AIの活用をはじめ、最先端の技術領域の研究開発と実用化をいち早く進めるCyberHuman Productionsの目に、NVIDIAが掲げる新たなプラットフォーム「NVIDIA Omniverse」はどう映るのか。音声データを基にリアルタイムでフェイシャルアニメーションを生成するAudio2FaceやOmniverse Createでの共同作業について、同社のアーティストとエンジニアが検証する。
<関連記事>
・「NVIDIA Omniverse」へようこそ!場所やツールを超え協業できる仮想プラットフォームの基本を解説
CyberHuman ProductionsのAI技術を活用したデジタルヒューマンへの取り組み
ーーデジタルヒューマンへの取り組みと、関連する事業内容を教えてください。
安黒:デジタルヒューマンを用いたコンテンツ制作の需要は確実に増加しており、当社としても人材・設備ともに大きく投資している段階です。事業においては、最先端の設備を備えたカムロ坂スタジオや、出張型3DCGスキャンカーである「THE AVATAR TRUCK(アバタートラック)」(※)などの高度なスキャン技術を軸として、アバター化した著名人やスポーツ選手を広告運用する「デジタルツインレーベル」を展開しています。
(※)THE AVATAR TRUCK:同社所有の高精細な移動式スキャンシステム。The ESPER LightCageにソニーのα7R IIIを60台搭載。https://www.cyberagent.co.jp/news/detail/id=23866

安黒篤史氏
株式会社サイバーエージェント デジタルツインレーベル 兼 株式会社CyberHuman Productions(旧AVATTA)/事業責任者
ーー制作過程において、AI技術を導入しているケースはありますか?
安黒:もともとサイバーエージェントには「AI Lab」という組織がありましたが、昨年秋頃にデジタルヒューマン領域での写実的な人体表現を効率的に実現するための研究専門組織である「デジタルヒューマン研究センター」を新設しました。
精密なデジタルヒューマンをたくさんのコストと時間をかけてアウトプットするというのは、われわれが実現したい未来ではありません。広告領域は映画1本を制作するのとは別の時間軸が流れています。このサイクルの速さに対応するために、AIを用いたアニメーションや動画生成の自動化、音声解析まで含めた、新しいパイプラインやワークフローの構築を行なっています。
柳島:写実的な3DCGモデル自体は、アプリケーション側の進化もあってかなり精密につくれるようになりました。でも、それを人間らしく動かすのはすごく難しいんです。表層的なアニメーション技術ではなく、もっと深くて微細な部分、人間の感性の機微のようなものを表現しなければいけないという課題の中で、この感性の部分をAIに補ってもらおうと考えています。

柳島秀行氏
株式会社サイバーエージェント デジタルツインレーベル 兼 株式会社CyberHuman Productions(旧AVATTA)/3Dアーティスト
ーーNVIDIAの最新ツールであるOmniverseを事前に検証していたということですが、その経緯を教えてください。また、ファーストインプレッションはいかがでしたか?
久家:従来のCGワークフローはウォーターフォール型でしたが、前の工程が終わらないと次の工程が動けないというのは非効率です。制作スピードをさらに上げるために、みんなが効率良く動けるための制作工程の並列化はマストでした。Omniverseは共同編集作業ができると聞いていたので、並列化の鍵になるだろうと思って検証を始めました。

久家隆宏氏
株式会社サイバーエージェント デジタルツインレーベル 兼 株式会社CyberHuman Productions(旧AVATTA)/ エンジニア
安黒:第一印象としては「非常に可能性を感じるツール」です。これまでにないワークフロー構築を模索する中で、われわれもケースに応じてOmniverseを使いこなしていく必要があるだろうと感じています。
Audio2FaceをはじめとしたNVIDIA Omniverseのデジタルヒューマン向けアプリ
ーーOmniverseで使える自動アニメーション機能「Audio2Face」について教えてください。
NVIDIA柿澤:Audio2Faceは音声ソースからフェイシャルアニメーションを自動生成するツールです。NVIDIA ディープラーニングAIテクノロジーがベースで、音声情報からの出力によってキャラクターメッシュの頂点が動き、リアルタイムでアニメーションを生成することが可能です。CES 2021で発表した通り、現在はEPIC Meta Humanとの連携も可能になっており、より現実的にプロジェクトで使用できる土台が整ってきました。
ーーAudio2Faceと共にGTC 2021で発表されたOmniverse Avatarも、同じテクノロジーが使われているのでしょうか。
柿澤:Omniverse Avatarは、NVIDIA Unified Compute Framework(UCF)というテクノロジーに基づいた専用の対話型AIアバターを構築するためのプラットフォームです。現在は技術デモとして、「Project Tokkio」という店頭接客の自動化だったり、NVIDIA代表のジェンスン・フアンを模した「Toy Jensen」という自動応答モデルをつくったりと急速に研究が進んでいる段階です。
柳島:今までの音声ガイドとタッチパネル操作を組み合わせた注文方式ではなく、アバターが目線を合わせて会話をしながら物事が進んでいくのは非常に面白いですね。老若男女問わず使えるインターフェイスだと感じます。コロナ禍ですとタッチパネルを触るのも躊躇するときはありますし、音声認識して対話を行うインタフェースの研究は時流にもマッチしていると思います。
柿澤:ほかにも「Project Maxine」という、同時翻訳における言語ごとにフェイシャルアニメーションを自動生成し、さらにカメラへの目線追従などを組み合わせてリアルに喋っているように見せるアバター開発なども行なっています。本来、同時通訳はどうやってもリップシンクが合わないのですが、音声をベースにフェイシャルを生成する方法であれば複数言語に渡って完璧な顔の動きをつくることができます。
柳島:こちらはビデオによる多言語ミーティングで実際に使ってみたいですね。言語の壁を乗り越えて、自分の顔と言葉であるかのように意見を伝え合えるのは素晴らしいと思います。これは3Dモデルがベースになっていると思うので、たとえ寝起きの状態であってもベストなステータスの自分のアバターが分身として対応してくれるということですよね? リアルなアバターが自分の代替をしてくれるのは助かります。
久家:さすがNVIDIAと言いますか、怖いくらいの技術力だなと思います。一方において、少しリアルな話をすると、機能単体で見たときに強力でもパイプラインに統合するときに工数がかかってしまっては意味がありません。ワークフローのどの位置に入れ込むのがいいのかを熟考しないと完全に恩恵を享受できないと思うので、そこの見極めが重要になると考えています。
柿澤:これらの機能はSDKとして提供していく予定です。ベースの技術はNVIDIA、どう組み込むかはソリューションベンダーにお任せする方向性となっています。例えば、現在ライブラリとして提供しているDeep Learning Super Sampling(DLSS)というAIベースのデノイザーは、すでに各アプリケーションベンダーに活用していただいています。今後はプロセスに応じた使い方ができるような提供・サポートをさらに拡充していくつもりです。
柳島:これらの技術は、もちろんOmniverseにも関係があることですよね? 例えばOmniverseに入っているレンダラでもDLSSは活用できますか?
