
Anand Majmudar氏は9月26日(金)、Google Deepmindのワールドモデル(世界モデル)「Genie」のコアアイデアを、少ないコードでシンプルに、300万パラメータで実装したワールドモデル「TinyWorlds」をGitHubで公開した。執筆現在はライセンス表記がないため、オープンソースかどうかは不明。
I spent the past month reimplementing DeepMind’s Genie 3 world model from scratch
— anandmaj (@Almondgodd) September 25, 2025
Ended up making TinyWorlds, a 3M parameter world model capable of generating playable game environments
demo below + everything I learned in thread (full repo at the end) pic.twitter.com/ISUKbiV4LF
ワールドモデル「Genie」は、テキストや画像から世界を生成し、リアルタイムでのインタラクションに応じて世界が変化し、かつ破綻鳴く一貫性を保つAIモデル。「TinyWorlds」はGenieのコンセプトを、よりシンプルで理解しやすい形で実装するため、VAE(Variational Autoencoder、変分オートエンコーダ)とトランスフォーマー(Transformer)に注目。「VAEでゲーム画面を理解し、トランスフォーマーで次の動きや世界の反応を予測する」というGenieの核をミニマルに実装した。
下記はMajmudar氏が自身のXに連投した「TinyWorlds」の説明をまとめたもの。
ワールドモデルの理解

ワールドモデルは動画を生成することで物理世界をシミュレートするニューラルネットワーク。GenieがLLMと同様に、大量の生動画データでスケールアップさせることで「操作性」や「一貫性」といった能力が自然に現れることがわかり、ラベルなし動画から行動を推測するGenieの仕組みを理解するため、TinyWorldsは開発された。
データセットの構築

モデルが生成する世界を決定するため、まずは学習用のデータセットを構築する。YouTubeから『Pong』『Sonic』『Zelda』『Pole』『Doom』といったゲームのプレイ動画を処理し、データセットを作成した。
時空間(space-time)トランスフォーマーの構築
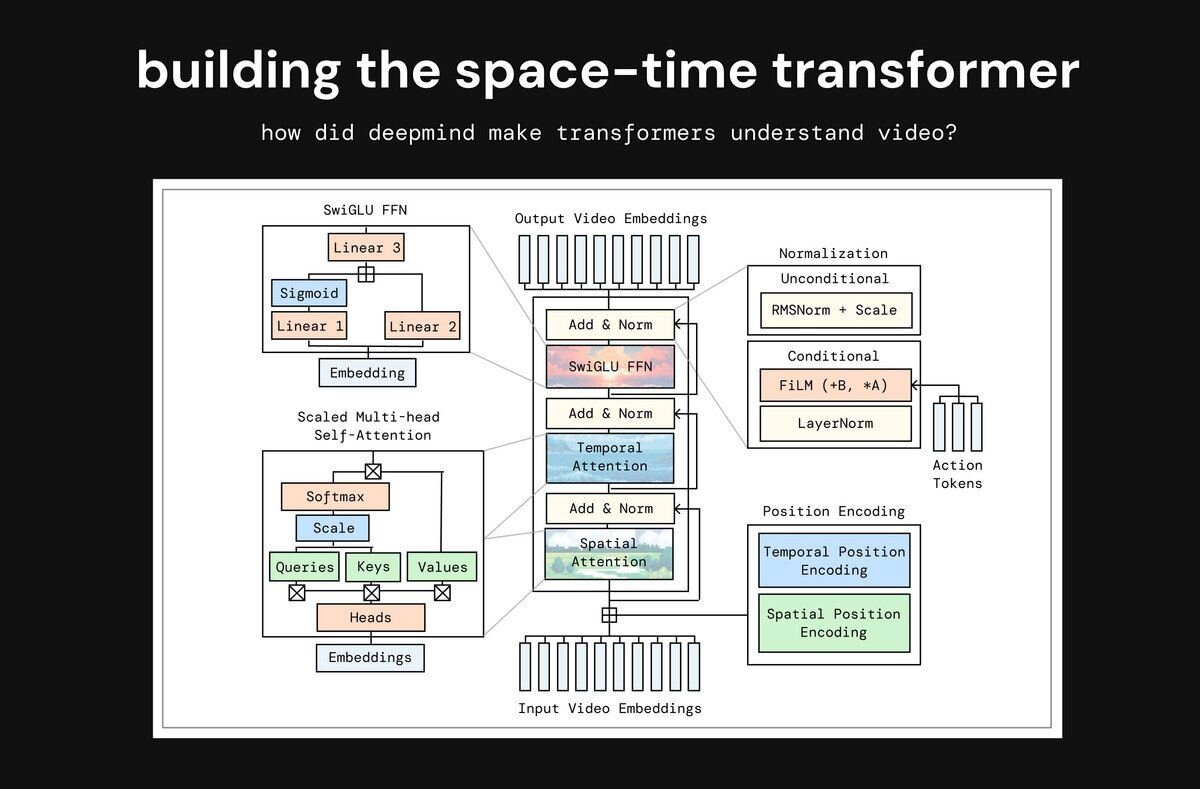
3次元の動画データを理解するためには、時空間トランスフォーマーを構築。ユーザーの操作を動画生成に反映させる方法を実験し、最も性能が良かった手法を採用した。さらに、学習を高速化・安定化させるため、SwiGLUやRMSNormといったLLMの最新技術を導入した。
アーキテクチャの設計
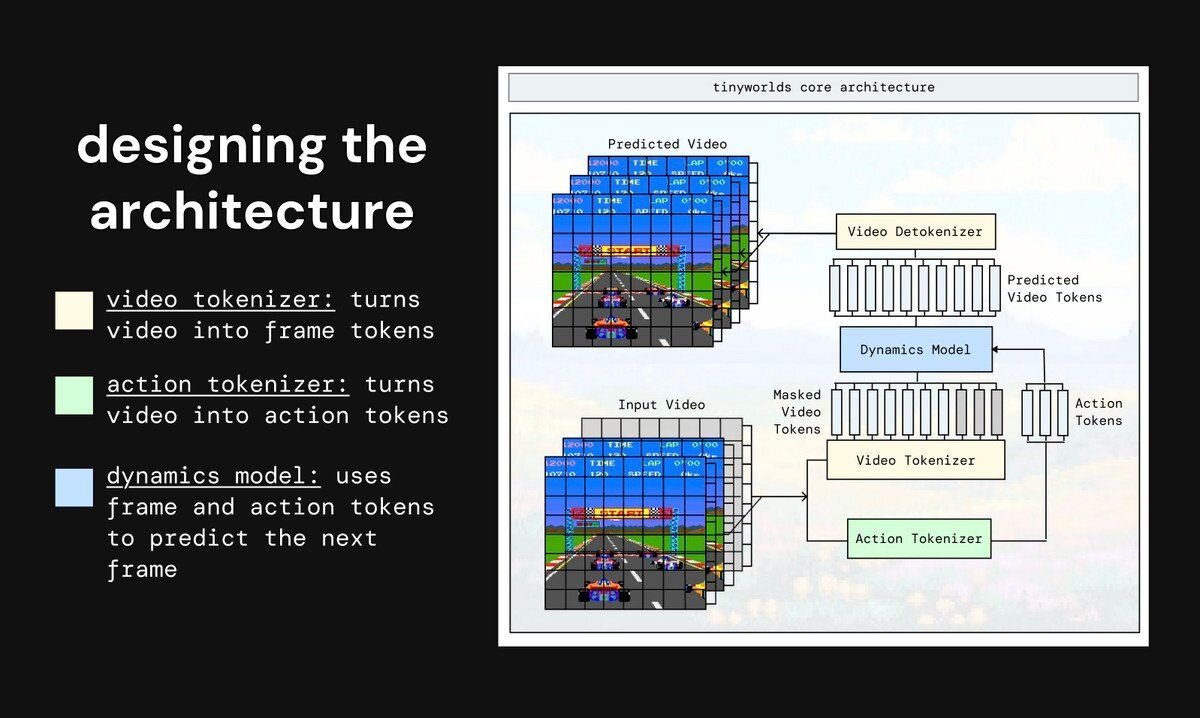
