NVIDIA Research(NVlabs)は5月14日(木)、1枚の画像とカメラの軌跡データから60秒間の720p動画を生成可能な、26億パラメータの世界モデル「SANA-WM」をオープンソース(Apache-2.0ライセンス)で公開した。実写ベースの高精細な背景生成や、ゲームエンジンのような精密なカメラワーク制御が可能な、一貫性のある長尺動画の生成を実現する。
Excited to share SANA-WM: a 2.6B open-source world model for minute-scale 720p video generation.
— Haoyi Zhu (@HaoyiZhu) May 15, 2026
Given one image + text + a 6-DoF camera trajectory, it synthesizes action-controllable 60s worlds on a single GPU.
Project: https://t.co/5NINfiFoTK
Paper: https://t.co/JKczmyRsJL pic.twitter.com/3oZ1uc55zM
1枚の画像から1分間の動画を生成する長尺世界モデル

「SANA-WM」は、1枚の画像から、空間的・時間的な一貫性を保持し続け、環境の破綻がない60秒・720pの動画を生成できる世界モデル。カメラ軌跡の厳密な制御が可能で、独立したメイン処理とカメラ処理を並行して行うDual-Branch Camera Control(デュアルブランチカメラ制御)により、6自由度(6DoF、6 Degree of Freedom、3D空間でのXYZ回転+XYZ移動という基本的な6つの動き)の軌跡データをフレーム単位で高精度に追従する。メートル法に基づいた正確なカメラパスを反映できることから、3DCGツールで作成したバーチャルカメラのアニメーションをそのままプロンプトとして適用し、意図通りのアングルで動画を出力できる。
長尺動画を高品質化する2段階生成パイプライン
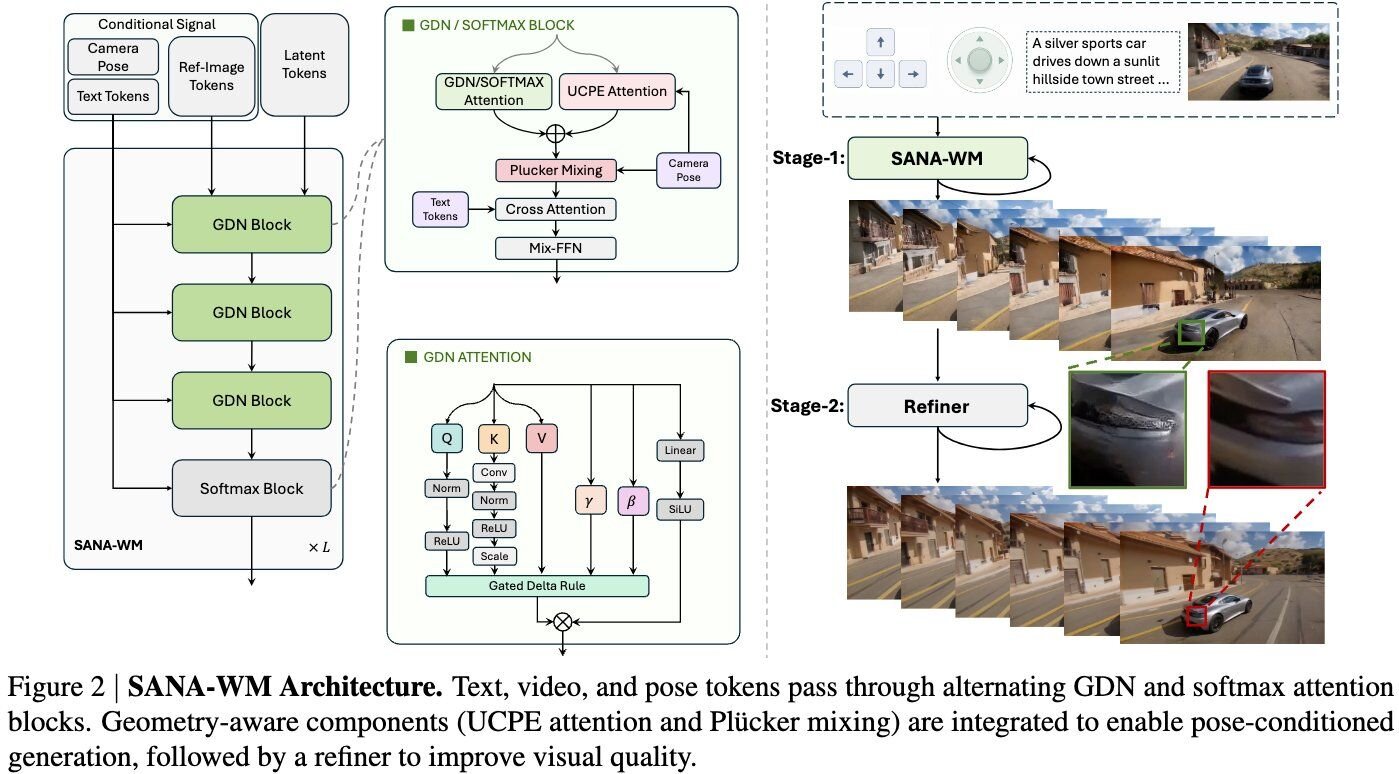
映像のディテールや質感を追求するため、SANA-WMはTwo-Stage Generation Pipeline(2段階生成パイプライン)を構築。最初のステージでベースとなる世界(動画の潜在表現)を生成し、第2ステージにおいて170億パラメータ規模の長尺動画リファイナー(LTX-2 refiner)を適用する。この後工程によって、テクスチャの細やかさやオブジェクトの動的なふるまいが大きく改善され、生成される動画の後半部分まで高い品質と時間的な連続性を担保できるという。