柿澤:複数のデノイザーと共にDLSSも使用可能です。レンダラ自体の選択肢も増えています。Omniverseはそのものがプラットフォームですので、その中にAudio2FaceやOmniverse Avatarなどの機能が入ってくるのはもちろんこと、他のパイプラインに技術単体を組み込めるようSDKとしても提供します。これらのテクノロジーは両方の用途で使えるということです。
フォトスキャンを用いた3DCGモデル制作とDCCツールでの編集、音声データの最適化
ーーここからは、実際にAudio2Faceを検証していただいた内容についてお聞きします。まずは検証内容について教えてください。
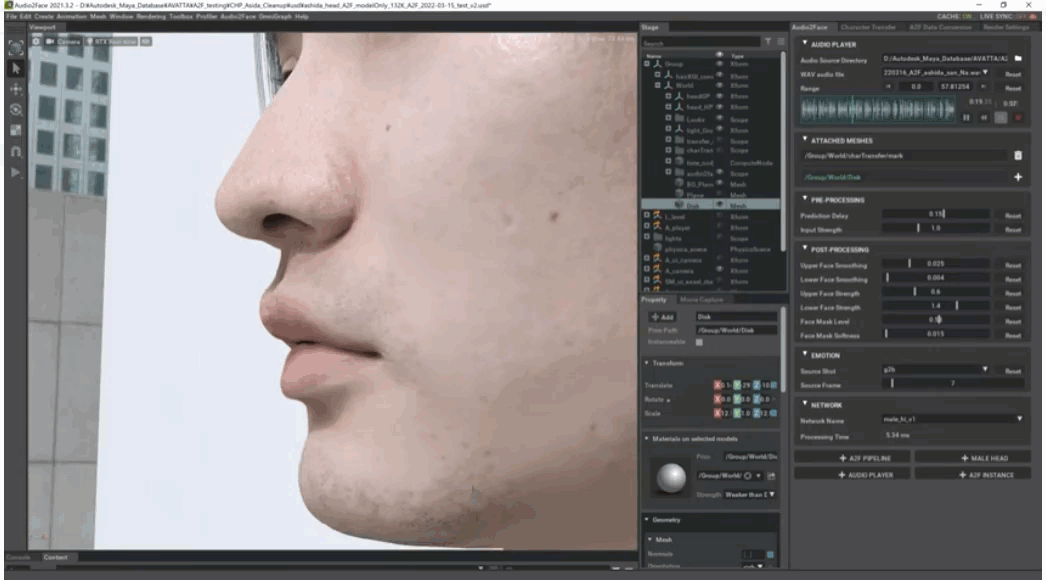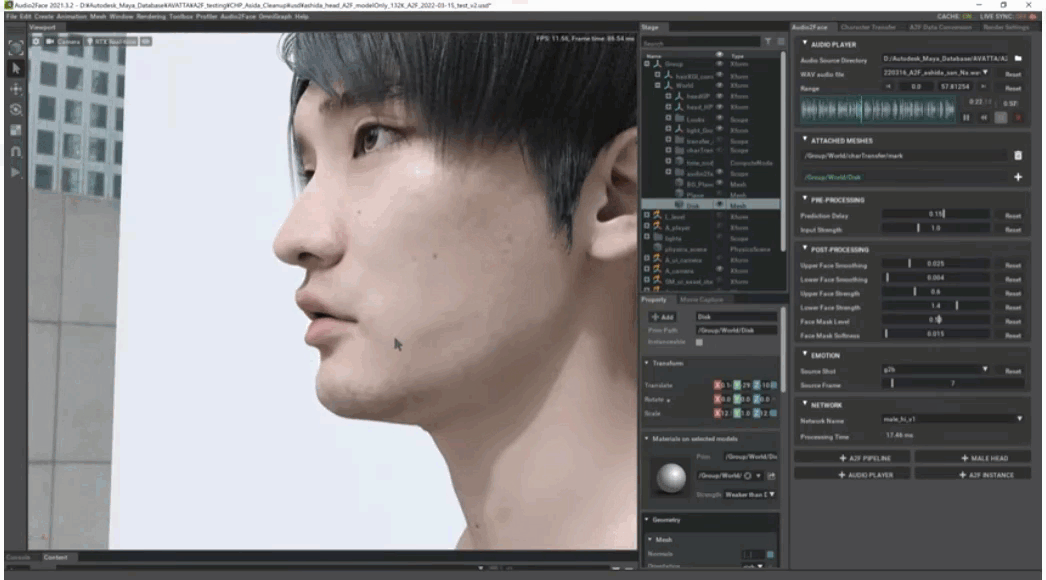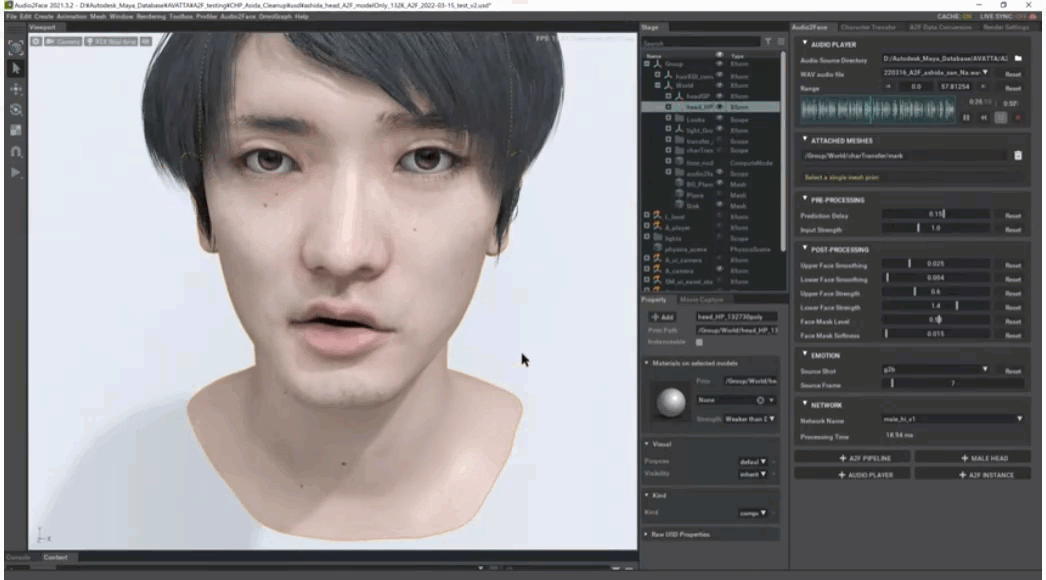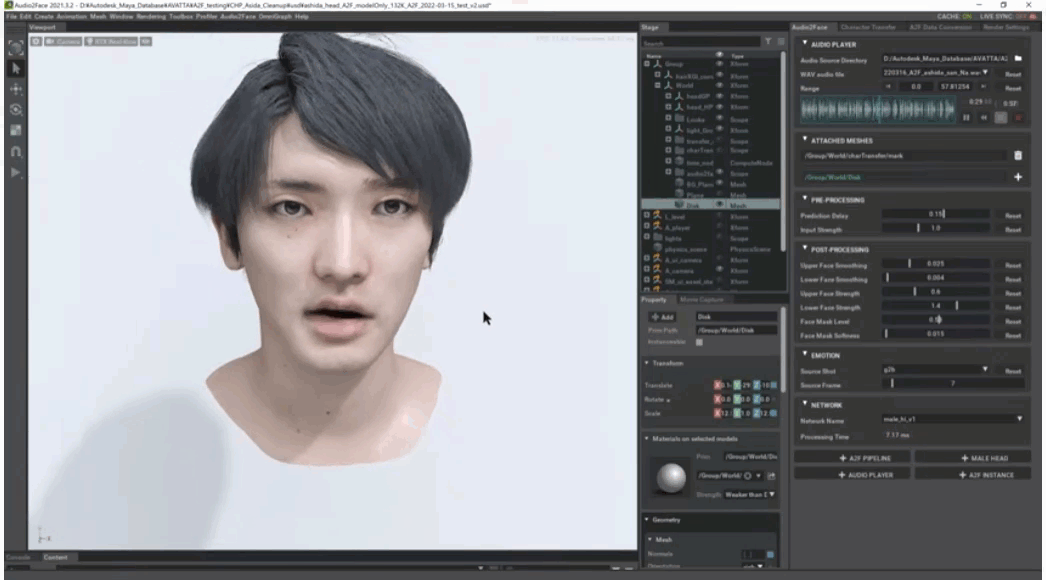
柳島:AVATAR TRUCKで撮影した頭部3DモデルをZBrushでクリーニングし、Mayaで調整した上でAudio2Faceにもっていき、特徴点を設定した上でリップシンクを実験しました。
