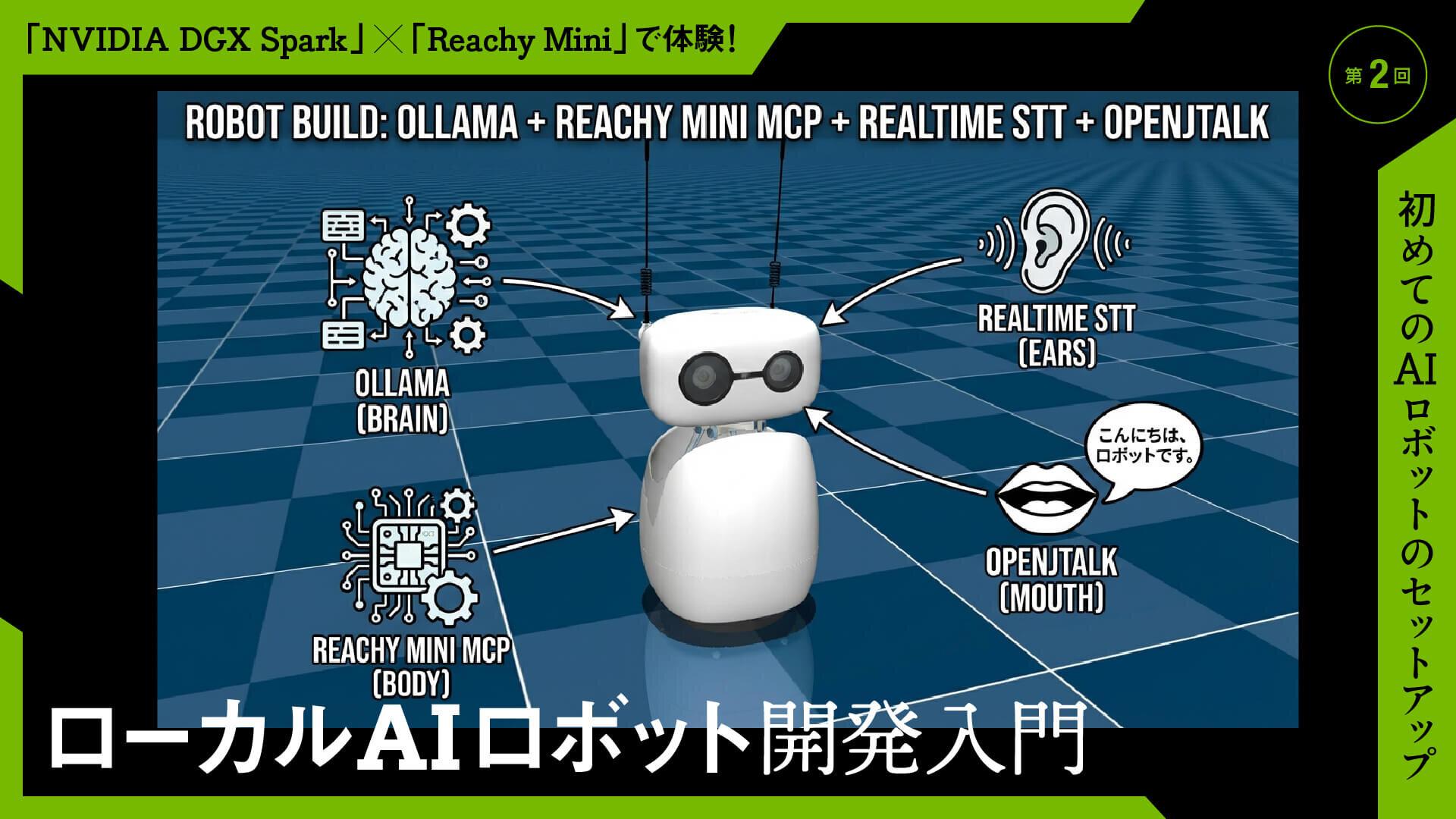
第1回では「未来の音声AIロボットを『自分の手で創る』時代へ」をタイトルに、「NVIDIA DGX Spark」(以下、DGX Spark)と「Reachy Mini」によるローカルAIロボットの全体構成を紹介した。今回は実践編として、DGX Sparkの環境をセットアップし、次の4つの要素を接続して、実際にローカルAIロボットを動かすところまで進めていこう。
今回つなぐ4つの要素は、次のとおりだ。
・脳:Ollama-LLM(大規模言語モデル)による思考、対話
・体:Reachy Mini MCP-ロボットの動作制御
・耳:RealtimeSTT-音声認識(Speech To Text)
・口:OpenJTalk-音声合成(Text To Speech)
クラウドAPIは使わず、すべてローカルで実行するため手元のDGX Sparkだけで動作が可能だ。DGX SparkはARMアーキテクチャ版のUbuntuで動作するため、使用するツールやライブラリ、実行ファイルはARM(aarch64)対応のものを選ぶ必要がある点は注意してほしい。
Codex CLIの準備
「Codex CLI」は、ChatGPTの開発元であるOpenAIが提供する、コマンドラインで使えるAIコーディングアシスタントだ。自然文で指示するだけで、環境構築、コード作成、修正、デバッグ支援まで行える。自分でコードを実装することも可能だが、Codexを使うと開発スピードを大きく上げることができる。本記事で掲載しているサンプルコードもCodexを利用して作成したものだ。
Codexでの生成結果が一度で期待どおりにならないこともあるが、誤りや修正したい点を具体的に伝えて、対話しながら調整していくのがCodexを使いこなすコツとなる。この記事のURLや仕様メモなどを参考資料としていっしょに渡すことで、より精度の高いコードが生成されやすくなることも覚えておこう。
・Codex CLIのGithub
github.com/openai/codex
Codex CLIの準備手順は、次の手順で進める。
①Node.jsのインストール
「Node.js」は、JavaScriptをブラウザの外(ターミナルやサーバ上)で実行できるようにする実行環境だ。ターミナルやコマンドプロンプト、Powershellなどを起動して、Codex CLIの実行に必要なNode.jsのインストールを行う。
----
sudo apt update
sudo apt install -y nodejs npm
----
②Codex CLIのインストール
npm(Node.js用のパッケージ管理ツール)を使ってインストールを行う。
----
sudo npm i -g @openai/codex
----
③Codexの起動
初回起動時はブラウザが開くので、ChatGPTで利用しているOpenAIアカウントでログインする。
----
codex
----
④動作の確認
起動後、プロンプト(>)が表示されたら、そのまま自然文で指示できる。入力してPythonプログラムが作成されていることを確認してほしい。
----
> "Hello Wrold!"と表示するPythonプログラム作って
----
Codex CLIは、実行したフォルダ(カレントディレクトリ)配下のファイルを対象として作成や編集が行われるため、プロジェクトごとにフォルダを分け、そのルートディレクトリで起動するのがおすすめとなる。
Ollama(脳)の準備
「Ollama」は、PC上で大規模言語モデル(LLM)を簡単にダウンロード・実行・管理できるローカルAI実行ツールとなる。クラウドを使わず、手元のDGX SparkだけでAIモデルを動かせるため、ここではローカルAIロボットの「脳」として利用する。
・Ollama
ollama.com
Ollamaの準備手順は、次の手順で進める。
①Ollamaのインストール
ターミナルなどを起動し、以下のコマンドでインストールを行う。
----
curl -fsSL https://ollama.com/install.sh | sh
----
②Ollamaサーバを起動
バックグラウンドでOllamaサーバを起動させるため、以下のコマンドを入力する。
----
ollama serve &
----
③モデルを取得
「脳」にあたるLLMとして、今回はAlibaba Cloudによって開発された「qwen3:8b」を使用する。ダウンロードには時間がかかるので、完了までしばらく待とう。
----
ollama pull qwen3:8b
----
④tools対応モデルかを確認
ロボット制御などの外部機能と連携するため、tools対応かどうかを以下のコマンドで確認する。出力の「Capabilities」に、次の結果が含まれていれば問題ない。「tools」があるモデルは、関数呼び出しや外部ツール連携に対応しているモデルとなる。
----
ollama show qwen3:8b
----
----
︙
Capabilities
completion
tools
thinking
︙
----
⑤動作確認
以下のコマンドで、実際にモデルを起動して対話できるかを確認する。プロンプトが表示され、会話できればインストールが成功している。
----
ollama run qwen3:8b
----
Reachy Mini MCP(体)の準備
