
中国・快手(Kuaishou)社は12月1日(月)、マルチモーダル動画生成AIモデル「Kling O1 動画モデル」をリリースした。テキストと参照画像、既存の動画、特定の被写体(エレメント)を混在させて指示を出し、3秒から10秒までの動画を生成できる。チャットによる複雑な動画編集やスタイル変換の機能も統合。公式Webアプリでは無料・有料プラン共に利用できるほか、各種サードパーティ製プラットフォームで提供されている。
Kling O1 動画モデルは、高度なマルチモーダル理解能力に基づく直感的な編集機能を備える。入力された写真や動画、被写体を深く理解するため、ユーザーは「背景の通行人を消去する」「昼のシーンを夕暮れに変える」「主人公の衣装を変更する」といった自然言語の指示を出すだけで、複雑な編集を実行できる。
また、All-in-One Reference機能により、モデルは入力された参照画像や特定の被写体の特徴を記憶し、カメラアングルやシーンの雰囲気が変化しても、そのアイデンティティを安定して維持し続けることが可能。さらに、Kling O1 動画モデルは複数のタスクを単一のプロンプト内で組み合わせて実行する能力を備え、「被写体を追加しつつ背景を変更する」「スタイルを変更しながら特定の要素を使用する」といった複合的な指示に対応する。
技術面では、新たに導入された「インタラクティブ・マルチモーダル・ビジュアル言語(MVL)」と「Multimodal Transformer」の統合により、テキストの意味とビジュアル信号の深い融合を実現。Kling AIチームによる内部評価では、画像参照タスクにおいてGoogle Veo 3.1に対して247%、変換タスクにおいてRunway Alephに対して230%の勝率を記録したとする。
