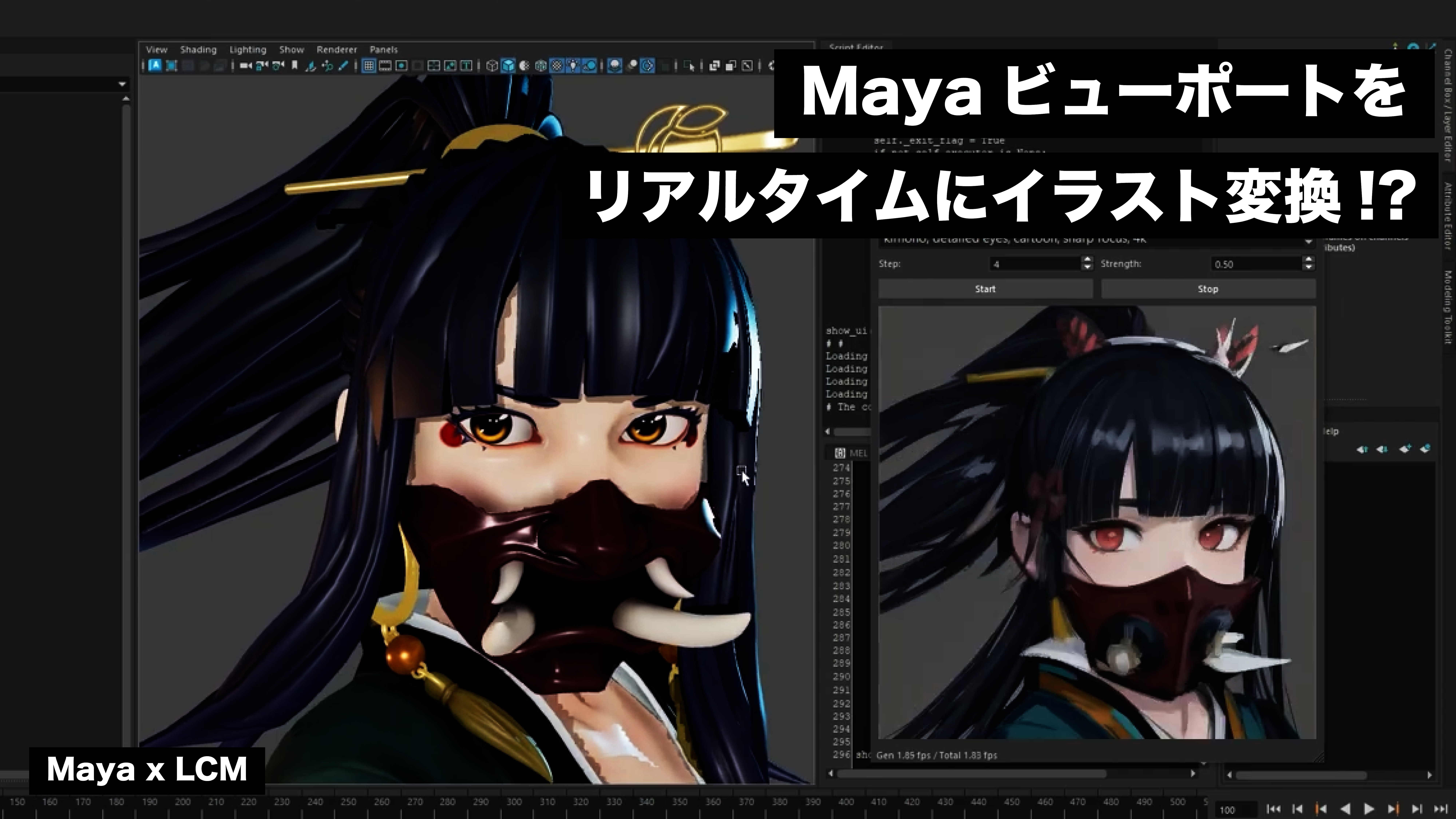
こんにちは。この連載では、AI生成技術と進化、3DCG制作現場への活用の可能性を探索していきます。今回取り上げるのは、高速で画像生成が出来ると話題のLCM-LoRAです。こちらを使用してMayaビューポートをリアルタイムにイラスト変換してみたいと思います。
AI関連の研究は日々驚くほどのスピードで進化しています。可能な限り正確な情報を提供するよう心掛けていますが、私自身も学習中であるため、記事中に誤りが含まれる可能性があることをご理解いただければ幸いです。

赤崎弘幸
Jet Studio Inc.所属のCGディレクター。
1. LCM-LoRAとは
Latent Consistency Model(以下LCM)(*1, *2)は、Stable DiffusionやSDXLを蒸留することで、生成に必要なステップ数を減らす手法です。元のモデルでは25~50ステップ必要だったものが4~8で済むようになり、結果的に少ない時間でそれなりの生成画像が得られるようになります。
*1. Latent Consistency Model(LCM)
*2. ASCII.jp:爆速化する画像生成AI。0.5秒で4枚出力、リアルタイム生成できるレベルに
そしてLCM-LoRA(*3, *4)は、この手法をLoRA形式で既存モデルに適用することで個別の訓練無しに使えるようにしたものになります。詳しくは参考リンクをご確認ください。
*3. LCM-LoRA: A Universal Stable-Diffusion Acceleration Module
*4. SDXL in 4 steps with Latent Consistency LoRAs
今回はこちらを使用して、Maya上で高速Image-to-Image(以下i2i)によるビューポートのリアルタイム変換をしてみたいと思います。
2. セットアップ
現在主流となっているStable Diffusionのローカル実行環境にはstable-diffusion-webuiやComfyUIがありますが、今回は直接Mayaに組み入れてみようと思いますので、GUIではなくPythonライブラリのDiffusersを使います。導入のハードルが少々高めで恐縮ですがPythonとCUDAは導入済みの前提で進めます。
<テスト環境>
・Windows 10
・NVIDIA GeForce RTX 3060 12GB
・VSCode
・Python 3.10.9
・CUDA Toolkit 12.1.1
まずはMayaとの連携の前に、DiffusersでLCM-LoRAを正常に動かせるかシンプルな環境で確認してみます。テスト用の仮想環境を作成し必要なパッケージをインストールしていきます。ここではPyTorchは2.1.0+cu121を、diffusersは現時点で最新の0.24.0を入れています(必ずしも一致させる必要はありません)。これらは後ほどMayaにもインストールします。
<テスト用仮想環境の作成>
python -m venv venv
venv\scripts\activate
pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu121
pip install diffusers transformers accelerate参考までに、上記インストール後の「pip freeze」の出力結果は以下の通りです。
accelerate==0.25.0
certifi==2022.12.7
charset-normalizer==2.1.1
colorama==0.4.6
diffusers==0.24.0
filelock==3.9.0
fsspec==2023.12.0
huggingface-hub==0.19.4
idna==3.4
importlib-metadata==7.0.0
Jinja2==3.1.2
MarkupSafe==2.1.3
mpmath==1.3.0
networkx==3.0
numpy==1.24.1
packaging==23.2
Pillow==9.3.0
psutil==5.9.6
PyYAML==6.0.1
regex==2023.10.3
requests==2.28.1
safetensors==0.4.1
sympy==1.12
tokenizers==0.15.0
torch==2.1.0+cu121
torchaudio==2.1.0+cu121
torchvision==0.16.0+cu121
tqdm==4.66.1
transformers==4.35.2
typing_extensions==4.4.0
urllib3==1.26.13
