
清華大学、Tencent ARC Lab、ビクトリア大学ウェリントンからなる研究チームは5月11日(月)、単一の画像から高精細な3Dアセットを生成する技術「Pixal3D」を発表し、ソースコードはGitHub、学習済みモデルはHugging Faceにて、どちらもオープンソース(MITライセンス)で公開した。入力画像のピクセル情報と生成される3Dモデルの対応関係を直接的に結びつけるピクセルアラインド(Pixel-Aligned)な生成手法の採用により、オリジナル画像に忠実な再構築を実現する。7月開催のSIGGRAPH 2026への採択も決定している。
Introducing Pixal3D (SIGGRAPH’26) — a new pixel-aligned image-to-3D generation paradigm for high-fidelity 3D asset creation.
— Wang Zhao (@WangZhao_0849) May 12, 2026
Today’s Image-to-3D has become pretty good at producing plausible 3D assets. But plausibility is not enough. Fidelity is a hidden bottleneck.
A… pic.twitter.com/7F9emjmNzO
Pixal3D(SIGGRAPH 2026採択)をご紹介します。
これは、高忠実度な3Dアセット制作のための、ピクセルアラインド(ピクセル単位で一致した)画像からの3D生成という新たなパラダイムです。現在の「画像からの3D生成(Image-to-3D)」技術は、一見それらしい3Dアセットを生成する点において、かなり優秀になりました。しかし、「それらしさ(Plausibility)」だけでは不十分です。「忠実度(Fidelity)」こそが、目に見えないボトルネックとなっています。生成されたモデルは「だいたい合っている」ように見えても、入力された画像のピクセルと真の意味で一致していないことが多いのです。
見えない部分を補完する生成能力を保ちつつ、3D再構築(Reconstruction)と同じくらい忠実な3D生成を実現することはできるのでしょうか?
Pixal3Dは、その問いに対する私たちの答えです。
私たちは、忠実度を阻む根本的なボトルネックは「2Dと3Dの対応関係」にあると考えています。ほとんどの3Dネイティブな生成モデルは、標準的な座標系(キャノニカル空間)で形状を合成し、クロスアテンションを通じて画像の手がかりを注入しています。この手法では、「どのピクセルが3D空間のどの領域に対応するのか」をモデルに暗黙的に探索させることになってしまいます。
Pixal3Dは異なるアプローチをとります。キャノニカル空間で生成するのではなく、Pixal3Dはピクセルアラインドなカメラスペース(入力視点に基づく座標空間)で直接生成を行います。つまり、「見たままのものがそのまま立体になる(What you see is what you get)」のです。生成された3Dアセットは、最初から入力された視点と完全に一致しています。
