
Googleは5月21日(水)、動画生成AIモデル「Veo 3」をリリースした。有料サブスクリプションのGoogle AI Proユーザーは10パックのトライアル、Google AI Ultraユーザーは無制限に近い利用(またはFlowでの利用)が可能となる。
Create videos with Veo 3, now available in 73 countries right in the Gemini app pic.twitter.com/LzgsVKyqxx
— Google (@Google) May 30, 2025
Veo 3は、Veo 2ではできなかった動画への音声付加に対応。テキストプロンプトから効果音やBGM、セリフ、会話といった音声を生成できるようになった。また、発話シーンにおけるリップシンクの精度も向上している。
映像品質面では、より高いリアリズムや忠実度を実現し、物理法則や人間の自然な動きや表情のニュアンスを豊かに表現できるようになった。また、テキストプロンプトへの忠実性が向上し、高品質な4K出力も可能となっている。
その他、カメラアングルやフレーミング、モーションのより細かな制御が可能になったほか、異なるクリップ間でキャラクターの一貫性を維持する能力も向上している。
We’re also launching Veo 3, our state-of-the-art video generation model.
— Google Gemini App (@GeminiApp) May 20, 2025
Veo 3 lets you generate videos with sound effects, background noises and even dialogue.#GoogleIO pic.twitter.com/atVx6HvI9R
Just got access to Veo 3 and the first thing I did was try the Will Smith spaghetti test. SOUND ON pic.twitter.com/y0CiZwNxgM
— Javi Lopez (@javilopen) May 22, 2025
Google AI Proメンバーシップでは10パックのトライアルが利用可能
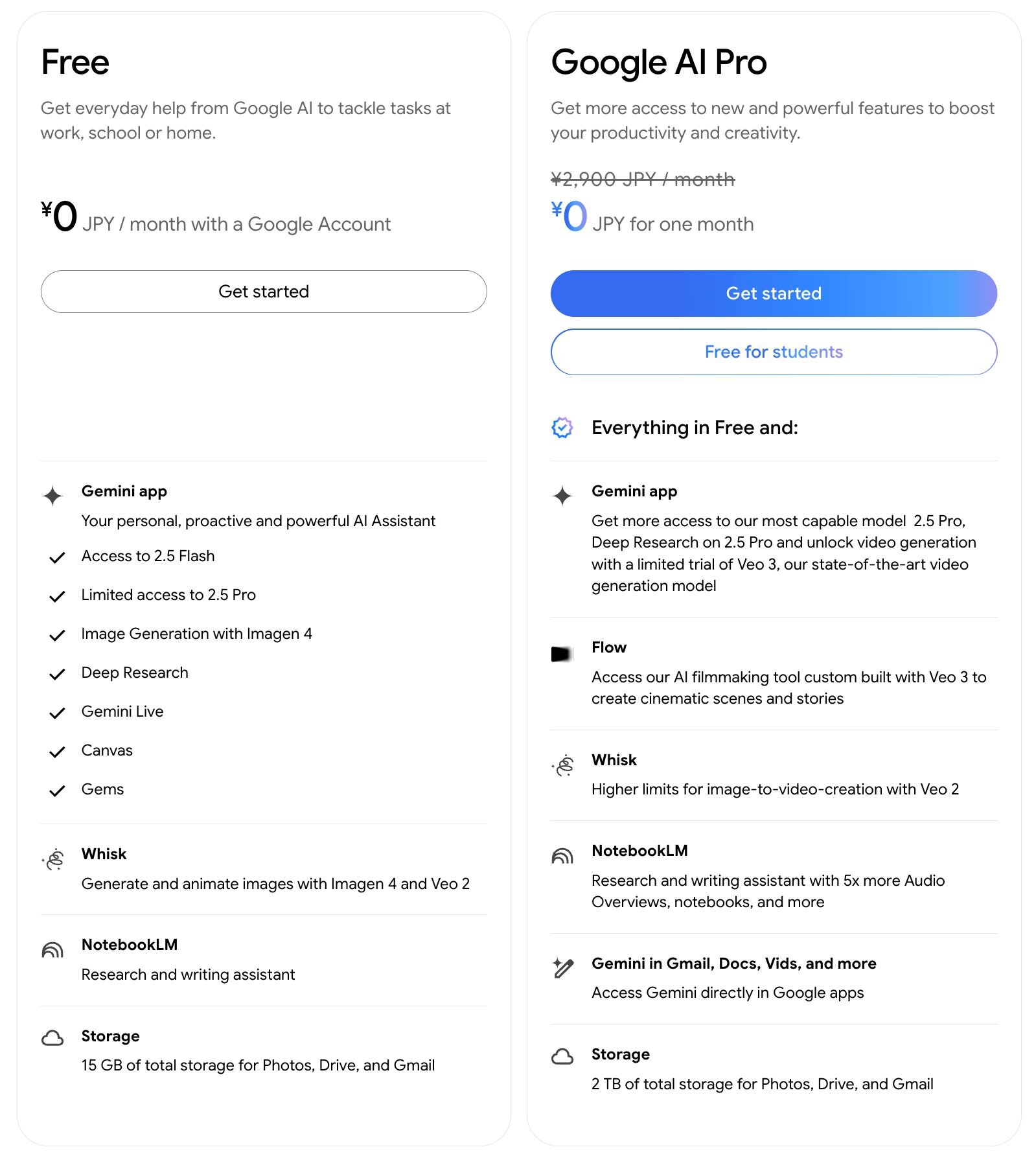

Gemini appの無料版ではVeoへのアクセスはできない。月2,900円(初月無料)のGoogle AI Proサブスクリプションでは10パックのVeo 3トライアルが利用可能。Veo 3の無制限に近い利用やFlow上でのVeo 3利用には、Google AI Ultraサブスクリプションが必要となる。
CGWORLD関連情報
●Googleがクリエイター向けAI映像制作ツール「Flow」をリリース! Veo・Imagen・Geminiを統合

Googleは映像制作者と共同開発したクリエイター向けAI映像制作ツール「Flow」をリリース。同社動画生成AI「Veo」、画像生成AI「Imagen」、AIアシスタント「Gemini」を統合したクリエイター向けAI映像制作ツール。利用にはGoogle AIのサブスクリプションが必要となる。
https://cgworld.jp/flashnews/01-202506-Google-Flow.html
●Tencentの3Dモデル生成AI「PrimitiveAnything」オープンソースで公開! 複雑な形状をプリミティブに分解して構築するモデル

Tencent AIPDと清華大学の研究チームが、3Dモデル生成AI「PrimitiveAnything」をオープンソースで公開。人の手によって分解されたモデルデータを10万以上学習し、AIが人間らしい分解の傾向を習得することで、複雑な形状を、人間が直感的に理解できるプリミティブの組み合わせに分解して構築する。
https://cgworld.jp/flashnews/01-202505-PrimitiveAnything.html
●RodinのDeemosが画像から3Dシーンを再構成する新手法「CAST」を発表! 次期Rodinに搭載予定

上海科技大学、3Dモデル生成AI「Rodin」のDeemos社、華中科技大学の研究チームが、1枚のRGB画像から3Dシーンを再構築する手法「CAST: Component-Aligned 3D Scene Reconstruction from an RGB Image」を発表。Rodin次期バージョンへの搭載を予定している。
https://cgworld.jp/flashnews/01-202505-CAST.html











