
2025年3月17日(月)から21日(金)までアメリカ・サンノゼにおいて、大手GPUメーカーNVIDIAが毎年開催する大規模カンファレンスGTC2025が行われた。このカンファレンスでは同社ジェンスン・フアンCEOによる基調講演を含め1,000を超えるセッションが行われ、最新グラフィックAIをテーマにしたセッションも多数あった。
そうしたセッションの中から、本稿ではNVIDIAのAudio2Face、Getty Imagesの画像生成に関する取り組み、そしてAI生成動画の最新制作事情を紹介する。
イベント概要
GTC2025
開催場所:カリフォルニア州 サンノゼ コンベンションセンター
開催日時:2025年3月17日(月)~21日(金)
www.nvidia.com/ja-jp/gtc
拡散モデルの採用をはじめとするAudio2Faceの5つの進化
NVIDIA・デジタルヒューマンテクノロジー部門シニアマネージャーのヤンゴン・ソル/Yeongho Seol氏と同部門シニアリサーチサイエンティストのマイケル・フアン/Michael Huang氏は、同社が提供するAudio2Faceの歴史と未来について発表した。
はじめにソル氏がAudio2Faceの概要について話した。同サービスは、音声を入力すると、その音声を話すグラフィックを生成するものである。音声を話す際には、喜びや悲しみといった感情も視覚的に表現する。グラフィック化の技法にはBlendshapeとCharacter Transferの2種類があり、特に後者は宇宙人のような人とは異なる造形のキャラクターもグラフィック化できる。
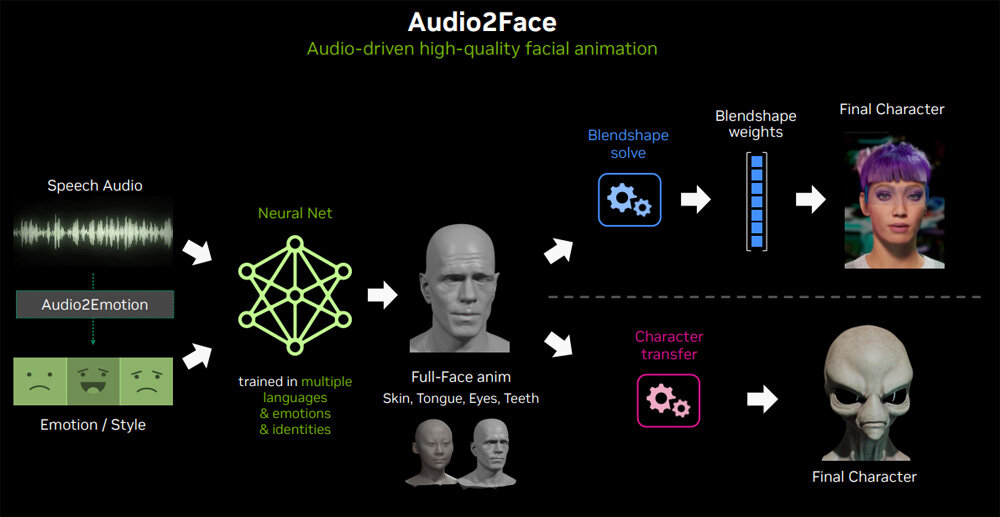
フアン氏がAudio2Faceの技術的改善について話した後、ソル氏は同サービスの進化について語った。進化の論点は5項目あり、1つめは拡散モデルの採用である。
従来のAudio2Faceでは回帰モデルを採用していたのだが、上半身がまったく動かないというような、顔以外の部分の表現に制限があった。新たに採用した拡散モデルではこうした制限が解消されたうえに、極端な表現も可能となった。この新機能は、GTC2025から数週間後にリリースされる予定だ。