「Reachy Mini MCP」は、Reachy MiniをLLMから操作するための「MCP」(Model Context Protocol)サーバ実装だ。MCPは、LLMが外部ツールやロボットを安全・標準的に制御するためのプロトコルとなる。
・Reachy Mini MCPのGithub
github.com/OriNachum/reachy-mini-mcp
構成イメージは「LLM→MCP→ロボット」という流れで制御が行われる。この接続により、自然文の指示からロボット操作をMCPを介して実行できるようになる。たとえば「ダンスして」という指示を行うと、Reachy Miniが「頭部やアンテナを動かして踊る」といったことを行なってくれる。
Reachy Mini MCPでは、次のような操作が可能となっている。こちらは、次の第3回の記事で詳しく紹介している。
・頭部やアンテナの動作制御
・カメラ操作
・ジェスチャーや感情表現
・状態取得や電源制御などの基本操作
・複数コマンドの連続実行
Reachy Mini Daemonのインストール
まず、ロボット本体(またはシミュレータ)を制御する「Daemon」の準備を行う。Daemonは、バックグラウンドで常時動作し続けるサービス用プログラムだ。
①Python仮想環境の準備
Python仮想環境は、プロジェクト専用の実行環境で、ライブラリの競合を防ぐため本記事では使用を推奨する。以下のコマンドで、Python仮想環境は作成できる。
----
python -m venv env
source env/bin/activate
----
②Reachy Miniパッケージのインストール
ロボットの実機だけでなく、DGX Sparkでシミュレータとしても動かせるようにするため、[mujoco]オプション付きでインストールを行う。
----
pip install 'reachy-mini[mujoco]'
----
③Reachy Mini Daemonの実行
実機ではなくシミュレータで起動する場合は、「--sim」を指定する必要がある。
---
reachy-mini-daemon --sim
----

Reachy Mini MCPサーバのインストール
次に、LLMとReachy MiniをつなぐMCPサーバを準備を行う。
①リポジトリの取得
以下のコマンドで、Reachy Mini MCPサーバを取得する。
----
git clone https://github.com/OriNachum/reachy-mini-mcp
cd reachy-mini-mcp
----
②Python仮想環境の準備
先の「Reachy Mini Daemon」と別のPython仮想環境を作成する。
----
python -m venv env
source env/bin/activate
----
③Pythonの依存関係のインストール
以下のコマンドで、必要なライブラリをインストールする。
----
pip install -r requirements.txt
----
④MCPサーバーの動作確認
以下のコマンドで、起動できることを確認する(確認後は「Ctrl」+「C」で停止)。
----
python server.py
----
OllamaとReachy Mini MCPの連携
ここまでインストールしたOllama(LLM)とReachy Mini Daemonは、あらかじめ起動しておく必要がある。
①Codexに、OllamaでReachy Mini MCPを使うコードの作成を指示
パス設定は自分の環境に合わせて調整してほしい。
----
OllamaでReachy Mini MCPを使うCLIアプリをpythonで作成して。
Python仮想環境はenvを作成して。
Reachy Mini MCPのコンフィグは、次のとおりです。
{
"mcpServers": {
"reachy-mini": {
"command": "/Users/npaka/reachy-mini/reachy-mini-mcp/env/bin/python",
"args": [
"/Users/npaka/reachy-mini/reachy-mini-mcp/server.py"
]
}
}
}
----
②Python仮想環境を有効化して、依存関係のインストール
仮想関係の有効化と、必要なライブラリをインストールする。
----
source env/bin/activate
pip install -r requirements.txt
----
③コードの実行
作成されたコードを実行する。ターミナルなどから自然文で指示(「ダンスして」)を出すと、LLM経由でReachy Miniが動作するのがわかる。次の動画は、シミュレータでの実行結果だ。
----
python reachy_ollama_cli.py
----
OpenJTalk(口)の準備
OpenJTalkは、日本語テキストを音声に変換するためのオープンソースの音声合成(TTS)エンジン。ローカル環境で動作し、日本語の読み上げに強いのが特徴で、ここではロボットの「口」として利用する。
・OpenJTalk
https://open-jtalk.sp.nitech.ac.jp/
OpenJTalkの準備手順は、次の手順で進める。
①OpenJTalkのインストール
以下のコマンドで、インストールを行う。
----
sudo apt update
