
本稿では、「SIGGRAPH」会期中、コンベンションセンターにほど近い会場で、AMDとNVIDIAの2大GPUベンダーがそれぞれ開催したイベントの模様をお届けしよう。いずれもコンテンツクリエイターに向けた新製品の発表を行ったわけだが、AMDは本業の核心とも言うべき、ハードウェアに関する技術を中心に、対するNVIDIAは、昨年ごろからフォーカスしているAIに対する研究部門の成果発表を中心にしていた。両社の方向性の共通点と差異が良く対比できるイベントとなっていたため、ふたつのイベントを併せてご紹介したい。
TEXT & PHOT_谷川ハジメ(トリニティゲームスタジオ) / Hajime Tanigawa(Trinity Game Studio)


<1>CG制作にすぐにでも役立つハード&ソフトを発表したNVIDIA
時系列的には前後してしまうが、まずは7月31日に、新製品の発表と、リサーチ部門のAI研究の成果発表を、プレス向けに行ったNVIDIAの話題からお伝えする。
NVIDIAが発表した新しい製品は、いわゆるeGPU用ボックスだ。ビデオボードそのものと同様に、NVIDIAは自社のビデオボードで動作するeGPUボックスのリファレンスデザインを策定し、実際の製品はパートナー各社が販売する。
通常PC本体にインストールするビデオボードを、USB経由のHDDのように外付けしてしまう製品で、ビデオボードがすっぽり収まるサイズのケースに、給電用の電源装置とPC本体に接続するためのインターフェイスが内蔵されている。コンテンツクリエイター向けのハイエンド製品に先行する形で、数年前からコンシューマ向けビデオボードでは同じコンセプトの製品がリリースされている。
今となっては技術的に何ひとつ難しい話ではないのだが、つい最近まで実現してこなかった。理由はいくつか推測されるが、技術的に課題であったのは、インターフェイスの問題だ。GPUとメインメモリ、CPU間のデータ転送には、大きな帯域幅を必要とする。現行のビデオボードは、PCIe x16接続が主流で、双方向の実効速度は32Gbyte/secになる。外付けの場合、PCIeバズに直結した場合に及ばないものの、Thunderbolt 3接続によって、双方向で10Gbyte/secの帯域が確保できるようになった。ビデオボード側にデータ転送する速度はデスクトップ内蔵ビデオボードの1/3程度ではあるものの、演算性能に優れたGPUで計算するメリットは大きい。 もうひとつ考えられる理由は、eGPUに対するニーズがニッチ過ぎて、NVIDIAがオフィシャルにサポートするには、市場性に乏しいと判断されてきたことだろう。前述した帯域幅の問題もあって、NVIDIAビデオボードの最高性能が引き出せないなら、リファレンスを作成しても意味がないということになる。一昨年、昨年ごろからのThunderbolt 3の普及に伴って、粗悪な製品が乱造される前に手を打った形だ。




続いてのハードウェアは、オフィスのデスク付近に収まるギリギリのサイズにデザインされたワークステーション『DGX Station』だ。200Gbyte/secの帯域幅のNVLINKでローカル接続されたGPU『TESLA V100』を4基搭載するモンスターマシンで、NVIDIAが「パーソナルAIスーパーコンピュータ」としているのも頷ける。DGXのレンダリング性能は圧巻で、CPU1基のみのCPUレンダリングと比較して157倍のレンダリング性能に達するとNVIDIAは主張している。
実際のところは、あらゆるシーンで157倍の性能が出せるわけではないし、また、CPUレンダリングとGPUレンダリングではレンダ結果に差異が出るレンダラや、そもそもGPUレンダリングに対応していない、対応していても不十分な実装のものもあるため、導入には十分な検証が必要だろう。