zipp==3.17.03. diffusersで LCM-LoRAを試す
環境が整ったら以下のLCM-LoRAでText-to-Image(以下、t2i)するスクリプトを実行してみます。スクリプトはこちらを参考に書いています。
<LCM-LoRAのt2iスクリプト>
import time
import torch
from diffusers import AutoPipelineForText2Image, LCMScheduler
# 使用するモデルのIDを設定
model_id = "" # ここにdiffusersで使えるモデル名を入力。例: "runwayml/stable-diffusion-v1-5"
lcm_lora_id = "latent-consistency/lcm-lora-sdv1-5"
# パイプラインを初期化
pipeline = AutoPipelineForText2Image.from_pretrained(
model_id,
use_safetensors=True
)
pipeline.to(device="cuda", dtype=torch.float16)
# スケジューラをLCMSchedulerに設定
pipeline.scheduler = LCMScheduler.from_config(pipeline.scheduler.config)
# LoRAウェイトを読み込み、パイプラインに統合
pipeline.load_lora_weights(lcm_lora_id)
pipeline.fuse_lora()
# プロンプトを設定
prompt = "anime, best quality, 1girl, solo, white hair, pony tail, red jacket, shorts, red eyes, goggles on head, detailed eyes, cartoon, sharp focus, 4k"
# Generatorを初期化
generator = torch.Generator("cuda")
for i in range(5):
st = time.time()
# 画像を生成し、結果を取得
image = pipeline(
prompt,
guidance_scale=1.0,
num_inference_steps=4,
generator=generator.manual_seed(1234)
).images[0]
# 処理時間を出力
print(time.time() - st)
# 生成した画像をファイルに保存
image.save("test_{}.png".format(i))
実行すると同じ条件で5枚生成され、かかった時間が表示されます。
<スクリプト実行時の出力>

初回のみ少し時間がかかっていますが、2枚目以降は1枚あたり約0.48秒で生成されていることがわかります。GPUのスペックやモデルの種類にもよりますが、私の環境ではLCM無しと比較して約6倍の高速化となりました。
次のスクリプトはLCMを外して通常通り20ステップほどで生成する比較用のスクリプトです。1枚の生成に3秒弱かかっています。
<LCM無しスクリプト(比較用)>
import time
import torch
from diffusers import AutoPipelineForText2Image
model_id = "" # ここにdiffusersで使えるモデル名を入力。例: "runwayml/stable-diffusion-v1-5"
pipeline = AutoPipelineForText2Image.from_pretrained(
model_id,
use_safetensors=True
)
pipeline.to(device="cuda", dtype=torch.float16)
prompt = "anime, best quality, 1girl, solo, white hair, pony tail, red jacket, shorts, red eyes, goggles on head, detailed eyes, cartoon, sharp focus, 4k"
generator = torch.Generator("cuda")
for i in range(5):
st = time.time()
image = pipeline(
prompt,
num_inference_steps=20,
generator=generator.manual_seed(1234)
).images[0]
print(time.time() - st)
image.save("test_{}.png".format(i))
