
こんにちは。この連載では、AI生成技術と進化、3DCG制作現場への活用の可能性を探索していきます。今回取り上げるのは、第1回でも取り上げたChatGPT(GPT-3.5やGPT-4) APIの新たな機能 Function calling、そしてMaya上で動作するAIエージェントです。
AI関連の研究は日々驚くほどのスピードで進化しています。可能な限り正確な情報を提供するよう心掛けていますが、私自身も学習中であるため、記事中に誤りが含まれる可能性があることをご理解いただければ幸いです。

赤崎弘幸
Jet Studio Inc.所属のCGディレクター。
1. エージェントとFunction calling
エージェントとは、一言でいうと「ある環境下で、行動を選択・決定し、その結果によって次の行動を決める」というある程度の意思決定を伴った動作ができるAIです。単体の能力だけでなく、別途与えられた外部の環境や機能から適切な行動を選択することができます。文脈によって多少定義が違う可能性がありますが、ここでは上記のようなものをエージェントと呼ぶこととします。第1回で作成した「エラー解説ダイアログ」や「オペレーションキャプチャツール」は言語モデルの能力の範疇で特定の1タスクに限定していましたので、その点で異なります。
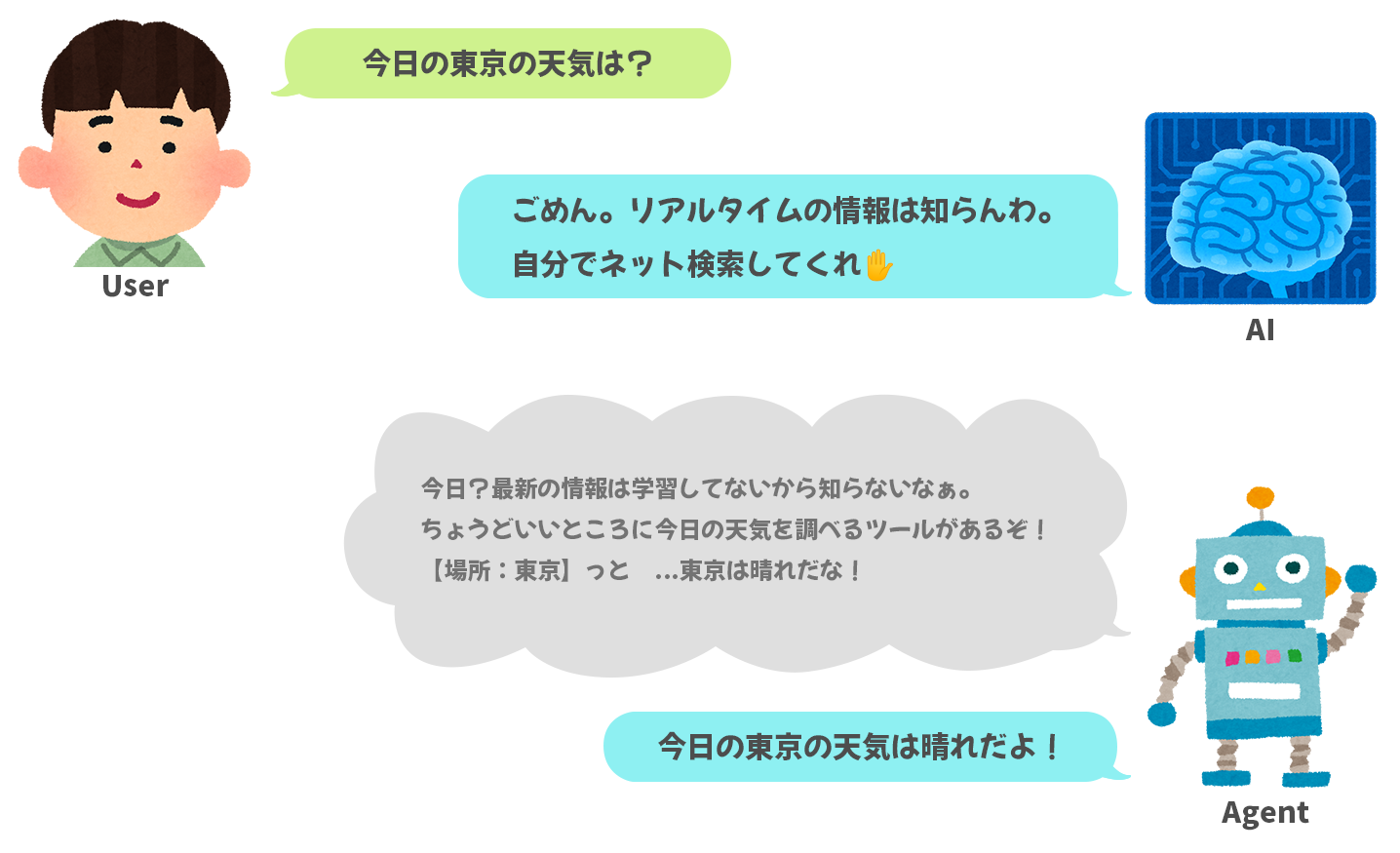
Function callingとは、事前に用意した関数の中からGPTが必要に応じて使用すべき関数を選んでくれる機能です。OpenAI APIに2023年6月半ばに追加されました。ユーザーの問いに対し、関数を使うべきか否か、また使うとしたらどの関数を使うのかをモデル自身が判断し、関数名と引数を返してくれます。関数の実行はこちら側で行う必要がありますが、実行結果を添えてさらに質問を重ねることで言語モデル単体では出来ない「WEB検索」や「コード実行」などの能力を付加することができます。
以下のスクリプトはリアルタイムの天気情報を取得する関数を与えた例です。公式のサンプルを少し改変してあります。
import openai
import json
# 天気を返す関数(仮)。実際はここで外部APIなどに問い合わせする。
def get_current_weather(location):
weather_info = {
"location": location,
"temperature": "24度",
"forecast": "晴れ",
}
return json.dumps(weather_info)
# 関数を動的に取得するための辞書
available_functions = {
"get_current_weather": get_current_weather,
}
def run_conversation(prompt:str):
# Step 1: 会話と利用可能な機能をGPTに送信
messages = [{"role": "user", "content": prompt}]
functions = [
{
"name": "get_current_weather", # 関数名
"description": "指定した場所の現在の天気を取得する", # 関数の説明
"parameters": { # 関数の引数。JSON Schemaで記述。https://json-schema.org/understanding-json-schema/
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "場所。例:東京, 大阪, 福岡, など",
},
},
"required": ["location"],
},
}
]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=messages,
functions=functions,
function_call="auto"
)
response_message = response["choices"][0]["message"]
# Step 2: GPTが関数を呼び出したいかチェックする
if response_message.get("function_call"):
# Step 3: 関数を呼び出す
function_name = response_message["function_call"]["name"]
function_args = json.loads(response_message["function_call"]["arguments"])
function_response = available_functions[function_name](**function_args)
# Step 4: 関数コールと関数のレスポンスをGPTに送信し、再度回答を得る。
messages.append(response_message)
messages.append(
{
"role": "function",
"name": function_name,
"content": function_response,