また、長尺のコンテキストをモデルに保持させるため、Hybrid Linear Attention技術が組み込まれている。これは、フレーム単位での効率的な情報処理を担うGated DeltaNetと、一定間隔で配置されたSoftmax Attentionを組み合わせた構造。従来のSelf-Attention(自己注意機構)が抱えていた計算量とメモリ消費の爆発的な増加という問題を抑え、長尺動画の生成を現実的なリソースで実行可能にする。
計算効率の向上により軽量版モデルはGeForce RTX 5090で動作
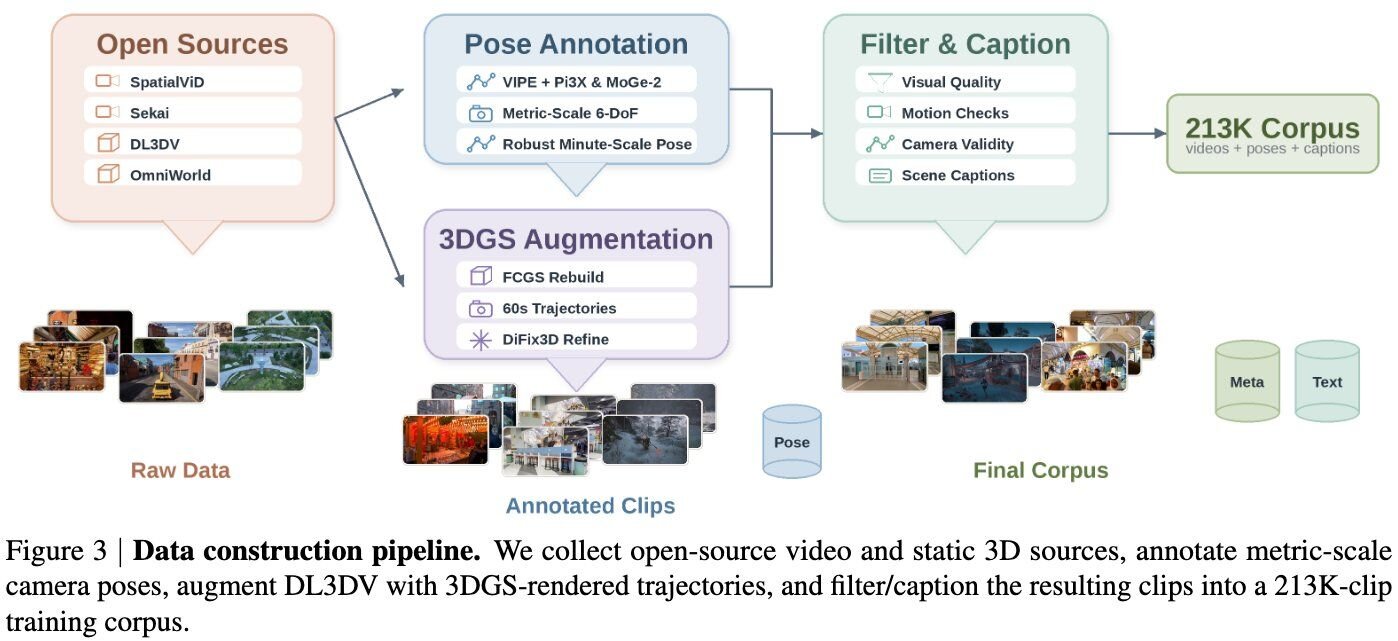
上記で紹介した複数の技術的ブレイクスルーを経て、SANA-WMは最先端の大規模モデルと同等のビジュアル品質と、効率的な学習および推論性能を両立している。モデルの学習は64基のNVIDIA H100を用いてわずか15日間で完了しており、推論時には単一のGPUのみで60秒・720pの動画を生成できる。また、NVFP4形式にクオンタイズ(量子化)された軽量版モデルを用いれば、GeForce RTX 5090環境下において、60秒のクリップのノイズ除去処理を、わずか34秒で完了させることができる。
■SANA-WM | Efficient Minute-Scale World Modeling(プロジェクトページ)
https://nvlabs.github.io/Sana/WM/
ソースコードとモデルのライセンスについて
GitHubで公開されているSANA-WMのコードと、Hugging Faceで公開されているモデルのウェイトデータには、Apache-2.0ライセンスが適用されている。ただし、第2ステージの高品質化に使用されるLTX-2 refinerとVAE(変分オートエンコーダ)のウェイトについては、同梱元の「LTX-2」が定めるライセンスが継承される。
■SANA(GitHub)
https://github.com/NVlabs/Sana
■SANA-WM (Bidirectional)(Hugging Face)
https://huggingface.co/Efficient-Large-Model/SANA-WM_bidirectional
CGWORLD関連情報
●テンセント、3Dモデル生成AI「Pixal3D」発表 入力画像に忠実な3D再現と遮蔽部の高度な生成