sudo apt install -y open-jtalk open-jtalk-mecab-naist-jdic hts-voice-nitech-jp-atr503-m001
----
②Python仮想環境の準備
仮想環境を準備して、有効化する。
----
python -m venv env
source env/bin/activate
----
③コードの作成
OpenJTalkをコマンドライン経由で呼び出し、生成した音声を再生するためのコードを作成する。
・hello_openjtalk.py
----
import subprocess
def tts_and_play(text, output="out.wav"):
# 音声生成
cmd = [
"open_jtalk",
"-x", "/var/lib/mecab/dic/open-jtalk/naist-jdic",
"-m", "/usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice",
"-g", "10.0",
"-ow", output
]
process = subprocess.Popen(cmd, stdin=subprocess.PIPE)
process.communicate(text.encode("utf-8"))
# 再生
subprocess.run(["aplay", output])
if __name__ == "__main__":
tts_and_play("こんにちは。今日も良い天気ですね")
----
④コードの実行
作成したコードを実行する。Reachy MiniをUSBでDGX Sparkに接続しておくと、Reachy Miniをマイクおよびスピーカーとして利用できる。
OpenJTalkで生成した音声がReachy Mini側から再生されれば、設定は正しく完了している。
Realtime STT(耳)の準備
RealtimeSTTは、マイクから入力された音声をリアルタイムで文字に変換するためのライブラリだ。発話が終わるまで待って一括変換するのではなく、話している途中から順次テキスト化を行ってくれる。さらにVAD(音声区間検出)により、発話と無音を自動判定してくれる。
RealtimeSTTは、ボタン操作なしで自然な音声入力を扱えるため、ローカルAIアシスタント、ロボット対話システム、音声UIの実装に適している。
RealtimeSTTの準備手順は、次の手順で進める。
①Python仮想環境の準備
これまでと同様に、仮想環境の作成と有効化を行う。
----
python -m venv env
source env/bin/activate
----
②RealtimeSTTのインストール
以下のコマンドで、インストールを行う。
----
pip install RealtimeSTT
----
③依存関係のインストール
音声入力に必要なライブラリをインストールする。
----
sudo apt-get update
sudo apt-get install python3-dev
sudo apt-get install portaudio19-dev
pip install requests
----
④pvporcupineの対応
Linux環境では「pvporcupine」(ウェイクワードを検出するための音声認識エンジン)が正常に読み込めない場合がある。その場合は、次のようにスクリプトのインポート部分を例外処理付きに変更を行う必要がある。
・env/lib/site-packages/RealtimeSTT/audio_recorder.py
【変更前】
----
import pvporcupine
----
【変更後】
----
try:
import pvporcupine
except Exception:
pvporcupine = None
----
⑤コードの作成
音声をリアルタイムに認識して、そのまま表示する簡単なコード例は以下のとおり。
・hello_realtimestt.py
----
from RealtimeSTT import AudioToTextRecorder
def process_text(text):
print(text)
if __name__ == '__main__':
print("Wait until it says 'speak now'")
recorder = AudioToTextRecorder(language="ja")
while True:
recorder.text(process_text)
----
⑥コードの実行
作成したコードを実行する。Reachy MiniをUSBでDGX Sparkに接続しておくと、Reachy Miniをマイクおよびスピーカーとして利用できる。
マイクに向かって話しかけ、テキストが順次表示されれば成功だ。
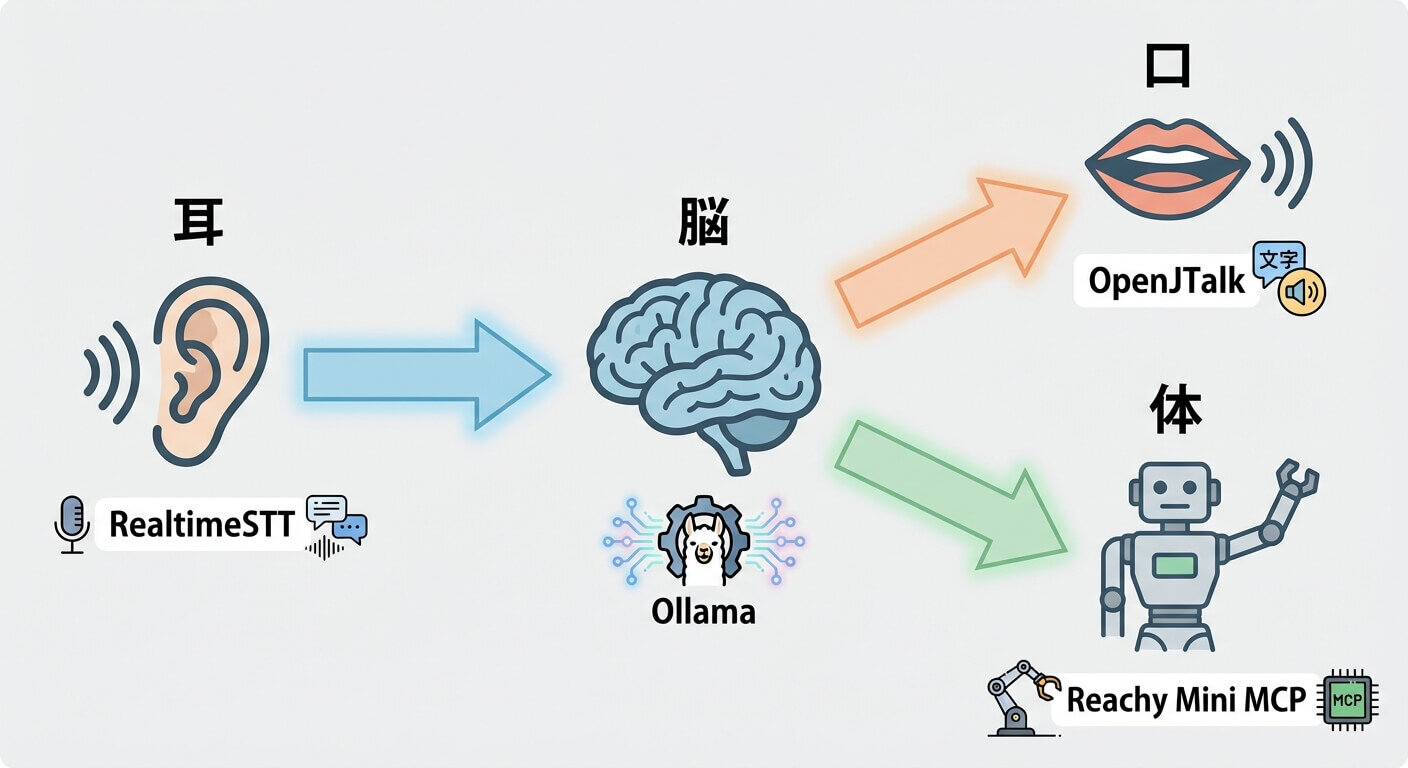
準備したコンポーネントの連携
ここまで準備した「脳」「体」「口」「耳」の各コンポーネントを連携させ、音声で話しかけると、LLMが考え、ロボットが動き、音声で返答する構成に仕上げていこう。実装は記事の最初に紹介したCodexを使って段階的に調整していくことで効率よく作成できる
①回答を「OpenJTalk」の音声出力に変更
Codexに次のように指示する。生成コードが期待どおりでない場合は、エラー内容や修正点を具体的に伝えて再調整を行う必要がある。
