イギリスSpAItial社は12月16日(火)、テキストや1枚の画像から一貫性のある3D世界を生成する新モデル「Echo」を発表した。Webデモでは3DGS(3D Gaussian Splatting)を採用し、低スペックな機材でもリアルタイムでジオメトリに裏付けされた空間の描画・編集、Webブラウザ上での自由な移動や探索を実現している。現在はクローズドベータ版の登録を受け付け中。
Announcing Echo — our new frontier model for 3D world generation.
Echo turns a simple text prompt or image into a fully explorable, 3D-consistent world. Instead of disconnected views, the result is a single, coherent spatial representation you can move through freely.
This is part of a bigger shift in AI: from generating pixels and tokens to generating spaces. Echo predicts a geometry-grounded 3D scene at metric scale, meaning every novel view, depth map, and interaction comes from the same underlying world — not independent hallucinations.
Once generated, the world is interactive in real time. You control the camera, explore from any angle, and render instantly — even on low-end hardware, directly in the browser. High-quality 3D world exploration is no longer gated by expensive equipment.
Under the hood, Echo infers a physically grounded 3D representation and converts it into a renderable format. For our web demo, we use 3D Gaussian Splatting (3DGS) for fast, GPU-friendly rendering — but the representation itself is flexible and can be easily adapted.
Why this matters: consistent 3D worlds unlock real workflows — digital twins, 3D design, game environments, robotics simulation, and more. From a single photo or a line of text, Echo builds worlds that are reliable, editable, and spatially faithful.
Echo also enables scene editing and restyling. Change materials, remove or add objects, explore design variations — all while preserving global 3D consistency. Editing no longer breaks the world.
This is only the beginning. Echo is the foundation for future world models with dynamics, physical reasoning, and richer interaction — environments that don’t just look right, but behave right.
Explore the generated worlds on our website and sign up for the closed beta. The era of spatial intelligence starts here.3D世界生成のための新たなフロンティアモデル「Echo」を発表します。
Echoは、シンプルなテキストプロンプトや1枚の画像から、完全に探索可能で3Dの一貫性を備えた世界へと変換します。断片的な視点の集まりではなく、その結果として得られるのは、自由に移動できる単一かつ一貫した(coherent)な空間表現です。
これは、AIにおける大きな転換点の一部です。つまり、ピクセルやトークンの生成から、空間そのものの生成への移行です。Echoはメトリックスケールでジオメトリに裏付けられた3Dシーンを予測します。これにより、あらゆる新しい視点、深度マップ、そしてインタラクションが、独立したハルシネーション(幻覚)からではなく、同一の基礎となる世界から導き出されることになります。
一度生成されれば、その世界はリアルタイムでインタラクティブに操作可能です。カメラを制御し、あらゆる角度から探索し、低スペックなハードウェアであってもWebブラウザ上で直接、即座にレンダリングできます。高品質な3D世界の探索は、もはや高価な機材によって制限されるものではありません。その仕組みとして、Echoは物理的に接地された3D表現を推論し、それをレンダリング可能な形式へと変換します。今回のWebデモでは、高速でGPUフレンドリーなレンダリングを実現するために3D Gaussian Splatting(3DGS)を採用していますが、この表現自体は柔軟であり、容易に適応させることが可能です。
これが重要である理由:一貫性のある3D世界は、デジタルツイン、3Dデザイン、ゲーム環境、ロボティクス・シミュレーションなど、実用的なワークフローを切り拓きます。たった1枚の写真画像や1行のテキストから、Echoは信頼性が高く、編集可能で、空間的に忠実な世界を構築します。
また、Echoはシーンの編集やスタイルの変更も可能にします。全体の3D一貫性を保ったまま、素材の質感を変更したり、オブジェクトを追加・削除したり、デザインのバリエーションを探索したりすることができます。編集によって世界(の整合性)が壊れることはもうありません。これは始まりに過ぎません。Echoは、動態、物理的推論、そしてより豊かなインタラクションを備えた将来の「世界モデル」の基盤となります。単に見かけが正しいだけでなく、正しく“振る舞う”環境です。
私たちのWebサイトで生成された世界を探索し、クローズドベータにご登録ください。空間知能(Spatial Intelligence)の時代が、ここから始まります。

