
こんにちは。この連載では、AI生成技術と進化、3DCG制作現場への活用の可能性を探索していきます。今回取り上げるのは、オープンソースの画像生成AI StableDiffusionとControlNet、3Dレンダラの連携についてです。
AI関連の研究は日々驚くほどのスピードで進化しています。可能な限り正確な情報を提供するよう心がけていますが、私自身も学習中であるため、記事中に誤りが含まれる可能性があることをご理解いただければ幸いです。

赤崎弘幸
Jet Studio Inc.所属のCGディレクター。
1. ControlNetとは
ControlNet(以下CN)はエッジマップ、セグメンテーションマップ、デプスマップなどの追加の入力によりStable Diffusionのような拡散モデルを制御する手法です(*1,*2,*3)。詳細は参考リンクをご確認いただくとして、今回はこの追加入力を3Dレンダリングにより用意したいと思います。
元素材が実写などの場合は各種Preprocessorを使用してマップを作成する方法がとられますが、3Dで元素材を作成しているのであればAOVなどを使用してより精度の高い入力素材を用意できるかと思います。
<参考リンク>
*1 ASCII.jp:画像生成AIに2度目の革命を起こした「ControlNet」
*2. Adding Conditional Control to Text-to-Image Diffusion Models
*3. lllyasviel/ControlNet: Let us control diffusion models!
<テスト環境>
・Windows 10
・NVIDIA GeForce RTX 3060 12GB
・Python 3.10.6
・stable-diffusion-webui v1.4.0
・sd-webui-controlnet v1.1.232
・sd-webui-controlnet-TemporalNet-API v1.1.224
2. 入力素材を3Dレンダリングで作成
今回は、Mayaで作成した3Dキャラクターのアニメーションを使用し、ArnoldとPencil+ 4 で素材レンダリングをします。他の3DCGツールでもたいていは同等のものが出力可能かと思いますので、必ずしもMayaである必要はありません。
また、ひと通り出力方法を紹介しますが全てが必須素材というわけではありません。必要に応じて取捨選択をしていただければと思います。実際に、次項で紹介する出力例ではNormalは使用しませんでした。
Beauty
Tileに入力するための素材です。text2imgの場合、色情報はこの素材とプロンプトにしかないのでそこそこ重要です。必要に応じてライティングもしておきます。

Normal
Normalに入力するための素材です。こちらはレンダリング後、背面に[0.5, 0.5, 1]の単色平面を合成してあります。

Available AOVsにある「N」はワールドスペースのノーマルですので使用せず、Custom AOVを別途作成しsamplerInfoとaiRangeを画像のように接続します。
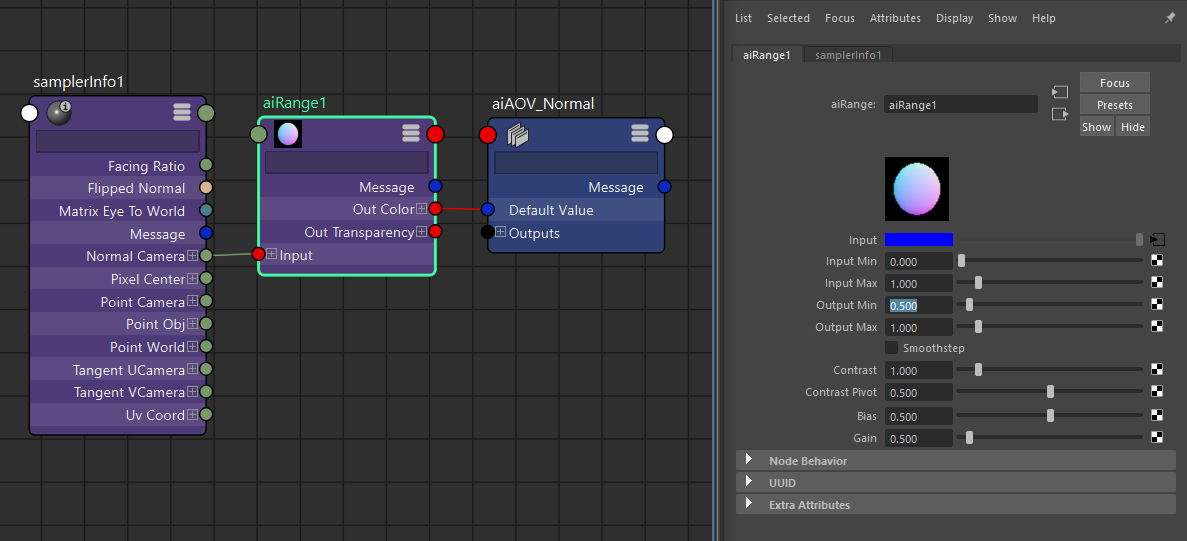
Depth
Depthに入力するための素材です。こちらはAvailable AOVsから「Z」を使用しています。EXR形式で出力した後、キャラクターの奥行きが階調に収まるように露出やレベルを補正してあります。

Material ID
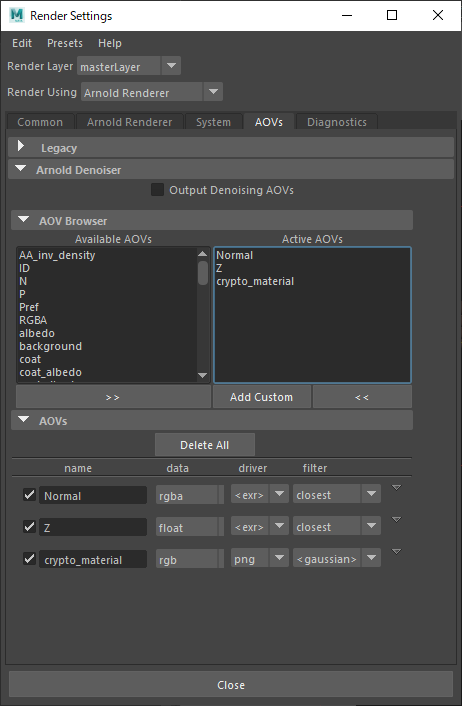