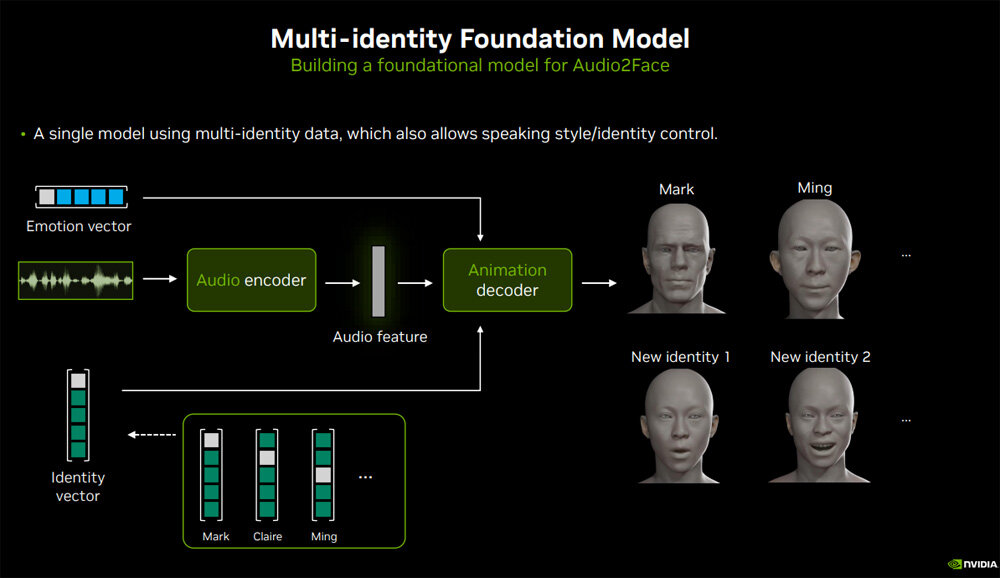
2つめは、マルチアイデンティティ基盤モデルの開発である。現状のAudio2Faceは、1つのグラフィック生成に関して1つのAIモデルを必要とする。例えば、デジタルヒューマンのMarkを生成するために1つのAIモデルが必要となり、このモデルを使って違うデジタルヒューマンのMingを生成できない。
現在開発中のマルチアイデンティティ基盤モデルを使えば、1つのAIモデルから複数のキャラクターを生成できるようになる。その結果として、例えばひとつの入力音声からMarkとMingを生成できるようになるのだ。さらに、MarkとMingの特徴を混合した新たなキャラクターも生成できるようになる。
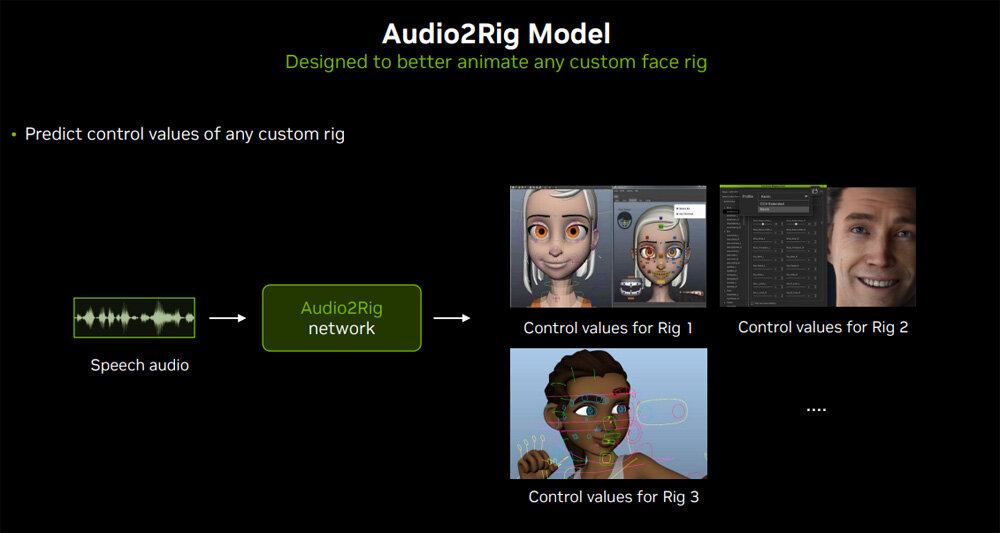
3つめは、Audio2Rigである。この機能は、音声から顔だけではなく、入力音声を反映した全身の動きを生成するものだ。ただし、同機能を活用するには、リグアニメーションに関する学習データが必要となる。
4つめは、入力情報の拡張である。具体的には笑い声や泣き声といった非言語的発声、さらには歌声を入力しても、それらにふさわしいグラフィックを生成できるようになる。こうした入力には通常の言語的発声より強い感情が含まれているため、顔だけではなく全身の動きがより重要になる。
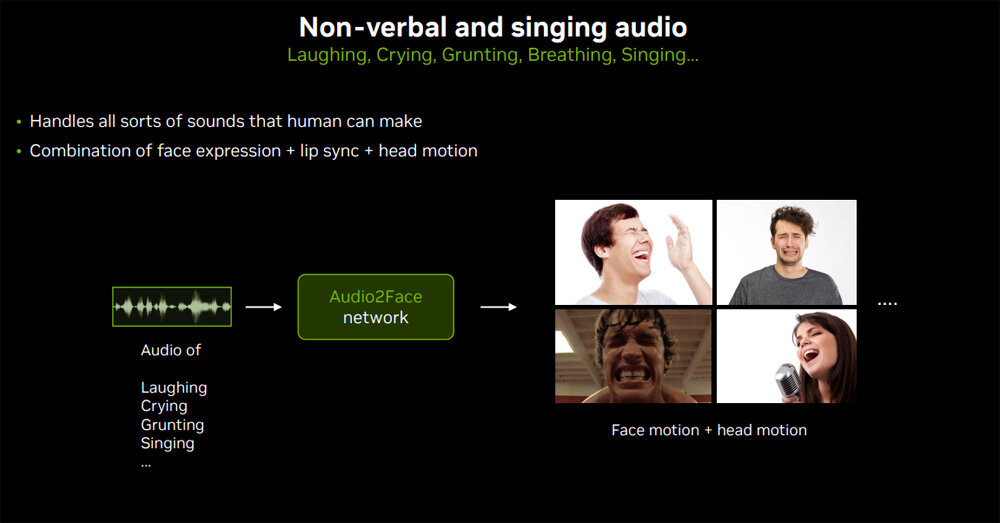
5つめは、デジタルヒューマンにおける「聴く」動作と「話す」動作の強化である。現状のAudio2Faceは入力音声に対応したグラフィックを生成しているだけで、誰かの話を黙って聴いているアイドル状態や、話を聴いてから自分の話をする移行動作に対応していない。より自然なデジタルヒューマンを生成するためには、こうした入力音声のない状態をもグラフィック化する必要がある。
