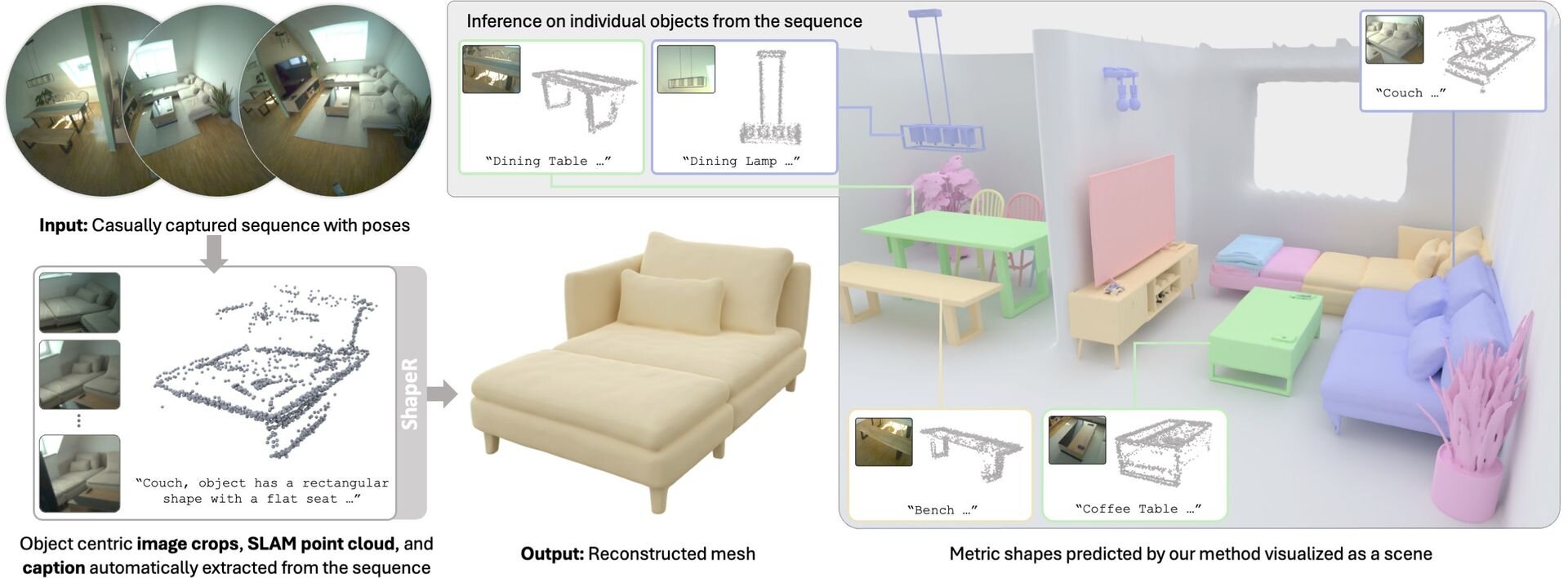
Meta Reality Labs Researchとサイモンフレーザー大学からなる研究チームは1月16日(金)、ラフな撮影映像から高品質な3Dオブジェクトを生成する基盤モデル「ShapeR」を発表した。ARグラスなどで撮影された、障害物や背景の写り込みが多い「日常的なキャプチャ(Casual Captures)」から、特定のオブジェクトを正確に3Dモデル化できるAI技術。ソースコードはGitHubで、学習済みモデルはHugging Faceで公開され、ライセンスは研究・非商用目的での利用に限定されたCC BY-NC 4.0が主に適用されている。
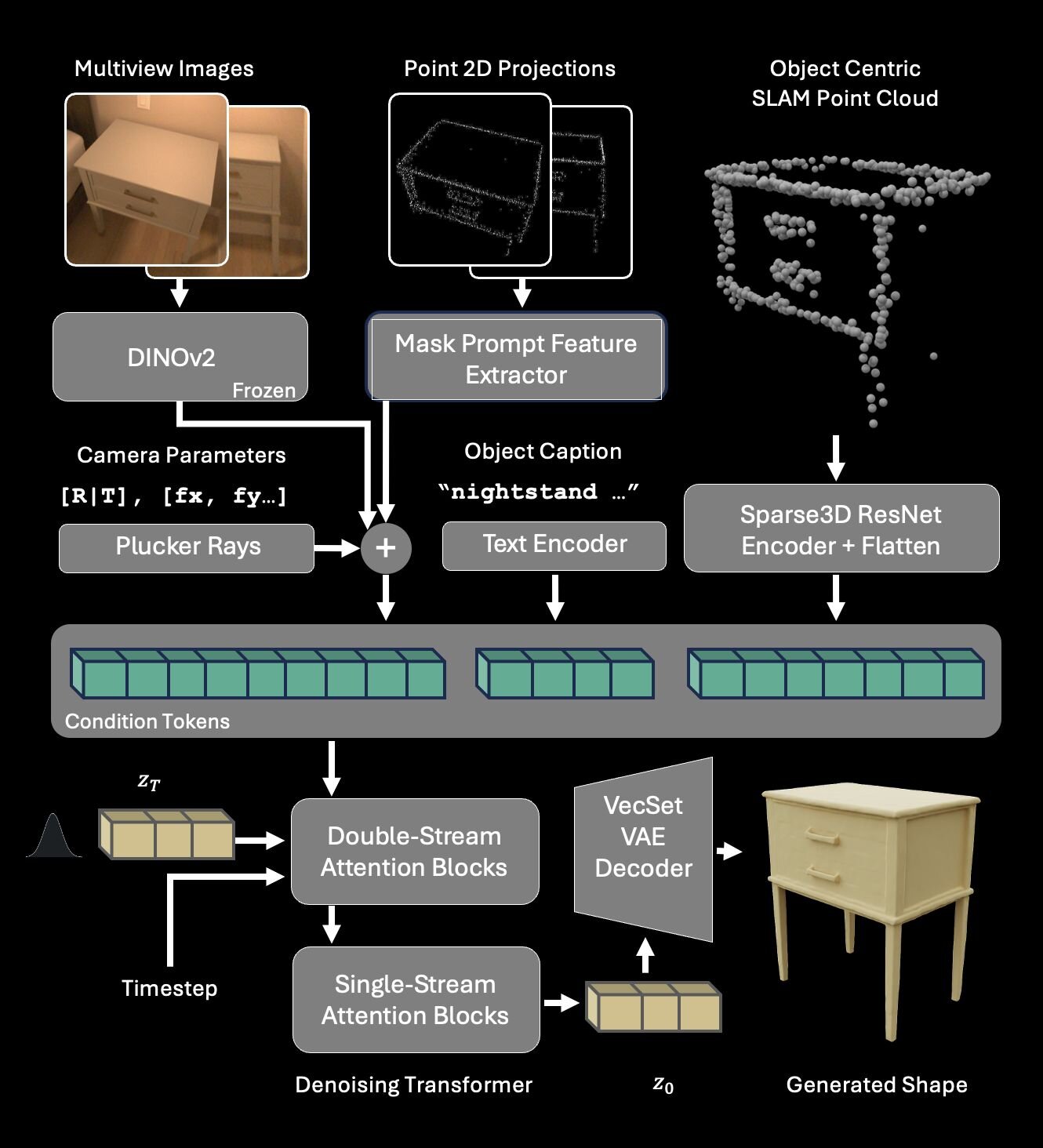
「ShapeR」は、生活空間で撮影された映像を3Dシーン再構成の入力として用いる際の課題となる、他の物体によるオクルージョンや、雑多な背景情報の処理を克服するために開発された「条件付き3D形状生成(Conditional 3D Shape Generation)」モデル。映像から得られるマルチモーダル(複数の異なる種類の)情報を組み合わせて3Dシーン再構成を処理する。
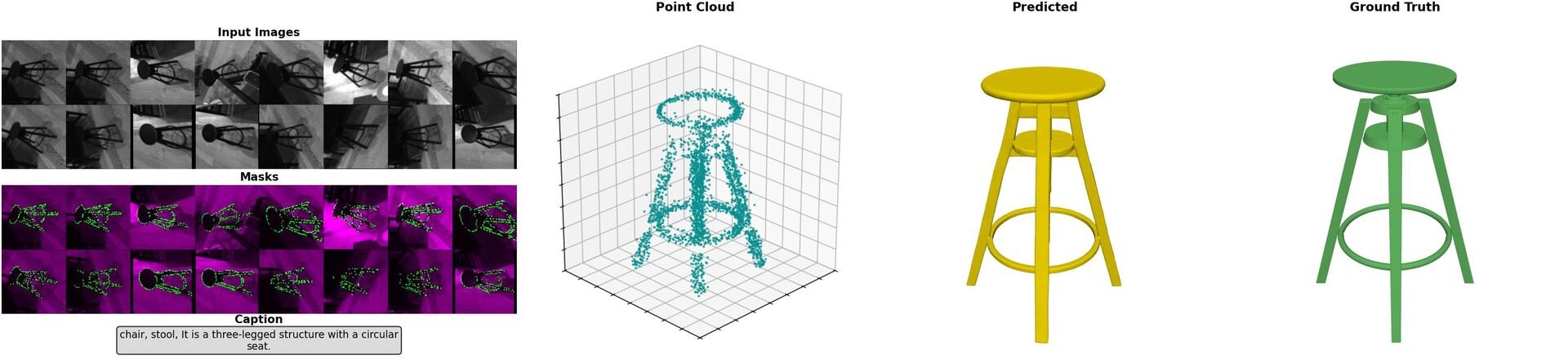