Segに入力するための素材です。Available AOVsから「crypto_material」をそのまま使います。

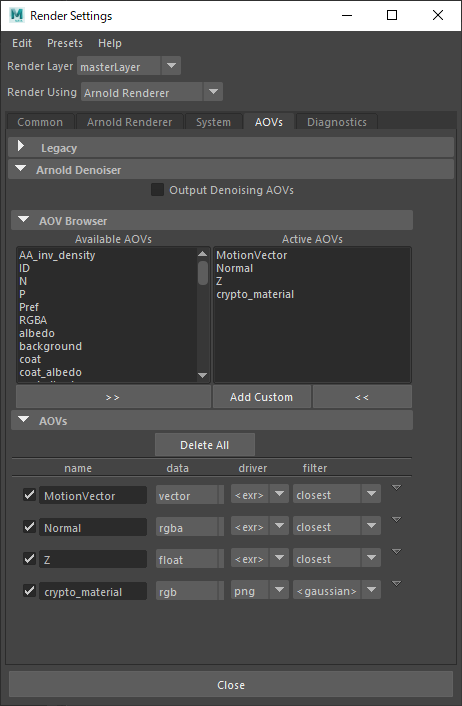
ここまでの3種のAOVを含めた[Render Settings→AOVs] タブは以下のようになっています。
Pencil+ 4 Line
Lineartに入力するための素材です。Pencil+ 4を使用して黒単色のマテリアルに白のラインとなるよう設定しました。今回は細かい制御がしやすいPencil+ 4 Lineを使用していますが、ArnoldのaiToonを使用しても簡易的なライン出力が行えます。

3. バッチ出力
AUTOMATIC1111/stable-diffusion-webui(以下webui)を使用して、前項の各素材をCNへ入力し画像を生成します。
まず、事前準備として以下を全て満たしているものとします。前提条件が多く恐縮ですがどうかご了承ください。
・webuiの実行環境が整っており、任意のSD1.5系モデルで画像生成が可能な状態になっている
・拡張機能「sd-webui-controlnet」をインストールしてある
・[Settings→ControlNet]より、[Multi ControlNet: Max models amount]を5以上に設定変更してある
・controlnetの各種モデルを所定のフォルダ(.\models\ControlNet)に配置してある
モードはtxt2img、プロンプトにはキャラクターの特徴をあらわす単語をいくつか入れておきます。上手く決められない場合はTaggerにbeauty画像を入力して候補を作成してもらうと良いでしょう。ネガティブプロンプトはとりあえずよく使われているテンプレを入力しておきます。1フレームのみで何度かテスト生成を行い、プロンプト、Sampling method、CFG Scale、Seedなど各種設定を確定させます。
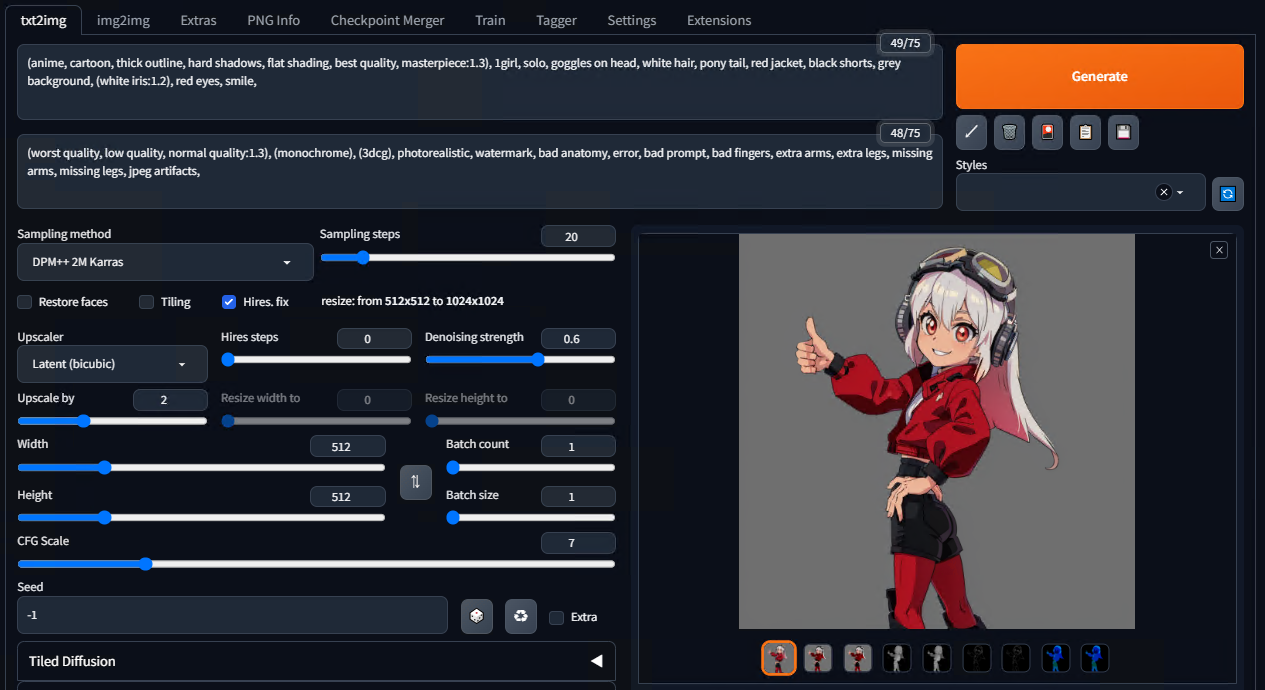
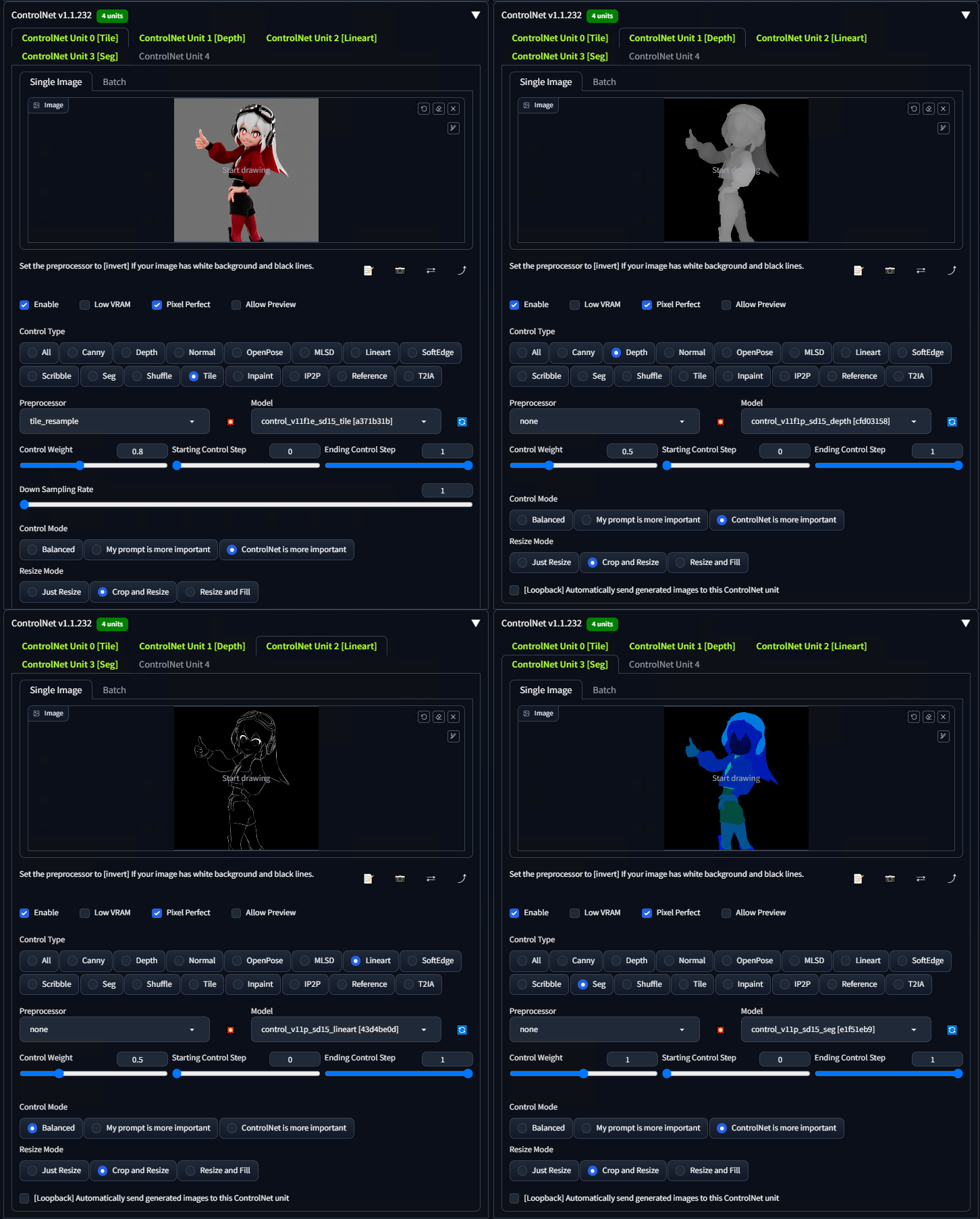
設定が決まったらSeedを固定しBatchモードで出力します。全CNをBatchタブに切り替えPNG連番が置いてあるフォルダを指定し、生成を開始します。以下は、出力された連番画像を全てつなげて動画化したものになります。
4. TemporalNet2でフレーム間の一貫性を向上
前項で出力した動画は、各フレームが独立して出力されておりフレーム間の一貫性はいっさい考慮されていません。複数のCNで強めに制御しているため形状的なブレは比較的抑えられていますが、ディテール、陰影、色味はフレーム間で大きく変化しています。そこで、フレーム間の一貫性を向上させるモデル「TemporalNet2」を追加してみます。
リンク先の紹介文によると、このモデルは前フレームだけでなく現在フレームと前フレーム間のオプティカルフロー(2フレーム間の動きをベクトル表現にて数値化したもの)を合わせた6チャンネルのイメージを入力するよう設計されています。前バージョンであるTemporalNetは前フレームのみを入力とする設計でしたが、v2ではコンセプトが大きく変わっています。
まず初めに追加のAOVを出力します。TemporalNet2ではRAFTモデルで推定したオプティカルフローを使用していますが、3Dデータがあるのであえて2Dから推定する必要はなさそうです。