<LCM無しスクリプト実行時の出力>

以下の画像は、前述のスクリプトでテスト生成した画像(LCM有り無しの比較)です。パラメーターが更新されているため結果は変わりますが、ステップを大幅に減らしたわりに破綻していないことが分かります。
<出力結果の比較>

4. Mayaへ組み込み
Diffusersのパイプラインを使用してサクッとLCMが試せることが確認できましたので、これをi2iのパイプラインに変えてMaya上で実行してみます。まずテスト用の仮想環境に入れたパッケージと同じものをMayaへインストールします。今回はMaya 2024を使います。
<Maya 2024へのインストールコマンド>
cd C:\Program Files\Autodesk\Maya2024\bin
mayapy -m pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu121 -t C:\Users\<USERNAME>\Documents\maya\2024\scripts\site-packages
mayapy -m pip install diffusers transformers accelerate -t C:\Users\<USERNAME>\Documents\maya\2024\scripts\site-packages
Mayaのビューポートをi2iするため、ビューポートをキャプチャするコードを準備します。以下のスクリプトは、アクティブなビューポート(=modelPanel)を取得しQWidgetに変換した後、QPixmap形式でキャプチャするスクリプトです。ここから先のスクリプトは全てMaya上で実行します。
<ビューポートキャプチャスクリプト>
from maya import cmds, OpenMayaUI
from PySide2 import QtWidgets, QtGui, QtCore
from shiboken2 import wrapInstance
def get_active_modelpanel():
# Mayaのモデルパネルのリストを取得
m_panels = cmds.getPanel(type='modelPanel')
# モデルパネルがある場合、それぞれをチェック
if m_panels:
for m_panel in m_panels:
# アクティブなモデルエディタがあれば、その名前を返す
if cmds.modelEditor(m_panel, q=True, av=True):
return m_panel
# アクティブなモデルパネルがない場合、何も返さない
return
def active_panel_to_widget():
# アクティブなモデルパネルを取得
panel = get_active_modelpanel()
# パネルが存在しなければ何も返さない
if not panel:
return
# パネルのQWidgetを取得
ptr = OpenMayaUI.MQtUtil.findControl(panel)
wgt = wrapInstance(int(ptr), QtWidgets.QWidget)
# ウィジェットを返す
return wgt
"""
(確認用)アクティブなビューポートをキャプチャし、PNGに保存します。
"""
# アクティブなモデルパネルのウィジェットを取得
wgt = active_panel_to_widget()
# ウィジェットの現在の状態をQPixmapとしてキャプチャ
pixmap = QtGui.QPixmap.grabWindow(wgt.winId())
# 画像をファイルに保存
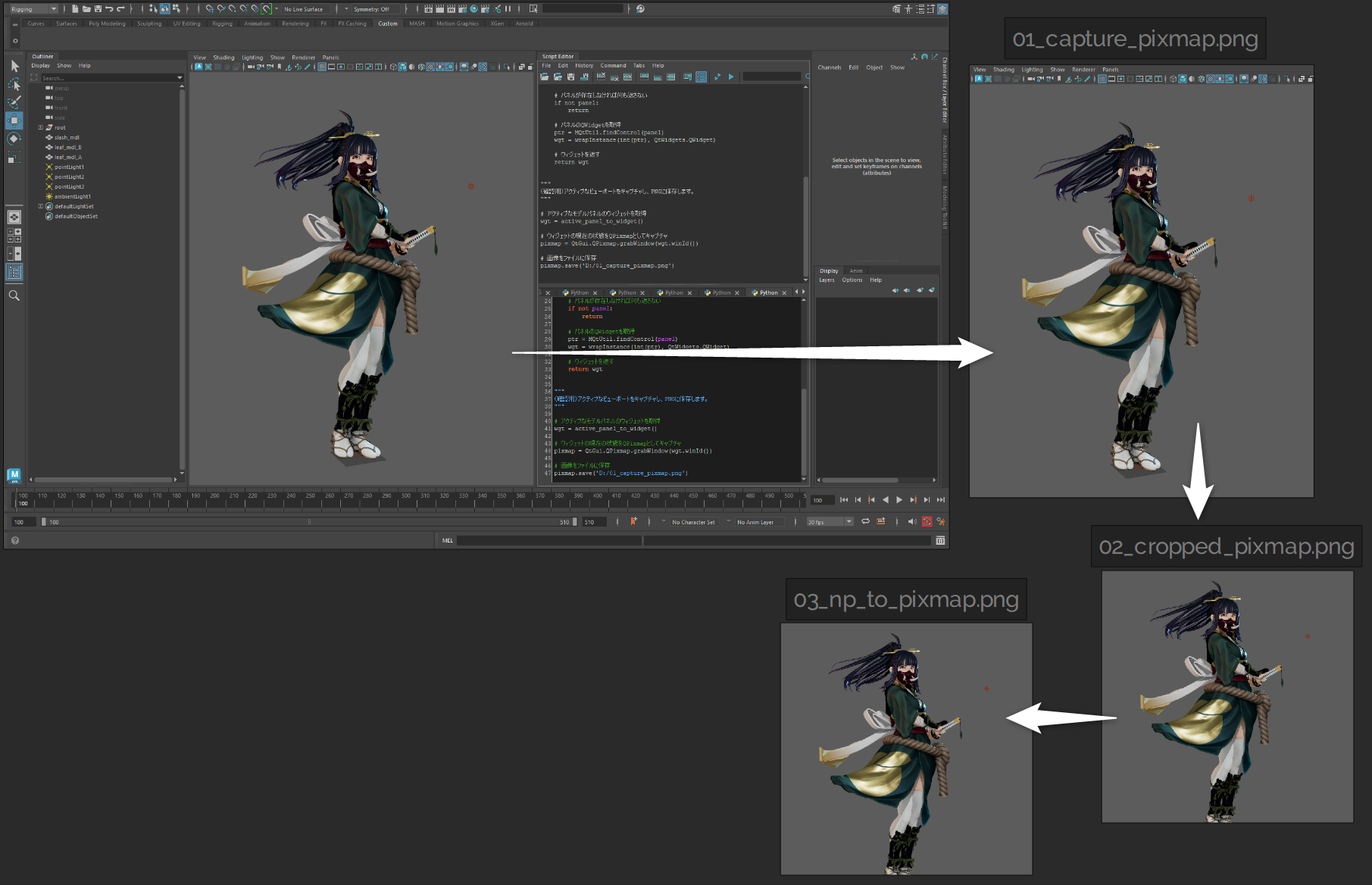
pixmap.save('D:/01_capture_pixmap.png')
キャプチャしたQPixmapをi2iに送りたいのですがPNGファイルに保存していては処理が遅くなってしまいますので、QPixmapを整形しつつNumPy配列に変換してパイプラインに送りたいと思います。
また、パイプラインからの生成結果はデフォルトではPILイメージで返されますが、これは少し変換に時間がかかるのでNumPy配列で受け取りたいと思います。
画像生成への入出力はいずれもNumPy配列にして、その前後でQPixmapに変換する形になります。
以下のスクリプトは、
・QPixmapを512×512にリサイズ&クロップする関数
・QPixmapをNumPy配列に変換する関数
・NumPy配列をQPixmapに変換する関数
です。ちなみに余談ですが、この手の関数は大部分をChatGPTに書いてもらっています。
<変換スクリプト>
import math