----
LLMからの回答をOpenJTalkの音声出力に変更して。
----
②文字入力をRealtimeSTTの音声入力に変更
次に、キーボード入力をやめて、マイクからのリアルタイム音声入力に切り替える。合わせて、音声再生中に誤認識しないような制御も追加する。
----
文字入力をRealtimeSTTによる音声入力に変更して。
音声出力している間は、音声入力しないで。
----
③Python仮想環境を有効化して依存関係をインストール
これまで同様、以下のコマンドを実行する。
----
source env/bin/activate
pip install -r requirements.txt
----
④コードの実行
コードを実行して、以下が確認できれば、各コンポーネントの連携は成功となる。
・音声で話しかける
・LLMが応答を生成
・Reachy Miniが動作
・OpenJTalkが音声で返答
----
python reachy_ollama_cli.py
----
シミュレータと実機での動作の様子を動画で用意したので、こちらも確認してほしい。
Codexが作成したコード
第2回目の本記事では、DGX SparkとReachy Miniを接続して、以下の4つの要素をすべてローカルで連携させて、「聞く→考える→動く→しゃべる」ローカルAIロボットの基本形を完成させた。
・脳:Ollama(LLM)
・体:Reachy Mini MCP
・耳:RealtimeSTT
・口:OpenJTalk
ここでのポイントは、いきなり全部を同時に動かそうとせず、次のように段階的に確認すること。これにより、どこで詰まっても原因を切り分けやすく、安定した構成に仕上げることができる。
①LLM単体→②MCPで動作→③口(TTS)→④耳(STT)→⑤統合
また、統合部分は調整が多くなりがちなので、Codex CLIを使って「こう動いてほしい」「このバグを直してほしい」などを具体的に伝えながら反復すると、完成までのスピードが一気に上がることになるだろう。
最後に、Codexが作成したコードをまとめて示しておく。
CLIでReachy Miniと会話するコード
・requirements.txt
----
mcp
httpx
----
・reachy_ollama_cli.py
----
import argparse
import asyncio
import json
import httpx
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
DEFAULT_MCP_PYTHON = "/Users/npaka/reachy-mini-mcp/env/bin/python"
DEFAULT_MCP_SERVER = "/Users/npaka/reachy-mini-mcp/server.py"
DEFAULT_OLLAMA_HOST = "http://localhost:11434"
DEFAULT_MODEL = "qwen3:8b"
DEFAULT_SYSTEM_PROMPT = "あなたはReachy Miniを操作するロボットアシスタントです。積極的にツールを使ってください。回答は日本語を1セリフで返して。"
def parse_args():
p = argparse.ArgumentParser(description="Ollama + Reachy Mini MCP CLI")
p.add_argument("--model", default=DEFAULT_MODEL)
p.add_argument("--ollama-host", default=DEFAULT_OLLAMA_HOST)
p.add_argument("--mcp-python", default=DEFAULT_MCP_PYTHON)
p.add_argument("--mcp-server", default=DEFAULT_MCP_SERVER)
p.add_argument("--system-prompt", default=DEFAULT_SYSTEM_PROMPT)
p.add_argument("--debug", action="store_true")
return p.parse_args()
async def ollama_chat(client, model, messages, tools):
r = await client.post(
"/api/chat",
json={"model": model, "messages": messages, "tools": tools, "stream": False},
)
r.raise_for_status()
return r.json()
def message_text(message, payload):
c = message.get("content")
if isinstance(c, str):
return c
if isinstance(c, list):
parts = [str(x.get("text", "")) for x in c if isinstance(x, dict) and x.get("type") == "text"]
if parts:
return "\n".join(parts)
