
Tencent AIPDと清華大学の研究チームは5月9日(金)、3Dモデル生成AI「PrimitiveAnything」をオープンソースで公開した。人の手によって分解されたモデルデータを10万以上学習し、AIが人間らしい分解の傾向を習得することで、複雑な形状を、人間が直感的に理解できるプリミティブの組み合わせに分解して構築する。
PrimitiveAnythingでは、人間がモデリングする工程を模倣して、分解可能なモデル構造を自然に構築することを目的に、会話型AIと同様の、図形を1つずつ順番に生成して追加する仕組みを採用。モデリングに用いるプリミティブはプリミティブ種(CubeやSphereなど)・位置・向き・大きさの4情報で制御・統一され、複雑な形状の処理をスムーズ化している。また、PrimitiveAnythingのシステムが用いるAIは「全体を見渡すAI」と「ディテールを決めるAI」の2つで構成され、分業により効率良く高精度の分解を実現するという。
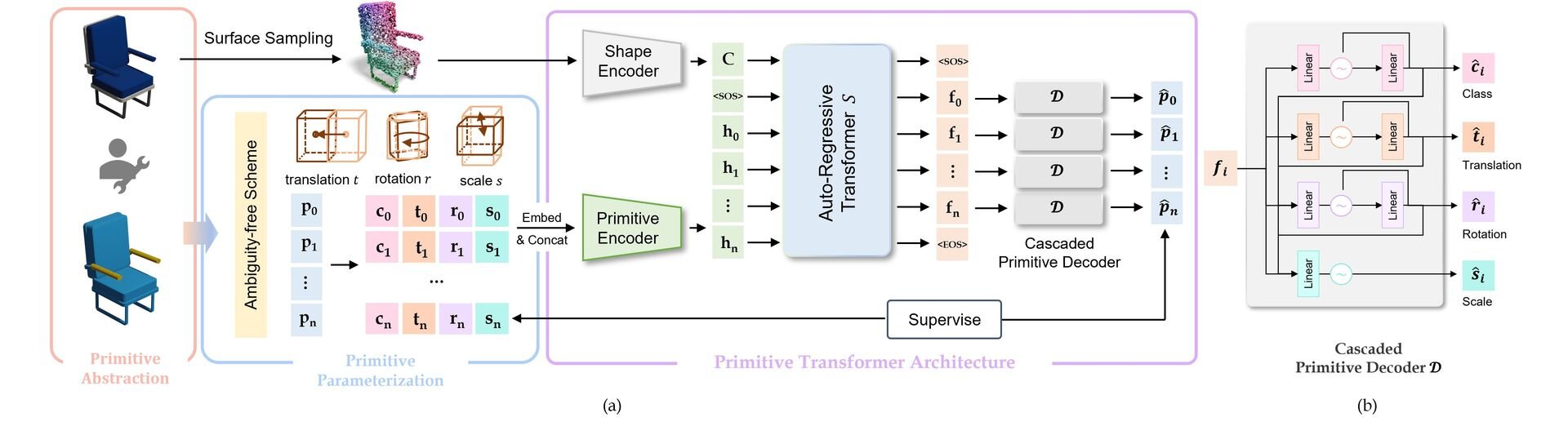


研究チームのテストでは、従来技術と比較して、形状の再現精度が最大2.3倍向上し、83%のユーザーが自然な分解だと評価。処理速度は高精度のモデルでも1形状あたり約15秒となっている。本技術の活用シーンとしては、ゲーム開発や建築設計、3Dモデリング教育などが想定されている。
なお現在、マウスの動きに連動したリアルタイム処理や、ねじれたパイプなどの特殊なプリミティブ形状への対応、生成モデルを3Dプリンタで直接プリントする機能などを開発中とのこと。
■PrimitiveAnything: Human-Crafted 3D Primitive Assembly Generation with Auto-Regressive Transformer(プロジェクトページ、英語)
https://primitiveanything.github.io/
■PrimitiveAnything: Human-Crafted 3D Primitive Assembly Generation with Auto-Regressive Transformer(GitHub)
https://github.com/PrimitiveAnything/PrimitiveAnything
CGWORLD関連情報
●RodinのDeemosが画像から3Dシーンを再構成する新手法「CAST」を発表! 次期Rodinに搭載予定

上海科技大学、3Dモデル生成AI「Rodin」のDeemos社、華中科技大学の研究チームが、1枚のRGB画像から3Dシーンを再構築する手法「CAST: Component-Aligned 3D Scene Reconstruction from an RGB Image」を発表。Rodin次期バージョンへの搭載を予定している。
https://cgworld.jp/flashnews/01-202505-CAST.html
●1枚の画像から3Dフェイスモデルを再構成する技術「Pixel3DMM」発表! 画像からノーマルとUVを推定し大規模データセットのパラメータに最適化
ミュンヘン工科大学、イギリスSynthesia社、ユニバーシティ・カレッジ・ロンドンの研究チームが、1枚の画像から3Dフェイスモデルを再構成する技術「Pixel3DMM: Versatile Screen-Space Priors for Single-Image 3D Face Reconstruction」を発表。
https://cgworld.jp/flashnews/01-202505-Pixel3DMM.html
●「Meta 3D AssetGen 2.0」発表! Metaの3Dアセット生成AI基盤モデルがアップデート、2025年後半よりHorizonクリエイターに提供予定

Metaが次世代の3Dアセット生成AI基盤モデル「Meta 3D AssetGen 2.0」を発表。単一ステージの3D拡散(diffusion)モデルを採用することにより、前世代と比較して高品質なメッシュとテクスチャを効率的に生成できるという。テキストまたは画像からの3Dアセット生成に対応する。
https://cgworld.jp/flashnews/01-202505-Meta-3D-AssetGen-20.html