まずはモデルの説明ですが、今回はリトポを行なった低解像度モデルと、ZBrushのDecimation Masterを利用してディテールを保ったままポリゴンリダクションをした中解像度・高解像度モデルの3種類を利用しています。
高解像度モデルは顔だけで約13万ポリゴン、髪の毛が約440万ポリゴンという非常に重いデータになっています。今回はこうした重いファイルをリアルタイムで処理できるか、そして3通りの解像度を試すことで「いかなるワークフローでも使用に耐えうるのか」を検証していきました。ちなみに、頭部は当社取締役・芦田(直毅氏)のスキャンデータになっています。今回は音声でも協力をしてもらいました。

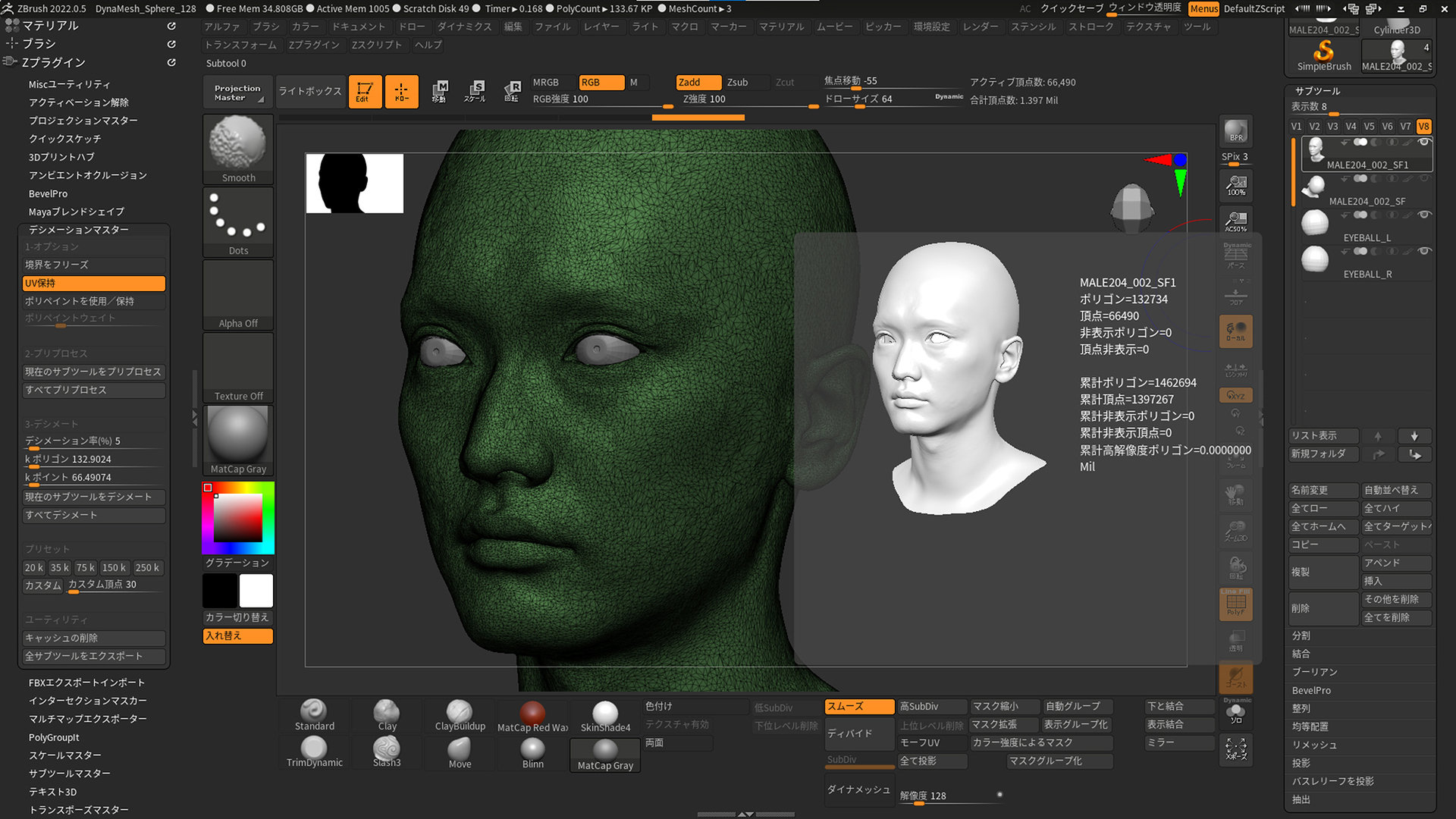
ーーDecimation Masterを利用して異なる解像度のモデルを用意した理由について、詳しく教えてください。
柳島:リトポ後のメッシュであれば正確なフェイシャルがつくれるだろうとは予測できますが、そうでないメッシュの挙動も確認したかったんです。例えば、スカルプトで作業している途中に「試しにフェイシャルアニメーションを付けてみよう」と思い立って、テスト結果が確からしいものであれば、それをふまえてさらにモデル側のブラッシュアップができますよね。