2026年3月16日(月)から19日(木)にかけて、NVIDIAが主催する世界最大級のAIカンファレンスGTC 2026が、アメリカ・カリフォルニア州のサンノゼでハイブリッド開催された。950のセッションが行われた今回のカンファレンスでは、フィジカルAIに大いに注目が集まるなか、最新グラフィックAIに関する発表も多数あった。
以上のようなセッションのなかから本稿では、Canvaにおける生成AI活用の現状と未来、Adobeが推進するAI駆動型広告コンテンツ展開、そしてRunwayの動画生成AIが切り拓く新たな可能性について紹介する。

ユーザーの創造性を支援するAIアプリとしてのCanvaの歩みと未来
CanvaのAI研究を率いるステフ・コラッツァ/Stef Corazza氏は、Canvaの歩みと未来を”AIによる進化”という観点から発表した。近年はAI新機能の実装を推進してきた同アプリは、これまでにのべ270億回AI機能が使われてきた。

また、Web上から利用するAIサービスとしては、CanvaはChatGPTとGeminiに次ぐ3番目に位置づけられる。このように、Canvaは現代における代表的なAIアプリのひとつなのだ。
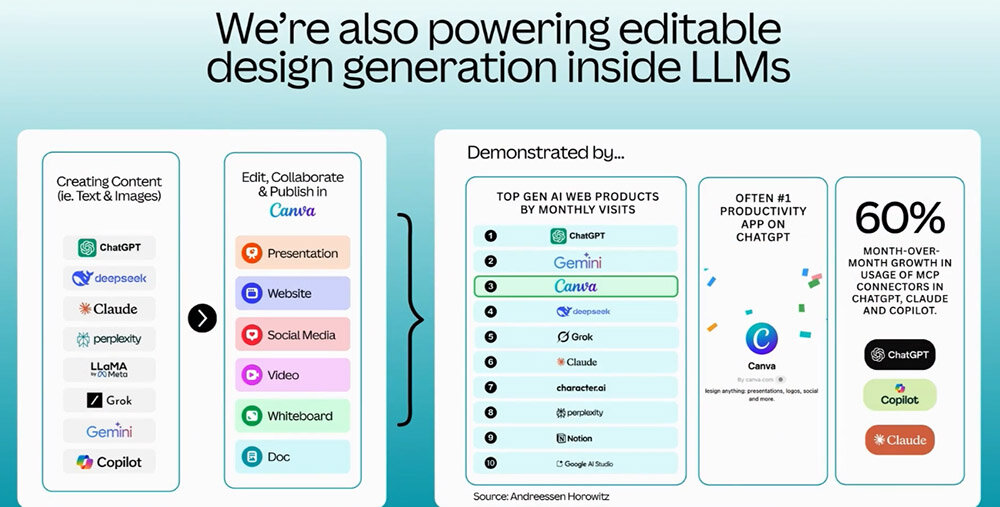
コラッツァ氏によると、CanvaのAI機能を使うと、制作物を同僚と共有したり、Web上に公開したりする可能性が13%向上する、とのこと。同アプリにおけるAI機能は、ユーザーのモチベーションに良い影響を与えているのだ。