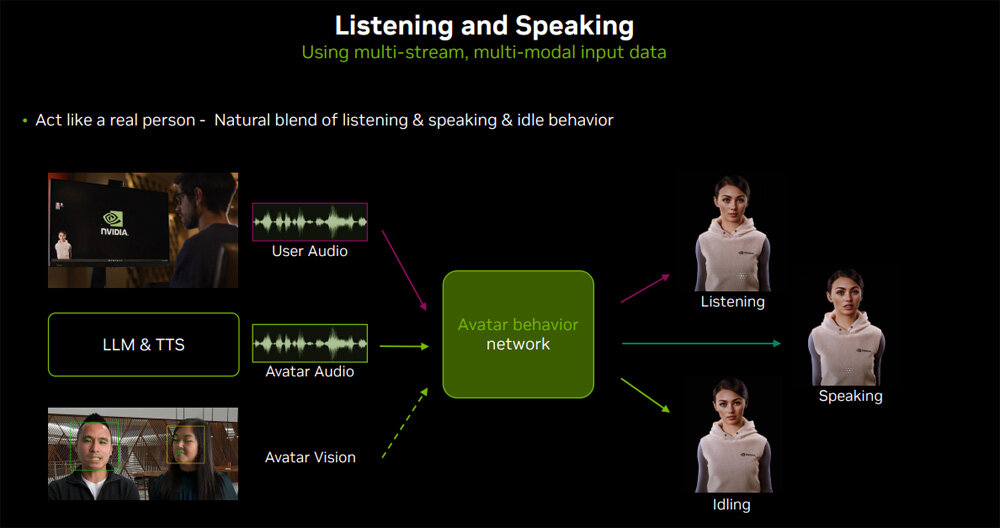
以上に紹介した進化は、拡散モデル以外は長期目標とされており、具体的なリリース時期には言及されなかった。そうは言っても、これらの進化のいくつかは今年中に公開されるかもしれない。
質量ともに豊富な画像アセットを保有するGetty Imagesの画像生成AI活用事例
画像代理店大手Getty ImagesのAI&Web 3戦略部門シニアディレクターのスーザン・ノメコス/Susan Nomecos氏は、同社の画像生成に関する取り組みについて発表した。
はじめにノメコス氏は、映画『ヴェノム:ザ・ラストダンス』のプロモーションで開発した画像生成AIについて話した。そのAIは、ペットや動物の画像をアップロードすると、それらの肌がヴェノムのようになった画像が生成されるコンテンツ「VENOMIZE MY PET」で活用されている。
以上の画像生成AIの開発にあたっては、最初にGetty Imagesが開発していた画像生成AIを10枚のヴェノムの画像によって訓練した。しかし、この訓練では高品質な画像生成が実現しなかったので、映画から厳選した画像や、映画制作に使われたヴェノムの3Dオブジェクト画像を学習データに追加した。
後者の画像には背景画像がなかったのだが、背景を設定した方が良い学習結果が得られるため、背景をAIで生成して合成した。こうして学習データを増やして再訓練することで、高品質なヴェノム画像生成AIが完成した。


