
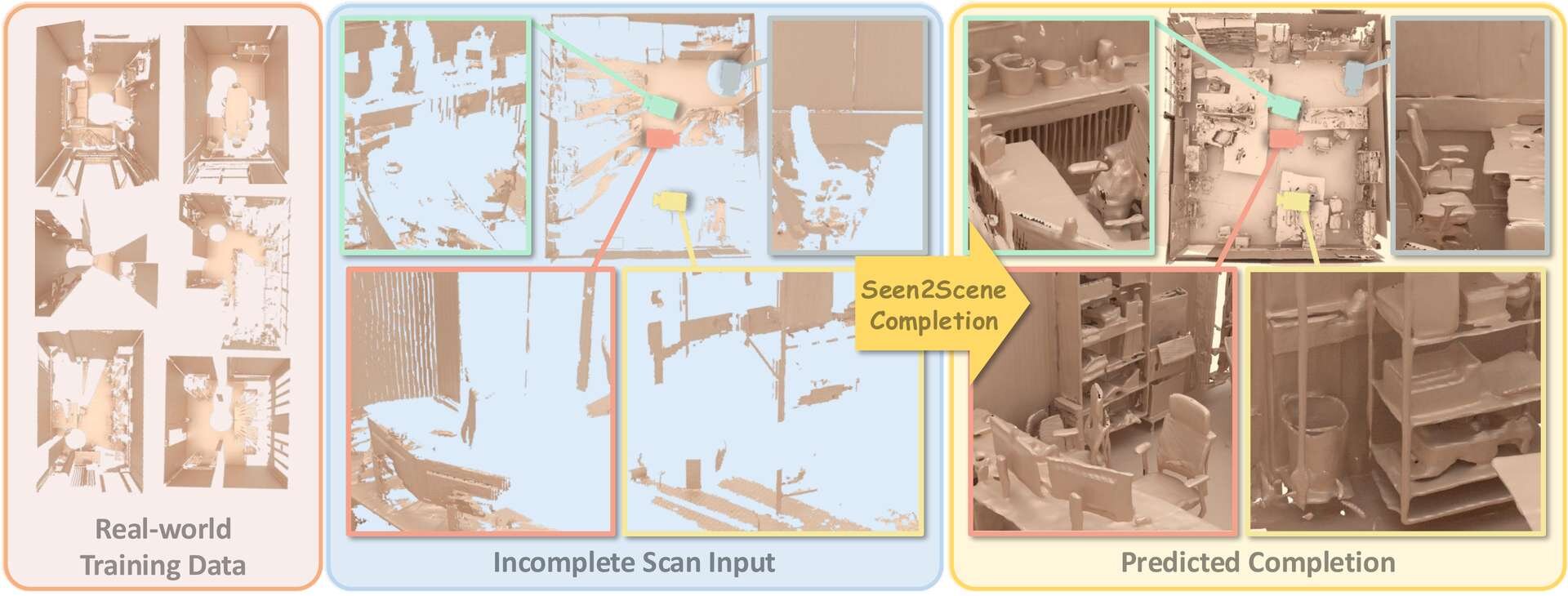
ミュンヘン工科大学とバージニア大学の研究チームは3月30日(月)、不完全な実世界の3Dスキャンデータから現実的な3Dシーンを補完・生成する技術「Seen2Scene」を発表した。現実の観測データから直接学習する新しいアプローチを採用し、複雑で雑然とした環境でも高精度なシーンの再構築を実現する。本技術は学術研究の成果であり、プロジェクトページにはソースコードへのリンクが用意されているが、執筆時点ではソースコードは公開されていない。
「Seen2Scene」は、単純なノイズのようなデータ分布を、現実の複雑なデータ分布へと滑らかに変換していくフローマッチング(Flow Matching)を用いた3Dシーン補完生成技術。
従来のシーン補完技術は、現実環境では家具の裏側やカメラの死角など、物理的な遮蔽によって取得できない「見えない領域」が必ず発生することから、形状に欠損のない完全な合成3Dデータを用いた学習に強く依存していた。
Seen2Sceneはこの課題解決のため、独自の「Visibility-Guided Flow Matching(可視性誘導型フロー・マッチング)」メカニズムを導入している。これは、現実のスキャンデータにおいてカメラから見えていない未知の領域を計算から意図的にマスクし、実際に観測できた部分のデータのみを信頼して形状の分布を学習する手法となる。これにより、ノイズが多く不完全な現実の観測データそのものを直接の学習ソースとして活用できるようになる。