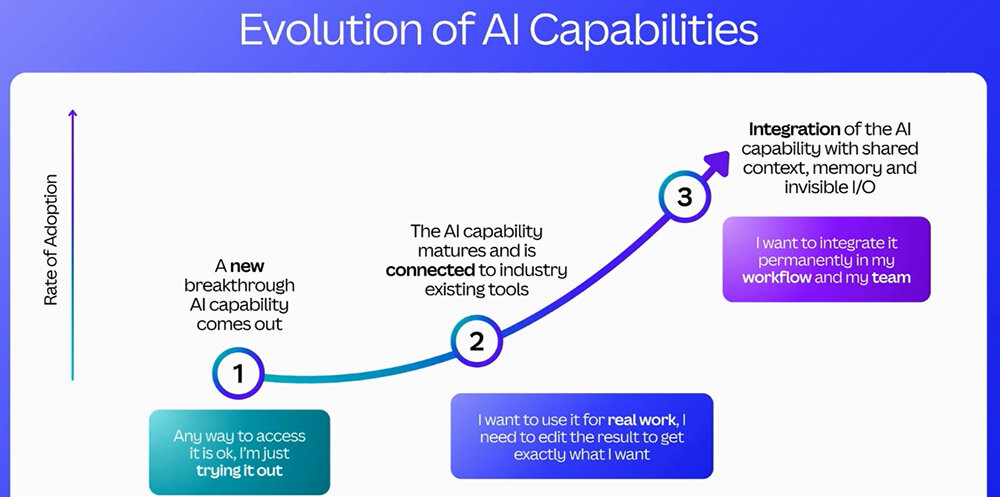
続いてコラッツァ氏は、AI機能実装の3段階について話した。一般にAI機能は以下のような3段階を経て、その業務活用が浸透していく。
・魔法の段階:新しいAI機能が、まるで魔法のように驚かれる段階。具体的活用には至らない。
・ツールの段階:AI機能を既存ツールと連携させて使う段階。
・ワークフローの段階:AI機能をワークフロー全体にわたって使う段階。
Canvaは、ワークフローの段階に達している。というのも、同アプリはユーザーが実行したいタスクに応じて、100種類以上のなかから最適なAI機能を提供することで、グラフィックコンテンツ制作のワークフロー全体をサポートしているからだ。こうしたAI機能群は、「Canva AI」と呼ばれる。

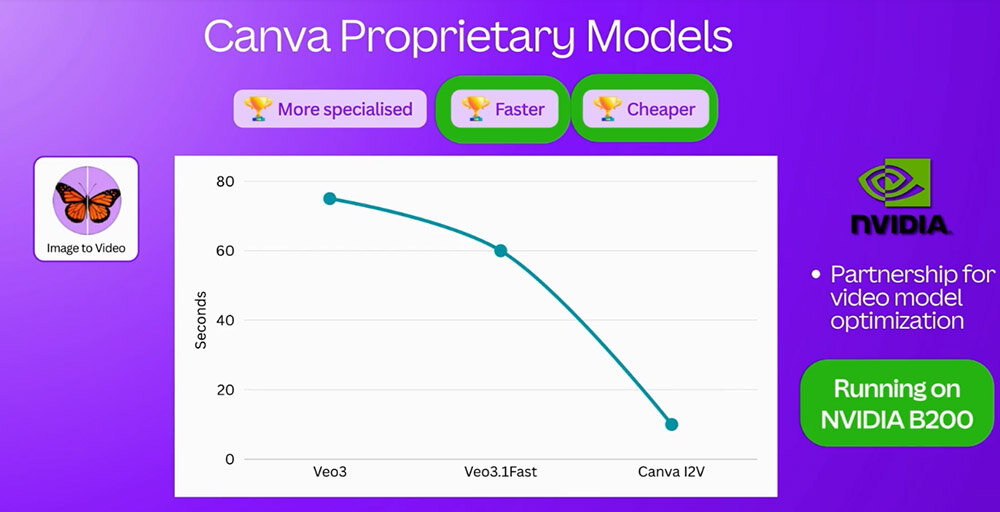
コラッツァ氏は、最近実装したAI機能にも言及した。画像を入力すると動画を出力する「Image to Video」機能は、NVIDIAとの共同研究から誕生した。NVIDIA DGX B200を活用する同機能が要する動画生成時間は、1分を要するGoogleの動画生成AI「Veo 3.1 Fast」に比べて10秒と驚異的な速さを実現したのだった。
コラッツァ氏は、Canvaの今後の進化についても話した。同アプリは様々なAI機能を実装してきたが、それらはいずれも1人のユーザーが使うことを前提とされてきた。今後は、あらゆるAI機能を複数のユーザーが使えるマルチユーザー仕様に移行させる予定だ。
発表の最後には、Canvaは人間の創造性を支援する「人間中心のAIアプリ」であり、今後もユーザーの要望を第一に考える、とコラッツァ氏は述べて締めくくった。
3Dデジタルツインと生成AIを併用する広告制作を提案するAdobe
AdobeのGenStudioおよびFirefly Enterprise部門でゼネラルマネージャーを務めるヴァルン・パーマー/Varun Parmar氏は、同社が推進するAI駆動型広告コンテンツ展開について発表した。
はじめにパーマー氏は、近年の広告コンテンツの需要の高まりに言及した。Adobeが行なった調査によると、広告コンテンツは今後2年間でその需要は5倍になる、と予想されている。