return payload.get("response") or payload.get("output_text") or ""
def tool_args(raw):
if isinstance(raw, dict):
return raw
if not isinstance(raw, str) or not raw.strip():
return {}
try:
parsed = json.loads(raw)
except json.JSONDecodeError:
return {}
return parsed if isinstance(parsed, dict) else {}
def tool_output(result):
content = getattr(result, "content", None)
if content:
parts = []
for x in content:
t = getattr(x, "text", None)
if t:
parts.append(t)
elif isinstance(x, dict) and x.get("type") == "text":
parts.append(str(x.get("text", "")))
if parts:
return "\n".join(parts)
structured = getattr(result, "structuredContent", None)
return json.dumps(structured, ensure_ascii=False) if structured is not None else "(no tool output)"
async def run(args):
server = StdioServerParameters(command=args.mcp_python, args=[args.mcp_server])
async with stdio_client(server) as (r, w):
async with ClientSession(r, w) as mcp:
await mcp.initialize()
listed = await mcp.list_tools()
tools = [
{
"type": "function",
"function": {
"name": t.name,
"description": t.description or "",
"parameters": getattr(t, "inputSchema", None) or {"type": "object", "properties": {}},
},
}
for t in listed.tools
]
messages = [{"role": "system", "content": args.system_prompt}]
async with httpx.AsyncClient(base_url=args.ollama_host, timeout=120.0) as client:
print("接続しました。終了には「exit」と入力してください。")
while True:
user = input("user> ").strip()
if user.lower() in {"exit", "quit"}:
print("bye")
return
if not user:
continue
messages.append({"role": "user", "content": user})
while True:
data = await ollama_chat(client, args.model, messages, tools)
msg = data.get("message") or {}
calls = msg.get("tool_calls") if isinstance(msg.get("tool_calls"), list) else []
text = message_text(msg, data)
if not calls and not text.strip():
retry = await ollama_chat(client, args.model, messages, [])
rmsg = retry.get("message") or {}
rcalls = rmsg.get("tool_calls") if isinstance(rmsg.get("tool_calls"), list) else []
rtext = message_text(rmsg, retry)
if rcalls or rtext.strip():
data, msg, calls, text = retry, rmsg, rcalls, rtext
messages.append(msg)
if not calls:
if text.strip():
print(f"assistant> {text}")
else:
print("assistant> (empty response)")
if args.debug:
print("debug(raw)>", json.dumps(data, ensure_ascii=False))
break
for c in calls:
fn = c.get("function", {})
name = fn.get("name")
if not name:
continue