}
)
second_response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=messages,
)
print(json.dumps(messages, indent=4, ensure_ascii=False))
return second_response["choices"][0]["message"]["content"]
# 実行
print(run_conversation("今日の東京の天気は?"))
# 出力結果
# 今日の東京の天気は晴れで、気温は24度です。
以前からもReActのように機能をすべてプロンプト内に記述する手法により同等のことは出来ていました。言語モデル界隈で有名なライブラリ「LangChain」ではZERO_SHOT_REACT_DESCRIPTIONでこれが実装されています。そのため特にFunction callingで新しいことが出来るようになったわけではないのですが、公式が対応したことでより使いやすくかつ精度高く同等の機能が実現出来るようになりました。(“使いやすく”というのは個人差があるかもしれません。)
Function callingの詳細な使い方は以下をご確認ください。
・GPT/Function calling - OpenAI API
・openai-cookbook/examples/How_to_call_functions_with_chat_models.ipynb
また、以下の記事に本質的なことがまとまっていますので一読しておくと良いかもしれません。
・[OpenAI] Function callingで遊んでみたら本質が見えてきたのでまとめてみた | DevelopersIO
現在はLangChainでもOpenAI Functions Agentが実装されています。
・OpenAI functions | Langchain
・OpenAI Multi Functions Agent | Langchain
前置きが長くなりましたが、今回は簡単にいくつか関数を作成し、Autodesk Maya上で動作する『あるキャラクターリグの操作に詳しいサポートエージェント』を作ってみたいと思います。シンプルに仕組みを理解できるよう、サードパーティ製ライブラリは出来るだけ使わずにやってみます。
<テスト環境>
・Windows 10
・Maya 2024 (Python 3.10.8)
・Python 3.10.9
・openai 0.28.0
事前準備として、以下数点が終わっている前提で進めます。VSCodeとMaya双方でopenaiライブラリが使用できる状態です。
①API keys - OpenAI APIよりAPI Keyを取得し、環境変数OPENAI_API_KEYに設定してある。
②Python仮想環境を作成しopenaiパッケージがインストールしてある。
python -m venv venv
venv\scripts\activate
pip install -U openai[datalib]
③Mayaにopenaiパッケージをインストールしてある。
cd C:\Program Files\Autodesk\Maya2024\bin
mayapy -m pip install -U openai[datalib] -t C:\Users\ユーザー名\Documents\maya\2024\scripts\site-packages
2. エージェントに与える機能を考える
エージェントに機能として追加したい(元の言語モデルに備わっていない)関数を考えていきます。大きく分けて以下の2種が考えられます。
・既存の知識に無い部分を補う
まず「あるキャラクターリグの操作に詳しい」ということはリグの仕様を把握していなければいけません。当然、GPTにはある特定のリグに関する知識はありませんので別途情報を与える必要があります。そこで、事前に用意した仕様書を埋め込みにして外部ファイルに保存し、検索用の関数を用意します。AIが必要だと判断した時に任意の検索ワードで情報を得られるようにしてみます。埋め込みについては次項でもう少し詳しく取り上げます。
・Mayaから情報を得る/操作する
今回のケースではリグに限定しますので、あるコントローラのアトリビュートの状態を取得する関数や、アトリビュートを指定値にセットする関数などをいくつか作成します。これによりMayaシーンから情報を得て判断し次のアクションを行えるようにします。操作するだけなら「スクリプトを書いてください」という指示だけで実現できそうですが、戻り値を受け取ったり、フォーマット通りの動作をさせるためにそれぞれ関数化しておきます。
APIに送る関数の説明リストと関数本体をまとめてFunctionSetというクラスにしてみました。用意した関数は以下の5種です。
・マニュアルを検索する関数
・コントローラを選択する関数
・アトリビュートを指定値に設定する関数
・アトリビュートの現在値を取得する関数
・Pythonコードを実行する関数