Arnoldで出力したMotionVectorを使って素材を作成してみます。Available AOVsに「motionvector」というAOVがありますが、こちらは使用せずCustom AOVを作成しaiMotionVectorノードを接続します。[Render Settings → Arnold Renderer → Motion Blur ]でEnable, Instantaneous Shutterにチェックを入れ、Shutter AngleはPosition=Start On Frame、 Length=1.0に設定しておきます。
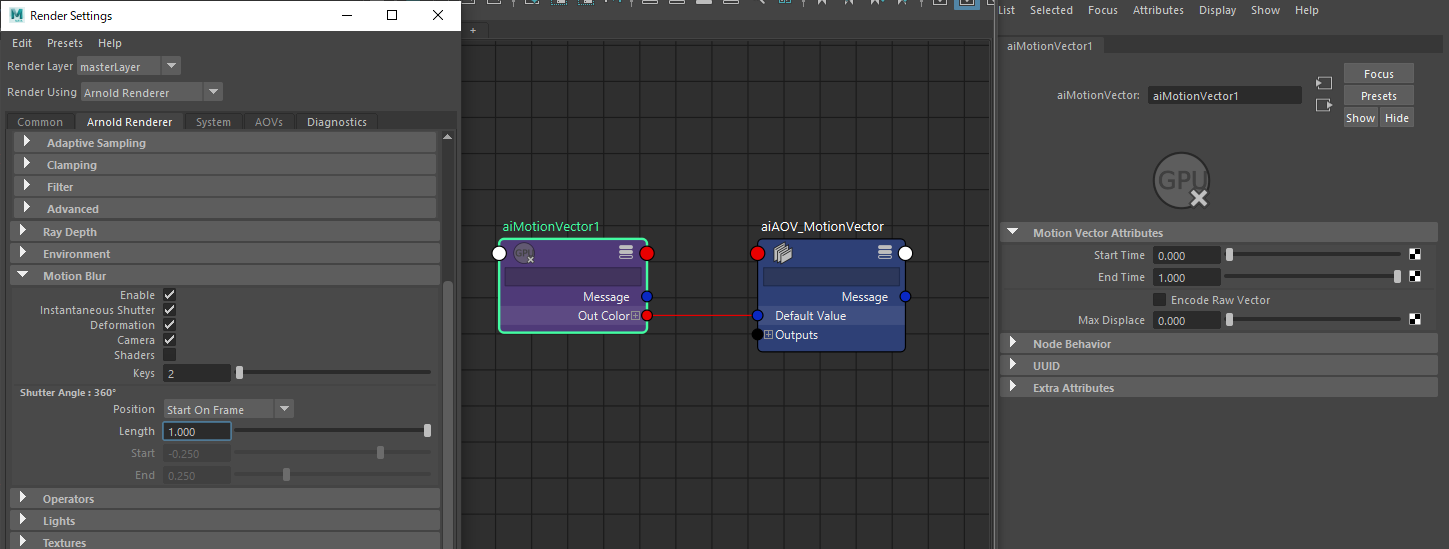
[Render Settings→AOVs]タブは以下のようになっています。
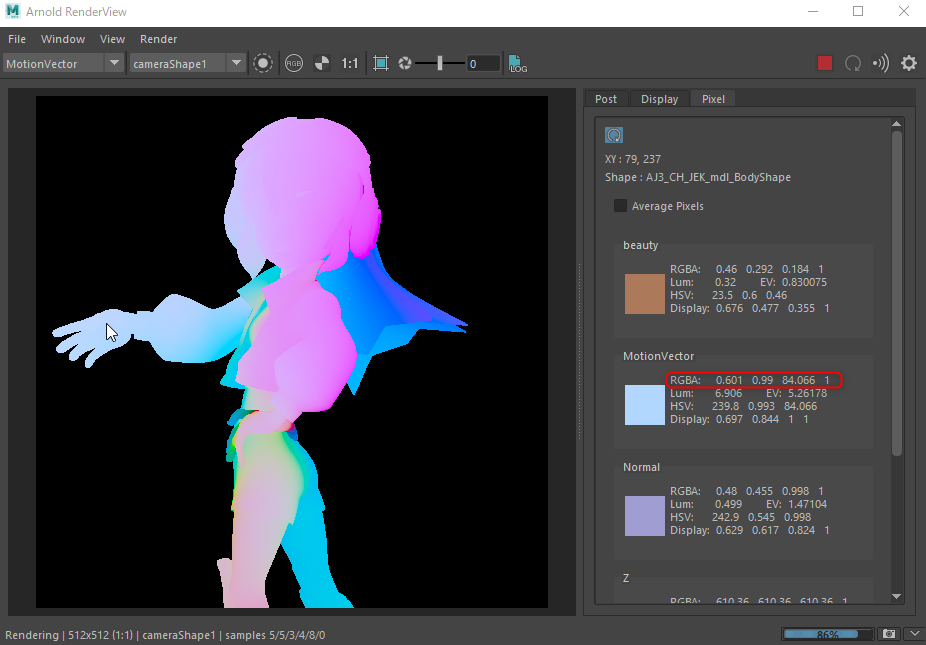
aiMotionVectorノードをデフォルト設定で使用すると、R、Gにベクトルの向き、Bにベクトルの大きさが入ります。これをオプティカルフローと同じ形式にするため、向きを角度に変換してHへ、長さをスケーリングしてSへ、Vは1固定として画像を作成します。
OpenCV、numpy、OpenEXRをインストールし次のスクリプトを実行すると、変換ができます。ディレクトリパスなどは適宜書き換えてください。
<コマンドライン>
pip install opencv-python numpy OpenEXR<Pythonコード>
from pathlib import Path
import cv2
import numpy as np
import OpenEXR
def mv_to_hsv(mv_exr_path:Path, output_png_path:Path):
# OpenEXRファイルを開く
exr_data = OpenEXR.InputFile(str(mv_exr_path))
# ヘッダ情報から画像の幅と高さを取得
header = exr_data.header()
width = header['dataWindow'].max.x + 1
height = header['dataWindow'].max.y + 1
# 各色チャンネルをロード
red_channel = exr_data.channel('R')
green_channel = exr_data.channel('G')
blue_channel = exr_data.channel('B')
red_pixels = np.frombuffer(red_channel, dtype=np.float32).reshape((height, width))
green_pixels = np.frombuffer(green_channel, dtype=np.float32).reshape((height, width))
blue_pixels = np.frombuffer(blue_channel, dtype=np.float32).reshape((height, width))
# 緑のピクセル値を反転
green_pixels = 1 - green_pixels
# 赤と緑のピクセル値をスケーリング
red_pixels = red_pixels * 2.0 - 1.0
green_pixels = green_pixels * 2.0 - 1.0
# 赤と緑のピクセル値から角度(色相)を計算
angle = np.arctan2(green_pixels, red_pixels)
angle = np.where(angle < 0, angle + 2 * np.pi, angle)