同時に、Pixal3Dは「バックプロジェクション(逆投影)ベースの画像条件付けスキーム」を導入しています。これは、複数解像度のピクセル特徴を3Dボクセルへと明示的にバックプロジェクションすることで、2Dと3Dの対応関係の問題を解決するものです。これにより、入力画像は単なるプロンプトではなく、ジオメトリ的なアンカー(基準点)となります。
Pixal3Dは、ピクセルアラインドな3D生成が実現可能かつスケーラブルであるだけでなく、忠実度を劇的に向上させ、3Dネイティブな生成技術を再構築レベルの正確さにまで押し上げることを証明しています。また、この手法は複数視点(マルチビュー)からの生成や、シーンレベルの3D生成にも自然に拡張可能です。
・入力視点に忠実でありながら、見えない部分も生成できる。
・3D生成の創造性を持ち合わせながら、再構築レベルの忠実度に近づく。Pixal3Dは、3D生成と3D再構築の統合に向けた私たちの取り組みでもあります。
従来の3D生成とは異なるアプローチで高忠実な3Dモデルを生成
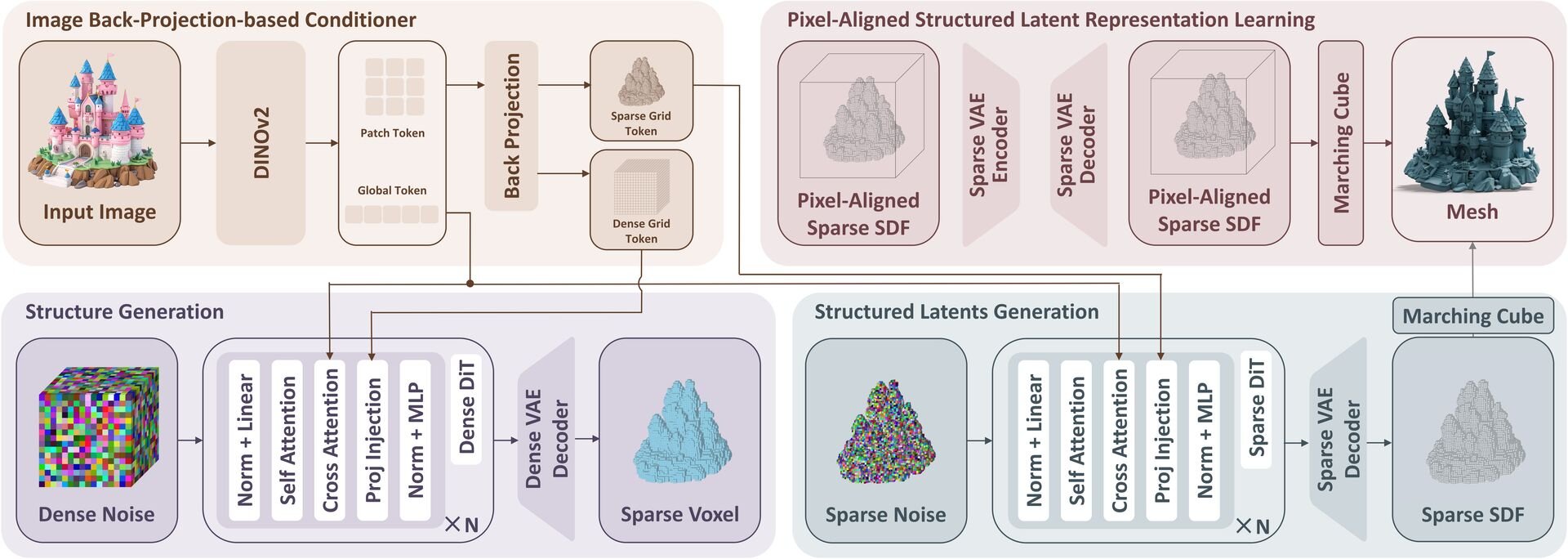
従来のImage to 3D生成モデルは、標準的な座標系であるキャノニカル空間(Canonical Space)で形状を生成し、アテンション機構を用いて画像の特徴を注入するアプローチが主流だった。しかし、この手法では2Dのピクセルと3D空間の対応関係が曖昧になり、入力画像の微細な情報が欠落しやすいという課題があった。
Pixal3Dは、写真測量などの3D再構築(3D Reconstruction)技術から着想を得て、キャノニカル空間を経由せず、入力視点に一致したピクセルアラインド(Pixel-Aligned)な状態で直接3Dモデルを生成する手法を採用することで、微細な情報の欠落という課題を解決している。
入力画像に忠実な3Dモデルの生成にあたっては、ピクセルバックプロジェクション条件付けスキーム(Pixel Back-Projection Conditioning Scheme)という中核技術が重要な役割を果たす。本技術では、複数の解像度で抽出された2D画像の特徴を、立体空間のデータ構造である3D特徴ボリューム(3D Feature Volume)へと直接的に投影(バックプロジェクション)する。これにより、画像の「どのピクセル」が3Dモデルの「どの位置」に該当するのかという対応関係が明確になり、AIによる推測の曖昧さを排除した高精度な生成が可能となる。
Pixal3Dは、複雑なジオメトリ形状とPBR対応の高精細テクスチャを同時に出力できる。また、ソースの限られた制作環境でも推論が実行できるよう、低VRAMモード(Low-VRAM mode)も搭載されている。
■Pixal3D: Pixel-Aligned 3D Generation from Images(プロジェクトページ)
https://ldyang694.github.io/projects/pixal3d/
■Pixal3Dデモページ(Hugging Face Space)
https://huggingface.co/spaces/TencentARC/Pixal3D
Introducing Pixal3D (SIGGRAPH’26) — a new pixel-aligned image-to-3D generation paradigm for high-fidelity 3D asset creation.