-
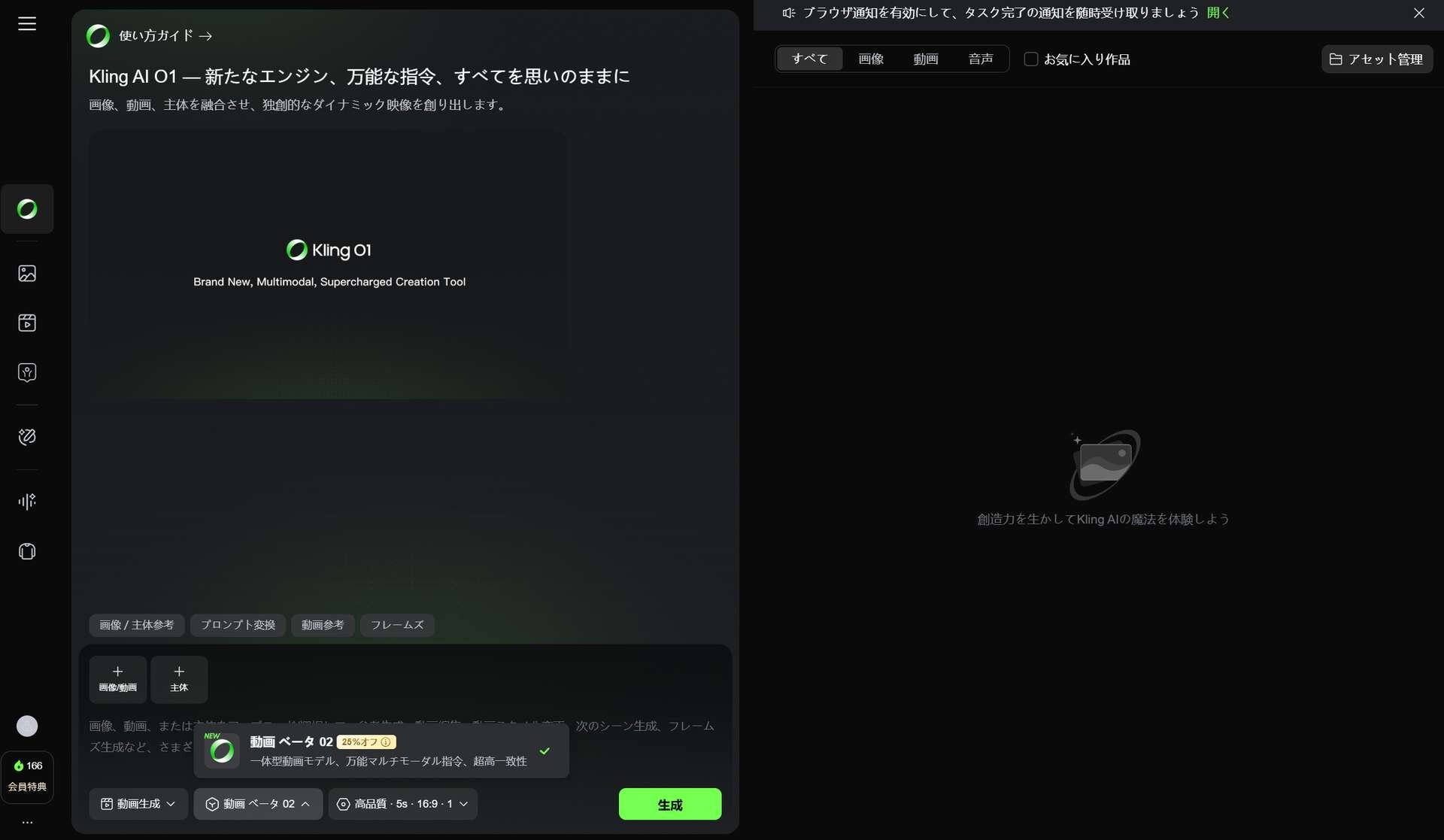
▲ワークスペースでKling O1 動画モデルにアクセス -
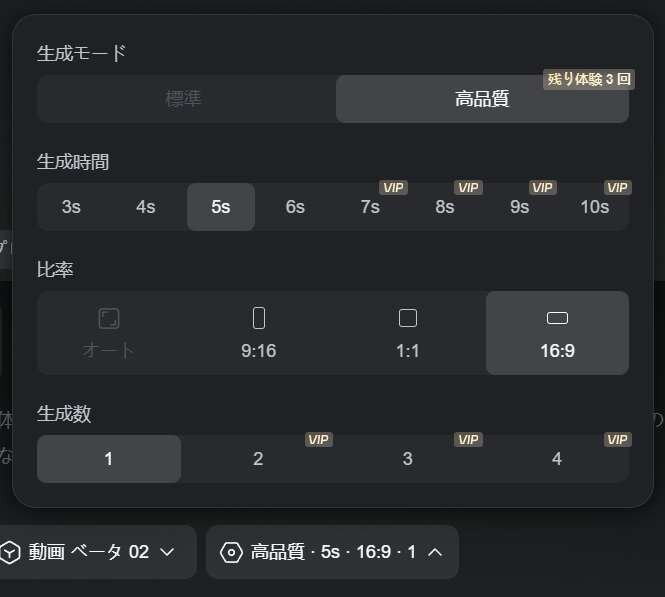
▲Kling O1 動画モデルは3~10秒の生成(7~10秒は有料プランが必要)に対応し、画像比率は16:9、9:16、1:1の3つに対応。性整数は1~4(2~4は有料プランが必要)
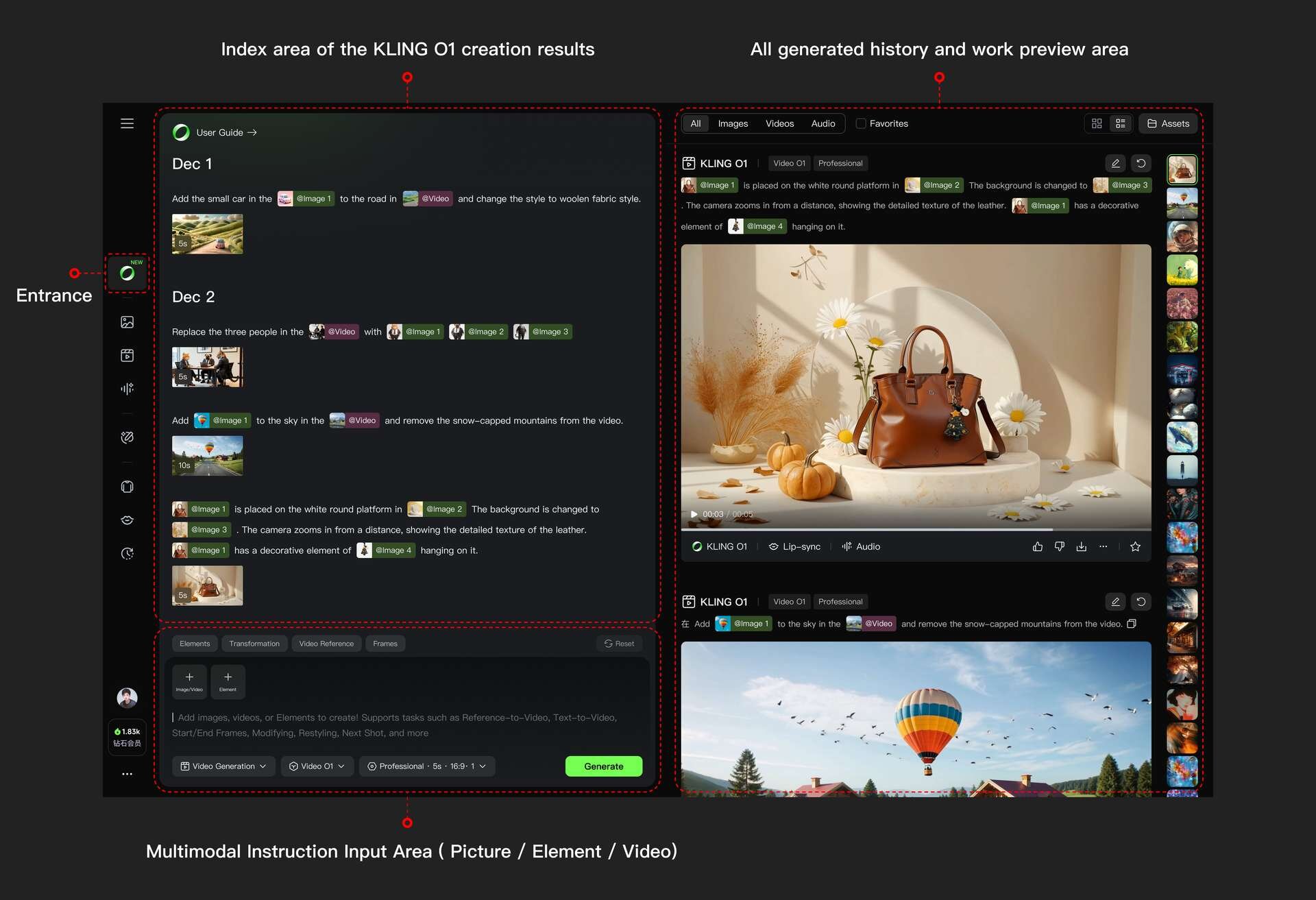
■Kling O1(公式Webアプリ、ワークスペース内)
https://app.klingai.com/global/omni/new
■Kling O1 動画モデル正式リリース! 新たなエンジン、万能な指令、すべてを思いのままに!(公式リリースノート)
https://app.klingai.com/global/release-notes/vaxrndo66h?type=dialog
■Kling O1 - Kling 動画 O1 ご利用ガイド
https://app.klingai.com/global/quickstart/klingai-video-o1-user-guide
プランと価格
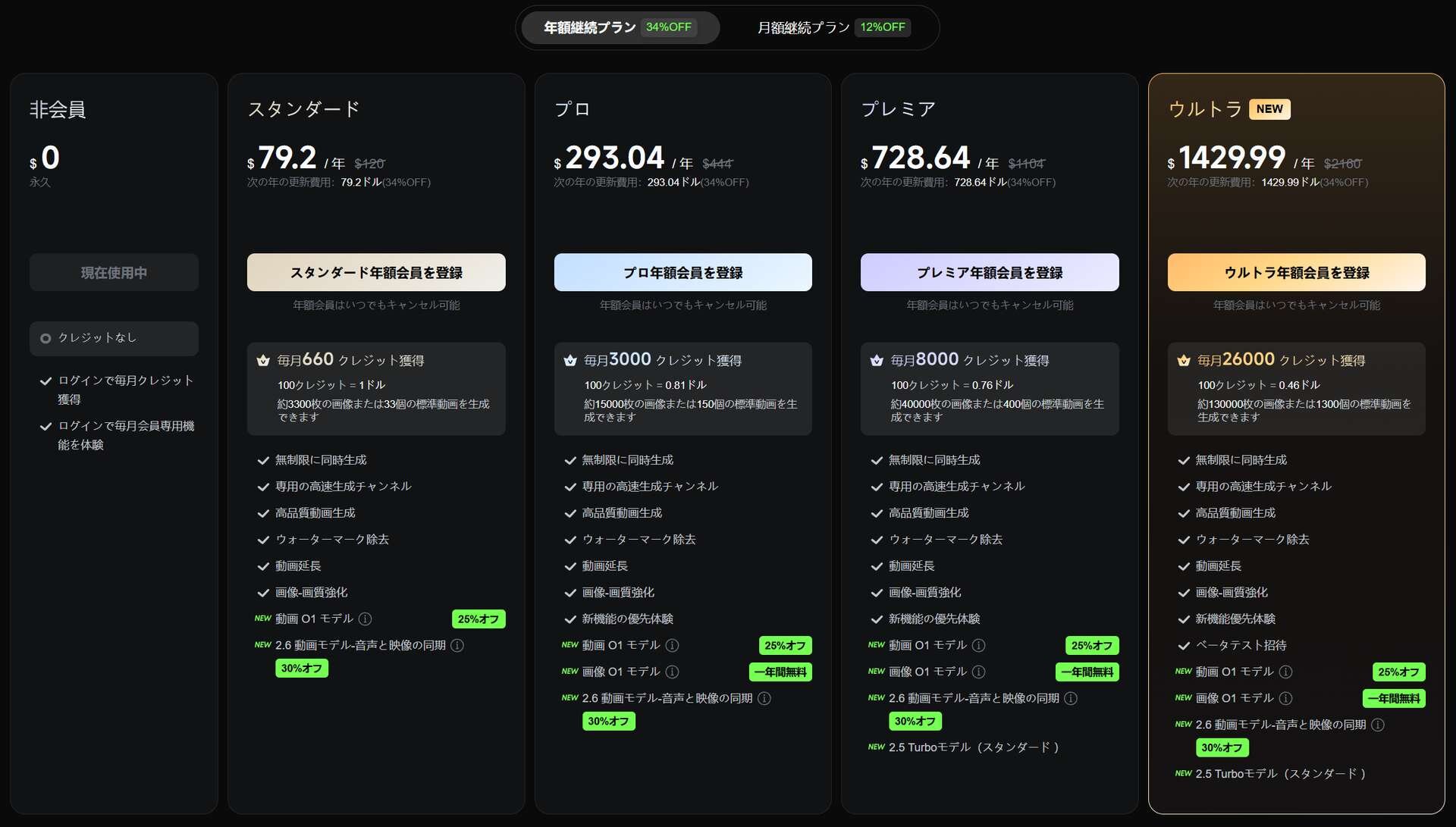
無料で利用できる非会員(Basic)プランは、ログインすることで毎月会員専用機能を体験できる権利が付与されるが、システムの混雑時には生成ができないほか、「VIP」表記のある有料プラン向けオプションは利用できない。