result = await mcp.call_tool(name, tool_args(fn.get("arguments")))
out = tool_output(result)
messages.append({"role": "tool", "content": out})
print(f"tool[{name}]> {out}")
def main():
asyncio.run(run(parse_args()))
if __name__ == "__main__":
main()
----
音声でReachy Miniと会話するコード
・requirements.txt
----
mcp
httpx
RealtimeSTT
requests
----
・reachy_ollama_cli.py
----
import argparse
import asyncio
import json
import os
import shutil
import subprocess
import sys
import tempfile
import httpx
from RealtimeSTT import AudioToTextRecorder
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
DEFAULT_MCP_PYTHON = "/home/npaka/reachy-mini-mcp/env/bin/python"
DEFAULT_MCP_SERVER = "/home/npaka/reachy-mini-mcp/server.py"
DEFAULT_OLLAMA_HOST = "http://localhost:11434"
DEFAULT_MODEL = "qwen3:8b"
DEFAULT_SYSTEM_PROMPT = "あなたはReachy Miniを操作するロボットアシスタントです。積極的にツールを使ってください。回答は日本語を1セリフで返して。"
DEFAULT_OPEN_JTALK_BIN = "/usr/bin/open_jtalk"
DEFAULT_OPEN_JTALK_DIC = "/var/lib/mecab/dic/open-jtalk/naist-jdic"
DEFAULT_OPEN_JTALK_VOICE = "/usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice"
DEFAULT_AUDIO_PLAYER = "afplay" if sys.platform == "darwin" else "aplay"
def parse_args():
p = argparse.ArgumentParser(description="Ollama + Reachy Mini MCP CLI")
p.add_argument("--model", default=DEFAULT_MODEL)
p.add_argument("--ollama-host", default=DEFAULT_OLLAMA_HOST)
p.add_argument("--mcp-python", default=DEFAULT_MCP_PYTHON)
p.add_argument("--mcp-server", default=DEFAULT_MCP_SERVER)
p.add_argument("--system-prompt", default=DEFAULT_SYSTEM_PROMPT)
p.add_argument("--open-jtalk-bin", default=DEFAULT_OPEN_JTALK_BIN)
p.add_argument("--open-jtalk-dic", default=DEFAULT_OPEN_JTALK_DIC)
p.add_argument("--open-jtalk-voice", default=DEFAULT_OPEN_JTALK_VOICE)
p.add_argument("--audio-player", default=os.getenv("AUDIO_PLAYER", DEFAULT_AUDIO_PLAYER))
p.add_argument("--debug", action="store_true")
return p.parse_args()
async def ollama_chat(client, model, messages, tools):
r = await client.post(
"/api/chat",
json={"model": model, "messages": messages, "tools": tools, "stream": False},
)
r.raise_for_status()
return r.json()
def message_text(message, payload):
c = message.get("content")
if isinstance(c, str):
return c
if isinstance(c, list):
parts = [str(x.get("text", "")) for x in c if isinstance(x, dict) and x.get("type") == "text"]
if parts:
return "\n".join(parts)
