
Google DeepMindは11月14日(金)、次世代AIエージェント「SIMA 2」(Scalable Instructable Multiworld Agent)を発表した。同社の高性能AIモデル「Gemini」の統合により、仮想3D世界でプレイし、推論し、人間と共に学習する、対話可能なAIエージェントとなったまた、同社が開発した画像やテキストから仮想世界を生成するAI「Genie 3」との連携実験においても高い適応性を見せたという。SIMA 2はまず、研究プレビューとして一部の研究者やゲーム開発者に提供されている。
高い推論能力による抽象的な目標理解と複雑な手順の計画的実行
Advanced reasoning
— Google DeepMind (@GoogleDeepMind) November 13, 2025
We trained SIMA 2 to achieve high-level goals in a wide array of games – allowing it to perform complex reasoning and independently plan how to accomplish tasks.
It acts like a collaborative partner that can explain its intentions and answer questions… pic.twitter.com/RXgWoJObRb
SIMA 2はGeminiモデルを中核に据えることにより、推論能力を向上させた。従来のAIエージェントが単純な命令に従うことに主眼を置いていたのに対し、SIMA 2はユーザーの抽象的な目標を理解し、それを達成するための複雑な手順を自ら計画・実行できる。AIエージェント自身の行動や視覚情報についても言語化できるため、ユーザーから「何をしているのか?」と問われれば、現在見ている状況や、次にどのような行動を取る予定かを説明できる。
未学習のゲームや環境にも柔軟に適応
Generalization
— Google DeepMind (@GoogleDeepMind) November 13, 2025
SIMA 2 is now far better at carrying out detailed instructions, even in worlds it's never seen before.
It can transfer learned concepts like “mining” in one game and apply it to “harvesting” in another – connecting the dots between similar tasks.
It even… pic.twitter.com/ANldQVWFd4
SIMA 2は、学習していない新しいゲームや環境に対しても高い適応能力(ジェネラリゼーション、汎化性能)を示す。マルチモーダル入力にも対応し、テキストや音声だけでなく、画面上のスケッチや画像、絵文字や多言語での指示も理解し、適切なアクションを起こすことができる。
試行錯誤を通じてスキルを磨く自己改善サイクル
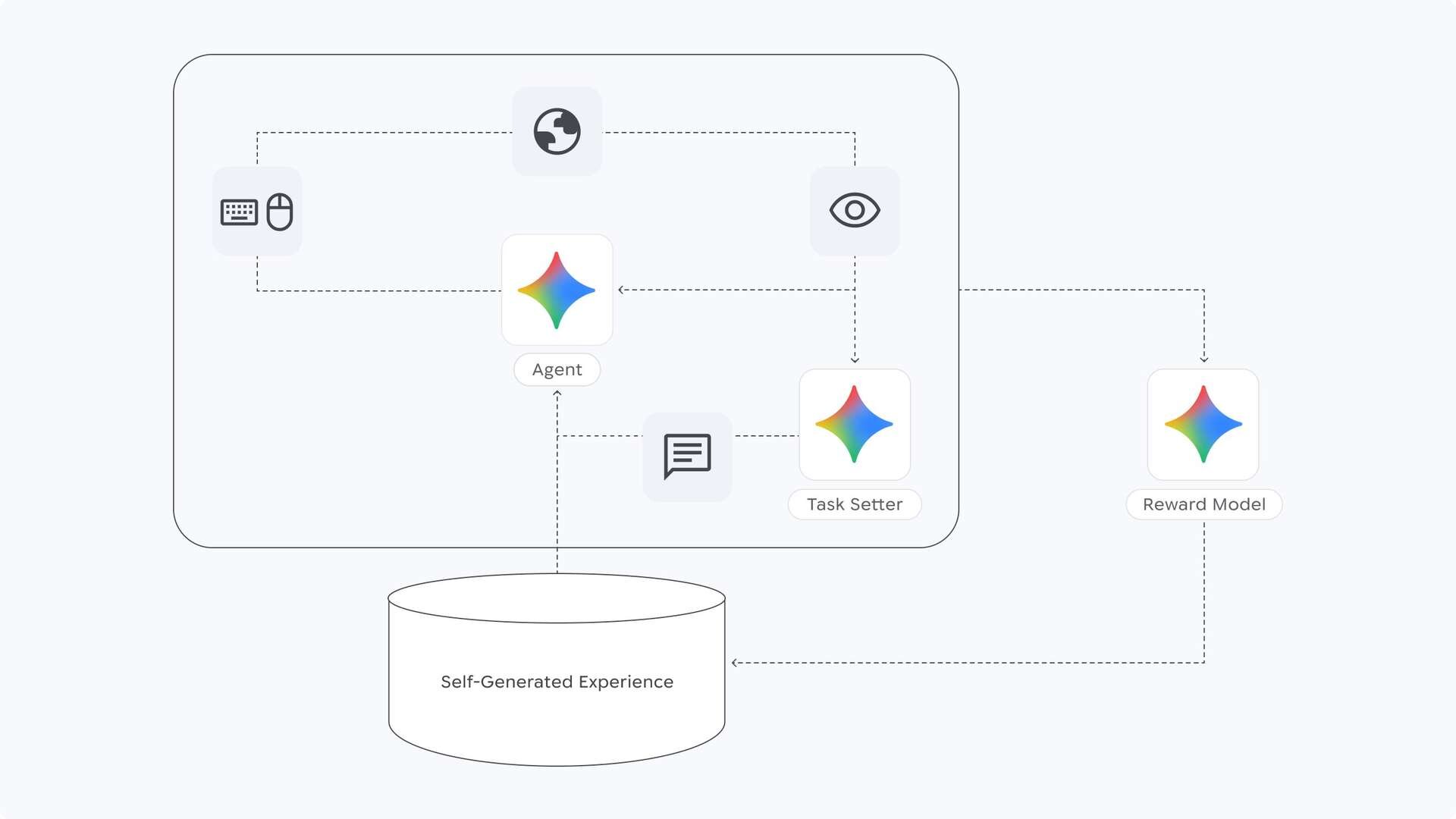
SIMA 2は、人間の介入なしに自己学習する能力を備える。Geminiからのフィードバックと報酬推定を用いた「自己改善サイクル」により、試行錯誤を通じてスキルを磨き続けることができる。
世界モデルGenie 3との連携でも高い適応性を見せる
SIMA 2 Genie 3
— Google DeepMind (@GoogleDeepMind) November 13, 2025
We tested SIMA 2’s abilities in simulated 3D worlds created by our world model Genie 3.
It demonstrated unprecedented adaptability by navigating its surroundings and took meaningful steps toward goals. pic.twitter.com/9M9bVMqD6e
画像やテキストから仮想世界を生成するAI「Genie 3」との連携実験では、生成されたばかりの未知の世界においても、SIMA 2は即座に状況を把握し、意味のある行動をとることができたと報告されている。
■SIMA 2: An Agent that Plays, Reasons, and Learns With You in Virtual 3D Worlds(Google DeepMind Blog、英語)
https://deepmind.google/blog/sima-2-an-agent-that-plays-reasons-and-learns-with-you-in-virtual-3d-worlds/
CGWORLD関連情報
●Googleの世界モデル「Genee 3」発表! テキストプロンプトからインタラクティブでプレイ可能な3D環境を生成、720p・24フレーム/秒