具体的には、自己位置推定と地図作成を同時に行う「SLAM(Simultaneous Localization and Mapping)」技術によって得られた点群データ(Sparse SLAM points)、視点の異なる複数の画像、およびAIが生成したテキストによるキャプションの3つを同時に入力とする。これらの情報を、データの変化を効率的に学習できる生成アルゴリズム、整流フロートランスフォーマー(Rectified Flow Transformer)で処理し、最終的に高品質な3Dメッシュとして出力する。
ShapeRは従来の最先端手法と比較して、3D形状の正確性の指標となる面取り距離(Chamfer distance)において、約2.7倍の精度向上を達成しているとのことだ。
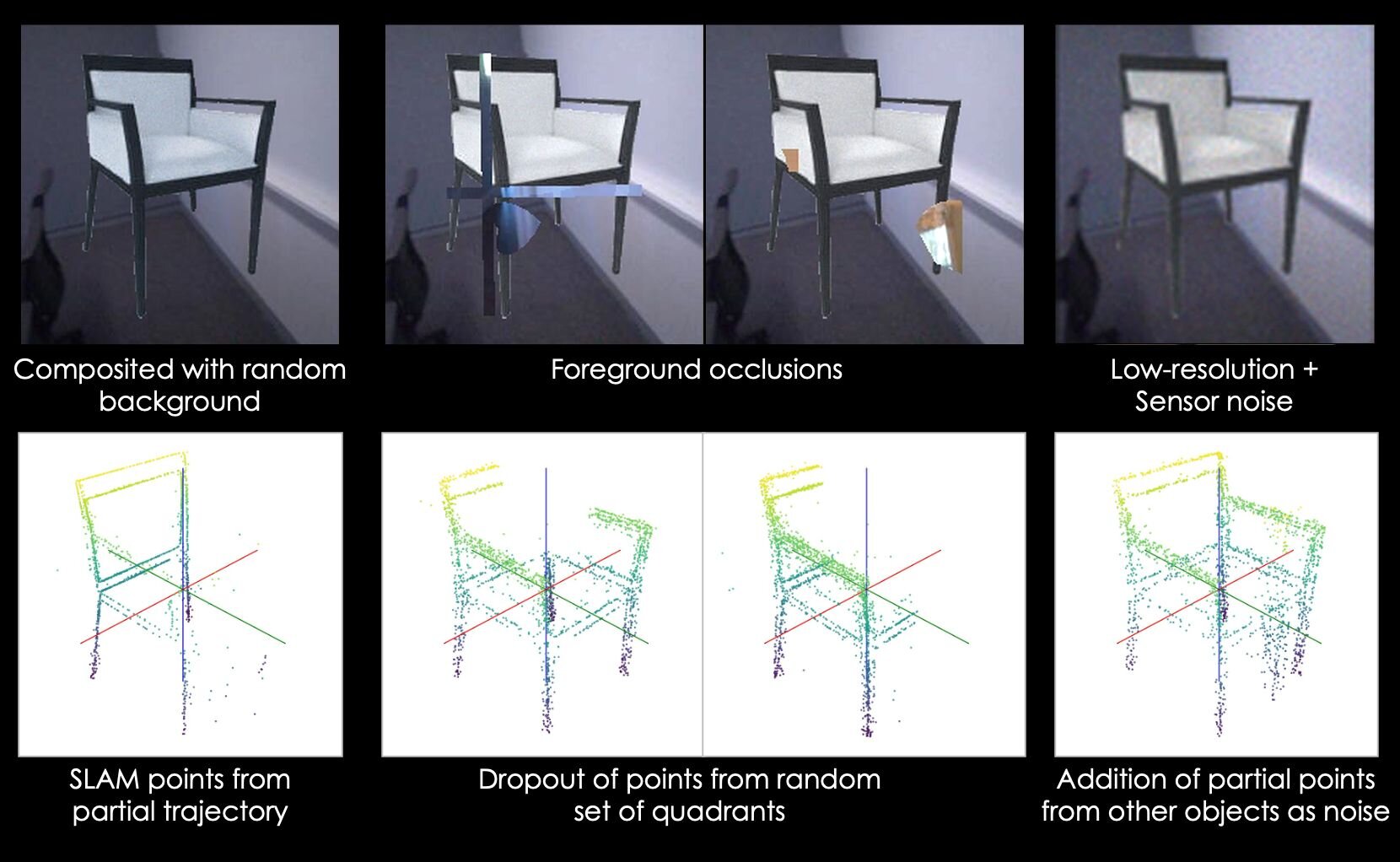
本研究の発表に伴い、Meta社は実環境での3D復元性能を測定するための新たなデータセット「ShapeR Evaluation Dataset」を公開した。このデータセットには、同社スマートグラス「Aria」を用いて日常的なシーンで撮影された、178種類のオブジェクトに関する詳細な3Dアノテーションが含まれている。



■ShapeR: Robust Conditional 3D Shape Generation from Casual Captures(プロジェクトページ)
https://facebookresearch.github.io/ShapeR/