関数はクラスにまとめることでPython組み込み関数「getattr」を使用して動的に呼び出せるようになります。
import sys
import traceback
from typing import List
from maya import cmds
class FunctionSet:
def __init__(self):
self.functions = [
{
"name": "search_manual",
"description": "リグの取り扱いマニュアルから関連する情報を検索します。マニュアルにはリグコントローラ名とその機能、その他の補助機能の概要が書いてあります。",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "マニュアルからどのような内容の関連文書を取得したいかの検索語句",
},
},
"required": ["query"],
},
},
{
"name": "select_ctls",
"description": "指定した名前のリグコントローラを選択する。複数可。",
"parameters": {
"type": "object",
"properties": {
"ctl_list": {
"type": "array",
"description": "リグコントローラ名の配列",
"items": {
"type": "string",
},
},
},
"required": ["ctl_list"],
},
},
{
"name": "set_attribute",
"description": "指定した名前のリグコントローラの、指定したアトリビュートを、指定した値に設定する。複数可。コントローラを選択している必要はない。",
"parameters": {
"type": "object",
"properties": {
"attribute_data_list":{
"type": "array",
"items": {
"type": "array",
"items": {
"ctl_name":{
"type": "string",
"description": "リグコントローラ名",
},
"attribute_name":{
"type": "string",
"description": "アトリビュート名",
},
"value":{
"type": "string",
"description": "設定値",
},
},
"minItems": 3,
"maxItems": 3
},
},
},
"required": ["attribute_data_list"],
},
},
{
"name": "get_attribute_value",
"description": "指定した名前のリグコントローラの、指定したアトリビュートの値を取得する。複数可。コントローラを選択している必要はない。",
"parameters": {
"type": "object",
"properties": {
"attribute_data_list":{
"type": "array",
"items": {
"type": "array",
"items": {
"ctl_name":{
"type": "string",
"description": "リグコントローラ名",
},
"attribute_name":{
"type": "string",
"description": "アトリビュート名",
},
},
"minItems": 2,
"maxItems": 2
},
},
},
"required": ["attribute_data_list"],
},
},
{
"name": "exec_code",
"description": "pythonスクリプトを実行します。",
"parameters": {
"type": "object",
"properties": {
"code": {
"type": "string",
"description": "pythonコード",
},
},
"required": ["code"],
},
},
]
# 既存の知識に無い部分を補う
def search_manual(self, query:str):
""" マニュアルから検索語句(query)に該当する箇所を取得する """
# 次項で
pass
# Mayaから情報を得る/操作する
def select_ctls(self, ctl_list:List[str]):
""" 指定したノードを選択する """
msg = []
for ctl in ctl_list:
if not cmds.objExists(ctl):
msg.append("{}というコントローラは無い。".format(ctl))
if msg:
msg.append("マニュアルを確認し正しいコントローラ名を得る必要がある。")
return "\n".join(msg)
cmds.select(ctl_list)
return "{}を選択した。".format(",".join(ctl_list))