SpAItial社は、現実および仮想環境の外観と物理法則の両方を生成・推論するAIパラダイム「空間基盤モデル(Spatial Foundation Models: SFMs)」を提唱し、「Echo」を開発した。SFMs(空間基盤モデル)は、既存のLLMや画像・動画生成モデルがデータ上の相関関係に依存しているのに対して、奥行き・広さ・重さ・繋がりを理解する、3次元(+時間軸の4次元)の知能を備える。「この椅子は床から何センチ浮いているか」といったジオメトリ的な接地を数学的に把握し、メートル法による空間と物体の把握、「このコップは手を離せば落ちる」といった物理的挙動の予測が行える。
EchoはSFMsに立脚したモデルとして、単純なプロンプトや1枚の画像から、メートル法でジオメトリ的に接地し、物理的挙動の予測が可能となる3Dシーンを生成する。これにより、AI特有のハルシネーションを排した、空間的に忠実で信頼性の高い世界を構築できるという。
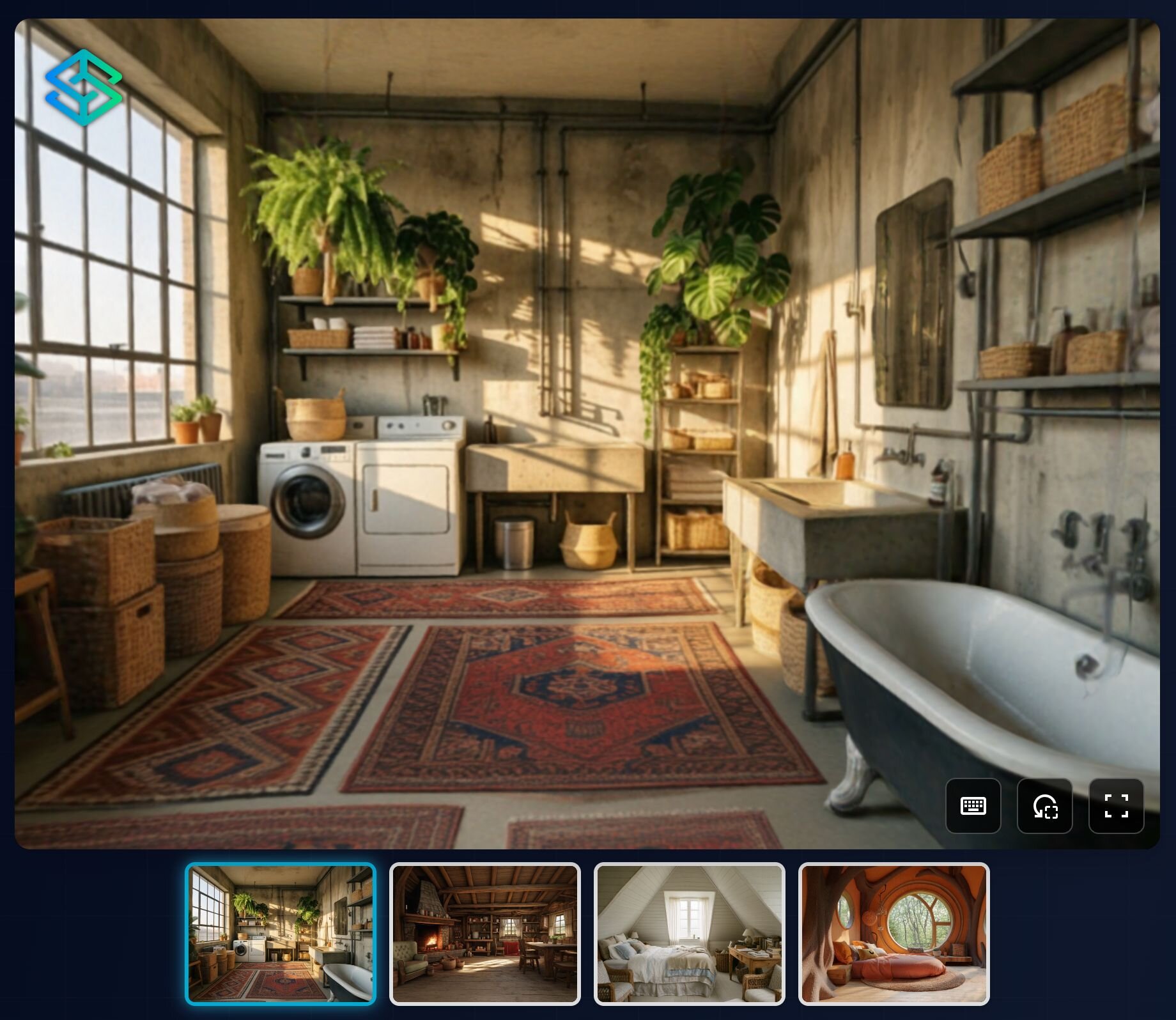