■ShapeR: Robust Conditional 3D Shape Generation from Casual Captures(GitHub)
https://github.com/facebookresearch/ShapeR
■ShapeR(Hugging Face)
https://huggingface.co/facebook/ShapeR
CGWORLD関連情報
●3D生成AIモデル「Tencent HY 3D 3.1」リリース! HY 3D Studio 1.2とHY 3D Global上で利用可能

テンセントのHunyuanチームが3Dアセット生成モデル「Tencent HY 3D 3.1」をリリース。アップデートされた同社3Dアセット生成プラットフォーム「Tencent HY 3D Studio 1.2」および、グローバル向けワークスペース「Tencent HY 3D Global」とAPI経由で利用できる。HY 3D Globalでは期間限定で1日20回まで無料で生成を試すことができるほか、高度な機能を利用できる有料サブスクリプションも提供される。
https://cgworld.jp/flashnews/01-202602-TencentHY3D.html
●3D生成AIモデル「Meshy-6」リリース! ジオメトリ構造改善、ハードサーフェスのシャープなエッジ表現、ローポリモード、マルチカラー3Dプリント、自由なポーズのモデル生成など

Meshyが3D生成AIモデル「Meshy-6」を公式にリリース。本アップデートでは、生成モデルのジオメトリ構造が改善され、より直感的な編集や出力が可能となった。また、キャラクターなどの有機的な形状におけるアナトミー的正確性が向上したほか、メカニカルオブジェクトのハードサーフェスのエッジをよりシャープに表現できるようになった。また、21日にはImage-to-3Dの機能が拡張され、自由なポーズのモデル生成に対応している。公式ワークスペースおよびAPIを通じて提供される。
https://cgworld.jp/flashnews/01-202601-Meshy-6.html
●3D生成AIワークスペース「Tripo Studio 1.0」公式リリース! HDテクスチャ、ローポリ品質向上

Vastが3Dモデル生成AI「Tripo」の公式ワークスペース「Tripo Studio 1.0」を公式にリリース。新機能として「Smart Low Poly(スマート低ポリ)」と「HD Textures(HDテクスチャ)」が実装され、有料サブスクリプションユーザー向けに提供を開始(プロフェッショナルプランは月額1,800円〜)。また、トポロジーの改善や最大200%の高速化やよりスムーズなインタラクションなど、パフォーマンスも向上しているとのこと。
https://cgworld.jp/flashnews/01-202601-TripoStudio.html