
中国テンセント(Tencent)社のHunyuanチームは11月21日(金)、オープンソースの動画生成AIモデル「HunyuanVideo-1.5」を公開した。パラメータ数83億(8.3B)の軽量モデルで最小14GBのVRAMで動作し、Text-to-VideoとImage-to-Videoの生成に対応する。ライセンスは独自のTENCENT HUNYUAN COMMUNITY LICENSEが適用され、原則として商用利用可能だが、欧州連合(EU)・イギリス韓国は適用外(事実上の利用不可)となっている。
We are excited to unveil HunyuanVideo 1.5, the strongest open-source video generation model. Built upon DiT architecture, it redefines the open-source SOTA for accessibility and performance.
— Hunyuan (@TencentHunyuan) November 21, 2025
HunyuanVideo 1.5 delivers state-of-the-art visual quality and motion coherence… pic.twitter.com/ygGgh2qfRh
We are excited to unveil HunyuanVideo 1.5, the strongest open-source video generation model. Built upon DiT architecture, it redefines the open-source SOTA for accessibility and performance. HunyuanVideo 1.5 delivers state-of-the-art visual quality and motion coherence while drastically lowering the entry barrier for developers and creators:
・Unmatched Accessibility: Ultra-light 8.3B parameters, deployable on consumer GPUs with only 14GB VRAM.
・HD Cinematic Quality: Natively generates 5–10 second 480p/720p HD videos, with super-resolution support for 1080p cinematic quality.
By merging SOTA performance with high hardware efficiency, HunyuanVideo 1.5 sets the new technical baseline for the open-source community.最強のオープンソース動画生成モデルHunyuanVideo 1.5を発表します。DiTアーキテクチャを基盤とし、アクセシビリティとパフォーマンスにおいてオープンソースの最先端(SOTA)を再定義するものです。本モデルは、最先端の視覚品質と動きの一貫性を実現すると同時に、開発者やクリエイターの利用障壁を大幅に引き下げます。
・比類なきアクセシビリティ: パラメータ数は超軽量の83億(8.3B)であり、わずか14GBのVRAMでコンシューマー向けGPU上に展開可能
・HDシネマティック品質: 5〜10秒の480pおよび720p HD動画をネイティブに生成可能で、さらに1080pのシネマティック品質を実現する超解像機能をサポート