こうした広告コンテンツの需要増加は、各種SNSにおけるコンテンツが短命になっていることと関係している。例えばTikTokコンテンツは、全エンゲージメントの半数は10秒以内に生じ、残り半分はさらに数分かけて起こっている。このようにコンテンツが短命になっているため、顧客とのエンゲージメントを維持するためには次々とコンテンツを投入する必要があるのだ。

広告コンテンツを継続的かつ大量に制作するために、最近では生成AIが活用されるようになった。しかし、生成AIはしばしば期待とは異なる生成結果を出力する。それゆえ、商品イメージを正確に伝えることが不可欠な広告コンテンツ制作では、生成AIの出力結果を精査して修正する手間が生じてしまう。

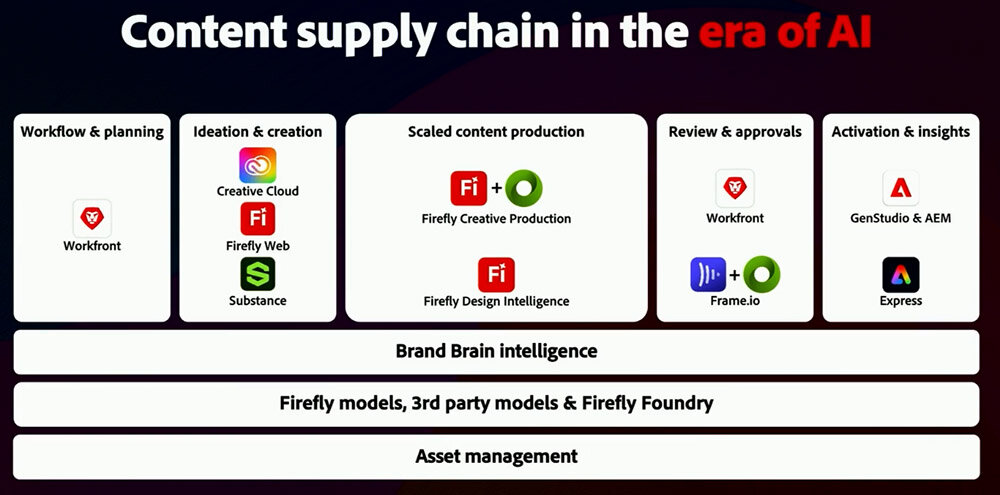
以上のような課題を克服するためにAdobeが提案するのが、3Dデジタルツインと生成AIを併用した広告コンテンツ制作だ。この提案は、広告の中心となる商品は3Dデジタルツインとして制作し、背景などは生成AIによって生成する、というアプローチである。

商品の3Dデジタルツイン制作にあたっては、Adobe Substance 3Dが有効である。このツールを使えば、商品に関する高精細な3Dオブジェクトにフォトリアルなテクスチャを付与して、リアリティのある商品画像を制作できる。

商品に関するフォトリアルな3Dデジタルツインが完成したら、Adobe Firefly Creative Production for Enterpriseを活用したステージング(staging)を行う。このタスクによって、商品の3Dデジタルツインは、広告コンテンツにふさわしい背景のなかに置かれる。背景は、テキストプロンプト入力によってAIが生成する。
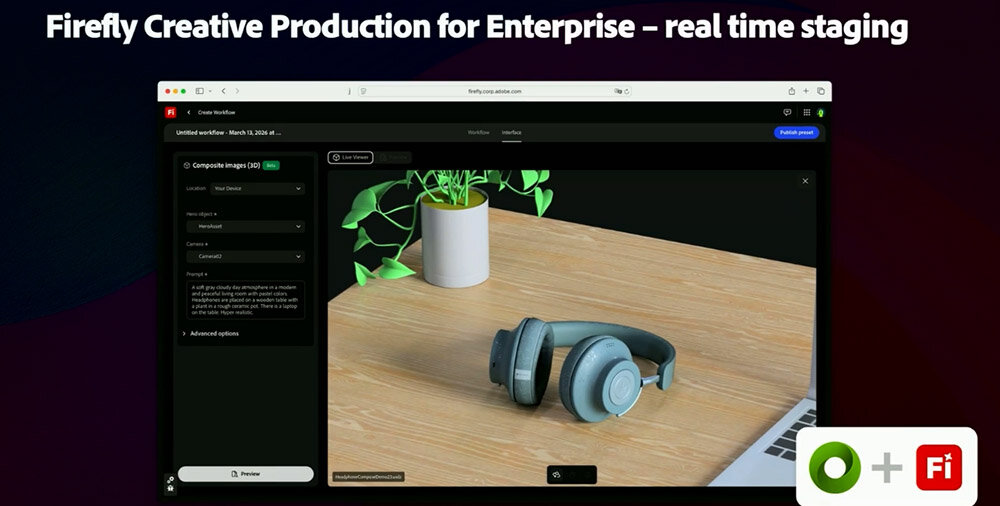
3Dデジタルツインと背景の融合においては、プロンプト入力のほかにも、3D構成を指定して、立体的に表現することも可能だ。以下のヘッドフォン画像は、3D構成指定を活用したものだ。