スタンダード(Standard)プランは年額79.2ドル(約12,335円)で提供され、毎月660クレジット付与。無制限の同時生成、専用の高速生成チャンネル、高品質動画の生成、ウォーターマークの除去などが含まれる。
プロ(Pro)プランは年額293.04ドル(約45,641円)で、毎月3,000クレジット付与。スタンダードプランの全機能に加え、新機能を優先的に体験できる権利が付与される。また、このプランからは画像O1モデルが1年間無料で利用できる特典が追加されている。
■Kling AI Membership Plans
https://app.klingai.com/global/membership/membership-plan
■Kling AI Terms of Paid Service
https://app.klingai.com/global/docs/payment-policy
CGWORLD関連情報
●Runwayの動画生成AIモデル「Gen-4.5」リリース! リアルな物理挙動の再現、複雑な演出指示への忠実な追従性を実現

Runwayが動画生成AIの最新基盤モデル「Gen-4.5」を発表し、有料プランのサブスクリプションユーザーに対して提供を開始した。複雑で連続的な指示を正確に理解し実行でき、リアルな物理挙動の再現も可能となった。基本解像度は1,280×720(16:9、9:16)または960×960で、4Kへのアップスケーリングが行える。まずはText to Videoが提供され、今後Image to Video、Keyframes、Video to Videoなども順次提供するとのこと。