AI活用デノイズとライトトランスポート。デノイズはirayに実装済、Mentalrayにも実装される予定。その他OptixSDK使用レンダラにも。ソフトウェアのほうでは、NVIDIAの研究部門の研究成果の実業へのフィードバックとして、11月に登録者向けに提供が開始されるOptix5.0ソフトウェア開発キットに、AIを活用した「デノイズ」(ノイズ除去)の機能が追加される。ここでいう「ノイズ除去」とは、従来のレンダラによるレンダリング結果に残ってしまうアーティファクトを除去するだけ、といったものではなく、レンダリングそのものを大きく変えるものだ。
具体的には、通常は1ピクセルあたり100〜1000回行うモンテカルロ法によるレイトレーシングを、たったの1回で済ませて、その結果レンダリング速度を10倍に高めるというものだ。1回のレイトレースでは正しく求まらないピクセルの色を「ノイズ」として捉えて、それを除去して正しい色に補正するから「デノイズ」というわけだ。
この技術で、レイトレースを1回だけで済ませる秘訣はAIにある。NVIDIAでは、あらかじめ1ピクセルあたり4000回のレイトレースを行って生成したイメージを、1万枚AIに学習させている。この学習を踏まえて、AIが適切にピクセルの色をどう補正すれば良いか推定して自動的に正しい色に置き換えているのだ。
この機械学習による色補正の推定は、特定のシーンによらない。十分なサンプルの学習を終えた後であれば、異なるシーンに適用しても良好なレンダリング結果が得られるのが、まさにAIらしいと言えるだろう。


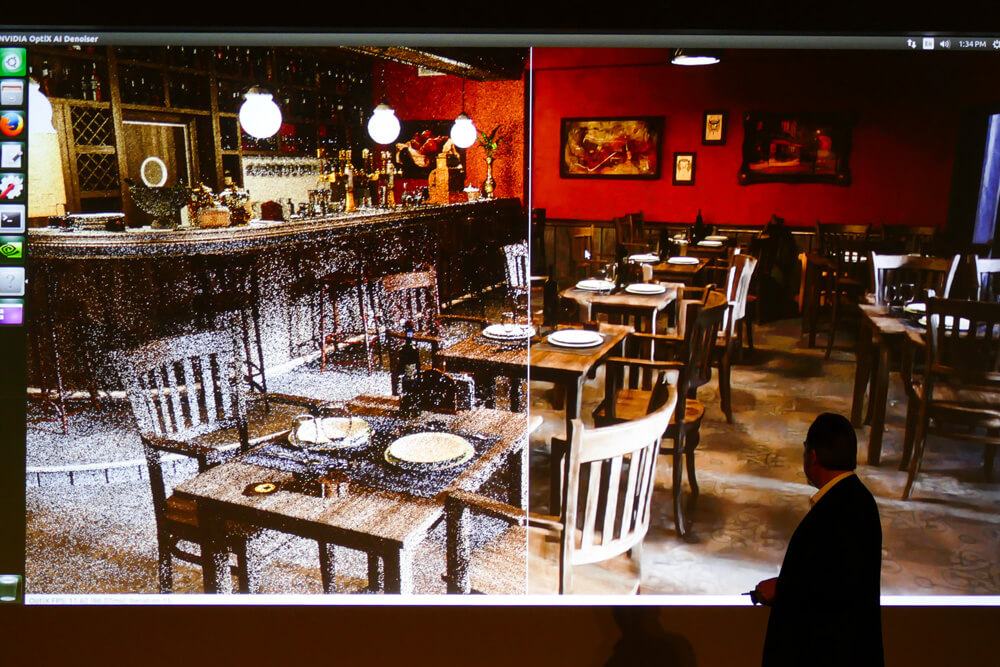


AIによるイメージ補正は、レンダリング結果として得られる投射平面の2Dイメージに対して行うものもある。AIによるアンチエイリアスがそれだ。詳細なアルゴリズムは筆者の理解を超えるところだが、従来の近隣のピクセルの色値から演算してフィルタリングを行うものではなく、おそらくはイメージ内の該当部分のカーブの度合い等を吟味して判断を行い、学習済みの近似のデータを参考にして、補正の程度と色を決定するのだろう。この結果、既存のアンチエイリアスが適用されたイメージにつきまとう、「眠くなった絵」にはならず、シャープさを失うことはない。
学習した内容を活用して、AIが「ジャギー」という「ノイズ」の一種を除去するという意味では、前述した「デノイズ」とそう遠くないのかもしれない。
発表会では、NVIDIA自身のものではないが、NVIDIA主催のコンペで技術力あ認められて100,000ドルの資金が贈られたArtomatix社のイメージをディティールアップする技術のデモも行われた。Artomatix社の技術も機械学習を活用したもので、具体的な活用としては、テクスチャのシーム除去、既存の異なるイメージを合成してシーンにフィットする新たなテクスチャの生成、古いソフト用に作成したテクスチャの密度感を高めてリサイクルする、といったことが挙げられる。これらの機能は同社が販売する統合テクスチャ作成環境に含まれているようだ。


