みなさんこんにちは。本連載が始まって今回で丸一年になります。何だかんだで私の趣味全開な本連載にお付き合いいただきありがとうございます。色々といたらないところもありますが、引き続きよろしくお願いします。そして、ネタや原稿のタレコミは随時募集していますので是非是非いいネタがありましたら教えてください :-)
ネタと言えば以前ご紹介したOpenCueに興味をもっている方が結構いらっしゃるようで、ちょくちょく「OpenCueどうなのよ?」というお話をふられることがあります。たしかにGoogleとSPIがタッグを組んで公開したソフトウェアということでかなり期待ができ、私の直感としてはここに突撃していってもいいかなという気はします。私が若かりし頃なら真っ先にいってましたね。笑。ただ、有名なスタジオが公開した無料のソフトだからという理由で使用するのは多分あまり幸せになれないのでおススメしません。その理由は昔Blogに書いたので、読んでいただけると幸いです。
あ、OpenCueでガッツリ記事を書いていただける方がいらしたら大歓迎ですよ!!:-)
TEXT_痴山紘史 / Hiroshi Chiyama(日本CGサービス)
EDIT_尾形美幸 / Miyuki Ogata(CGWORLD)
Fifemon環境の構築
前回までで、Fifemon環境を構築するための基礎となるシステムのおさらいができました。今回は本命・Fifemon環境の構築を行なっていきます。
・Probe
まずはじめに、HTCondorの状態をgraphiteに登録するようにします。そのために、Probeの設定をします。
手順は公式ドキュメントに書いてあるので、そこを参照しながら進めます。
ProbeはPythonで書かれていて、virtualenv環境下でsupervisorを使用してデーモンとして動作するようになっています。ここはドキュメントをそのまま実行していきます。
[chiyama@docker probes]$ cd /opt
[chiyama@docker opt]$ git clone https://github.com/fifemon/probes
[chiyama@docker opt]$ cd probes
[chiyama@docker probes]$ virtualenv --system-site-packages venv
[chiyama@docker probes]$ source venv/bin/activate
(venv) [chiyama@docker probes]$ pip install supervisor influxdb
続いて設定ファイルを編集します。
[chiyama@docker probes]$ cat etc/condor-probe.cfg
[probe]
interval = 240
retries = 10
delay = 30
test = false
once = false
[graphite]
enable = true
host = localhost
port = 2004