Getty Imagesは、以上の事例のようなクライアントからの受注案件のほかに、自社開発した画像生成AIの可能性を探求する取り組みも行なっている。
そうした取り組みには、特定の人物に関する様々な画像を生成できるようにAIを再訓練することも含まれる。同一人物に様々なポーズやアングルで撮影した27枚の画像を使って再訓練した結果、様々な衣装やポーズの新たな人物画像が生成できた。年齢設定を変えて画像を生成しても、説得力のある画像が得られた。


ノメコス氏は、画像生成AI開発から得られた学習データ画像収集に関するノウハウについても話した。同氏によれば、学習データ画像は多ければいいというわけではなく、「機能的な(Functional)」画像と、「差別化された(Differentiated)」画像の両方をバランスよく収集するのが望ましい。
機能的な画像とは(例えば「りんご」のような)任意の被写体カテゴリを代表する画像であり、差別化された画像とは特定の被写体カテゴリのバリエーションの幅を広げるような画像である。

セッションの締めくくりとしてノメコス氏は、画像生成AI開発におけるGetty Imagesの優位性を強調した。前述のように、高品質な画像生成AIを開発するには質量ともに豊富な画像が不可欠となる。
同社は、57万人のクリエイターが参加する世界規模のコミュニティを運営しており、そのうち81,000人とは専属契約している。四半期ごとに600万の新規クリエイティブアセットを追加している同社は、最新の社会情勢を反映した画像生成AIを開発できるのだ。

来るべき”AI生成動画無料配信”時代に求められる動画制作ワークフロー
中国の大手家電メーカーTCLでジェネラルマネージャーを務めているハオファン・ワン/Haohong Wang氏は、同氏が設立した同社の動画視聴サービスTCL tv+で試みたAI生成映画の制作背景について発表した。
はじめにワン氏は、動画視聴の歴史をふり返った上で、その未来について話した。サイレント映画の劇場上映から始まった動画視聴は、ハリウッド映画の繁栄、動画配信サービスの台頭を経て、AI生成オリジナル動画の無料配信の時代が到来する、と同氏は考えている。

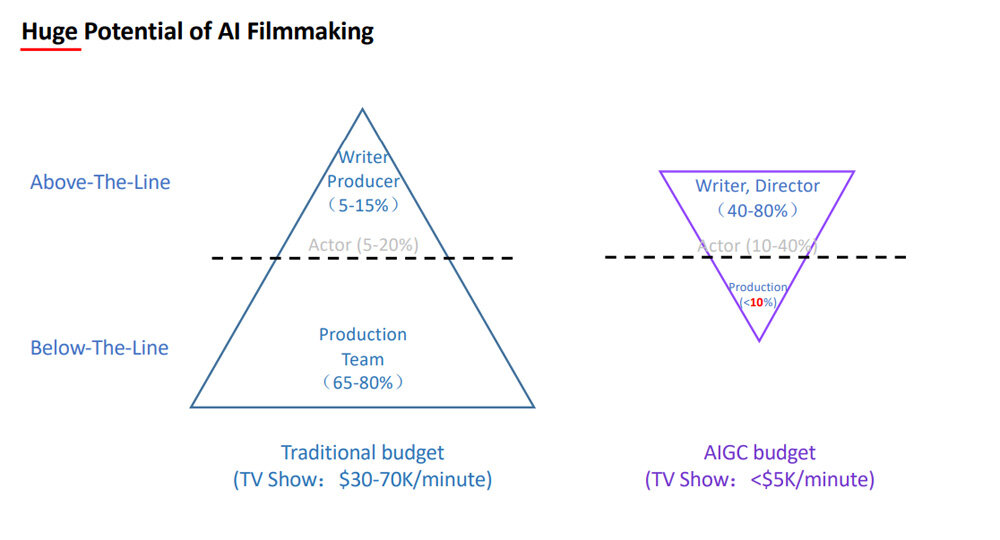
ワン氏がAI生成オリジナル動画配信の時代を予見するのは、こうした動画は従来の動画に比べて圧倒的な低予算で制作できるからだ。伝統的な動画では制作費の65~80%を制作スタッフの人件費などに費やされるが、AI生成動画では制作時の省人化が可能となることで、制作スタッフ人件費は制作費全体の10%に抑えられる。こうしたAI生成動画に広告をつければ、簡単に無料配信できるようになる。

