ミュンヘン工科大学、イギリスSynthesia社、ユニバーシティ・カレッジ・ロンドンの研究チームは5月2日(金)、1枚の画像から3Dフェイスモデルを再構成する技術「Pixel3DMM: Versatile Screen-Space Priors for Single-Image 3D Face Reconstruction」を発表した。
Pixel3DMM: Versatile Screen-Space Priors for Single-Image 3D Face Reconstruction
— Matthias Niessner (@MattNiessner) May 2, 2025
-> highly accurate face reconstruction by training powerful VITs via surface normals and UV-coordinates estimation.
The geometric cues from our 2D foundation model backbone constrain the 3DMM… pic.twitter.com/uBNKEPgbsH
Pixel3DMMは、各ピクセルごとに3Dジオメトリの手がかりとなるジオメトリック・キューを予測するビジョントランスフォーマーモデル(ViT、Vision Transformer)で、3Dによるモーフィングが可能な3Dフェイスモデル(3D Morphable Model、3DMM)の最適化をサポートする技術となる。
Pixel3DMMのViTは、自己教師あり学習(Self-Supervised Learning)で訓練済みの画像認識モデル「DINO」で、入力画像からピクセル単位でサーフェスノーマル(法線、顔表面の向き)とUV座標を予測。これらの情報を用いて、表情や顔の形状をパラメータで制御できる3Dフェイスモデル「FLAME」のパラメータを最適化し、3Dフェイスのジオメトリ形状を復元する。
■Pixel3DMM: Versatile Screen-Space Priors for Single-Image 3D Face Reconstruction(プロジェクトページ、英語)
https://simongiebenhain.github.io/pixel3dmm/
CGWORLD関連情報
●「Meta 3D AssetGen 2.0」発表! Metaの3Dアセット生成AI基盤モデルがアップデート、2025年後半よりHorizonクリエイターに提供予定

Metaが次世代の3Dアセット生成AI基盤モデル「Meta 3D AssetGen 2.0」を発表。単一ステージの3D拡散(diffusion)モデルを採用することにより、前世代と比較して高品質なメッシュとテクスチャを効率的に生成できるという。テキストまたは画像からの3Dアセット生成に対応する。
https://cgworld.jp/flashnews/01-202505-Meta-3D-AssetGen-20.html
●3Dモデル生成AI「Meshy」に自動リギング機能と複数画像からの3Dモデル生成機能が追加! リギングは人型と犬に対応、無料プランで利用可
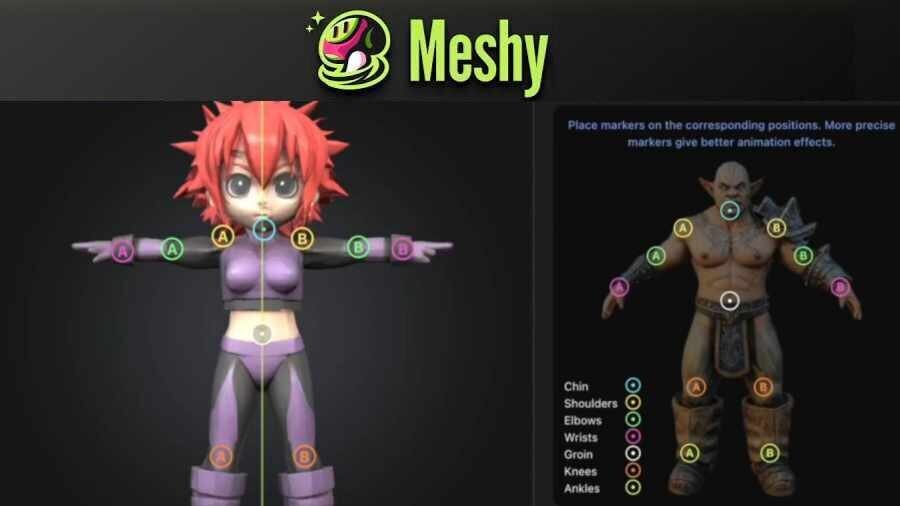
Meshyが3Dモデル生成AI「Meshy」に自動リギング機能を追加。まずは人型と犬のリグに対応しており、人型はTポーズまたはAポーズのモデルに適用できる。無料プランでも利用可能。
https://cgworld.jp/flashnews/01-202505-Meshy-AutoRig.html
●Tencentの3Dモデル生成AI「Hunyuan3D 2.5」リリース! モデルのパラメータ10倍、4Kテクスチャ、マルチビューPBR、自動リギング、1日20回まで無料生成可能

テンセントが3Dアセット生成AI「Hunyuan3D 2.5」をリリース。モデルのパラメータ数が大幅に増加したことによりシャープなエッジを描出できるようになったほか、4Kテクスチャ、マルチビューPBR、自動リギング(ボーンのバインドとウェイト設定)にも対応。公式ワークスペースのTencent Hunyuan 3D AI Creation Engineで利用でき、1日20回まで無料で生成が行える。
https://cgworld.jp/flashnews/01-202505-Hunyuan3D-25.html