def set_attribute(self, attribute_data_list:List[List]):
""" 指定したノードの指定したアトリビュートを指定値にセットする """
msg = []
for ctl, attr, value in attribute_data_list:
full_attr = ctl + "." + attr
if not cmds.objExists(ctl):
msg.append("{}というコントローラは無い。マニュアルを確認し正しいコントローラ名を得る必要がある。".format(ctl))
elif not cmds.objExists(full_attr):
msg.append("{}に{}というアトリビュートはない。マニュアルを確認し正しいアトリビュート名を得る必要がある。".format(ctl, attr))
else:
if type(value) == str:
value = self._convert_str(value)
if type(value) == str:
cmds.setAttr(full_attr, value, type="string")
else:
cmds.setAttr(full_attr, value)
msg.append("{}を{}に設定した。".format(full_attr, value))
return "\n".join(msg)
def get_attribute_value(self, attribute_data_list:List[List]):
""" 指定したノードの指定したアトリビュートの現在値を取得する """
msg = []
for ctl, attr in attribute_data_list:
full_attr = ctl + "." + attr
if not cmds.objExists(ctl):
msg.append("{}というコントローラは無い。マニュアルを確認し正しいコントローラ名を得る必要がある。".format(ctl))
elif not cmds.objExists(full_attr):
msg.append("{}に{}というアトリビュートはない。マニュアルを確認し正しいアトリビュート名を得る必要がある。".format(ctl, attr))
else:
value = cmds.getAttr(full_attr)
msg.append("{}の現在の値は{}。".format(full_attr, value))
return "\n".join(msg)
def exec_code(self, code:str):
""" pythonコードを実行する関数 エラーが発生したらエラー文を返す """
try:
exec(code, {'__name__': '__main__'}, None)
return 'pythonコード実行完了'
except Exception:
exc_type, exc_value, exc_traceback = sys.exc_info()
trace = traceback.format_exception(exc_type, exc_value, exc_traceback)
return "{}: {}: {}".format(exc_type.__name__, trace[-2].strip(), exc_value)
def _convert_str(self, s:str):
""" 文字列の内容に基づいて適切な型(bool, int, float, str)に変換する """
if s.lower() == "true":
return True
elif s.lower() == "false":
return False
try:
return int(s)
except ValueError:
pass
try:
return float(s)
except ValueError:
pass
return s3. 外部の文書を参照する仕組み(RAG)
少し本題から逸れて、検索の仕組みの話になります。リグの各コントローラ、アトリビュートの正式名称や、使い方を参照させるため仕様書を用意しておきます。Function callingの話だけでいいよ!という方は次項 [4. エージェント実装] まで飛ばしてしまって大丈夫です。
ここではRAG (Retrieval-Augmented Generation)というフレームワークで外部の文書を参照させます。文書は細かく区切って事前に埋め込みベクトル(以下embedding)にしておき、推論時に類似度検索を行い関連文書を取得するという構造です。簡単に図式化すると次のようになります。
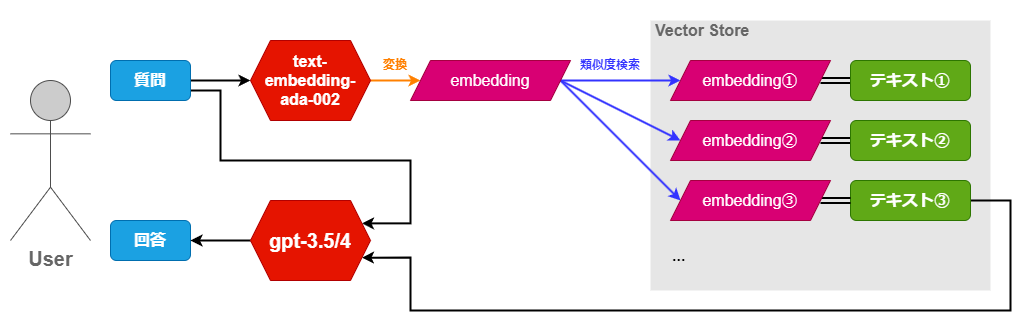
embeddingの取得には同じくOpenAI APIで「text-embedding-ada-002」というモデルを使用します。文字列を渡すとその意味を内包した1536次元のベクトルを返してくれます。お金はかかりますがタダに等しいくらい安いのできっとあまり気にならないと思います。