TinyWorldsでは、リアルタイムでの動作に不可欠な推論速度や学習速度、そしてシンプルさを重視し、動画を少しずつ予測していく「自己回帰型(Autoregression)」アーキテクチャを選択した。モデルは、動画を圧縮する「ビデオトークナイザ(tokenizer)」、行動を予測する「アクショントークナイザ」、次の動画を予測する「ダイナミクスモデル」の3つで構成されている。
動画のトークン化
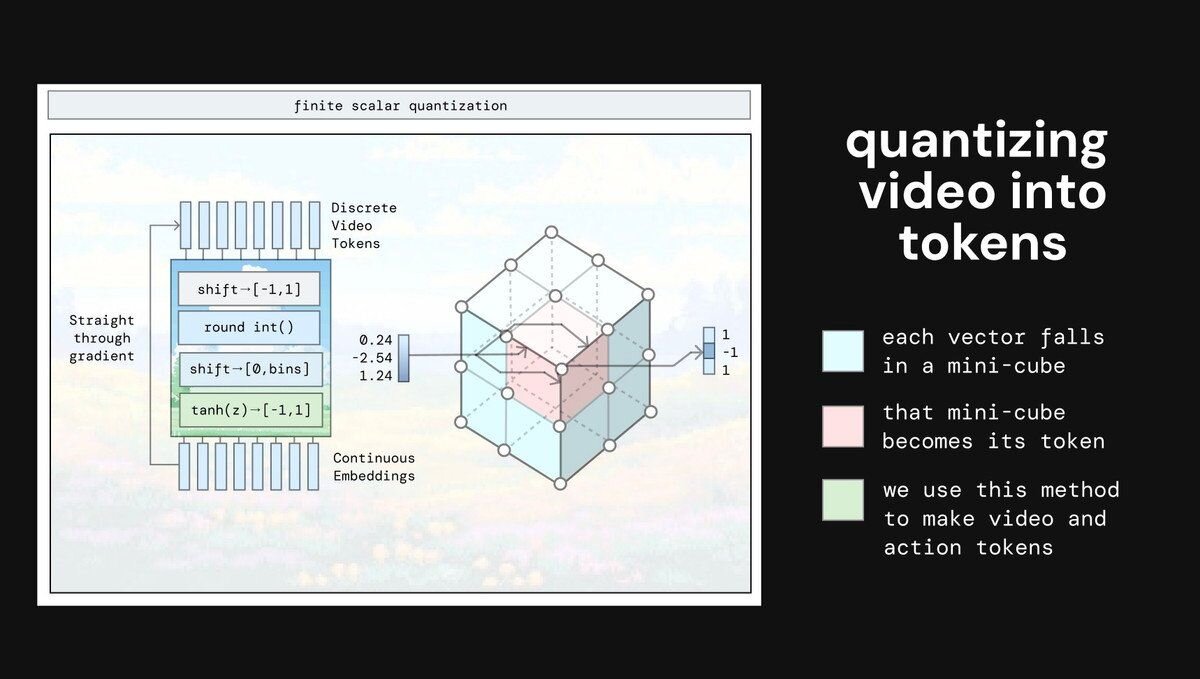
動画をAIが理解しやすいトークンに変換(量子化、quantizing)する方法として、有限スカラー量子化(FSQ、Finite Scalar Quantization)を採用した。これは空間を立方体に分割して画像の一部を表現する手法で、元の画像の有用な情報をトークンに強制的に保持させる。
ビデオトークナイザの学習
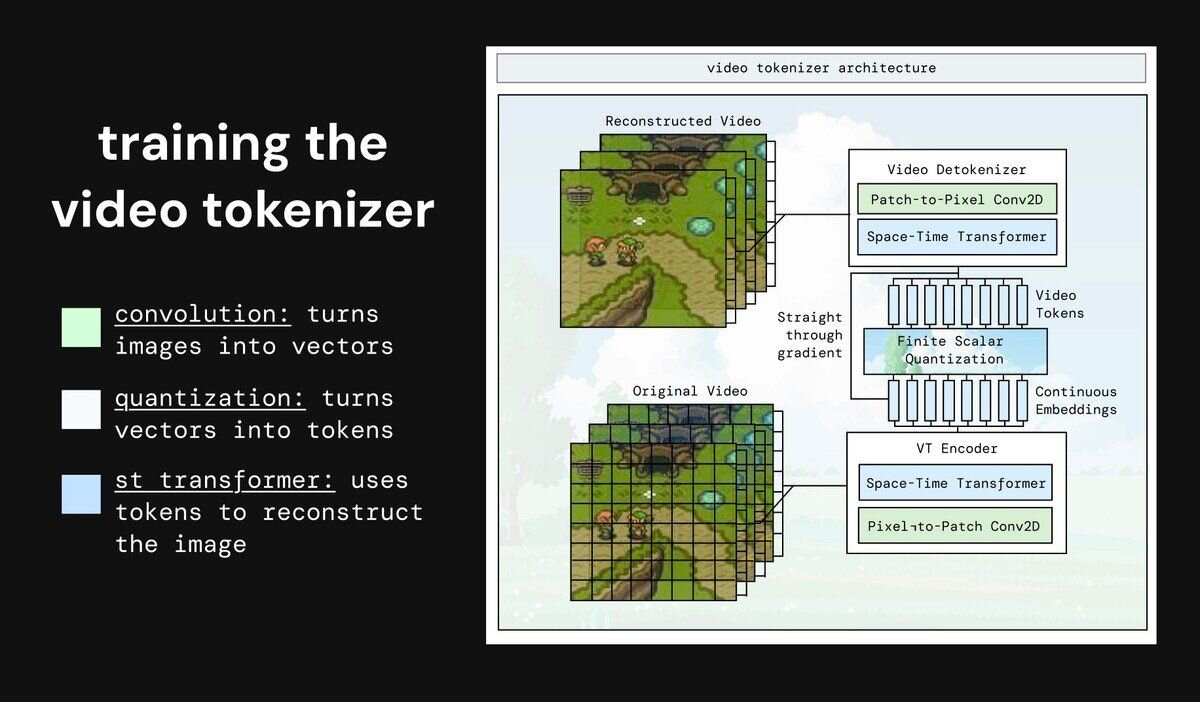
動画をトークンに圧縮する最初のモジュールを学習させた。当初は圧縮率が低く、未来予測の品質に悪影響を与えていた。Majmudar氏は、未来予測という最も困難なタスクを担うダイナミクスモデルの負荷を減らすため、トークナイザが圧縮の大部分を担うべきだと気付いた。
アクショントークナイザの学習

ラベルなし動画で学習可能にするため、2つのフレーム間の行動を予測するアクショントークナイザを学習させた。当初は行動が無視される問題があったが、フレームの一部を隠すなどの工夫で解決。しかし、モデルが小規模なため、トークンが「右」「左」のような意味のある行動には直接対応しなかった。
ワールドジェネレータの学習
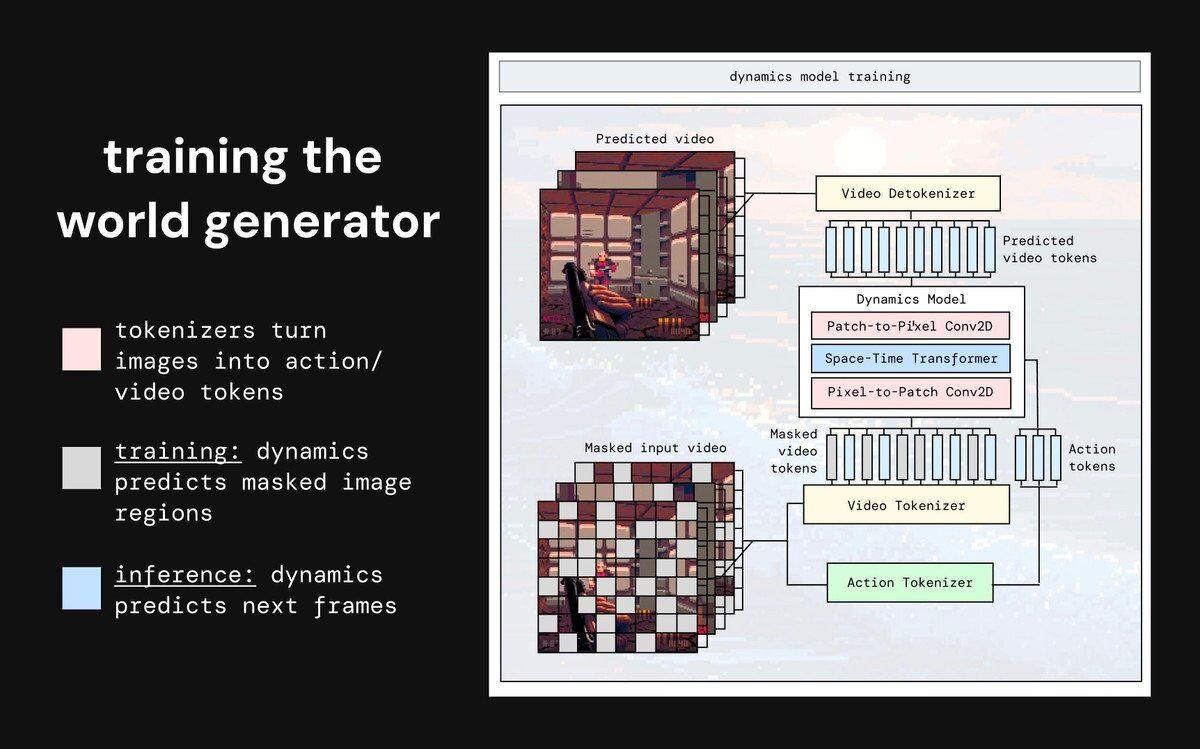
