
みなさんこんにちは。ここ最近高騰していたCPUやGPUの価格がちょっと落ち着いてきたのでAMD Ryzen 9 5950XとNVIDIA GeForce RTX 3080で計算機をリニューアルしました。以前がAMD Ryzen2700X+NVIDIA GeForce GTX1080だったのでかなりのパワーアップになります。リニューアルのためにPCパーツの価格を調べた感じでは、CPUやメモリは比較的落ち着いてきていてコロナ禍以前と同水準まで戻ってきているみたいですね。ただ、GPUだけは高いままで、RTX3090が発売開始時の予定価格23万円に対して今が30万円と、かなり買う気が削がれる価格のままになってしまっています。GPUなしでは仕事できないCG屋さんにとっては辛い状況がまだまだ続きそうです。
TEXT_痴山紘史 / Hiroshi Chiyama(日本CGサービス)
EDIT_尾形美幸 / Miyuki Ogata(CGWORLD)

プログラムを計測する
前回は流行りに乗って計算量について考えていきました。計算量は設計やプログラミングの段階で将来発生する問題を予測・回避するための強力な手段ではあるものの、実際の環境で動かした際に本当に影響があるのかどうかを知ることはできません。例えば、精々100個程度のアイテムから必要な要素を取り出すだけで良ければ、頭から順番に探していく方法をとったとしても何の苦もなく処理できてしまうでしょう。そのような処理に対して計算量や処理時間を見積もり、がんばって最適化をしても全体に対する効果は微々たるものに過ぎません。むしろ、わかりにくいアルゴリズムやデータ構造の採用、コードの複雑化によるメンテナンス性の低下といったマイナス面が大きくなってきてしまいます。
では、どのタイミングでどのような対応をとるべきかを知るには、どうすれば良いでしょうか。その疑問に対する答えのひとつが、プログラムを計測するという手段です。処理時間やメモリ使用量に問題が起きたときに、プログラムのどの部分が原因になっているのかを知ることで適切な対応をとることができます。今回はプログラムの計測と取得した情報の活かし方について考えていきます。
プログラムを計測するタイミング
ツールを作成しているとき、必ずと言っていいほど「遅い」という報告がユーザーから上がってきます。その際、闇雲に最適化を行なったりキャッシュをはさんだりするのではなく、きちんとパフォーマンスを計測して、どこがボトルネックなのかを突き止め、修正した結果どの程度速くなったのか(もしくは、遅くなったのか)を数値化することが大事です。
最も良くないのが、何となく遅いから、勘で「あそこかな? ここかな?」とあたりをつけて、何となく内容を変更してそのままにしてしまうことです。これは何かやった気になっているだけできちんとした対応とは言えないです。たとえ症状が改善しても、果たしてそこが問題の根本原因なのかわからないですし、対応前後でどの程度改善されたのか確認できなければ客観的な成果として示すことができません。
行うべきは
1. 原因の目星をつける
2. 計測する
3. プログラムを変更する
4. 計測する
5. 目標通りの結果が得られるまで1~4を繰り返す
という手順を踏むことです。
Pythonでのプロファイリング
パフォーマンスを計測するためのツールとして、プロファイラというものがあります。Pythonでプロファイリングを行う方法はいくつかありますが、cProfileを使用するのが無難でしょう。使い方はとても簡単です。
import cProfile
def some_very_heavy_process():
:
cProfile.run('some_very_heavy_process()')
こうすることで、some_very_heavy_process() を行なった際に、どの関数でどれだけ処理に時間がかかったかを把握できます。ただ、このままだとプロファイリング結果が画面に出力されるだけで使い勝手が悪いのでファイルに保存します。コマンドラインからは
> python -m cProfile -o < outputfilename > < script-name > < options >
こんな感じで実行すれば script-name のプロファイリング結果が outputfilename に出力されます。先ほどと同じようにコード中で実行する場合、
cProfile.runctx('some_very_heavy_process()', globals(), locals(), filename='outputfilename' )
となります。
プロファイリング結果を解析する