OpenAI Embeddingについて詳細は以下をご確認ください。
・Embeddings - OpenAI API
・openai-cookbook/examples/Question_answering_using_embeddings.ipynb
以下のサンプルスクリプトは ["動物","植物","乗り物","建物"] と”猫”をそれぞれembeddingにしてコサイン類似度を計算し、スコアが高い順に並べたものです。コサイン類似度というのは要は内積です。完全一致していれば1.0、真逆であれば-1.0になるので、数値が大きい方が類似しているということになります。今回はやりませんがユークリッド距離で比較する場合は小さい方が類似しているということになるのでご注意下さい。
import numpy as np
import openai
def get_embedding(text:str, engine="text-embedding-ada-002", **kwargs):
""" 与えられたテキストの埋め込みベクトルを取得する """
return openai.Embedding.create(input=[text], engine=engine, **kwargs)["data"][0]["embedding"]
def cosine_similarity(a, b):
""" 2つのベクトル間のコサイン類似度を計算する """
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# テキストのリスト
texts = ["動物","植物","乗り物","建物"]
# 各テキストの埋め込みベクトルを取得し、辞書のリストとして保存する
embeddings = [{"text": t, "embedding": get_embedding(t)} for t in texts]
# クエリの埋め込みベクトルを取得する
query_embedding = get_embedding("猫")
# クエリの埋め込みベクトルと各テキストの埋め込みベクトルとのコサイン類似度を計算する
scores = [(data["text"], cosine_similarity(query_embedding, data["embedding"])) for data in embeddings]
# 類似度の高い順にソートする
sorted_scores = sorted(scores, key=lambda x: x[1], reverse=True)
# ソートされた結果を表示する
for s in sorted_scores:
print(s)
# 出力:
# ('動物', 0.8673454180180918)
# ('植物', 0.8389430771237997)
# ('建物', 0.8142869467061629)
# ('乗り物', 0.7896206872541609)「猫」と最も近いのは「動物」という結果が出ました。これを利用して、既存の文書に対し意味的な検索を行います。
仕様書は単純なテキストファイル(.txt)で作成します。今回は既存の文書ではなくembedding前提でこれから作成しますので、文の長さやトピックを意識して区切り方を自分で考えながらテキストを用意します。この点はかなり試行錯誤のしがいがあるのですが、ひとまず意識するところは「固有名詞(ノード名など)には一般的な表現で説明を付け加える」「関係ない話を同じ区切りの中に混ぜない」「長すぎず短すぎず」あたりを意識して用意していきます。
後ほどembeddingにする際に三重改行(\n\n\n)で切り分けようと思いますので、区切り箇所にのみ空の行が2つ挟まるように書いておきます。以下は用意した仕様書の一部になります。

次のスクリプトでテキストファイルを読み込み、"\n\n\n"でsplitしてそれぞれembeddingにします。取得したembeddingと元のテキストのペアをベクトルストアとしてjsonファイルで保存します。ここで作成するベクトルストアは { "content": “元のテキスト”, "embedding": [1536次元のベクトル] } を複数連ねた配列で、非常にシンプルな構造です。本格的な実装をするならFAISSなどのベクトル検索ライブラリを使用すべきところかと思いますが、今回のような単純なテストではこちらで十分かと思います。
from pathlib import Path
from typing import List, Dict
import json
import openai
def get_embeddings(
list_of_text: List[str], engine="text-embedding-ada-002", **kwargs
) -> List[List[float]]:
assert len(list_of_text) <= 2048, "The batch size should not be larger than 2048."