最後に、次のフレームを予測するダイナミクスモデルを学習させた。当初は性能が頭打ちになったが、このモデルがワールドモデルの知能の大部分を担うため、サイズを大幅に大きくしたところ劇的に改善した。完成後、生成されたゲームをプレイできたが、映像はぼやけており、さらなる改善には大規模化が必要であるとMajmudar氏は結論付けた。
■TinyWorlds(GitHub)
https://github.com/AlmondGod/tinyworlds
CGWORLD関連情報
●世界モデル「HunyuanWorld-Voyager」オープンソースで公開! 点群動画から3Dへの直接のエクスポートも可能

テンセントのHunyuanチームが世界モデル「HunyuanWorld-Voyager」をオープンソース(研究や個人利用に加え、一定の条件下で商用利用も許可する独自ライセンス)で公開。1枚の画像とユーザーが定義したカメラの軌道から、3D的に一貫性のある動画を生成できる。
https://cgworld.jp/flashnews/01-202509-HunyuanWorld-Voyager.html
●世界モデル「Mirage 2」公開! 画像とプロンプトからリアルタイムでインタラクティブな空間を生成し、リンク共有でオンラインプレイが可能
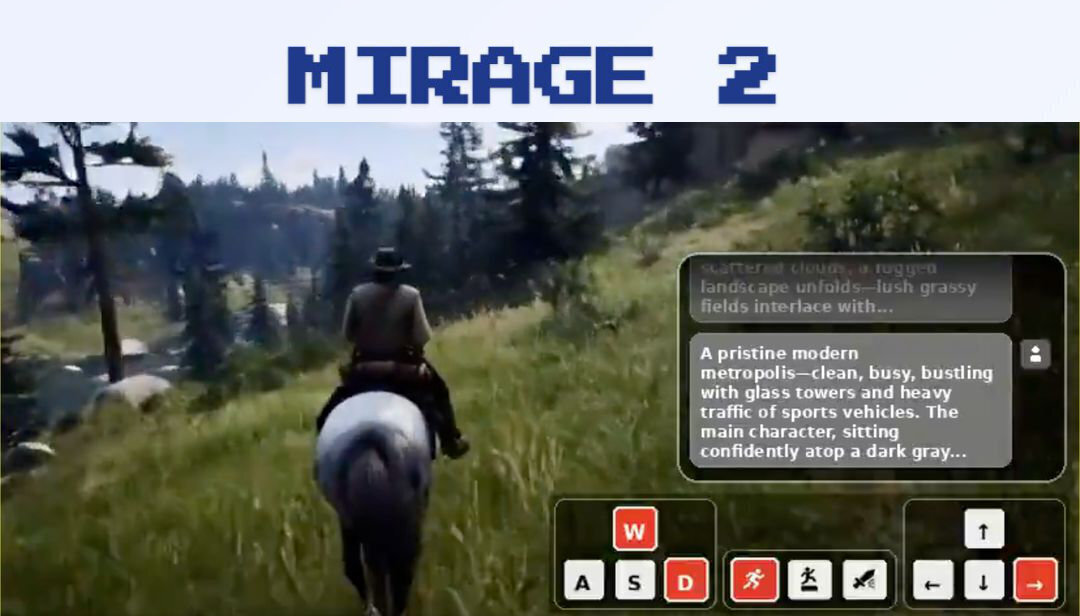
Dynamics LabがAIシステム「Mirage 2」を公開。画像やテキストプロンプトから、ユーザーが操作・探検できるインタラクティブな3D世界をリアルタイムに生成する技術で、ユーザーが創作した世界(ゲーム)はオンラインで共有できる。Mirage 2は現在、ユーザーを問わずオンラインでプレイ可能となっている。
https://cgworld.jp/flashnews/01-202509-Mirage2.html
●オープンソースの世界モデル「Matrix-Game 2.0」リリース! マウスやキーボード操作に反応しながら25fpsの長尺動画をその場で生成

Skywork AIがオープンソース(MITライセンス)の世界モデル「Matrix-Game 2.0」をリリース。マウスやキーボード操作に反応しながら、25fpsの長尺動画をその場で生成する。コードとウエイトがGitHubとHugging Faceで公開されている。
https://cgworld.jp/flashnews/01-202508-Matrix-Game2.html
●Googleの世界モデル「Genee 3」発表! テキストプロンプトからインタラクティブでプレイ可能な3D環境を生成、720p・24フレーム/秒

Google DeepMindが新しい世界モデル「Genie 3」を発表。テキストプロンプトからリアルタイムで操作可能な多様なインタラクティブ環境を生成できる汎用モデルで、720p・24フレーム/秒、数分間にわたる一貫性を維持できる。現在は一部の研究者やクリエイターを対象とした限定的な研究プレビューとして提供されている。
https://cgworld.jp/flashnews/01-202508-Google-Genee3.html