import numpy as np
from PySide2 import QtWidgets, QtGui, QtCore
def crop_pixmap(pixmap: QtGui.QPixmap, size: int = None) -> QtGui.QPixmap:
# 元の幅と高さを取得
original_width = pixmap.width()
original_height = pixmap.height()
# リサイズするためのスケールを計算
scale = 512 / min(original_width, original_height)
new_width = math.ceil(original_width * scale)
new_height = math.ceil(original_height * scale)
# リサイズ
pixmap = pixmap.scaled(new_width, new_height, QtCore.Qt.KeepAspectRatio)
# クロップする位置を計算
x = (pixmap.width() - size) // 2
y = (pixmap.height() - size) // 2
# size x size の正方形にクロップ
cropped_pixmap = pixmap.copy(x, y, size, size)
return cropped_pixmap
def pixmap_to_np(qpixmap: QtGui.QPixmap) -> np.ndarray:
# QPixMapをQImageに変換
qimage = qpixmap.toImage()
# QImageのフォーマットがRGB32でない場合は、RGB32に変換
if qimage.format() != QtGui.QImage.Format_RGB32:
qimage = qimage.convertToFormat(QtGui.QImage.Format_RGB32)
# QImageの幅と高さを取得
width, height = qimage.width(), qimage.height()
# QImageのビットデータを取得
ptr = qimage.bits()
# QImageからNumPy配列に変換
np_array = np.frombuffer(ptr, dtype=np.uint8)
np_array = np_array.reshape((height, width, 4)) # H x W x 4 にリサイズ
np_array = np_array[:, :, :3] # RGBAからRGBだけを取り出し
np_array = np_array[..., ::-1] # BGR形式に変換
np_array = np_array.astype(np.float32) / 255.0 # 0-1の範囲に正規化
return np_array
def np_to_pixmap(numpy_array: np.ndarray) -> QtGui.QPixmap:
# NumPy配列を8ビット整数に変換
numpy_array = (numpy_array * 255).astype(np.uint8)
height, width, channel = numpy_array.shape
bytes_per_line = 3 * width
# NumPy配列からQImageを作成
numpy_array_contiguous = np.ascontiguousarray(numpy_array)
qimage = QtGui.QImage(numpy_array_contiguous.data, width, height, bytes_per_line, QtGui.QImage.Format_RGB888)
# QImageからQPixMapに変換
qpixmap = QtGui.QPixmap.fromImage(qimage)
return qpixmap
"""
(確認用)
ひとつ前のキャプチャスクリプトの続きに↓これを書きます。
クロップ後に一度PNG保存し、正常に変換できるか確認のためNumPyに変換後そのまま元に戻してまたPNG保存、としています。
"""
# QPixmapをクロップして新しいQPixmapを作成
cropped_pixmap = crop_pixmap(pixmap, 512)
# クロップしたQPixmapをファイルに保存
cropped_pixmap.save('D:/02_cropped_pixmap.png')
# QPixmapをNumPy配列に変換
np_image = pixmap_to_np(cropped_pixmap)