# replace newlines, which can negatively affect performance.
list_of_text = [text.replace("\n", " ") for text in list_of_text]
data = openai.Embedding.create(input=list_of_text, engine=engine, **kwargs).data
return [d["embedding"] for d in data]
def texts_to_vectorstore(text_path: Path):
""" 指定されたテキストファイルをベクトルストアに変換 """
# テキストファイルを読み取る。
with open(text_path, 'r', encoding="utf-8") as f:
text = f.read()
# テキストを個々のテキストに分割。
texts = [t.strip() for t in text.split("\n\n\n") if t.strip()]
# 各テキストの埋め込みを取得。
embeddings = get_embeddings(texts)
# ベクトルストアデータを準備。
vector_store = []
for i, t in enumerate(texts):
vector_store.append(
{
"content": t,
"embedding": embeddings[i],
}
)
# ベクトルストアをJSONファイルとして保存。
with open(text_path.with_suffix('.json'), mode="w", encoding="utf-8") as f:
json.dump(vector_store, f, ensure_ascii=False)
texts_to_vectorstore(Path("./rig_manual.txt"))上記スクリプトはベクトルストア作成時に一度だけ使うスクリプトです。MayaではなくPythonのvenvで事前に実施しておきます。エージェントの推論時には次のようなベクトルストアの読み込みや検索を行うクラスを別途用意します。
from pathlib import Path
from typing import List, Tuple
import json
import numpy as np
import openai
class VectorStore:
"""
ベクトルストアを管理するクラス。テキストの埋め込みを取得し、類似度検索を行う機能を提供。
"""
def __init__(self, path: Path) -> None:
with open(path, mode="r", encoding="utf-8") as f:
self.vector_store = json.load(f)
def _get_embedding(self, text: str, engine="text-embedding-ada-002", **kwargs) -> List[float]:
""" 指定されたテキストの埋め込みを取得 """
text = text.replace("\n", " ")
return openai.Embedding.create(input=[text], engine=engine, **kwargs)["data"][0]["embedding"]
def _cosine_similarity(self, a, b):
""" 2つのベクトル間のコサイン類似度を計算 """
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
def similarity_search(self, query: str, k: int = 4) -> List[Tuple]:
""" 与えられたクエリに基づいて、ベクトルストア内のテキストとの類似度を計算し、上位k件の最も類似度が高いテキストとそのスコアを返す。 """
query_embedding = self._get_embedding(query)
scores = [(data, self._cosine_similarity(query_embedding, data["embedding"])) for data in self.vector_store]
sorted_scores = sorted(scores, key=lambda x: x[1], reverse=True)
return sorted_scores[:k]また、前項で作成した関数セットにこちらのベクトルストアを内包し、検索関数を以下のように更新しておきます。
class FunctionSet:
def __init__(self, manual_vs:VectorStore):
self.manual_vs = manual_vs
self.functions = [
## 中略 ##
]
# 既存の知識に無い部分を補う
def search_manual(self, query:str):
""" マニュアルから検索語句(query)に該当する箇所を取得する """