https://cgworld.jp/flashnews/01-202512-Gen-4.5.html
●テンセント、オープンソースの動画生成AIモデル「HunyuanVideo 1.5」公開! 超軽量8.3Bパラメータで14GB VRAMのGPUにデプロイ可能

テンセントのHunyuanチームがオープンソースの動画生成AIモデル「HunyuanVideo-1.5」を公開。パラメータ数83億(8.3B)の軽量モデルで最小14GBのVRAMで動作し、Text-to-VideoとImage-to-Videoの生成に対応する。ライセンスは独自のTENCENT HUNYUAN COMMUNITY LICENSEが適用され、原則として商用利用可能だが、欧州連合(EU)・イギリス韓国は適用外(事実上の利用不可)となっている。
https://cgworld.jp/flashnews/01-202512-HunyuanVideo15.html
●Adobeら、リアルタイム動画生成AI「MotionStream」発表! マウスのドラッグ&クリックに即座に反応するインタラクティブな動画を無限長ストリーミング

Adobe Research、カーネギーメロン大学(CMU)、ソウル大学校(SNU)の研究者らが、リアルタイムかつインタラクティブな制御が可能な動画生成技術「MotionStream」を発表。単一のNVIDIA H100 GPU上で最大29fpsの生成速度と0.4秒以下の低遅延を実現し、無限長のストリーミングを可能にしたという。
https://cgworld.jp/flashnews/01-202511-MotionStream.html