— Wang Zhao (@WangZhao_0849) May 12, 2026
Today’s Image-to-3D has become pretty good at producing plausible 3D assets. But plausibility is not enough. Fidelity is a hidden bottleneck.
A… pic.twitter.com/7F9emjmNzO
ライセンスについて
Pixal3DのソースコードはGitHub、学習済みモデルはHugging Faceで公開されており、どちらも適用ライセンスはMITライセンスとなっている。ただし、プロジェクト内で使用されているサードパーティ製の依存ライブラリ(dinov2、TRELLIS.2、Direct3D-S2、MoGe)については、各ライブラリのライセンスが適用される。
■Pixal3D: Pixel-Aligned 3D Generation from Images(GitHub)
https://github.com/TencentARC/Pixal3D
■Pixal3D: Pixel-Aligned 3D Generation from Images(Hugging Face)
https://huggingface.co/TencentARC/Pixal3D
CGWORLD関連情報
●Blenderを人間同様に操作して3Dシーンを生成するエージェント「Moonlake's 3D Agent」ベータ公開 AIがマウスとキーボードを操作し、モデリングからシーン構築、リギングまで実行

Moonlakeが単一画像から複雑な3D環境を自動生成するAI技術「Moonlake's 3D Agent」を発表。AIエージェントが3DCGツールの画面を認識し、人間と同様にアセットのモデリングやシーン構築、リジッドボディのセットアップまでを自律的に行う能力を持つ。第1弾の対応DCCツールはBlender。
https://cgworld.jp/flashnews/01-202605-Moonlake.html