search_result = self.manual_vs.similarity_search(query)
return "\n".join([sr[0]["content"] for sr in search_result])
## 以下略 ##4. エージェント実装
本題に戻ります。前項で用意したベクトルストア付き関数セットを与えてエージェントクラスを作り、Maya上で動作させてみます。ここまで来ればすでにコア要素は出来ている状態ですのであとは問い合わせに対して最終的な答えが出るまで繰り返しAPIコールを回させるだけです。
from typing import List
import json
import openai
class Agent:
def __init__(self, function_set:FunctionSet):
self.func_set = function_set
self.system_prompt = """あなたはある特定のキャラクターリグの取り扱いをサポートする優秀なAIです。
質問に対し、必ずマニュアル内を検索し該当する記述があるかを確認してから返答してください。
一般的な既存の知識だけで返答することがないよう徹底してください。
不足している情報があれば無理に回答せず、ユーザーへ質問を返してください。"""
def __call__(self, query:str, messages:List=[], model:str="gpt-3.5-turbo-0613", max_call:int=10, **kwargs):
print("-------------")
print("user: ", query)
if len(messages) == 0:
# メッセージが空だった場合(会話の最初だった場合)はmessagesにシステムプロンプト追加
messages.append({"role": "system", "content": self.system_prompt})
# ユーザーの問い合わせをmessagesに追加
messages.append({"role": "user", "content": query})
for i in range(max_call):
# ターン数表示
print("---- [{}] ----".format(i))
# APIリクエスト
finish_reason, message = self.chat_completion_with_functions(messages, model, **kwargs)
if finish_reason == "function_call":
### function 使う場合 ###
# 関数名と引数取得
func_name = message["function_call"]["name"]
arguments = json.loads(message["function_call"]["arguments"])
print("call <{}> args={}".format(func_name, arguments))
# 関数セットから関数を取得し、引数を渡して実行
func_returns = getattr(self.func_set, func_name)(**arguments)
print(func_returns)
# messagesに返答と関数の実行結果を追加
messages.append(message)
messages.append({"role": "function", "name": func_name, "content": func_returns})
else:
### function 使わない場合 ###
# messagesに返答を追加して終了
messages.append(message)
print("agent: ", message["content"].strip())
break
return messages
def chat_completion_with_functions(self, messages:List, model:str, **kwargs):
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0,
top_p=1,
functions=self.func_set.functions,
function_call="auto",
**kwargs
)
finish_reason = response.choices[0]["finish_reason"]
message = response.choices[0]["message"]
return finish_reason, messageここまでで作成したVectorStore、FunctionSet、Agentクラス、そして以下のスクリプトを全てひとつにまとめてMaya上で実行します。ベクトルストアのファイルパスは適宜変更してください。
from pathlib import Path
from maya import cmds, OpenMayaUI
from PySide2 import QtWidgets
from shiboken2 import wrapInstance