また、スキャンデータを適度なクリーニングの上で、特にリトポせずにリダクションしただけの不規則なメッシュからでも正確なフェイシャルがつくれるとなれば、今後はスキャンデータの利用用途が広がることにつながります。このあたりの使用感や制御も確認しておきたいと考えました。
ーーMayaではどういった作業を行いましたか?
柳島:クリーニング済みの頭部のデータに対して汎用的な頭部のベースメッシュをラップし、眼球や歯、眉毛、まつ毛、髪の毛などのパーツを追加していきました。髪の毛はXGenで作成しましたが、OmniverseにはUnreal EngineでいうHair Groom(MayaなどのDCCツールで作成したヘアをAlembic形式でインポートし、エンジン側でシミュレーションを行うもの)と同等の機能がないため、XGenからInteractive Groomに変換し、その後ポリゴンへコンバートを行いました。
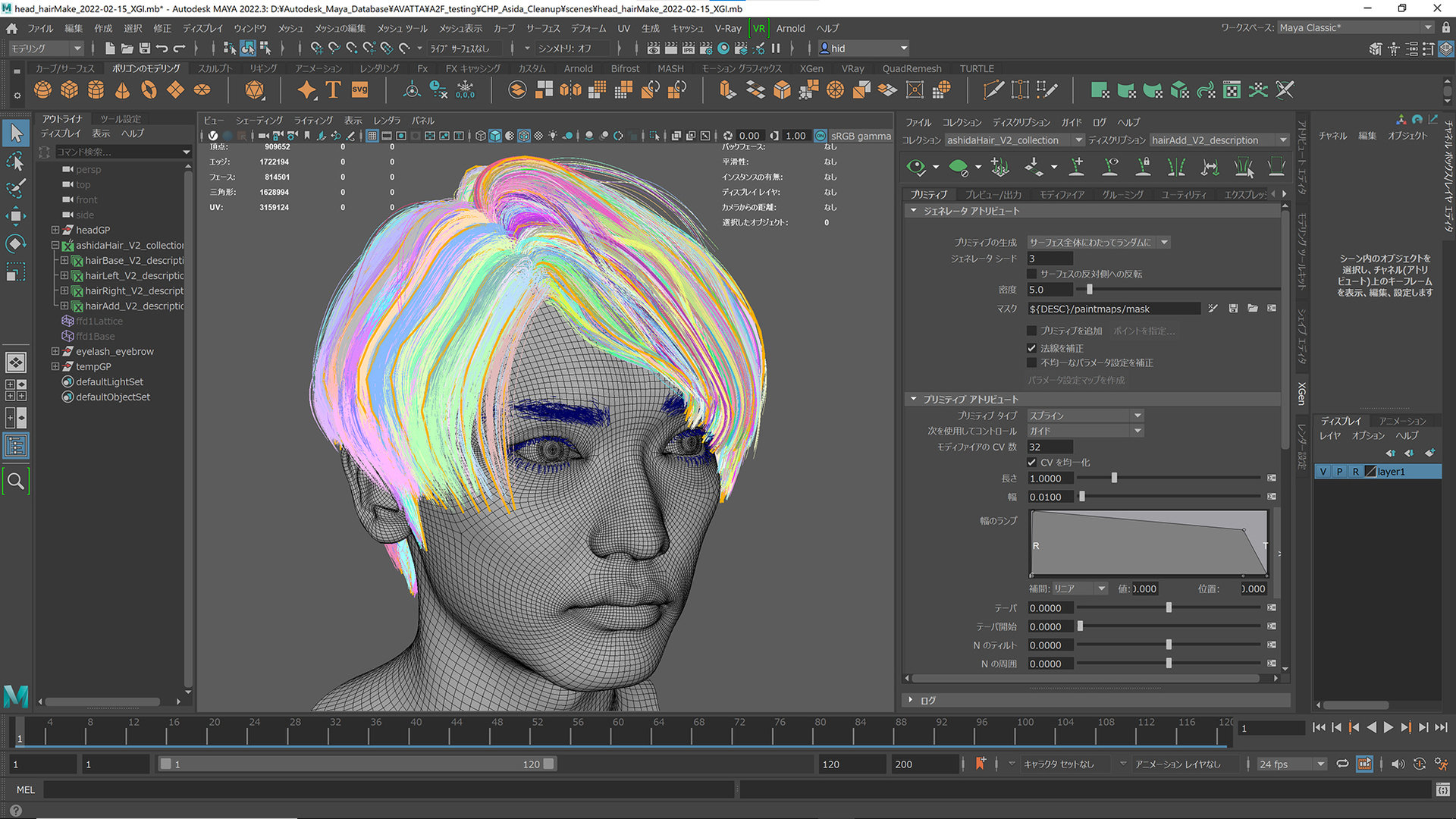
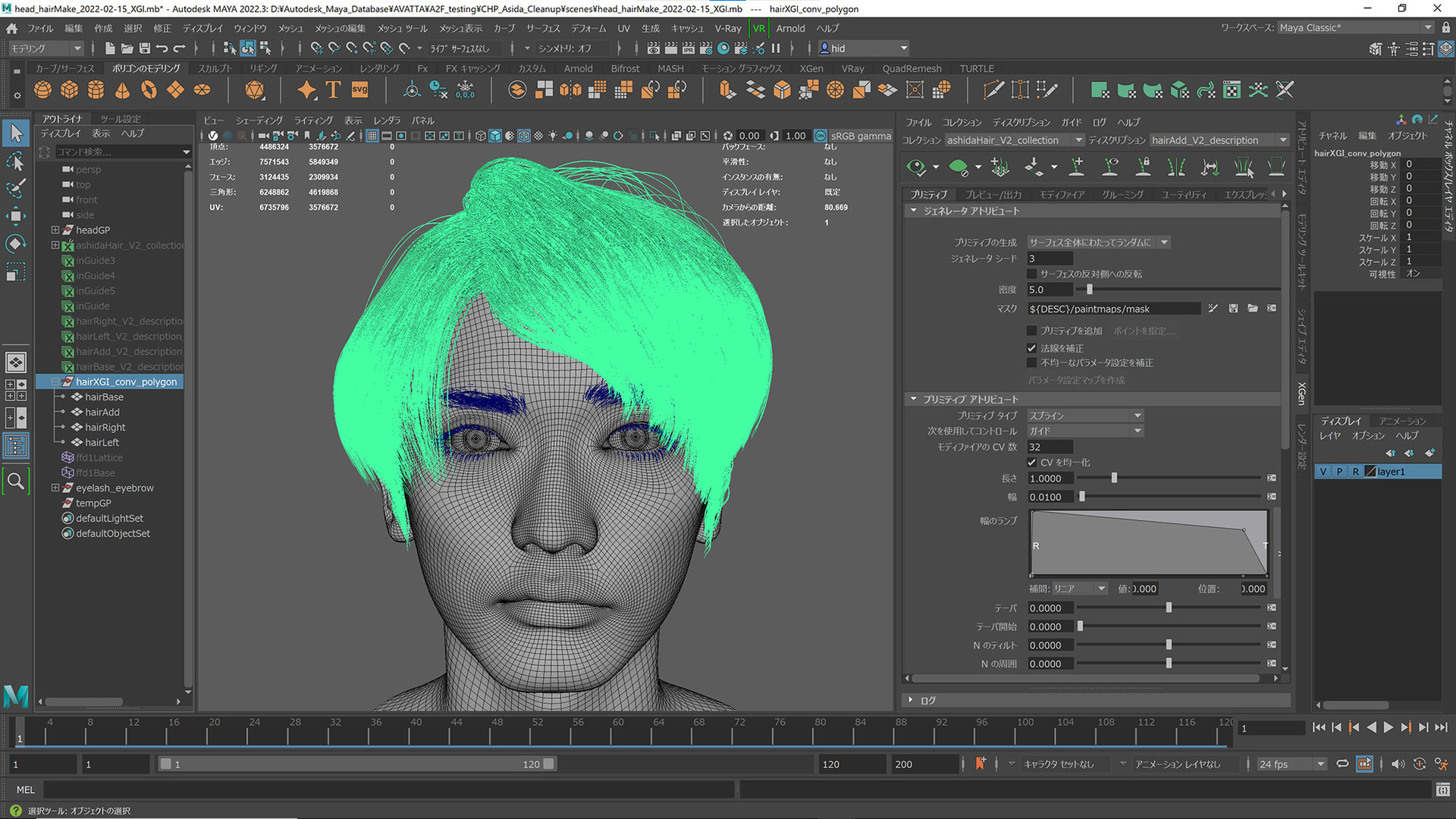
ーーAudio2Faceでの自動フェイシャルアニメーションに用いた音声データについても、簡単にご説明いただけますか?