Google DeepMindが新しい世界モデル「Genie 3」を発表。テキストプロンプトからリアルタイムで操作可能な多様なインタラクティブ環境を生成できる汎用モデルで、720p・24フレーム/秒、数分間にわたる一貫性を維持できる。現在は一部の研究者やクリエイターを対象とした限定的な研究プレビューとして提供されている。
https://cgworld.jp/flashnews/01-202508-Google-Genee3.html
●ワールドモデル「Genie」のミニマル実装「TinyWorlds」公開! シンプルな実装で生成AIと世界モデルを手軽に体験できるプロジェクト

Anand MajmudarがGoogle Deepmindのワールドモデル(世界モデル)「Genie」のコアアイデアを、少ないコードでシンプルに、300万パラメータで実装したワールドモデル「TinyWorlds」をGitHubで公開。執筆現在はライセンス表記がないため、オープンソースかどうかは不明。
https://cgworld.jp/flashnews/01-202510-TinyWorlds.html
●テンセント、オープンソースの世界モデル「HunyuanWorld-Mirror」公開! 動画や画像から最適化なしで3DGS・深度・カメラパラメータをまとめて高速出力

テンセントがオープンソースの世界モデル「Hunyuan World Models」シリーズの新モデルとして、高速・汎用3D復元モデル「HunyuanWorld-Mirror(Hunyuan World 1.1)」を公開。動画や画像から3Dシーンを数秒で生成し、3DGS(3D Gaussian Splatting)やデプス(深度)マップ、サーフェスノーマル(法線)、カメラパラメータといった3Dデータを一度にまとめて出力できる。GitHubとHugging Faceでコードとウェイトが公開されており、基本的に商用利用が許可されるが、地理的制限などのある独自ライセンスとなっている。
https://cgworld.jp/flashnews/01-202511-HunyuanWorld-Mirror.html