「Quantum Break」「Max Payne」「Alan Wake」といったゲームを開発するRemedy Entertainmentからの依頼に端を発するAIを活用したフェイシャルアニメーションの取り組みでは、当初ビデオ映像をソースとして、わずか5分の学習で、ゲームに使用するすべてのフェイシャルアニメーションデータをAIが自動的に作り出すことに成功した。この方法の段階でも、従来のフェイシャル用リギングといった作業は行っておらず、ソースとして与えているのは、俳優の演技を録画したビデオ映像だけだ。
NVIDIAは、このソリューションをさらに改良して、最終的には音声データを与えるだけで、フェイシャルアニメーションを生成することができるようになったという。このシステムを活用すれば、他言語に対応する場合でも、それぞれの言語ごとに容易にフェイシャルアニメーションを用意することができるとNVIDIAは主張している。
これが、はたして日本語のようなヨーロッパ言語とは異なるルーツを持つ言語で、かつ現実に近いリアルなアニメーション表現ではなく、リミテッドアニメ由来の「口パク」の様式美を良しとする文化においても、はたして実用的に機能するかはテストしてみないと分からないが、昨今はハリウッド由来のアニメも随分と浸透していることから、案外違和感なく受け止められるのかもしれない。


その他、NVIDIAのAIに対する取り組みとして、バーチャル空間「HOLODECK」に存在してAIで学習し、現実世界にリアルに存在するロボットと連動してパフォーマンスを行うISAACくんや、「VRWorks」SDKに対応し、360度4K映像のライブストリーミング撮影が可能なZCAMの『Z-Cam V1 Pro』などが紹介された。







次ページ:
<2>新アーキテクチャ「Vega」でCG制作を広範囲に支えるGPU製品を投入したAMD
<2>新アーキテクチャ「Vega」でCG制作を広範囲に支えるGPU製品を投入したAMD
他方、AMDは、新CPU『Ryzen』販売好調の波に乗る。前日の7月30日に、昨年に引き続いて開催された「Capsaicin」イベントの冒頭に登壇したCEOのLisa Su氏も、その後登壇したRadeonチーフアーキテクトのRaja Koduri氏も、このあたりのところを力説しつつ、新アーキテクチャのGPUコア「Vega」を紹介する流れにつなげていった。




本イベントでは多数の「Vega」搭載製品が紹介されたが、ごく一般的なスタジオやインディクリエイターにとってターゲットとなるのは、コストパフォーマンスに優れたコンシューマ向け製品『Radeon WX 64/56』(うちWX64には水冷クーラー搭載のものと空冷クーラー搭載のものの2タイプが存在)だろう。マルチコア最適化が進むレンダラーの恩恵を受けるために、競合Intel CPUよりコア数が多く同時実行可能なスレッドを多く立てられる『Ryzen』と併せてリプレイスを検討してもいい。非常にコストパフォーマンスに優れたシステムとなるはずだ。


設備投資を行う余力が充分にあり、多数のクリエイターを擁する大規模なスタジオでは、『Radeon Pro WX 9100』を視野に入れることができるだろう。ただし、GPUコア性能は基本的にコンシューマ製品と同じものであるため、判断のポイントは、広い帯域幅を持つHBM2ビデオメモリが16GB必要かどうかになる。V-RAMがあったほうがいいに決まっているが、価格差に見合うかが重要だ。従来品の『FirePro W9100』を使っているなら、タスクによって50%〜110%のパフォーマンス向上が見込めると、AMDは主張する。重量級シーンのレンダリングが主な用途で、従来品のリプレイスが必要なら本製品が検討対象になるだろうが、慌てて導入しないで今度発売されるであろう2xGPU版を待つなり、『Radeon WX 64』搭載ビデオカードの複数枚構成ともども、ベンチマークを取るなりしてからでも遅くないと思われる。