normalized_hue = angle / (2.0 * np.pi)
# 青のピクセル値からベクトルの長さ(彩度)を計算
max_length = np.max(np.array(blue_pixels))
if max_length == 0.0:
max_length = 1.0
normalized_saturation = blue_pixels / max_length
# 明度は全ピクセルに対して1を設定
value = np.ones_like(normalized_hue)
# 色相、彩度、明度のデータからHSV画像を作成
hsv_image = cv2.merge([normalized_hue, normalized_saturation, value])
# OpenCVのHSV表現に合わせてスケーリング
hsv_image = np.clip(hsv_image, 0, 1) * [179, 255, 255]
# float型からuint8に変換
hsv_image = hsv_image.astype('uint8')
# BGRに変換して保存
bgr_image = cv2.cvtColor(hsv_image, cv2.COLOR_HSV2BGR)
cv2.imwrite(str(output_png_path), bgr_image)
# MotionVectorのEXR連番があるディレクトリ
MV_PATH = Path(r".\MotionVector")
# 変換後のPNGを出力するディレクトリ
OUTPUT_PATH = Path(r".\flow")
if __name__ == "__main__":
for mv_path in sorted(MV_PATH.glob("*.exr")):
png_path = Path(OUTPUT_PATH, mv_path.stem + '.png')
mv_to_hsv(mv_path, png_path)
print(png_path)
出力されたPNGは以下のようになりました。
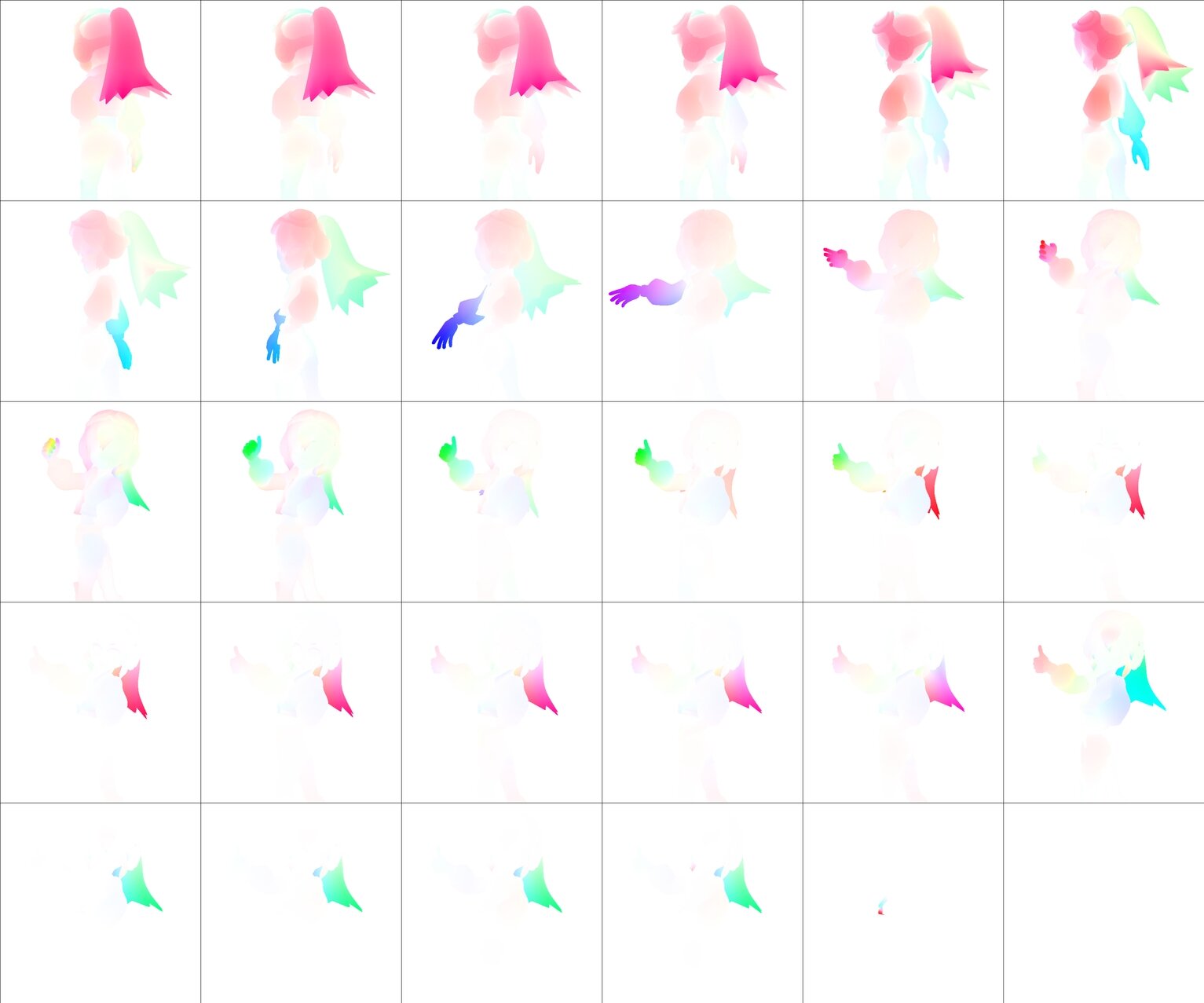
次に、TemporalNet2をwebuiで使用可能にするためリンク先の解説を参考に以下を実施します。
①CNの拡張機能をgithub.com/CiaraStrawberry/sd-webui-controlnet-TemporalNet-APIに置き換えます。
sd-webui-controlnetが入ったままになっていると正常に動作しないため、アンインストールしておきます。無効にするだけではエラーになるのでフォルダごと削除しておきます。
②temporalnetversion2.ckptをダウンロードしモデルフォルダ(.\models\ControlNet)に配置します。
③webuiの起動バッチ(webui-user.bat)に引数「--api」を追加し、再起動します。すでに他の引数が追記してある場合はスペースを空けて追加します。
set COMMANDLINE_ARGS=--xformers --api生成結果を逐次的に次の入力としていくバッチ処理機能は今のところwebuiにはないようですので、サンプルスクリプトに倣いAPIモードで起動したwebuiにリクエストを送信します。
以下がそのスクリプトです。ベースはUIで設定した項目をそのままjson形式で書き換えているだけになりますが、TemporalNet2を追加している点が異なります。こちらもパスや設定値については適宜書き換えてください。