以上に紹介した3Dデジタルツインと生成AIを併用する広告コンテンツ制作に関して、Adobeはワークフロー全体にわたって各種Adobe製品を提供している、と述べてパーマー氏は発表を終えた。
世界シミュレータへと進化する動画生成AI
RunwayのCTOを務めるアナスタシス・ゲルマニディス/Anastasis Germanidis氏は、動画生成AIの現状と新しい可能性について発表した。
発表の前半では、ゲルマニディス氏はRunwayが開発する動画生成AIであるGenシリーズの現状について話した。最近、同社はNVIDIAとの共同研究によって、Gen-4.5におけるリアルタイム動画生成を実現した。テキストプロンプトを入力すると、その内容が即座に動画に反映されるのだ。この成果により、”テキストプロンプトによる動画の編集や演出”という新たな動画制作技法が可能となった。


この発表から数週間前(2026年2月頃)、RunwayはGenシリーズの性能を精査する実験を行なった。具体的には、同一の1コマから始まる2本の動画を人々に見てもらって、どちらがGenによる生成動画であるかを見抜いてもらうテストを実施したのだ。なお、AI生成動画は、本物の動画の最初の1コマを入力して生成したものである。

以上のテストの結果、AI生成動画を見抜けた人は被験者の10%未満だった。この結果は、Genが高品質な動画を生成できると同時に、このAIが世界を動画としてリアルに再現できる”世界シミュレータ”として機能することを証明した。
発表の後半では、ゲルマニディス氏は世界シミュレータとしての動画生成AIの可能性について話した。そうした可能性のひとつとして、動画生成AIを用いて3Dワールドを生成することがある。GWM(Generative World Models:生成的世界モデル)ワールドと命名されたこのユースケースは、Google傘下の研究機関DeepMindが2025年8月に発表したGenie 3に酷似している。
世界シミュレータのほかのユースケースとして、デジタルヒューマンの生成がある。この事例ではユーザーが話すと、その返事を話すデジタルヒューマンの動画が生成される。

ゲームアシスタントを生成するユースケースも披露された。この事例では、ゲームの進行状況に合わせて、ゲームアシスタントがユーザーにヒントを伝える。ゲームの状況が入力となって、ゲームアシスタントの動画が出力結果になっていると推測される。

以上のような世界シミュレータのユースケースからは、リアルタイム生成と世界を再現する高度な表現力を獲得したことで、動画生成AIがゲームエンジンの機能を取り込みつつある傾向が窺える。
発表の締めくくりとして、今後数週間から数ヶ月のあいだに、より多くの世界シミュレータのユースケースを公開していきたい、とゲルマニディス氏は述べた。
以上に紹介した3つの発表からは、生成AIがコンテンツ制作のワークフロー全体に浸透しつつあることと、世界シミュレータのように新しい活用方法が開拓されていることがわかる。
いずれにしても、生成AIはもはやクリエイターにとって当たり前のものになりつつある、と言えるのではないだろうか。そうした生成AIの最新動向を伝えるGTCやSIGGRAPHには、今後とも注目すべきだろう。
TEXT_吉本幸記 / Kohki Yoshimoto
EDIT_小村仁美 / Hitomi Komura(CGWORLD)