●単一画像から顔と髪を切り離す頭部アバター生成手法「One-shot Compositional 3D Head Avatars with Deformable Hair」発表 3DGS、FLAME、物理演算の活用により自然なフェイシャル&ヘアアニメーションを実現

西安交通大学の研究チームが1枚の画像から髪の毛が自然に揺れる高品質な3D頭部アバターを生成する新手法「CompHairHead(One-shot Compositional 3D Head Avatars with Deformable Hair)」を発表。顔と髪の毛の要素を分離し、3DGSによるディテール豊かな3D表現と、FLAMEメッシュによる自然なフェイシャルアニメーション、ケージ構造と物理シミュレーションを適用したヘア表現を採用することで、リアルなフェイシャルアバターをリアルタイムでアニメーションさせることを可能にする。
https://cgworld.jp/flashnews/01-202605-1shotHead.html
●NVIDIA、物理シミュレーション対応の3D環境構築フレームワーク「Lyra 2.0」公開 長時間のウォークスルー動画生成と高品質な3Dシーン出力で大規模な環境構築を実現
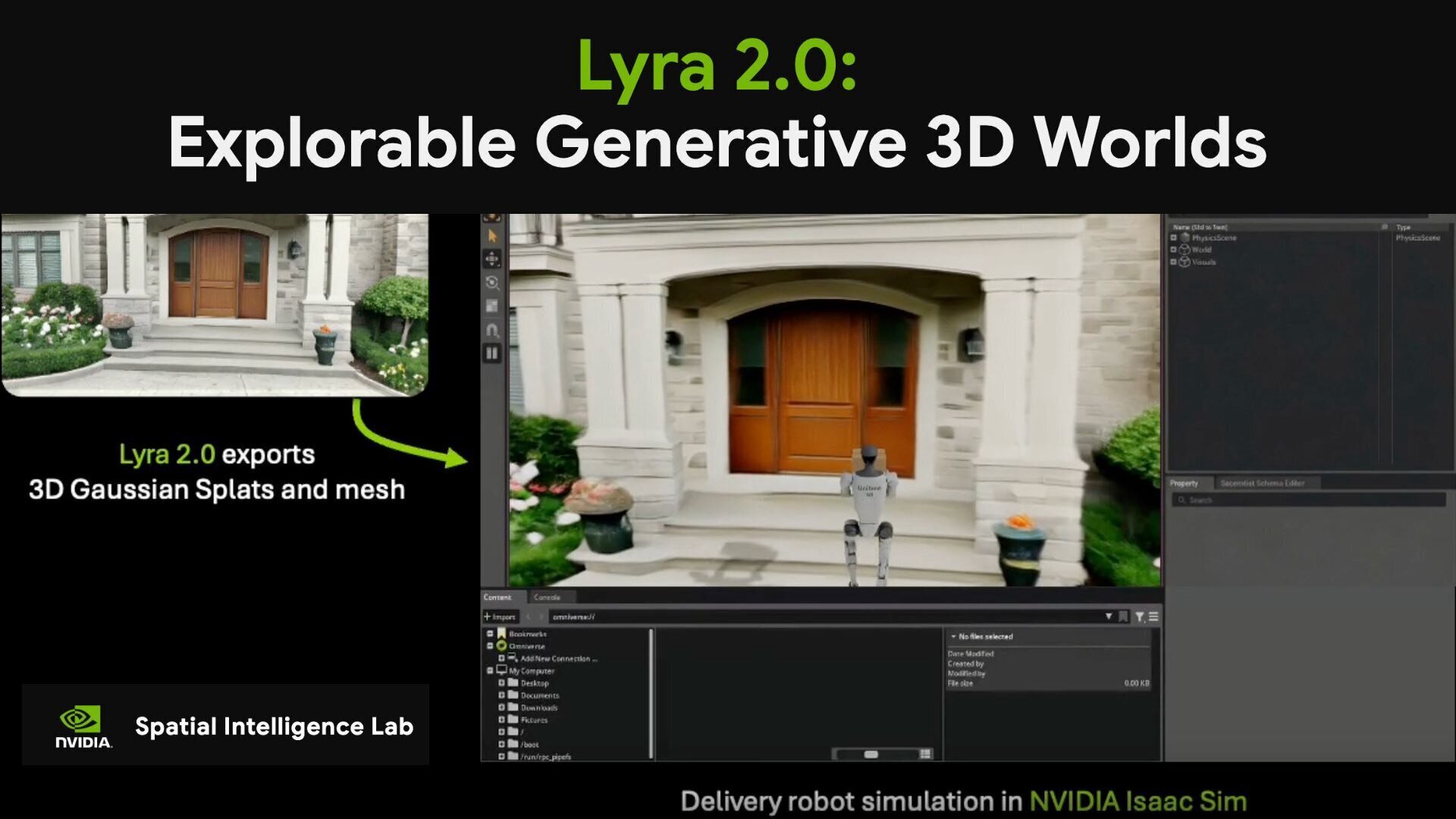
NVIDIAのSpatial Intelligence Lab(SIL)が、探索可能な生成3D世界を構築する新たなAIフレームワーク「Lyra 2.0」を発表。カメラ操作の可能なウォークスルー動画を生成し、フィードフォワード再構成技術によって3D空間を生成することで、大規模で複雑な3D環境の構築を実現する。ソースコードはApache-2.0ライセンスでGitHubにて、モデルはNVIDIA Internal Scientific Research and Development Model License(非商用の研究開発用途限定)でHugging Faceで公開されている。
https://cgworld.jp/flashnews/01-202605-Lyra2.html