※APIについて詳しくは以下をご参照ください
・github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/API
・github.com/Mikubill/sd-webui-controlnet/wiki/API
from typing import List, Dict
from pathlib import Path
import requests
import base64
import cv2
import numpy as np
import pickle
from io import BytesIO
from PIL import Image, PngImagePlugin
BASE_URL = "http://127.0.0.1:7860"
def load_image(image_path:Path):
"""指定したパスの画像を読み込み、Base64でエンコードした結果を返します。"""
if not image_path.is_file():
return
with open(image_path, "rb") as b:
encoded_image = base64.b64encode(b.read()).decode("utf-8")
return encoded_image
def load_tn2_input(prev_image_path:Path, flow_image_path:Path):
"""指定したパスの2つの画像を読み込み、6チャンネルに接続した結果を返します。"""
if not (prev_image_path.is_file() and flow_image_path.is_file()):
return
prev_image = cv2.imread(str(prev_image_path))
prev_image = cv2.cvtColor(prev_image, cv2.COLOR_BGR2RGB)
prev_image = cv2.resize(prev_image, (512, 512))
flow_image = cv2.imread(str(flow_image_path))
flow_image = cv2.cvtColor(flow_image, cv2.COLOR_BGR2RGB)
flow_image = cv2.resize(flow_image, (512, 512))
# Concatenating the three images to make a 6-channel image
six_channel_image = np.dstack((prev_image, flow_image))
# Serializing the 6-channel image
serialized_image = pickle.dumps(six_channel_image)
# Encoding the serialized image
encoded_image = base64.b64encode(serialized_image).decode('utf-8')
return encoded_image
def send_t2i_request(
data:Dict,
output_path:Path,
) -> None:
# t2i generate
response = requests.post(BASE_URL + "/sdapi/v1/txt2img", json=data)