# NumPy配列からQPixMapに変換
pixmap = np_to_pixmap(np_image)
# 変換されたQPixMapをファイルに保存
pixmap.save('D:/03_np_to_pixmap.png')
<画像変換処理の確認>
では下準備が出来ましたので、生成と結果表示をするUIを作成します。UI起動時にパイプラインを初期化し、生成ループはスタートボタンを押した時にThreadPoolExecutorを使用して別スレッドで起動します。以下がそのスクリプトです。ここまでで用意した関数もすべて合わせます。
<メインスクリプト>
import gc
import time
import numpy as np
import math
from concurrent.futures import ThreadPoolExecutor
import torch
from diffusers import AutoPipelineForImage2Image, LCMScheduler
from maya import cmds, OpenMayaUI
from PySide2 import QtWidgets, QtGui, QtCore
from shiboken2 import wrapInstance
### ↓ 前述の関数をここに書きます ↓ ###
def get_active_modelpanel():
### 中略 ###
def active_panel_to_widget():
### 中略 ###
def crop_pixmap(pixmap: QtGui.QPixmap, size: int = None) -> QtGui.QPixmap:
### 中略 ###
def pixmap_to_np(qpixmap: QtGui.QPixmap) -> np.ndarray:
### 中略 ###
def np_to_pixmap(numpy_array: np.ndarray) -> QtGui.QPixmap:
### 中略 ###
####################################
def maya_main_window():
main_window_ptr = OpenMayaUI.MQtUtil.mainWindow()
return wrapInstance(int(main_window_ptr), QtWidgets.QMainWindow)
def show_ui():
window = ImageWindow(parent=maya_main_window())
window.show()
model_id = "" # ここにdiffusersで使えるモデル名を入力。例: "runwayml/stable-diffusion-v1-5"
lcm_lora_id = "latent-consistency/lcm-lora-sdv1-5"
class ImageWindow(QtWidgets.QMainWindow):
def __init__(self, parent=None, *args, **kwargs):
super(ImageWindow, self).__init__(parent, *args, **kwargs)
self.executor = None
self.init_pipe() # パイプラインの初期化
self.init_ui() # UIの初期化
self.encode_prompt() # プロンプト事前エンコード
self.update_step() # step値アップデート
def init_ui(self):
self.setWindowTitle("LCM Viewport Img2Img")
self.statusBar()
# Prompt
self.user_input = QtWidgets.QPlainTextEdit()
self.user_input.setPlaceholderText("prompt...")
self.user_input.setFixedHeight(50)
self.user_input.setStyleSheet("QPlainTextEdit {font-size: 15px;}")
self.user_input.textChanged.connect(self.encode_prompt)
# Step
self.step_label = QtWidgets.QLabel("Step:")
self.step_spinbox = QtWidgets.QSpinBox()
self.step_spinbox.setValue(4)
self.step_spinbox.setMinimum(1)