柳島:日本語音声にはまだ対応していないので、芦田には英語のスピーチ収録を依頼しました。その後、Premiere Proで音声をノーマライズしています。リップシンクの追従性を求めるためには音質も重要で、小声ではっきりしない発声は検知が難しくなりますので、ゲインを持ち上げています。
-

リップシンクに活用する音声データは、収録データをそのまま使うのではなくPremiere Proでノーマライズが行われている。 左:ノーマライズ前、右:ノーマライズ後 -

Audio2Faceのラッピング作業は「非常に高速」
ーーこれでモデルデータと音声データが揃いました。いよいよAudio2Face側の作業になると思いますが、まずは作業手順について教えてください。
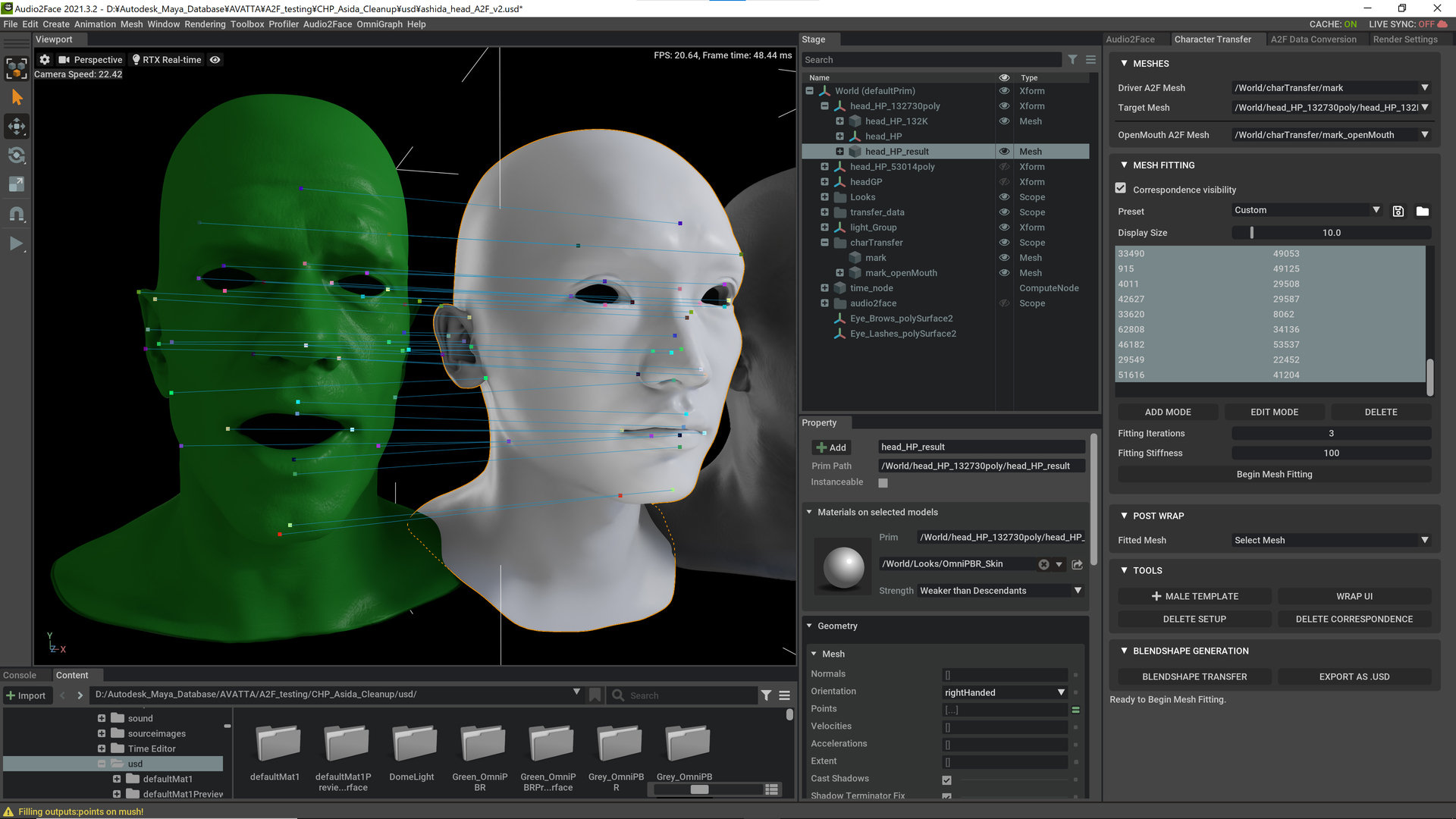
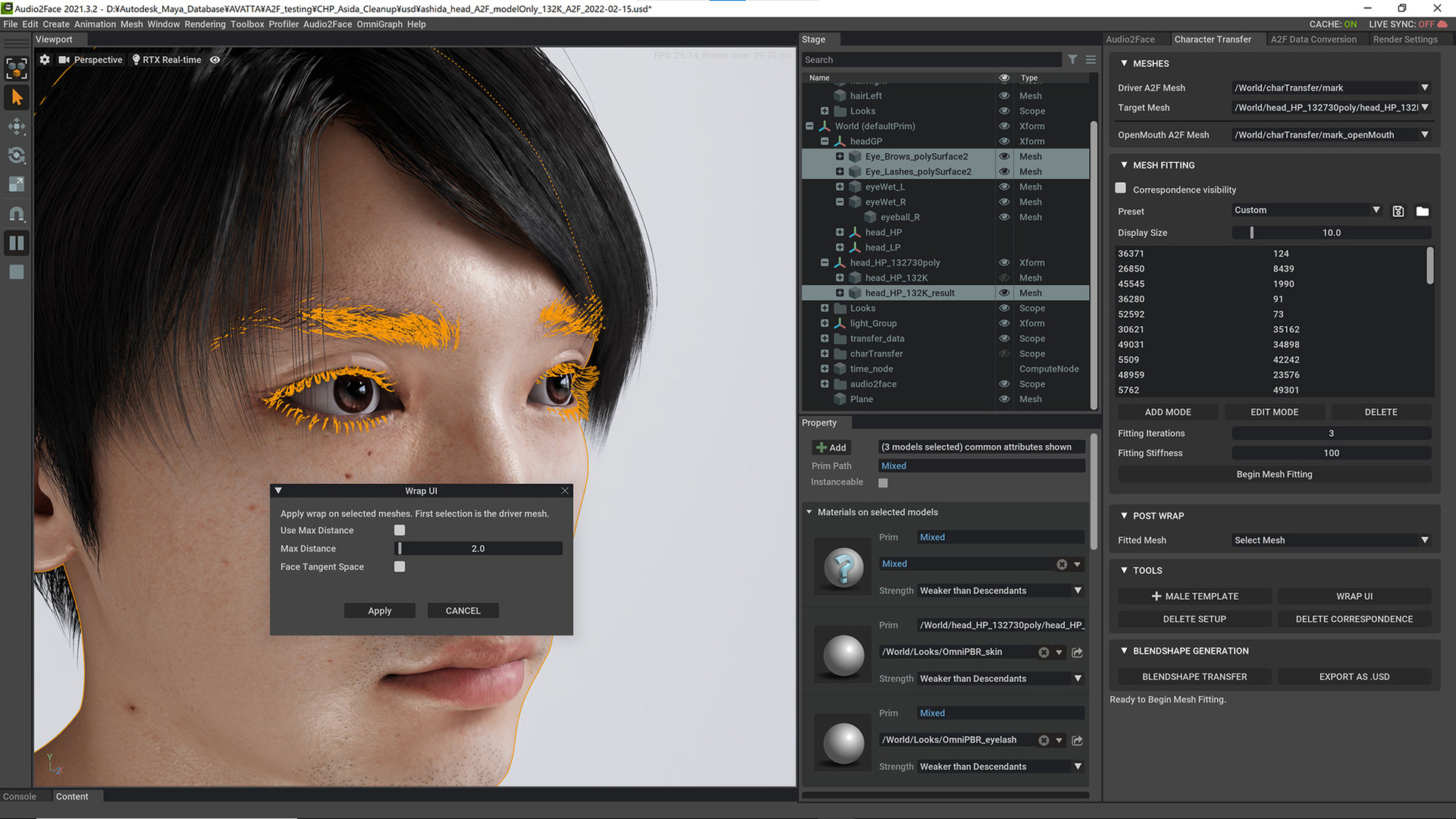
柳島:Audio2Faceはあらかじめ学習されたモデルに自作のモデルをラッピングすることでフェイシャルを転送するというしくみですが、使い方自体はかなり簡単でした。特徴点を指定するだけでフィットするので、ベースメッシュの定着であまり悩む部分はありません。