r = response.json()
result = r['images'][0]
# png info
png_payload = {"image": "data:image/png;base64," + result}
response2 = requests.post(url=BASE_URL+'/sdapi/v1/png-info', json=png_payload)
pnginfo = PngImagePlugin.PngInfo()
pnginfo.add_text("parameters", response2.json().get("info"))
# save
image = Image.open(BytesIO(base64.b64decode(result.split(",",1)[0])))
image.save(output_path, pnginfo=pnginfo)
def request(
output_path:Path,
tile_input=None,
#normal_input=None,
depth_input=None,
line_input=None,
seg_input=None,
tn2_input=None,
) -> Path:
cn_args = [
{
"input_image": tile_input,
"module": "tile_resample",
"model": "control_v11f1e_sd15_tile [a371b31b]",
"weight": 0.8, # 任意の値を入力
"control_mode": 2, # 0:Balanced, 1:My prompt is more important, 2:ControlNet is more important
"pixel_perfect": True,
"threshold_a": 1, # Down Sampling Rate
},
#{
# "input_image": normal_input,
# "module": "none",
# "model": "control_v11p_sd15_normalbae [316696f1]",
# "weight": 1.0,
# "control_mode": 2,
# "pixel_perfect": True,
#},
{
"input_image": depth_input,
"module": "none",
"model": "control_v11f1p_sd15_depth [cfd03158]",
"weight": 0.5,
"control_mode": 2,
"pixel_perfect": True,
},
{
"input_image": line_input,
"module": "none",
"model": "control_v11p_sd15_lineart [43d4be0d]",
"weight": 0.5,
"control_mode": 0,
"pixel_perfect": True,
},
{
"input_image": seg_input,
"module": "none",
"model": "control_v11p_sd15_seg [e1f51eb9]",
"weight": 1.0,
"control_mode": 2,
"pixel_perfect": True,
}
]
if tn2_input:
cn_args.append(
{
"input_image": tn2_input,