3D空間のジオメトリ表現には、何もない空間の計算を省略し、物体が存在する領域付近のみを疎な格子状に分割して計算負荷を軽くするデータ構造である「Sparse Grids(スパース・グリッド)」にエンコードされた「Truncated Signed Distance Fields(TSDF、打ち切り符号付き距離場)」を採用。TSDFは、空間上の各点から最も近い物体の表面までの距離を数値化し、オブジェクトの内側と外側を符号(プラスマイナス)で区別することで、3Dモデルの輪郭を精密に表現する手法となる。
処理のながれとしては、まず部分的なスキャンのデータがMasked Sparse VAE(入力データを圧縮し、特徴を抽出する)に入力され、カメラから見えない未知の領域をマスクしながら潜在表現(Latent Representations)に変換される。その後、膨大なデータの中から関係性の深い重要な要素にのみ焦点を当て、複雑な文脈を理解するAIモデルであるスパース・トランスフォーマーを用いて、この潜在表現から空間全体の構造をモデリングする。
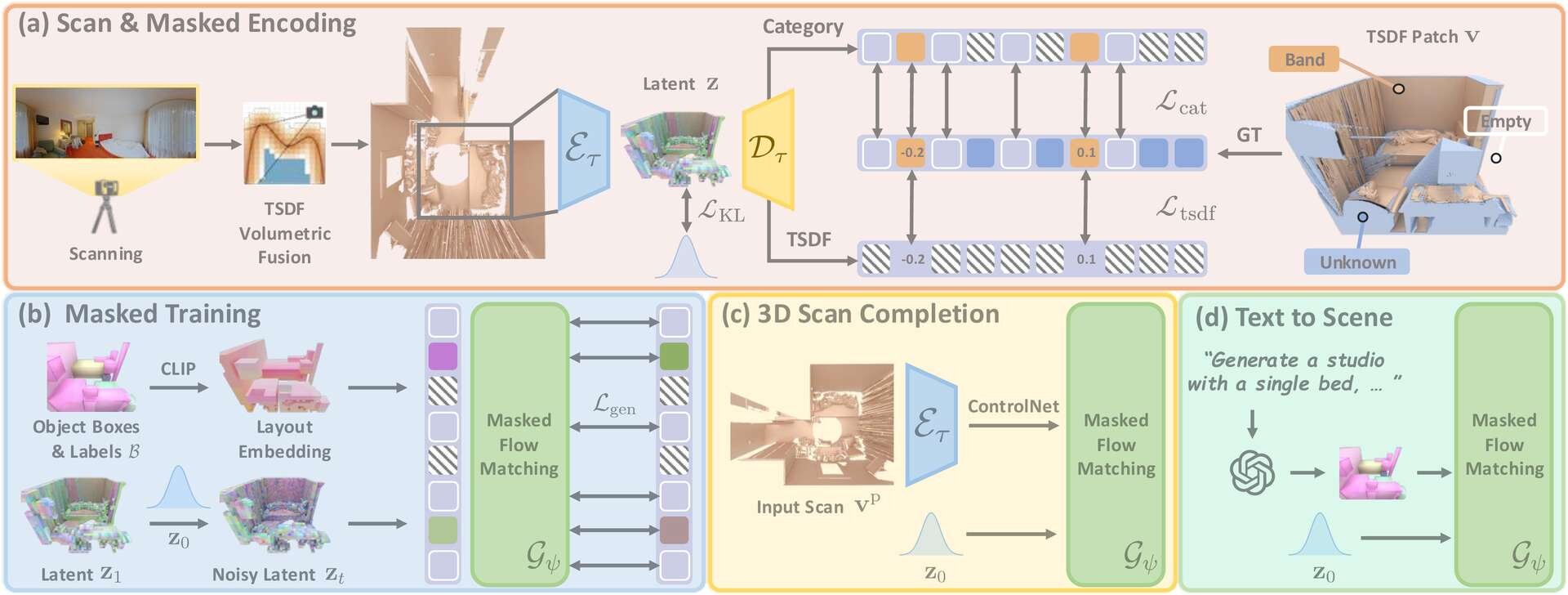
本手法は、単なる欠損部分の穴埋めにとどまらず、新しいシーンをゼロからつくり出す生成タスクにも強力な適応力を示す。生成の際のガイド役となる入力の条件付けには、空間内のどこに何があるかを示す3Dのバウンディングボックスが活用されている。部分的なスキャンデータを補完するタスクにおいては、ControlNetを介してスキャンデータをモデルに注入し、ファインチューニングを行うことで高精度な補完を実行している。
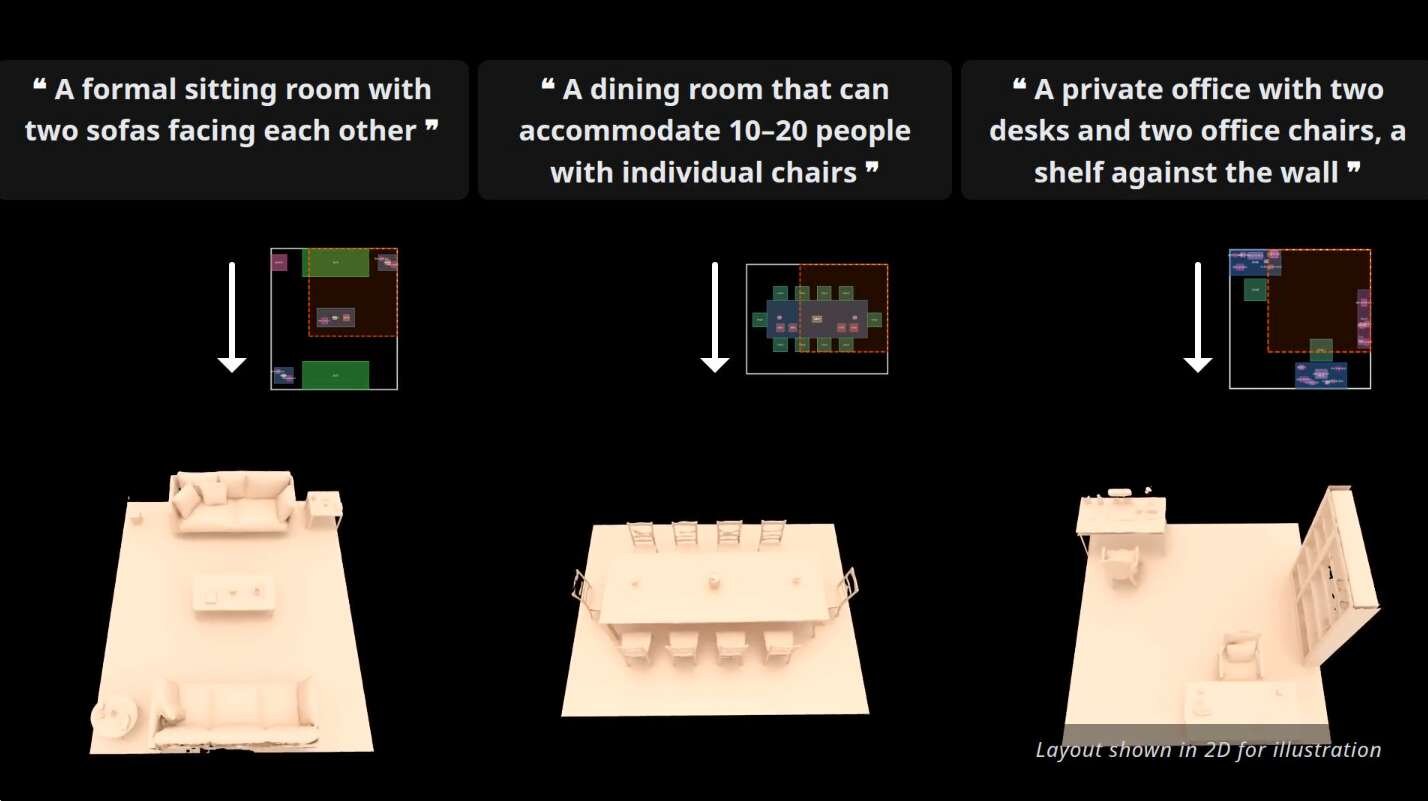