self.step_spinbox.valueChanged.connect(self.update_step)
# Strength
self.strength_label = QtWidgets.QLabel("Strength:")
self.strength_spinbox = QtWidgets.QDoubleSpinBox()
self.strength_spinbox.setValue(0.5)
self.strength_spinbox.setSingleStep(0.05)
self.strength_spinbox.setRange(0, 1)
self.strength_spinbox.valueChanged.connect(self.update_step)
# スタートボタン
start_button = QtWidgets.QPushButton("Start")
start_button.clicked.connect(self.start)
# ストップボタン
stop_button = QtWidgets.QPushButton("Stop")
stop_button.clicked.connect(self.stop)
# 画像表示用のラベル
self.pix_label = QtWidgets.QLabel()
# レイアウト
hBoxLayout1 = QtWidgets.QHBoxLayout()
hBoxLayout1.addWidget(self.step_label)
hBoxLayout1.addWidget(self.step_spinbox)
hBoxLayout1.addWidget(self.strength_label)
hBoxLayout1.addWidget(self.strength_spinbox)
hBoxLayout2 = QtWidgets.QHBoxLayout()
hBoxLayout2.addWidget(start_button)
hBoxLayout2.addWidget(stop_button)
main_layout = QtWidgets.QVBoxLayout(self)
main_layout.addWidget(self.user_input)
main_layout.addLayout(hBoxLayout1)
main_layout.addLayout(hBoxLayout2)
main_layout.addWidget(self.pix_label)
widget = QtWidgets.QWidget(self)
widget.setLayout(main_layout)
self.setCentralWidget(widget)
def init_pipe(self):
# Pipeline
self.pipe = AutoPipelineForImage2Image.from_pretrained(
model_id,
use_safetensors=True,
safety_checker=None,
feature_extractor=None
)
# LCM
self.pipe.scheduler = LCMScheduler.from_config(self.pipe.scheduler.config)
self.pipe.load_lora_weights(lcm_lora_id)
self.pipe.fuse_lora()
# UNETメモリフォーマット
self.pipe.unet = self.pipe.unet.to(memory_format=torch.channels_last)
# プログレスバー非表示
self.pipe.set_progress_bar_config(disable=True)
self.pipe.to(device="cuda", dtype=torch.float16)
def encode_prompt(self):
"""プロンプトの事前エンコード"""
self.prompt_embeds, self.n_prompt_embeds = self.pipe.encode_prompt(
prompt=self.user_input.toPlainText(),
device="cuda",
num_images_per_prompt=1,
do_classifier_free_guidance=False,
)
def update_step(self):
"""step値の更新"""
step = self.step_spinbox.value()
self.strength = self.strength_spinbox.value()
self.num_inference_steps = math.ceil(step / self.strength)