"module": "none",
"model": "temporalnetversion2 [b146ac48]",
"weight": 0.4,
"pixel_perfect": False,
}
)
# request data
data = {
"denoising_strength": 0.7, # 任意の値を入力。0.5~0.7くらい。
"prompt": "", # プロンプト
"negative_prompt": "", # ネガティブプロンプト
"seed": 123456789, # Seed値を入力
"sampler_name": "Euler a", # 任意選択
"batch_size": 1,
"n_iter": 1,
"steps": 20, # 任意の値を入力
"cfg_scale": 7, # 任意の値を入力
"width": 512, # 解像度
"height": 512, # 解像度
"restore_faces": False,
"tiling": False,
"enable_hr": True,
"hr_scale": 2.0,
"hr_upscaler": "Latent", # 任意選択
"alwayson_scripts": {
"ControlNet":{
"args": cn_args
}
}
}
for cn in cn_args:
print("{:.02f} {} {}".format(cn["weight"], cn["module"].ljust(15), cn["model"]))
print("Send t2i request... ")
send_t2i_request(
data=data,
output_path=output_path,
)
print(output_path)
print('=='*30)
return output_path
# ControlNetの入力素材が置いてあるディレクトリ
CN_INPUTS_PATH = Path(r".\cn_inputs")
# 生成画像を出力するディレクトリ
OUTPUT_PATH = Path(r".\output")
if __name__ == "__main__":
beauty_paths = sorted(Path(CN_INPUTS_PATH, "beauty").glob("*.png"))
#normal_paths = sorted(Path(CN_INPUTS_PATH, "normal").glob("*.png"))
depth_paths = sorted(Path(CN_INPUTS_PATH, "depth").glob("*.png"))
line_paths = sorted(Path(CN_INPUTS_PATH, "line").glob("*.png"))
id_paths = sorted(Path(CN_INPUTS_PATH, "id").glob("*.png"))
flow_paths = sorted(Path(CN_INPUTS_PATH, "flow").glob("*.png"))
prev_image_path = Path("")
for i in range(len(beauty_paths)):
tile_input = load_image(beauty_paths[i])
#normal_input = load_image(normal_paths[i])
depth_input = load_image(depth_paths[i])