さらに、空間のスキャンデータが全く存在しない状態からでも、LLM(大規模言語モデル)を活用することで空間生成が可能。ユーザーが入力した自然言語のプロンプトをLLMが解釈して適切な3Dレイアウトに変換し、それを条件としてSeen2Sceneが空間全体を描画する。

■Seen2Scene: Completing Realistic 3D Scenes with Visibility-Guided Flow(プロジェクトページ)
https://quan-meng.github.io/projects/seen2scene/
■Seen2Scene: Completing Realistic 3D Scenes with Visibility-Guided Flow(GitHub)
https://github.com/quan-meng/seen2scene
CGWORLD関連情報
●自己回帰的3DGSシーン生成技術「GaussianGPT」発表! GPT形式のトランスフォーマーを用いて3D空間の構造と外観を段階的に生成

ミュンヘン工科大学の研究チームが、次トークン予測を用いた自己回帰型の3DGS(3D Gaussian Splatting)生成モデル「GaussianGPT」を発表。LLM(大規模言語モデル)と同様の学習手法を3D空間の構築に応用することで、シーンの欠損補完や自由度の高い拡張を可能にする。現在は学術的な研究段階となっており、ソースコードは近日公開予定。
https://cgworld.jp/flashnews/01-202604-GaussianGPT.html
●NVIDIAら、少数の画像から高速・高精度の3Dシーンを復元する「InstantSplat++」をオープンソースで公開! 2024年発表「InstantSplat」の拡張版