オフライン編集やエフェクトを取り扱うスタジオなどでは、『Radeon Pro SSG』が気になるだろう。高速なV-RAMに加え、フラッシュメモリを低速なV-RAMとして二段構えのメモリ(HBCC)を搭載する本製品は、2TBの広大なメモリ空間を誇る。ただし本ビデオボードの価格は、北米で$6,999と、お値段のほうも規格外となっている。すでにメインメモリを潤沢に搭載し、ストレージも大容量SSDにリプレイス済みならともかく、メインメモリの増設余力がある状態で、容量の観点から回転数が大きいとしても依然低速なHDDを積んでいる環境なら、まずはそこから手をつけるべきだ。すでにそれらに対する投資が済んでいる状態で、かつ長尺や4K8Kといった高解像度映像の編集が必要なスタジオなら、本製品を導入すれば非常に幸せになれるかもしれない。


本イベントでは、いくつかのパートナー企業から要人が登壇したのだが、ゲーム業界からはおなじみのレジェンド、Epic GamesのTim Sweeney氏が登壇した。「SIGGRAPH」に合わせたイベントということと、Epic Gamesが『Unreal Engine 4』の映像分野への利用を促進していることから、本イベントでSweeney氏が紹介したのも「Fortnite」のゲームそのものではなく、「Fortnite」のプロモーション用トレーラームービーのほうだった。もっとも、「Fortnite」のトレーラーのほうも、『Unreal Engine 4』で制作されており、当然のことながら、カメラやキャラクターアニメーション、ライティングやモデルに対する変更ですら、リアルタイムでUnrealエディタのビューポートに反映される。


映像制作ツールからは、MaxonのCEO、Paul Babbが登壇し、同社の『Cinema4D』にAMDの「Radeon Pro Render」を取り込んで高速化を果たしていることが報告された。4GPU搭載機での精密な腕時計のレンダリングは28秒と高速で、1CPUだとはてしなく時間がかかるものを、ごく短時間でレンダリング可能であることをアピールしていた。


映像コンテンツ制作の分野からは、インド発、70カ国10の言語で配給され2億7500万USドルの興行成績を記録した超大作『Baahubali』の続編、『Baahubali 2』の監督、S.S.Rajamouli氏と小型で高性能な撮影機材で知られるRED DIGITAL CINEMAのJarred Land氏が登壇して、8K解像度の映像編集にビデオメモリ空間が広い『Radeon Pro SSG』がいかに寄与するかが語られた。




加えて『Baahubali 2』に登場する4500万トライアングルの王宮モデルをGIバウンス5回の条件でレンダリングするデモでは、寄りで8FPS強引きで6FPS強と良好なフレームレートを叩き出しており、宮殿全体を画面に収めるようなロングのカメラでも、ひょっとしたら1FPS出るんじゃないかと思わせるほどだ。なるほど「HBCC」搭載メモリが活きてくるシーンもあるものだなと認識させられた。なお、この際に、HBCC非搭載のビデオカードではメモリ不足でクラッシュするという(予定調和な)ハプニングが起きる一幕もあったことを付け加えておく。
実際のところ、ハリウッドの1/3〜1/4でもいいから、CGにバジェットが割り当てられるシネマプロジェクトなら、『Radeon Pro SSG』の導入は、可能だろうし、導入すれば間違いなく活きてくるだろう。