詳しく話をすると、まずはUSDでモデルを取り込んで、Audio2Faceタブから+MALE HEADで学習済みの男性頭部を呼び出します。その後、MESH FITTINGで特徴点をマーキングしていきます。高解像度モデルだと少し特徴点を増やす必要はありましたが、そこまで大変ではありませんでした。
気になるのはラッピングの速度ですが、13万ポリゴンの頭部モデルであっても42秒前後。GeForce RTX 3090搭載マシンで作業をしていますが、類するスペックのGPUであれば1分前後で完結するのではないかと思います。この時点でプリセットに用意されているテスト用の音声を再生し、フェイシャルアニメーションができていることが確認できます。

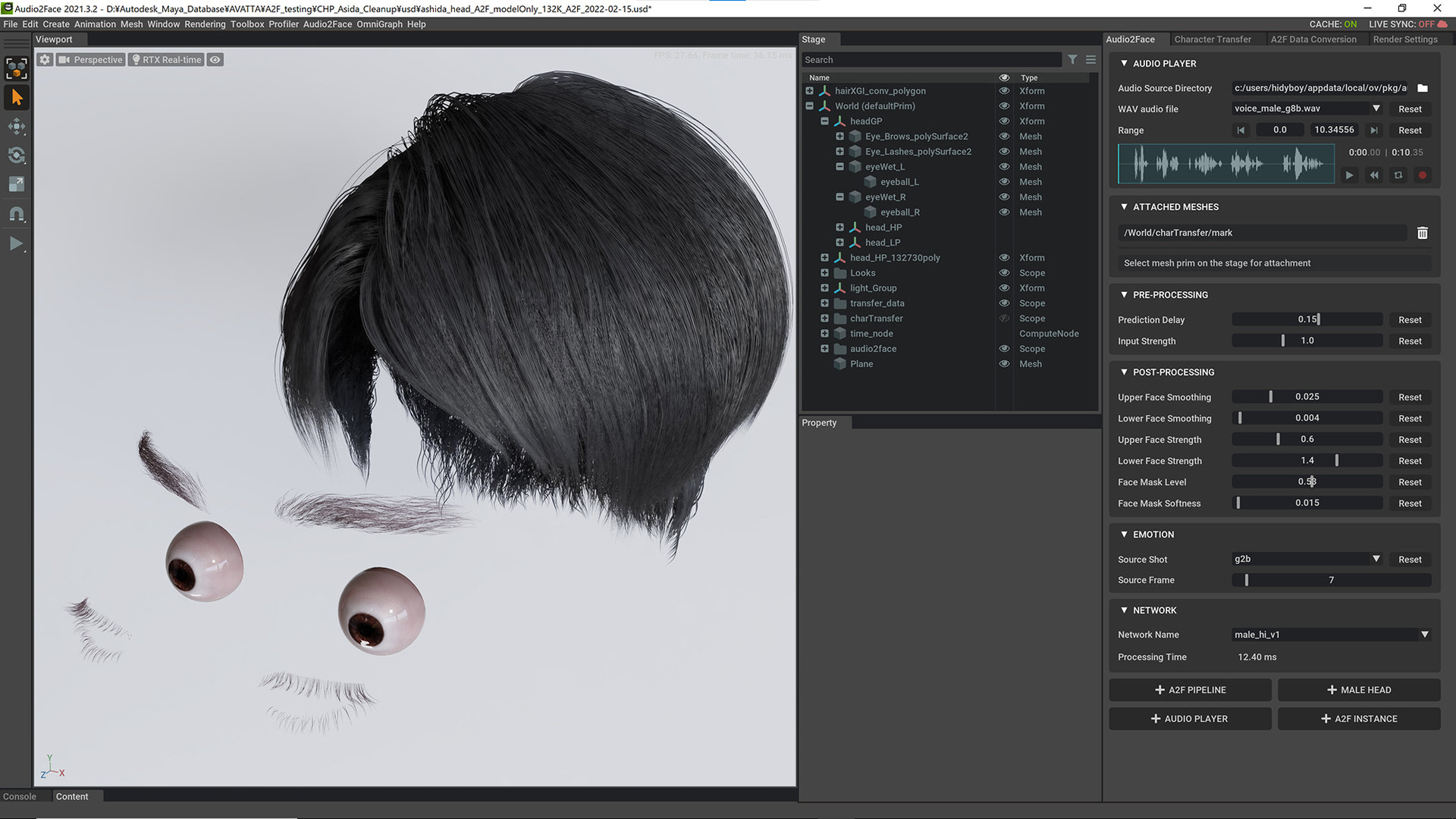
左からOpenMouth A2F Mesh、自作モデル、Drive A2F Mesh
久家:少し補足すると、Omniverseはドキュメンテーションがかなり充実しています。ランチャーのインストールさえ終われば、そこから全ての機能が入るようなイメージです。ランチャーをインストールして、ランチャーの中でAudio2Faceをインストールして、Createが使いたいならそれを追加して、といったかたちで、ソフトウェアの導入自体もかなりシンプルです。