namespace = clusters.mypool
meta_namespace = probes.condor-mypool
[influxdb]
enable = false
host = localhost
port = 8086
db = test
tags = foo:bar
[condor]
pool = XXX.XXX.XXX.XXX
post_pool_status = true
post_pool_slots = true
post_pool_glideins = false
post_pool_prio = false
post_pool_jobs = true
use_gsi_auth = false
X509_USER_CERT = ""
X509_USER_KEY = ""
[chiyama@docker probes]$
graphiteはローカルマシンのDockerコンテナ上で動いていて、condorは別の環境で動いている想定です。
・Probeで取得したメトリクスを使用できるようにする
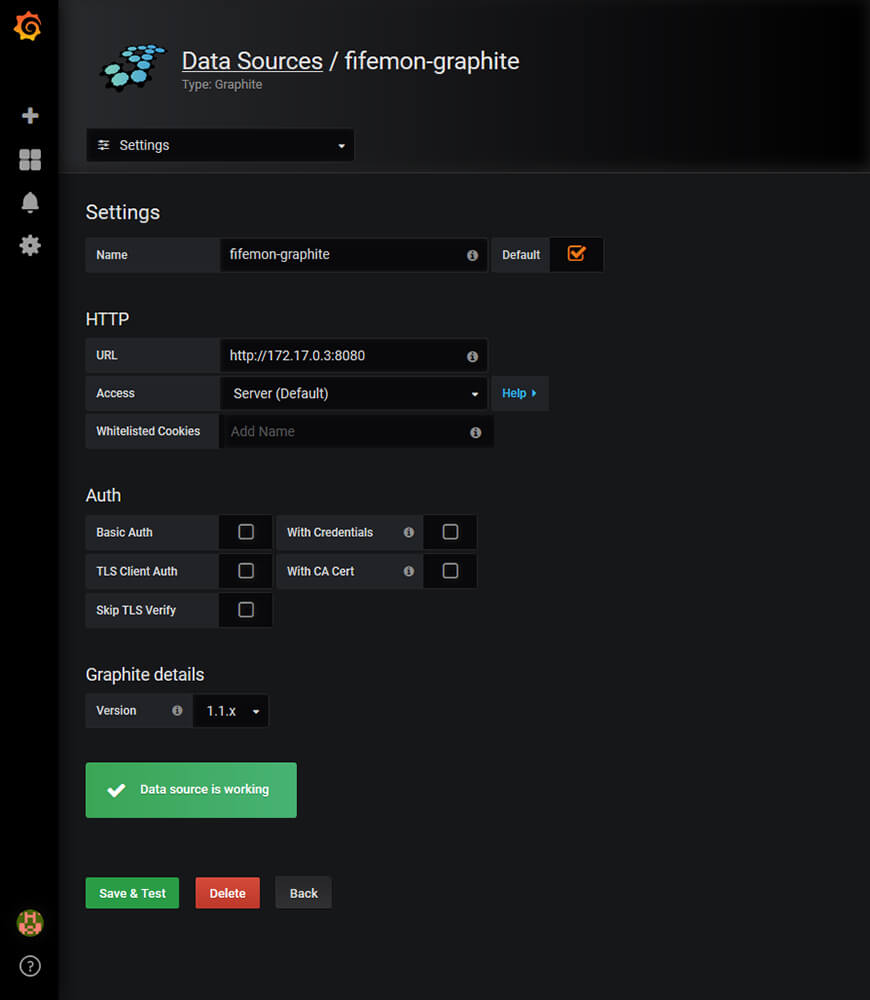
add data sourceでgraphiteを選び、名前をfifemon-graphiteにします。
※fifemonではfifemon-graphiteという名前で参照するようになっているので、必ずこの名前にします。
・Dashboard
メトリクスを表示できるように、Grafanaのダッシュボードを設定します。Fifemonではデフォルトのダッシュボードが公開されています。今回これを使用するため、Createからimportを選びます。

Upload .json Fileからファイルをアップロードするか、GitHubから直接コードをコピーアンドペーストします。
Importをクリックします。
このとき、いくつかのダッシュボードはデフォルトの設定がよくないため、クラスタの名前が正常に取得できません。

そのような場合、settingで設定を変更します。Variablesから、設定を変更したいVariableを選びます。
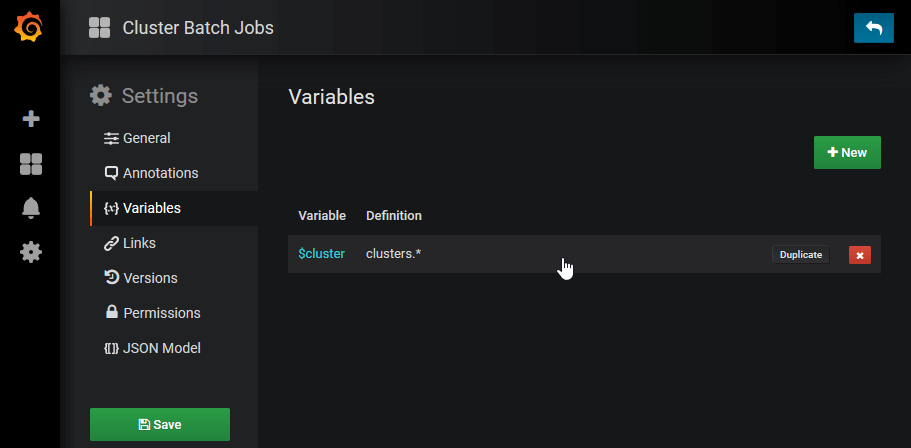
RefreshがNeverになっていたらOn Dashboard Loadに切り替えます。
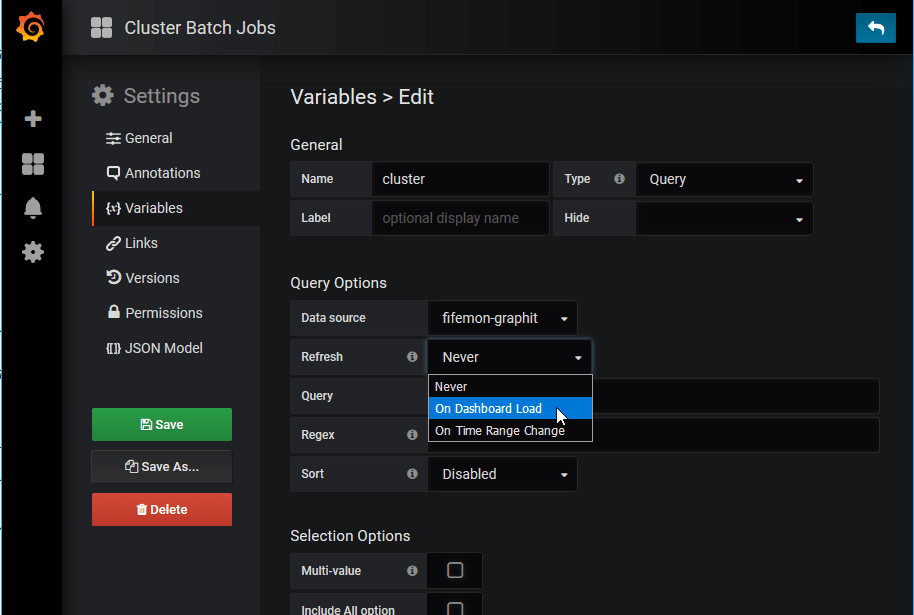
切り替えたら、UpdateとSaveをするのを忘れないようにします。
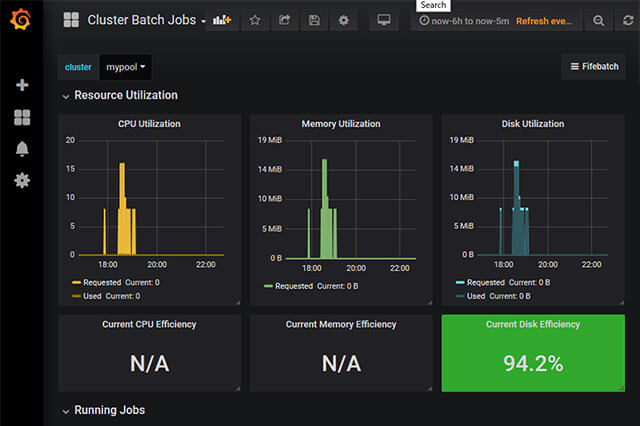
これで正しいclusterがリストアップされ、情報が表示されるようになります。最初はグラフの内容が空だったりN/Aと表示されていますが、いくつかジョブを実行して時間が経つにつれて必要な情報が集まっていき、グラフの内容も表示されるようになります。
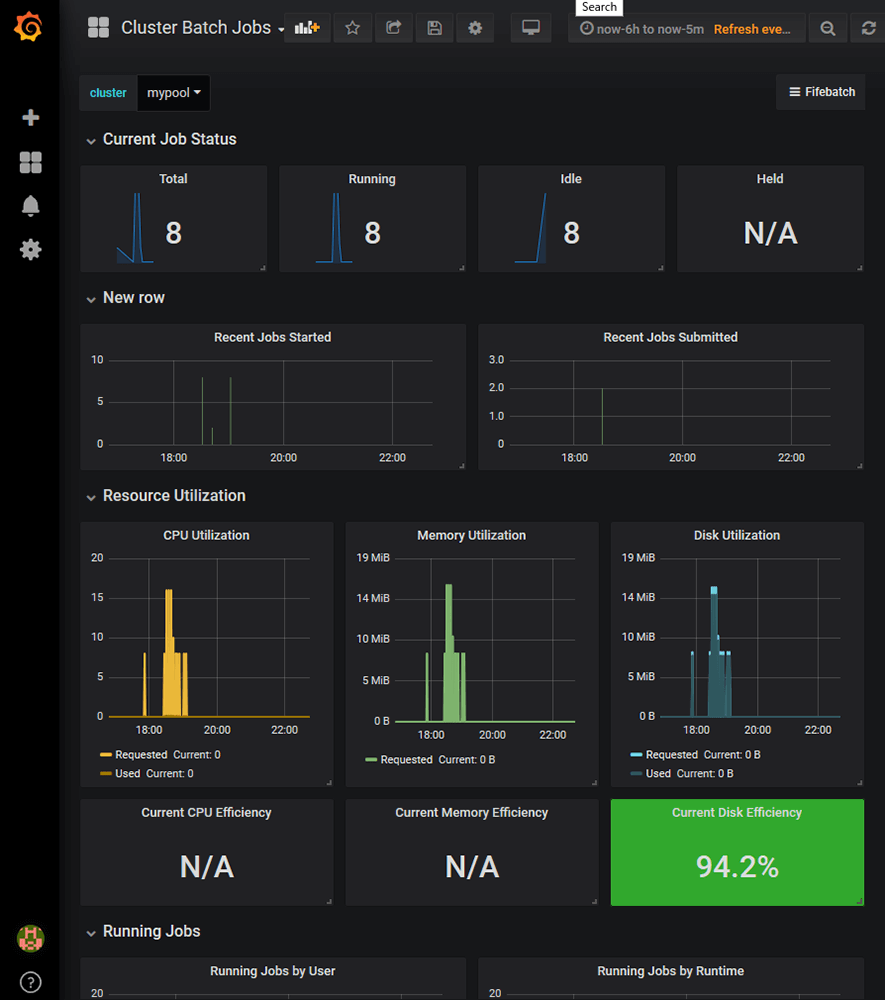