def cap(self):
"""キャプチャ&生成"""
generator = torch.Generator("cuda")
while not self._exit_flag:
st = time.time()
# アクティブなビューポートのウィジェットを取得
wgt = active_panel_to_widget()
if not wgt:
# ビューポートが無ければ0.5秒待って再試行
time.sleep(0.5)
continue
# 現在の状態をQPixmapとしてキャプチャ
pixmap = QtGui.QPixmap.grabWindow(wgt.winId())
# 512 x 512にクロップ後、NumPy配列に変換
cropped_pixmap = crop_pixmap(pixmap, 512)
np_image = pixmap_to_np(cropped_pixmap)
gen_st = time.time()
# 画像生成
gen_image = self.pipe(
prompt_embeds=self.prompt_embeds, # promptの代わりにエンコード済みprompt入力
image=np_image,
strength=self.strength,
guidance_scale=1.0,
num_inference_steps=self.num_inference_steps,
generator=generator.manual_seed(0),
output_type="np"
).images[0]
gen_fps = 1.0 / (time.time() - gen_st)
# NumPy配列をQPixmapに変換してUIに表示
pixmap = np_to_pixmap(gen_image)
self.pix_label.setPixmap(pixmap)
# FPSをステータスバーに表示
fps = 1.0 / (time.time() - st)
self.statusBar().showMessage("Gen {:.2f} fps / Total {:.2f} fps".format(gen_fps, fps))
def start(self):
# cap関数を別スレッドで起動
self._exit_flag = False
self.executor = ThreadPoolExecutor(max_workers=1)
self.executor.submit(self.cap)
def stop(self):
# スレッド終了
self._exit_flag = True
if not self.executor is None:
self.executor.shutdown(wait=True)
def closeEvent(self, event):
# 停止処理
self.stop()
# メモリ解放
del self.pipe
del self.prompt_embeds
del self.n_prompt_embeds
gc.collect()
torch.cuda.empty_cache()
show_ui()実行したらアクティブなビューポートがキャプチャされ、リアルタイムに変換が始まりました。ステータスバーに生成部分のみのFPSと画像変換を含む実質FPSを表示していますが、1.5fps前後で出力されていることが分かります。
5. 最後に
今回の実験では、リアルタイムレンダリング後のポスプロ処理をイメージしてみました。Mayaビューポートはあくまでプレビュー用途のものでしたが、ゲームエンジンなどの高品質なリアルタイムレンダラーと組み合わせるといろいろと面白いことが出来そうです。3Dである程度作り込んで細かな調整はAIに任せるというアプローチも、高速化が進むと使い勝手が増していくような気がします。今回のLCMはControlNetなど別の手法とも組み合わせられますし、例えばGバァッファをそのままControlNetに送り込むとか(技術的に可能かは分かりませんが)、レンダリングパイプラインに直接組み込むような例も出てくるかもしれません。
11月はStabilityAI公式からもSDXL-Turboが公開されていますし、言語モデルではGPT-4もTurboが発表されていました。高性能なモデルを軽量化(または高速化)してさらに普及させる流れが流行り始めているようにも思います。
最後までお読みいただき、ありがとうございます。今回は画像生成の高速化を紹介させていただきました。速度が上がるとさらなる組み合わせの応用例がたくさん出てくることが予想されます。次回以降も様々なAI技術と3DCGの応用について探求していきますので、お楽しみに!