柳島:その後のセットアップも結構やりやすくて。今回使用したパーツは眼球が11,056ポリゴン、眉毛が211,376ポリゴン、眉毛が1,358,214ポリゴンです。頭部全体で1,580,646ポリゴン、髪の毛を含めると620万ポリゴン近いモデルとなりますし、テクスチャも8K(8,192×8,192)が4枚に加え、眼球用に4K(4,096×4,096)も使っています。さらに眉毛とまつ毛にはアルファによる透過処理も加えています。ということでなかなかの重さではあると思いますが、これらのパーツをOmniverseに読み込んで、頭部スキンモデルのマテリアル設定などを行なっていても、まったくパフォーマンス的に問題ありませんでした。眉毛やまつ毛はフェイシャルに追従する必要がありますが、Wrap UIを使うことで簡単に頭部モデルにバインドできます。この状態で本人の音声に差し替え、最後の仕上げとして全体的なマテリアルを調整した上でライトにDomeLight(HDRI)とRectLightを3灯セットアップして画づくりを行いました。
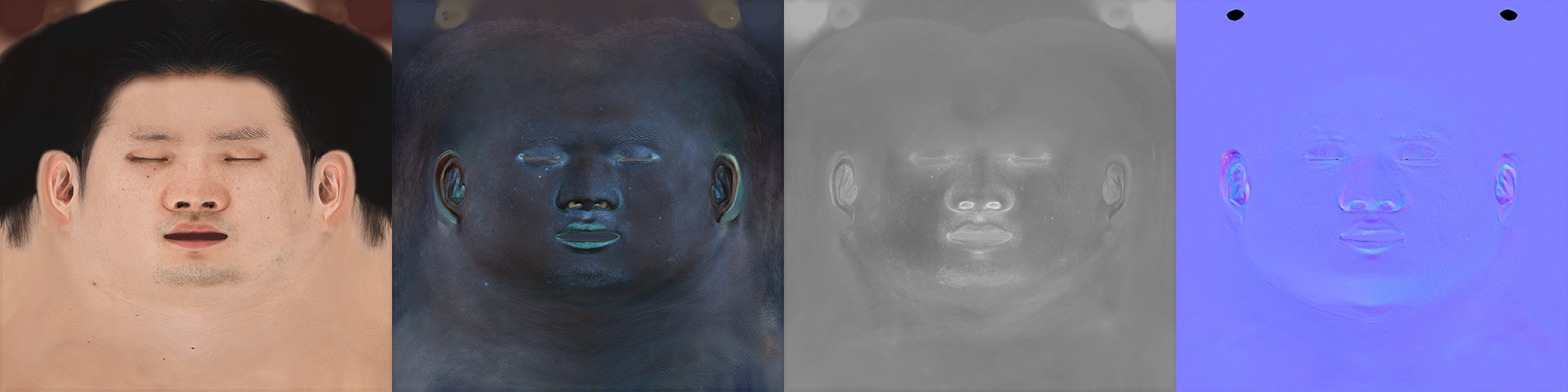
他のリップシンクとは一線を画するクオリティ
ーーかなりリッチな頭部モデルだと思いますが、問題なく動いているのでしょうか? また、肝心のリップシンクの品質ですが、こちらはどのように評価されますか?