Cluster Batch Jobsでは、投入されたジョブや実行中のジョブの数、いつジョブが投入されたかといったHTCondor特有の情報がきちんと取得されていることが確認できます。ここまでくれば、後は同様の手順を全ての.jsonファイルに対して繰り返すだけです。一通り設定が終わると、公式サイトにあるスクリーンショットのようなダッシュボードが再現できます。
[[SplitPage]]・ジョブ詳細情報の取得
続いて、ジョブの詳細情報を取得できるようにします。詳細情報はlogstash経由でElasticsearchに格納して使用します。情報を取得する際にHTCondor Python bindingsを使用するので、インストールします。インストールの際は、稼働しているHTCondorとバージョンを揃えます。
[chiyama@docker probes]$ cd /opt/probes
[chiyama@docker probes]$ source venv/bin/activate
(venv) [chiyama@docker probes]$ pip install htcondor==8.7.10
etc/logstash-fifemon.confを/root/pipelineにコピーし、logstashから認識されるようにします。logstash-fifemon.confの内容も適宜書き換えます。
[root@docker pipeline]# cat logstash-fifemon.conf
input {
pipe {
command => "/opt/probes/venv/bin/python /opt/probes/bin/jobstate.py --pool XXX.XXX.XXX.XXX 2>>/opt/probes/log/jobstate.log"
codec => "json"
type => "job"
}
pipe {
command => "/opt/probes/venv/bin/python /opt/probes/bin/slotstate.py --pool XXX.XXX.XXX.XXX 2>>/opt/probes/log/slotstate.log"
codec => "json"
type => "slot"
}
}
filter {
mutate {
remove_field => ["command"]
}
}
output {
# stdout {
# codec => "rubydebug"
# }
if [type] == "job" {
elasticsearch {
hosts => ['172.17.0.2:9200']
index => "fifemon-jobs"
doc_as_upsert => true
document_id => "%{jobid}"
}
}
if [type] == "slot" {
elasticsearch {
hosts => ['172.17.0.2:9200']
index => "fifemon-slots"
doc_as_upsert => true
document_id => "%{Name}"