テキサス大学オースティン校、NVIDIA、厦門大学、テキサスA&M大学、ジョージア工科大学、スタンフォード大学、南カリフォルニア大学からなる共同研究チームが、数点の画像から数秒でフォトリアルな3Dシーンを構築できる技術「InstantSplat」の拡張版「InstantSplat++」をオープンソース(Apache-2.0ライセンス)でリリース。基盤となるInstantSplatの設計を維持しつつ、ごくわずかな視点の画像から大規模な空間を再構成できるように改良されている。
https://cgworld.jp/flashnews/01-202603-InstantSplat.html
●Metaら、3Dシーン生成AIモデル「ShapeR」リリース! ラフな日常撮影の動画シーケンスからロバストな3Dシーンを再構築

Meta Reality Labs Researchとサイモンフレーザー大学からなる研究チームが、ラフな撮影映像から高品質な3Dオブジェクトを生成する基盤モデル「ShapeR」を発表。ARグラスなどで撮影された、障害物や背景の写り込みが多い「日常的なキャプチャ(Casual Captures)」から、特定のオブジェクトを正確に3Dモデル化できるAI技術。ソースコードはGitHubで、学習済みモデルはHugging Faceで公開され、ライセンスは研究・非商用目的での利用に限定されたCC BY-NC 4.0が主に適用されている。
https://cgworld.jp/flashnews/01-202602-ShapeR.html