line_input = load_image(line_paths[i])
seg_input = load_image(id_paths[i])
if i > 0:
tn2_input = load_tn2_input(prev_image_path, flow_paths[i-1])
else:
tn2_input = None
prev_image_path = request(
output_path=Path(OUTPUT_PATH, "output_image_{}.png".format(str(i+1).zfill(4))),
tile_input=tile_input,
#normal_input=normal_input,
depth_input=depth_input,
line_input=line_input,
seg_input=seg_input,
tn2_input=tn2_input,
)
スクリプトを実行してしばらく待ち、全フレームが生成されました。2フレーム目以降がTemporalNet2を適用した結果になっています。
以下は、生成された画像を動画化して前項の結果と比較したものです。細部のチラつきが抑えられ、いくらか滑らかに繋がるようになったかと思います。
冒頭の数フレームはキャラクターが後ろ向きであったにも関わらず表情や瞳の色を示すプロンプトを入れていたため、ヘッドフォンなどのおかしな箇所に赤い瞳が現れていました。以下の動画は冒頭のプロンプトのみを変更し、ついでにリミテッド風に一部のフレームを抜いてみたものです。若干ですが違和感が軽減できたかと思います。
5. 最後に
今回の実験では、既存ワークフローのレンダリング〜ポスプロの部分に画像生成AIを導入するイメージで考えてみました。細部にこだわるとまだまだコントロールしきれない箇所が多い印象ですが、3DCGはかなり精度の高い素材を出力できることからControlNetとの相性は非常に良いように感じました。
また、物理ベースレンダラのような光の経路をシミュレーションする手法とは大きく異なり、最終的な見かけを再現しようとする画像生成AIは特にNPR表現と親和性が高いようにも思えます。効率面では特に大きなメリットはないかもしれませんが、選択肢のひとつとなる可能性は十分にありそうです。
現在は、7月末に公開されたStableDiffusionの最新バージョン「SDXL 1.0」への移行が進んでいます。本記事で使用したSD1.x系および2.x系とはまったく別のアーキテクチャになっておりControlNetなどの出力をコントロールする手法については現在対応中のようです。おそらく同等の効果が得られるものと思いますので、これから試してみようという方はSDXL版を待ったほうが良いかと思います。
モデルの学習データ等に関する問題は各方面で活発に議論されており、諸問題がどのように解決していくかも注目のひとつです。私自身は現時点では技術検証にとどめておくのが得策かと思っていますが、3DCGの世界にも少なからず影響が出てくることは予想されます。今後の技術進歩とその可能性について、注意深く観察していきたいと思います。
最後までお読みいただき、ありがとうございます。
今回は3DCGと画像生成AIの組み合わせをテーマにその可能性の一部を紹介させていただきました。次回以降も様々なAI技術と3DCGの応用について探求していきますので、お楽しみに!
TEXT_赤崎弘幸(Jet Studio Inc.) / Hiroyuki Akasaki
EDIT_中川裕介(CGWORLD) / Yusuke Nakagawa