柳島:データ自体は重いですが、リアルタイムで40fps出ていたので驚きました。品質についても、今まであったようなリップシンクと比べると、ひとつ上のレベルではないでしょうか。ただ単純にデータを入れるだけでここまでのクオリティが出せるのは非常にメリットが大きいと思います。芦田が英語で喋っているときのリップを詳しくは知らないのですが、恐らくこのように話すのではないかと。
現状のベータ版においてはリアルタイムで処理していものを、A2Fでスクリーンショットで連番保存するかスクリーンレコードアプリなどで保存することしかできないのは少し残念です。リアルタイムでの処理表示ではフレームレートが出ているのに、動画として記録するとなるとフレームレートが現時点では出ないのは少し歯がゆいものがあります。
久家:まだ日本語に正式対応していない状況ということを差し引いても、フレーズによっては極めて自然な口の動きが生成できていると感じました。例えば、カタカナ語や、マ行のリップはとても正確だと思います。ちなみに、実験として頭部モデルだけでなく全身入ったモデルをAudio2Faceにインポートしてみましたが、きちんと特徴点を入力すれば顔だけしっかり動かすことができました。

ーーリップシンクの品質について、言語によってAIパターンが変えられるなどの機能はありますか?
柿澤:現在は「Digital Mark」というAIパターンのみ選択可能ですが、今後学習が進めば他のパターンもセクレションできるようになるでしょう。そうなれば、より日本語らしい口の動きが実現できるかも知れません。この項目は今後増えるかもしれない、とお考えください。まずはヨーロッパ系から研究を進めています。
ーーちなみに、ポストプロセスでフェイシャルアニメーションのチューニングを行うなど、その後の処理についても何か試されましたか?
柳島:データが完成した後に、いろいろと調整機能を試してみました。Audio2Faceタブでは様々な調整パラメータがあって、「POST-PROCESING」ではフェイシャルの動き自体を調整でき、「EMOTION」ではニューラルパターンを変更することで感情を付加することができています。人の手でリアルな感情を付加するのは、結構難しいんです。人間らしさというのは、本人よりも他者が俯瞰でみた方がその人自身の特徴がわかりやすいように、AIに判断してもらったほうが良い領域なのかもしれませんね。
ーーOmniverseはUSD形式でモデルのインポートを行いますが、データ形式についてもスムーズに移行できたのでしょうか?
柳島:OmniverseはUSD形式を用いることになりますが、USD形式自体はMaya 2022でも、ZBrushでも普通に書き出すことが可能です(ZBrushの場合はZpluginの利用が必要)。Maya 2019などのバージョンでも、NVIDIA Omniverse LauncherからMaya Connectorをダウンロードすれば、USD形式での出力ができるようになります。本来であればこのMaya Connectorを使って、Omniverseの真骨頂でもあるオープンプラットフォームで作業を行うべきだったかも知れませんが、今回は「Audio2Faceが簡単に使える」ということを皆さんにも知っていただくためにローカルでカジュアルに使用してみました。
久家:エンジニア職はもちろんのこと、アート職であっても、恐らく学生であったとしても、インストールをして動かすところまではスムーズにいけるはずです。それくらいシンプルで使いやすいと思ってください。
柳島:ただ単純にAudio2Faceを試すだけなら、サーバを建てる必要もないですし、スタンドアローンですぐに使い始めることができます。β版は無償で使えるので、気になったらすぐローカルでテストしてみるというのがオススメです。
柿澤:今の段階では、RTX A4000とGeForce RTX 3070をボトムとして、それ以上のスペックのGPUを推奨としています。スペック要求を満たすのであれば、別途ドライバをインストールすればすぐに試せる状態になっています。
柳島:インポートの話題があったので、エクスポートについても説明しておきます。プリレンダーで活用するためにはAudio2Faceで生成したアニメーションデータをMayaに戻す必要がありますが、Audio2FaceでつくったアニメーションはUSD CacheもしくはMaya Cacheで書き出すことが可能ですし、エクスポート時にfps設定もできます。 " .mc " と " .xml " の2ファイル構成で書き出され、Maya側でインポートのさいオリジナルモデル(今回は頭部)を選択し .xml の方を選択し読み込むことでキャッシュ結果を反映させることが可能となります

ーー最後に、この検証を終えて、率直な感想をお聞かせください。
柳島:かなり重いポリゴンメッシュでも簡単に扱えましたし、操作も悩む部分はほとんどありませんでした。AIテクノロジーを使った画期的な機能だと思いましたので、まずはお手持ちのモデルで検証していただくのが良いと思います。
TEXT_神山大輝(NINE GATES STUDIO)
EDIT_藤井紀明(CGWORLD)
INTERVIEW_池田大樹(CGWORLD)












