphiteのデータを可視化することができました。

[[SplitPage]]
・Elasticsearchの概要
続いてElasticsearchです。ElasticsearchはElasticが開発している分散型RESTful検索/分析エンジンです。すごくざっくり言うと、大量のドキュメントから目的の単語を含むドキュメントを探すためのエンジンです。例えば、何百何千というファイルの中から目的の言葉が含まれている文章を探すためにひとつひとつ目視で確認するわけにもいかないですし、grepなどを駆使して探しても膨大な時間がかかってしまいます。そのようなケースでも、Elasticsearchを使用することで高速に検索することができます。また、REST APIを使用して簡単にアクセスできるのも魅力です。
・Elasticsearchの日本語対応
ソフトウェアにとって日本語処理はとても大変なことです。標準のElasticsearch環境では日本語文章をきちんと認識して扱うことができません。そこで、Japanese (kuromoji) Analysis Plugin(以下、kuromoji)をインストールして日本語文章をきちんと単語ごとに区切ることができるようにします。
・kuromojiのインストール
[chiyama@docker ~]$ sudo docker exec -it elasticsearch bash
[root@305ef1f43db6 elasticsearch]# elasticsearch-plugin install analysis-kuromoji
-> Downloading analysis-kuromoji from elastic
[=================================================] 100%??
-> Installed analysis-kuromoji
・Dockerコンテナを再起動
[root@305ef1f43db6 elasticsearch]# exit
exit
[chiyama@docker ~]$ sudo docker restart elasticsearch
elasticsearch
[chiyama@docker ~]$
・kuromojiを使用するindexを作成
kuromojiを使用するようにしたindexを作成します。設定用JSONファイルを用意して、REST API経由で登録を行います。
[chiyama@docker ~]$ cat kuromoji.json
{
"settings": {
"index":{
"analysis":{
"tokenizer" : {
"kuromoji" : {
"type":"kuromoji_tokenizer",
"mode":"search"
}
},
"analyzer" : {
"default" : {
"type" : "custom",
"tokenizer" : "kuromoji_tokenizer"
}
}
}
}
}
}
[chiyama@docker ~]$ curl -H "Content-Type: application/json" -XPUT docker.XXX.XXX.XXX:9200/articles --data-binary @kuromoji.json
{"acknowledged":true,"shards_acknowledged":true,"index":"articles"}[chiyama@docker ~]$
これでkuromojiが有効になったindexが作成されました。確認してみます。
[chiyama@docker ~]$ curl -XGET http://docker.XXX.XXX.XXX:9200/articles?pretty
{
"articles" : {
"aliases" : { },
"mappings" : { },
"settings" : {
"index" : {
"number_of_shards" : "5",
"provided_name" : "articles",
"creation_date" : "1550391403665",
"analysis" : {
"analyzer" : {
"default" : {
"type" : "custom",
"tokenizer" : "kuromoji_tokenizer"
}
},
"tokenizer" : {
"kuromoji" : {
"mode" : "search",
"type" : "kuromoji_tokenizer"
}
}
},
"number_of_replicas" : "1",
"uuid" : "L5daMZdgQO6BQ4VQn0Va4w",
"version" : {
"created" : "6060099"
}
}
}
}
}
[chiyama@docker ~]$
analyzerとtokenizerにkuromoji_tokenizerが指定されています。試しに、きちんと処理ができるか確認します。
[chiyama@docker ~]$ curl -H "Content-Type: application/json" -XGET http://docker.XXX.XXX.XXX:9200/articles/_analyze?pretty -d '{"text" : "東京スカイツリー"}'
{
"tokens" : [
{
"token" : "東京",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "スカイ",
"start_offset" : 2,
"end_offset" : 5,
"type" : "word",
"position" : 1
},
{
"token" : "ツリー",
"start_offset" : 5,
"end_offset" : 8,
"type" : "word",
"position" : 2
}
]
}
[chiyama@docker ~]$
公式ドキュメントのようにユーザー辞書を用意して個別の単語を登録すれば「スカイツリー」もひとつの単語として認識されますが、今回はこれでよしとしておきます。
準備ができたので、検索用の文章を登録します。
[chiyama@docker Elasticsearch]$ cat 008.json
{
"title" : "HTCondorの概要 ",
"text" : "HTCondorは、アメリカのウィスコンシン大学で開発が行われており、ネットワーク上にある計算機の有効利用を目的としていることが特徴です。通常、シミュレーションやレンダリングといった計算はレンダーファームにある計算機に行わせますが、スタジオ内にはそれ以外にも多くの計算機が存在します。一番多いのはアーティストが使用するPCですね。これらのPCは多くの能力があるにも関わらず、夜間や昼食、会議など、人が使用していないときには待機状態になってしまいます。HTCondorは、そのような資源を有効利用することを主目的に開発されました。HTCondorの大まかな構成は下図の通りです。 "
}
[chiyama@docker Elasticsearch]$ curl -H "Content-Type: application/json" -XPUT docker.XXX.XXX.XXX:9200/articles/cgwjp/1?pretty --data-binary @008.json
{
"_index" : "articles",
"_type" : "cgwjp",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
[chiyama@docker Elasticsearch]$
検索してみます。
[chiyama@docker Elasticsearch]$ curl -H "Content-Type: application/json" -XGET docker.XXX.XXX.XXX:9200/articles/_search?pretty -d '{"query":{"match":{"text":"ウィスコンシン"}}}'
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.29191685,
"hits" : [
{
"_index" : "articles",
"_type" : "cgwjp",
"_id" : "1",
"_score" : 0.29191685,
"_source" : {
"title" : "HTCondorの概要 ",
"text" : "HTCondorは、アメリカのウィスコンシン大学で開発が行われており、ネットワーク上にある計算機の有効利用を目的としていることが特徴です。通常、シミュレーションやレンダリングといった計算はレンダーファームにある計算機に行わせますが、スタジオ内にはそれ以外にも多くの計算機が存在します。一番多いのはアーティストが使用するPCですね。これらのPCは多くの能力があるにも関わらず、夜間や昼食、会議など、人が使用していないときには待機状態になってしまいます。HTCondorは、そのような資源を有効利用することを主目的に開発されました。HTCondorの大まかな構成は下図の通りです。 "
}
}
]
}
}
[chiyama@docker Elasticsearch]$
無事に日本語も検索できています。日本語対応でちょっと準備が大変でしたが、これを応用すれば社内システムに検索エンジンを乗せることができるようになるわけです。
次回予告
ここまでで、データ処理の後半に当たるGraphite、Grafana、Easticsearchがどのようなものかという確認ができました。次回はデータ収集を効率的に行うためのツール、Logstashの解説と本命のFifemon環境の構築へと進んでいきます。
第11回の公開は、2019年4月を予定しております。
プロフィール













