
中国・アリババグループの研究開発チームTongyi Labは12月16日(火)、テキスト・画像・音声入力を統合し、リアルな画像と動画を生成するマルチモーダル生成AIモデル「Wan2.6」をリリースした。特定のリファレンスキャラクターを異なるシーンへ一貫性を保ったまま配役する「Starring」機能、単純な指示から複数のカットで構成される物語を自動構築する「マルチショット・ナラティブ」機能、ネイティブレベルでのA/V同期による自然な対話シーン、1080p、緻密なライティング制御などの特徴を備える。Wan2.6は公式プラットフォームやサードパーティ製プラットフォーム、APIから利用可能。
Introducing Wan2.6 - A native multimodal model that turns your ideas into breathtaking videos and images!
・Starring: Cast characters from reference videos into new scenes. Support human or human-like figures, enabling complex multi-person and human-object interactions with appearance and voice consistency.
・Intelligent Multi-shot Narrative: Turn simple prompts into auto-storyboarded, multi-shot videos. Maintain visual consistency and upgrade storytelling from single shots to rich narratives.
・Native A/V Sync: Generate multi-speaker dialogue with natural lip-sync and studio-quality audio. It doesn’t just look real - it sounds real.
・Cinematic Quality: 15s 1080p HD generation with comprehensive upgrades to instruction adherence, motion physics, and aesthetic control.
・Advanced Image Synthesis and Editing: Deliver cinematic photorealism with precise control over lens and lighting. Support multi-image referencing for commercial-grade consistency and faithful aesthetic transfer.
・Storytelling with Structure: Generate interleaved texts and images powered by real-world knowledge and reasoning capabilities, enabling hierarchical and structured visual narratives.Wan2.6 発表:あなたのアイデアを、息を呑むような映像と画像へ変えるネイティブ・マルチモーダルモデル
・Starring機能: 参照動画からキャラクターを抽出し、新しいシーンへと登場させることが可能です。人間や人型キャラクターに対応しており、外見や音声の一貫性を保ちながら、複雑な多人数描写や人間と物体の相互作用を自然に描き出します。
・インテリジェントマルチショットナラティブ: 単純なプロンプトから、自動的に絵コンテ化(ストーリーボード化)されたマルチショットの映像を生成します。視覚的な一貫性を維持しつつ、単一ショットの描写から、重層的で豊かな物語へと映像表現を引き上げます。
・ネイティブA/V同期: 自然なリップシンクとスタジオ品質のオーディオを備えた、複数話者による対話シーンを生成します。それは単に「本物のように見える」だけでなく、「本物のように聞こえる」体験を提供します。
・シネマティッククオリティ: 指示への忠実度、運動物理、および審美的なコントロールを全面的にアップグレード。最大15秒間の1080p HD映像生成において、映画レベルの品質を実現しました。
・高度な画像合成と編集: レンズ設定やライティングを精密に制御し、映画のようなフォトリアリズムを提供します。複数画像の参照をサポートすることで、商業利用に耐えうる一貫性と、忠実なスタイル転送(aesthetic transfer)を可能にしています。
・構造化されたストーリーテリング: 現実世界の知識と推論能力を活用し、テキストと画像を織り交ぜたコンテンツを生成します。これにより、階層的で構造化された視覚的ナラティブの構築が可能になります。
■Wan公式ワークスペース
https://create.wan.video/explore
■Introducing Wan 2.6(公式ブログ、英語)
https://wan.video/blog/wan2.6-introduction
■API(Alibaba Cloud Model Studio)
https://modelstudio.alibabacloud.com/
プランと価格
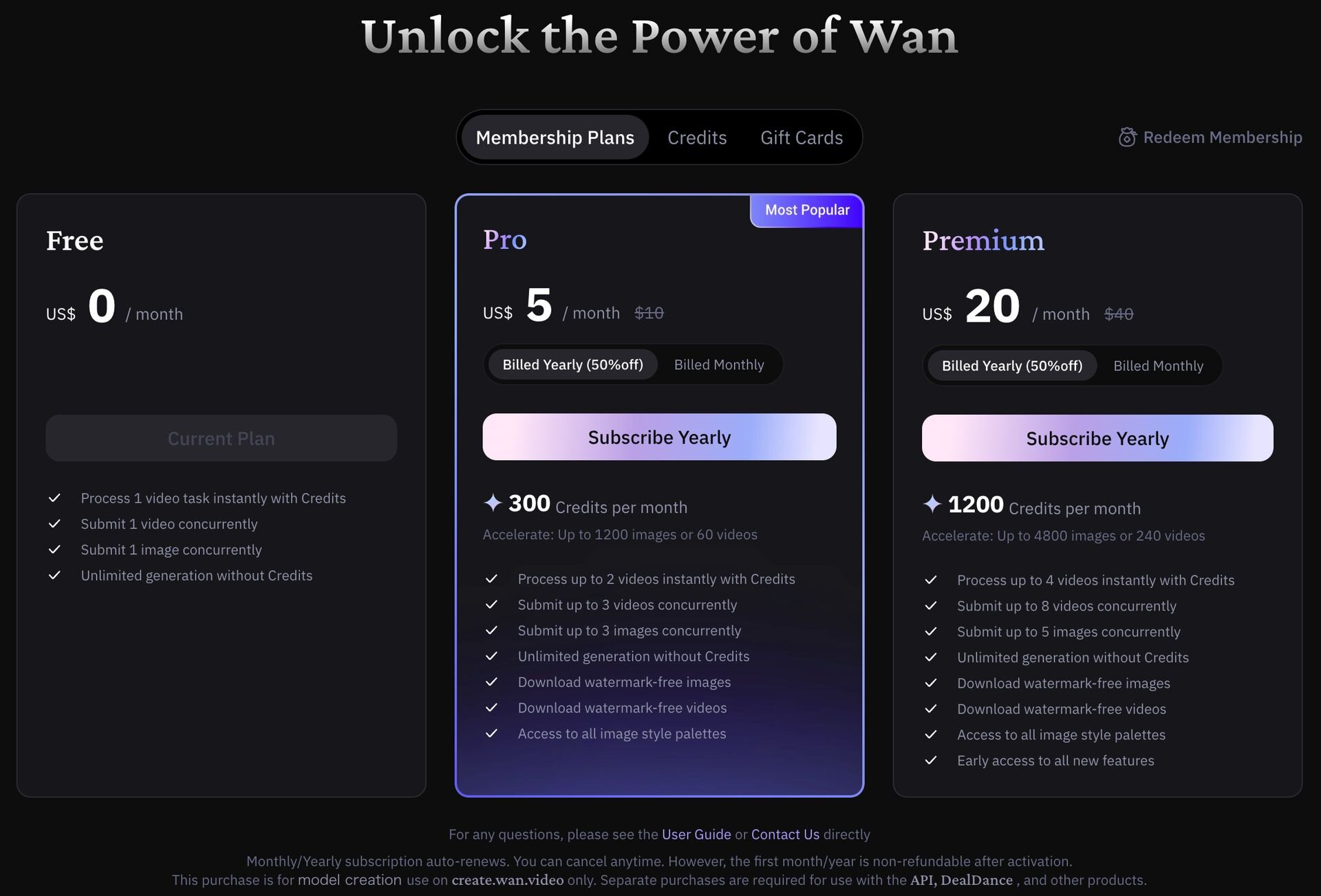
Wan2.6の公式ワークスペースでは、無料のFreeプランと有料のProプラン、Premiumプランが用意されている。Proプランは月額5ドル(約780円)で、透かしなしの画像・動画のダウンロードや商業利用が可能となる。また、毎月300クレジットが付与され、最大60本の動画生成を高速化できる。なお、最上位のPremiumプランには新機能への早期アクセス権が付帯する。
■Wan AI Membership Plans
https://create.wan.video/pricing
CGWORLD関連情報
●マルチモーダル動画生成AIモデル「Kling O1」リリース! テキスト・画像・動画・特定の被写体を組み合わた入力に対応、動画生成から編集・スタイル変換まで1モデルに統合