}
}
}
[root@docker pipeline]#
logstashを再起動します。
[root@docker pipeline]# docker restart logstash
/opt/probes/log以下にログファイルができるので、ここを確認してエラーが出ていなければ成功です。
・Graphiteでジョブ情報を可視化
GraphiteでData SourceとしてElasticsearchを追加し、設定します。logstash-fifemon.confで取得したメトリクスはfifemon-jobsとfifemon-slotsというindexに格納されます。

新規にfifemon-jobsというDashboardを作成し、New PanelでTableを追加します。
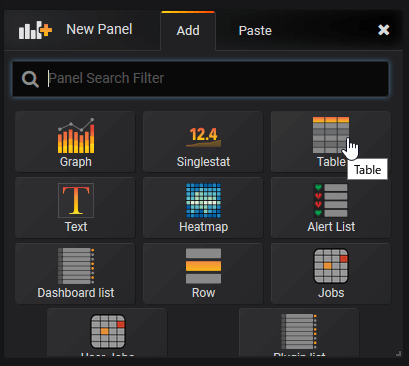
追加したパネルにElasticsearchに格納されたジョブ情報を表示してみます。


ざっくりですがジョブ情報の表示もできました。実際に運用する場合は、ここから自分なりにカスタマイズしていくことになります。ここまでくれば後はGrafanaの使い方のお話になるので、豊富にあるドキュメントを参考にしながら満足のいくまで設定をしていきます。
以上でFifemon環境構築ができました。ドキュメントがあまりないのでソースコードを読んだり勘を働かせたりと四苦八苦する部分もあったのですが、基礎になっているlogstash、graphite、Elasticsearch、Grafanaといった技術を把握した上でリポジトリの中をジーーーッと眺めれば何とかなるものです。
・ユーザー向けインターフェイスについて考える
システム管理者が使用する部分をFifemonで構築するのはとても便利で、必要な情報を可視化することができます。
それに対して、ユーザーがジョブの作成・監視を行うためのモニターとして使用するには不十分です。例えば、ジョブの停止や再起動といった操作をFifemonから行うことはできません。このような、ユーザー向けのモニタリングツールは別に用意する必要があります。この場合、完全に別のアプリケーションとして用意することも可能ですし、Graphiteのプラグインとして作成してしまうことも考えられます。Fifemonにもuserjoba-panelがあるので、これを基に開発を進めることは十分現実的かと思います。
ちなみに以前にもご紹介したDreamWorks Animationの事例では、システム管理はGrafana、ユーザーの使用するツールは別途Webアプリケーションとして用意しているようです。
次回予告
今回までで、HTCondorを使用してローカルネットワークにある計算機を管理するための仕組みをつくることができました。クライアントPC、社内サーバと進んできた社内環境構築はここで一旦一区切りとし、次回からは新章・クラウド環境を用いるための環境構築に進んでいきます。
第13回の公開は、2019年6月を予定しております。
プロフィール