ワン氏は、AI生成映画の可能性を探求する一環として、こうした映画を制作するプロジェクト「TCL Film Machine」を立ち上げた。このプロジェクトから誕生した9本の短編映画は、TCL tv+公式YouTubeチャンネルから視聴できる。

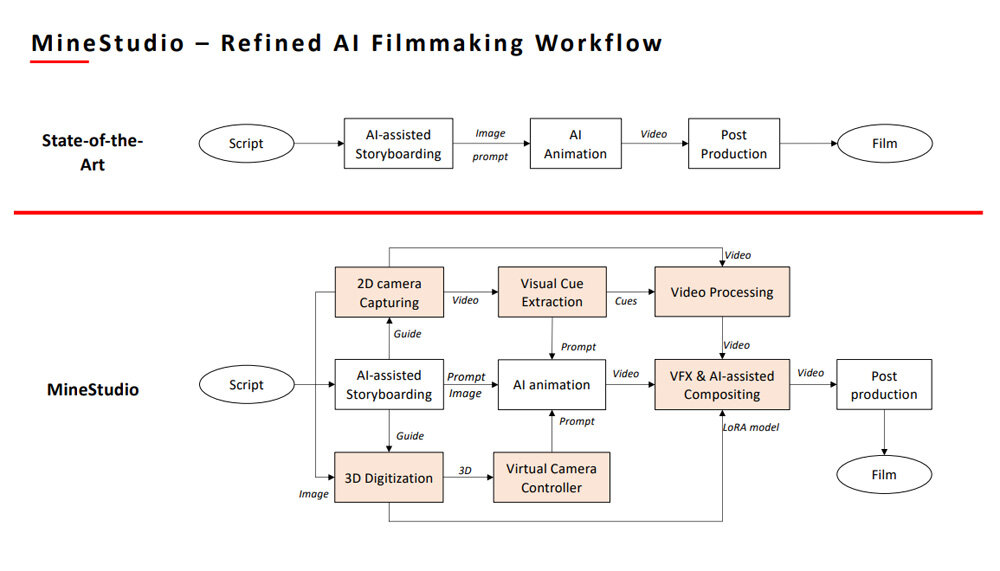
以上のプロジェクトに取り組むことで、ワン氏は現状のAI生成動画制作における課題に直面した。現状では、まず脚本を執筆後、脚本を複数のシーンに分けてストーリーボードを制作して、そのボードに合致するようにAIで動画を生成して最終的な動画を完成させる。
このプロセスにおいては、AIの出力結果を人間の制作スタッフが制御できる余地が少ないので、被写体の一貫性、カメラ制御、人間の所作、事物の物理的な挙動に関して問題が生じる。

AI動画生成における制御性を拡大するためにワン氏が試みたのが、動画生成の全てをAI任せにしないことであった。具体的には、例えば自動車が走行するシーンを生成する際には、あらかじめ自動車の3Dオブジェクトを画面に設定した上で、AIによってディテールを生成するのだ。

以上のアプローチを推し進めると、制御可能な被写体、背景、カメラなどをあらかじめ設置したうえで、ディテールのみをAIで生成するプロセスとなる。ワン氏は、こうしたプロセスを遂行できるワークフローをMineStudioと命名した。
MineStudioを活用してAI生成動画を制作すると、例えば、背景は簡単に差し替えられる。この背景には、3Dシーンを生成する技法であるガウシアンスプラッティングで生成した画像を使うので、カメラアングルを変更しても一貫した背景を維持できる。

MineStudio活用による利点は、登場キャラクターの年齢などを簡単に変更できるところにある。キャラクター設定を変更しても、背景やシーンにあるオブジェクトはこの変更の影響を受けずに一貫性が保たれる。

MineStudioは、従来の3DCG技術と動画生成AI技術を折衷したようなものと言える。このワークフローを活用すれば、AIによって生成する範囲を増減させることで動画制作費を節約しても、動画品質を維持できる。
以上に紹介したグラフィックAIとそのノウハウは、いずれも制作現場のニーズに応えられるものである。かつてグラフィックAIはその目新しさのみに注目されることもあったが、現在では制作現場における選択肢や可能性を増やす実用性から語られるようになった。GTCはSIGGRAPHと並び立つグラフィックAIの祭典でもあり、2026年もGTCに注目していきたい。
TEXT_吉本幸記 / Kohki Yoshimoto
EDIT_小村仁美 / Hitomi Komura(CGWORLD)、山田桃子 / Momoko Yamada