快手がマルチモーダル動画生成AIモデル「Kling O1 動画モデル」をリリース。テキストと参照画像、既存の動画、特定の被写体(エレメント)を混在させて指示を出し、3秒から10秒までの動画を生成できる。チャットによる複雑な動画編集やスタイル変換の機能も統合。公式Webアプリでは無料・有料プラン共に利用できるほか、各種サードパーティ製プラットフォームで提供されている。
https://cgworld.jp/flashnews/01-202512-KlingO1.html
●Runwayの動画生成AIモデル「Gen-4.5」リリース! リアルな物理挙動の再現、複雑な演出指示への忠実な追従性を実現

Runwayが動画生成AIの最新基盤モデル「Gen-4.5」を発表し、有料プランのサブスクリプションユーザーに対して提供を開始した。複雑で連続的な指示を正確に理解し実行でき、リアルな物理挙動の再現も可能となった。基本解像度は1,280×720(16:9、9:16)または960×960で、4Kへのアップスケーリングが行える。まずはText to Videoが提供され、今後Image to Video、Keyframes、Video to Videoなども順次提供するとのこと。
https://cgworld.jp/flashnews/01-202512-Gen-4.5.html
●テンセント、オープンソースの動画生成AIモデル「HunyuanVideo 1.5」公開! 超軽量8.3Bパラメータで14GB VRAMのGPUにデプロイ可能

テンセントのHunyuanチームがオープンソースの動画生成AIモデル「HunyuanVideo-1.5」を公開。パラメータ数83億(8.3B)の軽量モデルで最小14GBのVRAMで動作し、Text-to-VideoとImage-to-Videoの生成に対応する。ライセンスは独自のTENCENT HUNYUAN COMMUNITY LICENSEが適用され、原則として商用利用可能だが、欧州連合(EU)・イギリス韓国は適用外(事実上の利用不可)となっている。
https://cgworld.jp/flashnews/01-202512-HunyuanVideo15.html