▲公式サイト内に埋め込まれたEchoのデモシーン
Echoでは、物理的に裏付けられた3D表現の推論後、レンダリング可能な形式へと変換するプロセスを踏む。Webデモにおいては3D Gaussian Splatting(3DGS)を採用することにより、一般的なWebブラウザ上でもGPU負荷を抑えた高速な描画を可能にしている。また、Echoは素材の変更や物体の追加・削除といった編集機能も備え、グローバルな一貫性を保ったままデザインの調整が行える。
現在、Echoは公式Webサイトを通じてクローズドベータ版への参加登録を受け付けている。現時点でのライセンス体系や詳細なモデルの仕様は一般公開されていない。
■SpAItial公式ページ
https://www.spaitial.ai/
■Announcing Our Frontier Model for 3D World Generation(SpAItial公式ブログ)
https://www.spaitial.ai/blog/echo-release
CGWORLD関連情報
●Google DeepMind、バーチャル3D空間用AIエージェント「SIMA 2」発表! Gemini駆動、インタラクティブな環境で自律的に思考・理解・行動し、人間と共に学習

Google DeepMindが次世代AIエージェント「SIMA 2」(Scalable Instructable Multiworld Agent)を発表。同社の高性能AIモデル「Gemini」の統合により、仮想3D世界でプレイし、推論し、人間と共に学習する、対話可能なAIエージェントとなったまた、同社が開発した画像やテキストから仮想世界を生成するAI「Genie 3」との連携実験においても高い適応性を見せたという。SIMA 2はまず、研究プレビューとして一部の研究者やゲーム開発者に提供されている。
https://cgworld.jp/flashnews/01-202511-SIMA2.html
●ワールドモデル「Genie」のミニマル実装「TinyWorlds」公開! シンプルな実装で生成AIと世界モデルを手軽に体験できるプロジェクト

Anand MajmudarがGoogle Deepmindのワールドモデル(世界モデル)「Genie」のコアアイデアを、少ないコードでシンプルに、300万パラメータで実装したワールドモデル「TinyWorlds」をGitHubで公開。執筆現在はライセンス表記がないため、オープンソースかどうかは不明。
https://cgworld.jp/flashnews/01-202510-TinyWorlds.html
●テンセント、オープンソースの世界モデル「HunyuanWorld-Mirror」公開! 動画や画像から最適化なしで3DGS・深度・カメラパラメータをまとめて高速出力

テンセントがオープンソースの世界モデル「Hunyuan World Models」シリーズの新モデルとして、高速・汎用3D復元モデル「HunyuanWorld-Mirror(Hunyuan World 1.1)」を公開。動画や画像から3Dシーンを数秒で生成し、3DGS(3D Gaussian Splatting)やデプス(深度)マップ、サーフェスノーマル(法線)、カメラパラメータといった3Dデータを一度にまとめて出力できる。GitHubとHugging Faceでコードとウェイトが公開されており、基本的に商用利用が許可されるが、地理的制限などのある独自ライセンスとなっている。
https://cgworld.jp/flashnews/01-202511-HunyuanWorld-Mirror.html