さらに、その後登壇したJellyfish PicturesのJeremy Smith氏からは、同スタジオが『Star Wars』シリーズのスピンオフ『ROGUE ONE』の制作に携わっていること、また『ROGUE ONE』の続編制作の近況が報告された。『ROGUE ONE』の映像のほうは、特にスタジオ撮影のシーンで、自然に撮影されたように見えるシーンでも、奥行き方向のディティールアップのために、CG合成が多用されていることが見て取れた。
なお、Jeremy Smith氏の登壇は、「AMDは、AMD STUDIOSと銘打って、ハードとソフト一体でコンテンツクリエイションをバックアップしています」「AMDの方針はドライバやAPIレベルからオープンで、開発者側で何でも自由にできます」という大変美しい流れのなかでのことだったのだが、こういったイベントのゲスト登壇者にありがちなパターンで、Jeremy Smith氏も、多分にJellyfish Picturesの知名度向上や、新プロジェクト受注、人材のリクルーティングを目的にしていたようだった。




最後に、ペタFLOPSを目指してAMDが技術の粋を集めて取り組んできた『Project 47』が紹介された。『Project 47』は1ラックにぎっしりと搭載されたサーバ群の並列処理で1TFLOPSを実現するスーパーコンピュータで、科学的分野での活用を視野に開発されてきたものだ。AMDは、従来よりx86 CPUを活用したスーパーコンピュータでIntel Xeonのシェアを奪っており、本プロジェクトは、超高速な演算が必要とされる学術的研究用途のコンピューティングでゲームチェンジャーになるポテンシャルを持っている。
「Vega」搭載製品が12テラFLOPSを超えたばかりで、なんとも飛躍した夢のような話であるが、複数のクライアントPCに対して、『Maya』を実行しても十分なパフォーマンスが得られる仮想PCをサーブするデモを通じて、ペタオーダーの演算性能が、『Project 47』ラックサーバーで確かに具現化していることが確認できた。冒頭で含みをもたせていた、イクサFLOPSの演算性能も、そう遠い未来の話ではないのかもしれない。


<3>まとめ
NVIDIAとAMD、ふたつのGPUベンダーのイベントをまとめてお伝えしたが、いかだだっただろうか。ことAMDについては、厳しい経営環境に苛まれると、必ずカミカゼが吹くという流れが、過去に幾度か繰り返されてきている。PC市場のシュリンクが続くなか、AMDは、新CPU『Ryzen』でIntelのシェアを奪ったように、新GPU『Vega』でNVIDIAのシェアを奪うことができるだろうか。
対するNVIDIAは、PC市場でのAMDとのシェア争いもそこそこに、計算コストのかかる機械学習の応用範囲を広げて、新たな計算機需要を作り出そうと躍起になっている。「SIGGRAPH」ではめぼしい話題がなかったが、リビングテレビ用セットトップ『SHIELD』や車載用の『Drive PX 2』といった組み込み製品にも積極的に取り組むほか、仮想GPUの『GRID』や仮想ゲーミングマシンの『GeForce NOW for Mac and PC』といったクラウドサービスにも取り組んでいる。ただし、モバイル用APU『Tegra』はQualcommの牙城の前に苦戦が続いており、ニンテンドーSwitchに採用されたことで多少の挽回はあったものの、成功しているとは言えない。
いずれにしても、ハードウェアの進化は、まずは特定の専門分野で高速な演算性能に対する需要が起こり、それに応える形で演算性能を向上させた新たなアーキテクチャが登場する。その後、時間経過とともに、新技術が低価格帯にも波及していくのが常だ。GPUについて、そのサイクルを駆動するのが、必ずしもCGではなくなっただけのことで、恩恵に与ることができなくなったわけではない。
AIや機械学習という新たな潮流を得て、ここ5年のうちには、現状で最高品質のフォトリアルなCGが、デスクトップPCのマシンパワーで、リアルタイム出力できるようになるのは間違いないだろう。そうなれば、技術的な知見の有無や、所有する計算機資源の性能差が試行回数に影響する度合いは、相対的に小さくなる。コンピュータグラフィクスの優劣を決定付けるのは、アーティストの創造力と画作りにかける情熱──そんな当たり前の時代が再びやってくるかもしれない。
info.
-

-
SIGGRAPH 2017
会期:2017年7月31日(日)〜8月3日(木)
場所:Los Angeles Convention Center
主催:ACM SIGGRAPH
公式サイト