return payload.get("response") or payload.get("output_text") or ""
def tool_args(raw):
if isinstance(raw, dict):
return raw
if not isinstance(raw, str) or not raw.strip():
return {}
try:
parsed = json.loads(raw)
except json.JSONDecodeError:
return {}
return parsed if isinstance(parsed, dict) else {}
def tool_output(result):
content = getattr(result, "content", None)
if content:
parts = []
for x in content:
t = getattr(x, "text", None)
if t:
parts.append(t)
elif isinstance(x, dict) and x.get("type") == "text":
parts.append(str(x.get("text", "")))
if parts:
return "\n".join(parts)
structured = getattr(result, "structuredContent", None)
return json.dumps(structured, ensure_ascii=False) if structured is not None else "(no tool output)"
def resolve_audio_player(preferred):
if preferred and shutil.which(preferred):
return preferred
if sys.platform == "darwin":
candidates = ["afplay"]
else:
candidates = ["aplay", "paplay", "play"]
for c in candidates:
if shutil.which(c):
return c
return None
def speak_text(text, recorder=None, *, open_jtalk_bin="open_jtalk", dic_path=None, voice_path=None, audio_player="afplay"):
if not text or not text.strip():
return
if not dic_path or not voice_path:
print("tts(error)> OPEN_JTALK_DIC と OPEN_JTALK_VOICE を設定してください")
return
try:
if recorder and hasattr(recorder, "stop"):
recorder.stop()
if not shutil.which(open_jtalk_bin):
print(f"tts(error)> '{open_jtalk_bin}' が見つかりません")
return
resolved_player = resolve_audio_player(audio_player)
if not resolved_player:
print("tts(error)> 再生コマンドが見つかりません (aplay/paplay/play)")
return
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as f:
wav_path = f.name
try:
cmd = [open_jtalk_bin, "-x", dic_path, "-m", voice_path, "-g", str(10), "-ow", wav_path]
subprocess.run(
cmd,
input=text,
text=True,
check=True,
capture_output=True,
)
subprocess.run([resolved_player, wav_path], check=True)
finally:
if os.path.exists(wav_path):
os.remove(wav_path)
except Exception as e:
print(f"tts(error)> {e}")
async def run(args):
server = StdioServerParameters(command=args.mcp_python, args=[args.mcp_server])
stt_recorder = AudioToTextRecorder()
try:
async with stdio_client(server) as (r, w):
async with ClientSession(r, w) as mcp:
await mcp.initialize()
listed = await mcp.list_tools()
tools = [
{
"type": "function",
"function": {
"name": t.name,
"description": t.description or "",