class InputDialog(QtWidgets.QDialog):
def __init__(self, parent=None):
super(InputDialog, self).__init__(parent)
self.line_edit = QtWidgets.QLineEdit(self)
self.line_edit.setStyleSheet("QLineEdit {font-size: 15px;}")
self.ok_button = QtWidgets.QPushButton('Send', self)
self.ok_button.clicked.connect(self.accept)
self.layout = QtWidgets.QVBoxLayout(self)
self.layout.addWidget(self.line_edit)
self.layout.addWidget(self.ok_button)
def show(self):
super(InputDialog, self).show()
if self.exec_():
return self.line_edit.text()
if __name__ == "__main__":
# VectorStore読み込み
manual_vs = VectorStore(Path("./rig_manual.json"))
# 関数セットのインスタンスを作成
function_set = FunctionSet(manual_vs=manual_vs)
# エージェントのインスタンスを作成
agent = Agent(function_set=function_set)
# 初期の空メッセージリスト
messages = []
input_dialog = InputDialog(wrapInstance(int(OpenMayaUI.MQtUtil.mainWindow()), QtWidgets.QWidget))
while True:
user_input = input_dialog.show()
if user_input is None:
break
if not user_input:
continue
# エージェントへ問い合わせて更新されたメッセージを受け取る
messages = agent(query=user_input, messages=messages, model="gpt-4-0613", max_call=20)
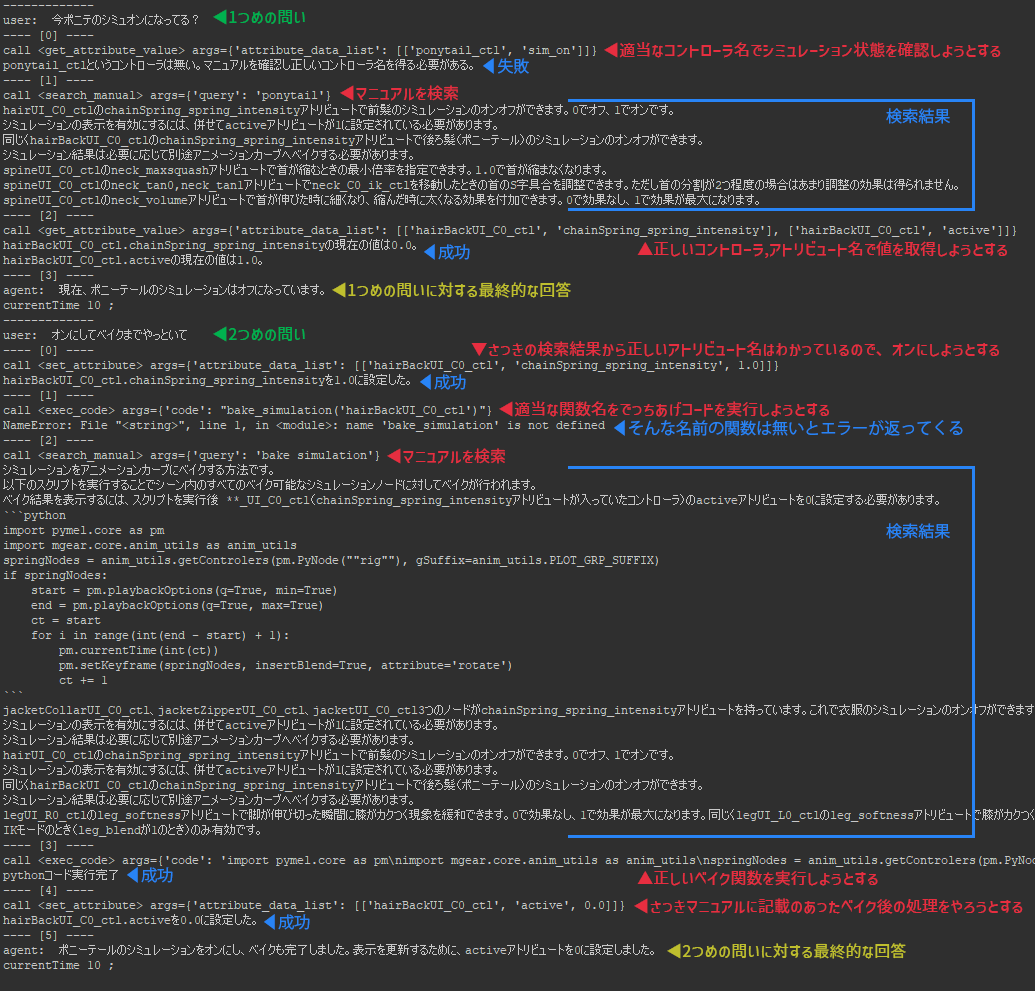
cmds.refresh()ScriptEditorを見ていると、ひとつの問いに対し関数の実行を複数行った後、最終的な回答へ至っていることが分かります。1つ目の「ポニテのシミュオンになっている?」という問いに対しては、一度は適当なノード名とアトリビュート名で関数を実行した結果エラーとなったため、マニュアル内を検索し正しいノード名とアトリビュート名を取得しています。2つ目の「オンにしてベイクまで」という指示に対しては直前の文脈から正しいアトリビュートでオンにすることに成功していますが、その後に存在しないベイク関数を実施しようとして失敗し、再度マニュアルを確認しにいっています。下の画像の赤字が言語モデルの“判断”の部分、青字が関数の結果の部分です。
マニュアル検索の精度にだいぶ左右されそうですが、ユーザーの大雑把な指示だけでここまで到達できる点は大きな進歩のように思います。
ここまでの実装を整理したものを以下のリポジトリに置いておきます。サンプルとして、mGear 4.1.0の「Biped Template, Y-up」用に作成したマニュアルテキストもリポジトリに含んでいます。ベクトルストアの作成~エージェント起動がすぐに試せる状態になっていますので、ご興味があればご確認いただけますと幸いです。
GitHub - akasaki1211/maya_agent at aicg04
5. 最後に
第1回に引き続きGPTを取り上げましたが、質問に対する返答やスクリプト生成だけではなく、脳内の思考をシミュレートするような意思決定の道具としても使えることがわかりました。また、RAGという知識を補足するフレームワークにより、固有の目的に対して特化した能力を付加することもできそうでした。
とはいえかなり丁寧に調整をしないと思い通りに動いてくれないことも多々あります。今回のテストでは外部の情報が少量でしたが、情報量が増えると検索の精度も落ち始めます。曖昧かつ複雑な指示ではGPT-4レベルでようやくまともに対応できるかどうかという状態ですし、API料金(与えられた関数はモデルが学習時に使用した構文でシステムメッセージに挿入されるため関数を増やすほど消費トークンが増大します)や生成速度も相まって、現状ではまだまだ実用的ではないかもしれません。ただしこれらはおそらく時間の問題で、もっと精度の高い言語モデルがローカルでサクサク動くようなことになれば、それこそ会話でアプリケーションを操作する日も遠くないかと思います。
最後までお読みいただき、ありがとうございます。今回はMaya上で半自律型のサポートエージェントを動かしてみました。次回以降もさまざまなAI技術と3DCGの応用について探求していきますので、お楽しみに!