清華大学、Tencent ARC Lab、ビクトリア大学ウェリントンからなる研究チームが、単一の画像から高精細な3Dアセットを生成する技術「Pixal3D」を発表。ソースコードはGitHub、学習済みモデルはHugging Faceにて、どちらもオープンソース(MITライセンス)で公開している。入力画像のピクセル情報と生成される3Dモデルの対応関係を直接的に結びつけるピクセルアラインド(Pixel-Aligned)な生成手法の採用により、オリジナル画像に忠実な再構築を実現する。7月開催のSIGGRAPH 2026への採択も決定。
https://cgworld.jp/flashnews/01-202606-Pixal3D.html
●単一画像から顔と髪を切り離す頭部アバター生成手法「One-shot Compositional 3D Head Avatars with Deformable Hair」発表 3DGS、FLAME、物理演算の活用により自然なフェイシャル&ヘアアニメーションを実現

西安交通大学の研究チームが1枚の画像から髪の毛が自然に揺れる高品質な3D頭部アバターを生成する新手法「CompHairHead(One-shot Compositional 3D Head Avatars with Deformable Hair)」を発表。顔と髪の毛の要素を分離し、3DGSによるディテール豊かな3D表現と、FLAMEメッシュによる自然なフェイシャルアニメーション、ケージ構造と物理シミュレーションを適用したヘア表現を採用することで、リアルなフェイシャルアバターをリアルタイムでアニメーションさせることを可能にする。
https://cgworld.jp/flashnews/01-202605-1shotHead.html
●NVIDIA、物理シミュレーション対応の3D環境構築フレームワーク「Lyra 2.0」公開 長時間のウォークスルー動画生成と高品質な3Dシーン出力で大規模な環境構築を実現

NVIDIAのSpatial Intelligence Lab(SIL)が、探索可能な生成3D世界を構築する新たなAIフレームワーク「Lyra 2.0」を発表。カメラ操作の可能なウォークスルー動画を生成し、フィードフォワード再構成技術によって3D空間を生成することで、大規模で複雑な3D環境の構築を実現する。ソースコードはApache-2.0ライセンスでGitHubにて、モデルはNVIDIA Internal Scientific Research and Development Model License(非商用の研究開発用途限定)でHugging Faceで公開されている。
https://cgworld.jp/flashnews/01-202605-Lyra2.html