プロファイリング結果が取得できたら内容を解析します。cProfile の出力結果を自分で加工しながら読めば詳細を自由に確認することもできるのですが、もうちょっとお手軽に確認したいのでGUIベースのツールを使用します。私はRunSnakeRunを昔から愛用しています。pipでもprofile-viewerとして登録されているようです。
下図は、プロファイリングした結果を RunSnakeRun に読み込んだ状態です。関数の呼び出しが入れ子表示になっており、処理時間がそのまま大きさとなっています。
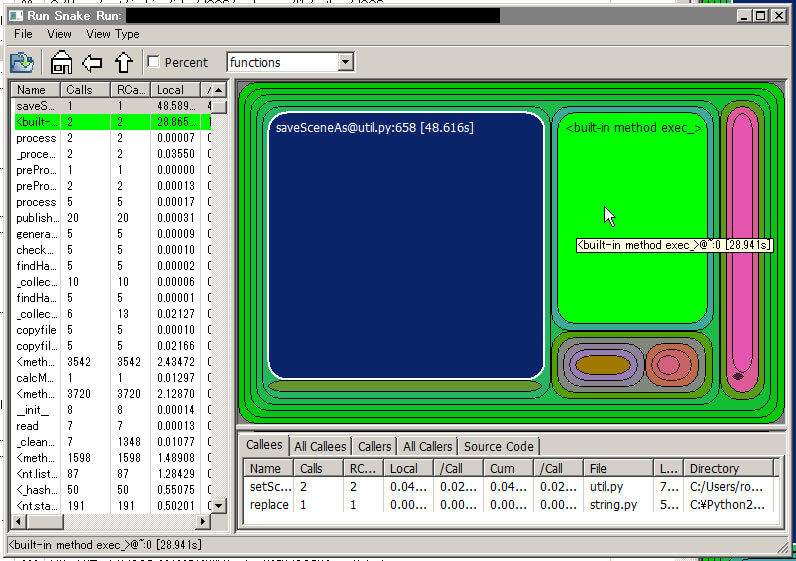
この場合、処理の約半分 saveSceneAs(48.6秒)を占めているため、例えば saveSceneAs の処理時間が半分になれば全体で25~30%程度高速化できますし、もし saveSceneAs の処理時間がほぼゼロになれば全体で倍以上高速化できるということがわかります。
ちなみに、以下は最近採取した絶望的なプロファイリング結果です。他にもいろいろ処理しているのにSQL処理が大半で、これだけで50秒かかっているというものです。
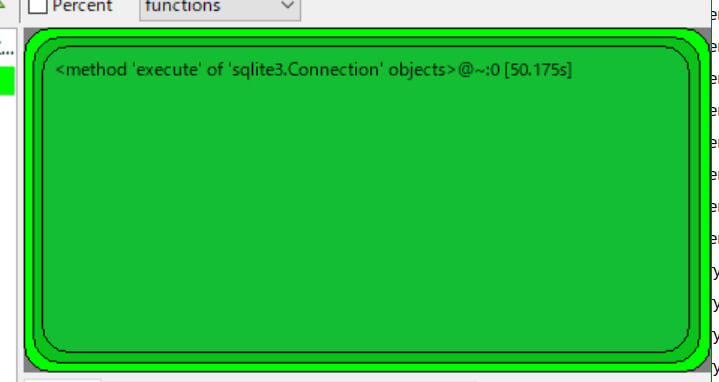
このようなデータは収集したときには頭を抱えてしまうものの、問題が一点に集中しているため対処がしやすいです。この場合も最終的にSQLでの処理を1秒以下にでき、ほぼ一瞬で処理を終えられるようになりました。このときは、Python内の処理をいくらいじっても効果がないことがわかっていたので、SQL内部を見直すべきだという判断ができました。これもプロファイリングをとっていたおかげです。
最適化をする際の注意点
プログラムの計測ができるようになると、どこまでも最適化したくなってきます。前述の RunSnakeRun の画面で言うと、SaveSceneAs が小さくなると次に exec_ と赤い部分が大きく見えるようになり、exec_ を小さくすると赤い部分が目立ってきます。これはちょっとした泥沼で、注意しないと全体に対してほとんど影響のない部分の最適化を延々行なってしまうことになりかねません。
基本的に、実用上問題ない速度で動いているのなら何もせず、問題になったときに計測と最適化を行います。また、最適化も極力難しいことはしないで、読みやすい、メンテナンスしやすいコードを維持するよう心がけます。
最適化には、主に
1. アルゴリズムやデータ構造の見直し
2. コードの見直し
3. 可読性やメンテナンス性よりも速度を重視したコードの見直し
4. 高速な言語で書き直す
という段階があります。1では前回話題にした計算量が大きな助けになりますね。基本は1から順番に行い、それでも不十分な場合に次の段階に進みます。決して、いきなり3や4に進んでしまってはいけません。私の感覚では、最適化の8割はアルゴリズムやデータ構造の見直しで解決します。3まで必要になるのは、開発しているシステム内でも相当コアの部分になる感じです。これができるかどうかでシステム全体のパフォーマンスが大幅に変わるのでとても大事ですが、大抵は割に合わない作業となります。
また、計測をする際には可能な限り実際の環境と同じ状態で行うようにします。特にネットワークが絡むとプロファイリング結果の中身がガラリと変わってくることがあります。
例えば、ローカルのファイルにアクセスする場合には1ファイル1msで処理できていて、1,000ファイルあっても1秒、さらにほかの処理で10秒かかっていても全体で11 秒で済みます。この場合、全体に対するファイルアクセスは無視しても良いという判断ができます。それに対してネットワークごしにファイルアクセスした場合には1ファイル20msかかったとします。すると1,000ファイルで20秒、全体で30秒かかることになります。仮にユーザーがネットワークごしにファイルアクセスする環境で作業していて、開発者が自分のローカル環境でのみ動作確認をしていたら、まったく的外れな対応をしてしまい話が噛み合わなくなってしまうでしょう。
まとめ
今回はプログラムの計測と最適化に焦点を当てました。動いているプログラムをきちんと計測しないで開発を進めるというのは、地図も明かりもなしで旅をするようなものです。当たるも八卦当たらぬも八卦、いい感じの成果が出たら万歳というのは止めて、計測→修正→計測というループを繰り返すことで自分の位置を正確に把握すると共に、周囲に対しても成果を数値化して伝えることができるようにしましょう。実際に開発をしていても、ちょっとした工夫でスコーーーンと数十倍速くなった数字を目の当たりにするのはモチベーションという面でも大きなプラスになるのでおススメです。
第40回の公開は、2021年12月を予定しております。
プロフィール