"parameters": getattr(t, "inputSchema", None) or {"type": "object", "properties": {}},
},
}
for t in listed.tools
]
messages = [{"role": "system", "content": args.system_prompt}]
async with httpx.AsyncClient(base_url=args.ollama_host, timeout=120.0) as client:
print("接続しました。終了には「バイバイ」と発話してください。")
while True:
if hasattr(stt_recorder, "start"):
stt_recorder.start()
print("user(voice)> ", end="", flush=True)
user = stt_recorder.text().strip()
print(user)
if user.lower() in {"バイバイ"}:
print("bye")
return
if not user:
continue
messages.append({"role": "user", "content": user})
while True:
data = await ollama_chat(client, args.model, messages, tools)
msg = data.get("message") or {}
calls = msg.get("tool_calls") if isinstance(msg.get("tool_calls"), list) else []
text = message_text(msg, data)
if not calls and not text.strip():
retry = await ollama_chat(client, args.model, messages, [])
rmsg = retry.get("message") or {}
rcalls = rmsg.get("tool_calls") if isinstance(rmsg.get("tool_calls"), list) else []
rtext = message_text(rmsg, retry)
if rcalls or rtext.strip():
data, msg, calls, text = retry, rmsg, rcalls, rtext
messages.append(msg)
if not calls:
if text.strip():
print(f"assistant> {text}")
speak_text(
text,
stt_recorder,
open_jtalk_bin=args.open_jtalk_bin,
dic_path=args.open_jtalk_dic,
voice_path=args.open_jtalk_voice,
audio_player=args.audio_player,
)
else:
print("assistant> (empty response)")
if args.debug:
print("debug(raw)>", json.dumps(data, ensure_ascii=False))
break
for c in calls:
fn = c.get("function", {})
name = fn.get("name")
if not name:
continue
result = await mcp.call_tool(name, tool_args(fn.get("arguments")))
out = tool_output(result)
messages.append({"role": "tool", "content": out})
print(f"tool[{name}]> {out}")
finally:
if hasattr(stt_recorder, "shutdown"):
stt_recorder.shutdown()
def main():
asyncio.run(run(parse_args()))
if __name__ == "__main__":
main()
----
第2回のまとめ
第2回の本記事ではDGX Sparkの環境をセットアップして、Reachy MiniをつなげローカルAIロボットとして動作させるところまでを紹介した。ロボットに「脳」「体」「耳」「口」などの機能を持たせるため、複数の環境をインストールする必要があるが、一度セットアップしてしまえば、音声で指示を行うことでロボットが、実際に指示どおりに動作してくれることがわかるだろう。
次の連載第3回目では、ここまでつくったローカルAIロボットをさらに実用寄りに育てる活用方法を紹介していこう。たとえば、会話の継続性(メモリ)を持たせる、反応や感情表現を増やす、定型タスクを自動化する、カメラ入力や環境センサーと連携するなど、Reachy Miniを今回行なった「デモ動作」から、「身近な相棒」にしていくための拡張アイデアを扱っていくことにしたい。
関連記事
お問い合わせ
エヌビディア合同会社
www.nvidia.com/ja-jp/contact
TEXT_布留川英一 / Hidekazu Furukawa
EDIT_佐藤英一 / Eiichi Sato(ボーンデジタル)