最先端のパフォーマンスと高いハードウェア効率を融合させることで、HunyuanVideo 1.5はオープンソースコミュニティにおける新たな技術的基準を確立します。
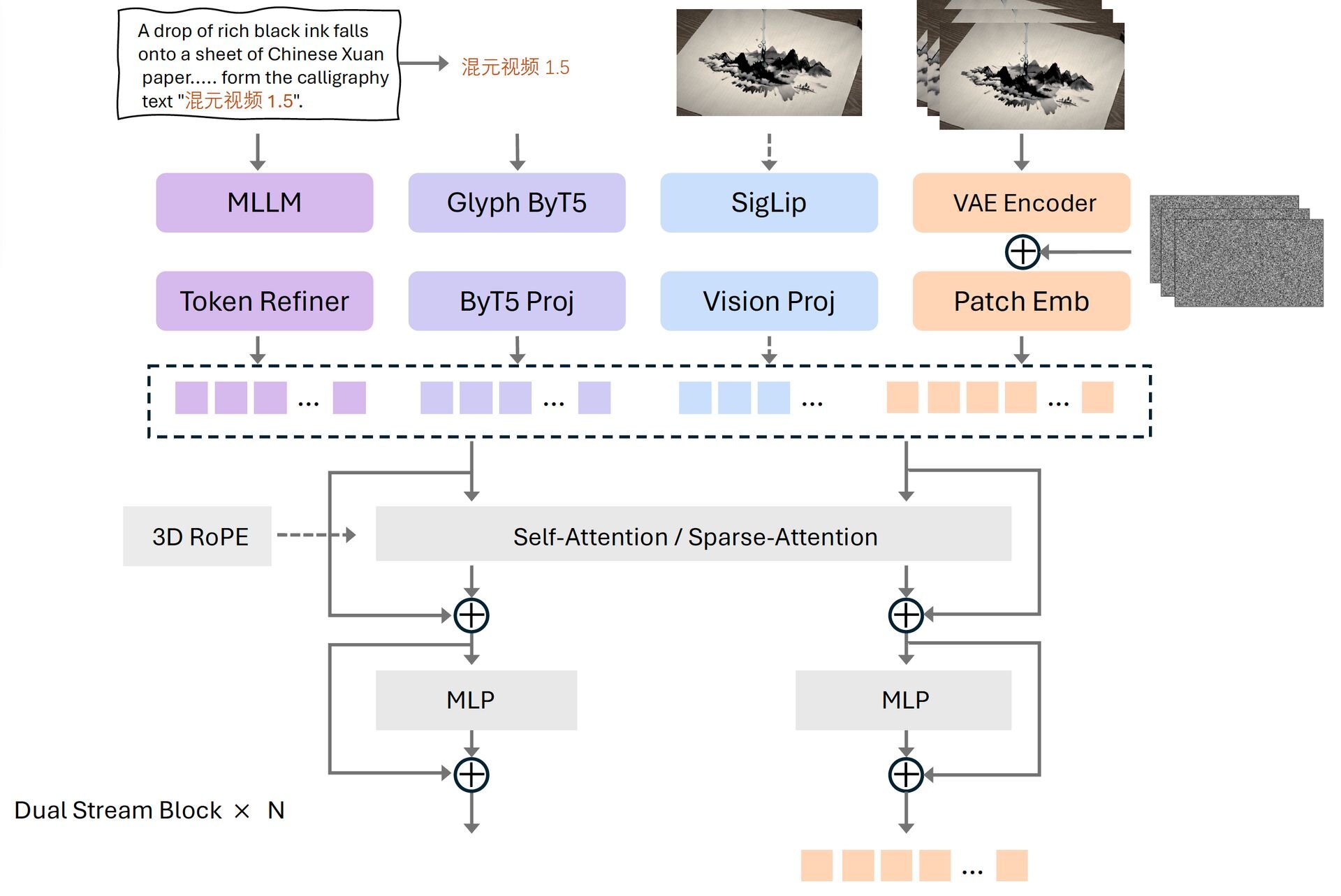
「HunyuanVideo-1.5」は、徹底的なデータ圧縮と計算の効率化により、高速動作を実現した軽量な動画生成AI。その基本設計には拡散トランスフォーマー(DiT、Diffusion Transformer)と3D Causal VAE(Variational Autoencoder)が統合されており、動画データを空間的に16分の1、時間的に4分の1へ圧縮して処理することで、システムの負担を軽減している。
さらに、独自の「Selective and Sliding Tile Attention(SSTA)」機能が計算の無駄を排除。動画生成において重要ではないデータの処理を自動的に見極めて省くSSTにより、10秒間の720p動画を生成する速度は、従来の高速技術(FlashAttention-3)と比較して約1.9倍に達したという。
HunyuanVideo-1.5はコンシューマー向けGPUでの動作を想定して設計されており、モデルのオフローディング機能を有効にした場合、最小14GBのVRAMで動作可能。GPUメモリに余裕がある場合は、オフローディングを無効化することで推論速度を向上させることができる。
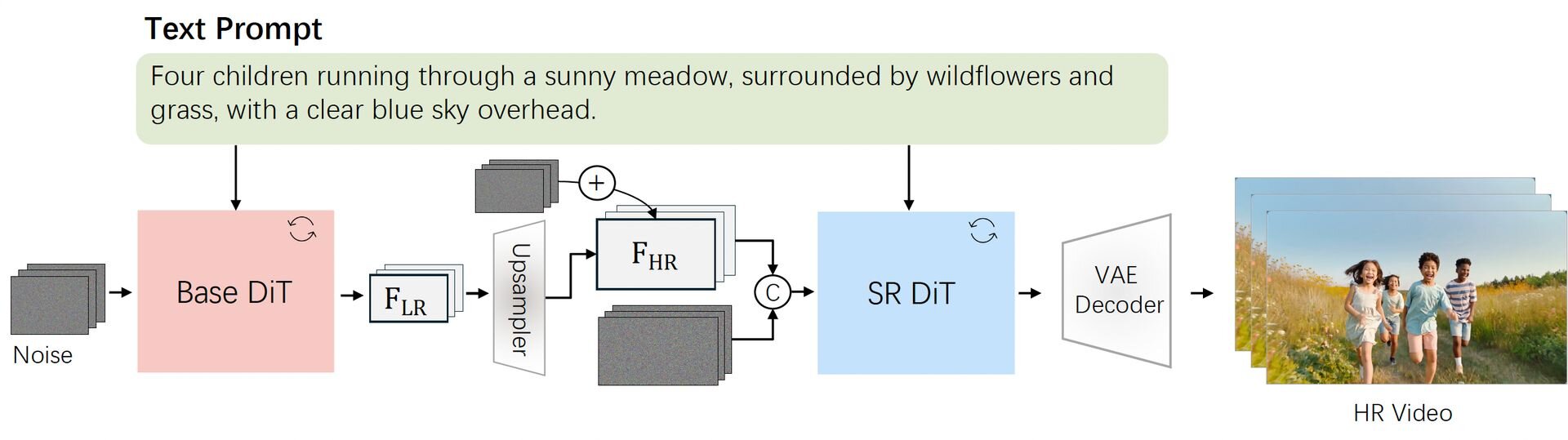
映像品質においては、独自の超解像技術(Video Super-Resolution、VSR)により、生成された動画の歪みを補正しつつ細部を鮮明化し、1080pの高画質へとアップスケールできる。また、学習プロセスでは、初期段階から仕上げまでを段階的に行う手法と専用のオプティマイザ(Muon)を導入し、動画の動きの滑らかさとビジュアル品質を効率的に高めているという。
入力の理解力に関しては、文字の形状(グリフ)まで認識する技術によって、言語間のニュアンスをより正確に捉えることができる。さらに、GeminiやQwenといった外部の大規模言語モデルと連携し、ユーザーのプロンプトを自動で詳細な記述へと書き換える機能を備え、簡潔なプロンプト入力であってもモデルの性能を最大限に引き出した動画生成を実現できるとする。
HunyuanVideo-1.5の推論コードとモデルウェイトはGitHubとHugging Faceで公開されている。また、ComfyUIへのネイティブサポートやコミュニティ製プラグイン、軽量フレームワーク「LightX2V」への対応も整備されている。
■Hunyuan-Video Generation Open-Source Model: HunyuanVideo 1.5(公式ページ)
https://hunyuan.tencent.com/video/zh?tabIndex=0
■HunyuanVideo-1.5: A leading lightweight video generation model(GitHub)
https://github.com/Tencent-Hunyuan/HunyuanVideo-1.5
■HunyuanVideo-1.5: A leading lightweight video generation model(Hugging Face)
https://huggingface.co/tencent/HunyuanVideo-1.5
CGWORLD関連情報
●Adobeら、リアルタイム動画生成AI「MotionStream」発表! マウスのドラッグ&クリックに即座に反応するインタラクティブな動画を無限長ストリーミング

Adobe Research、カーネギーメロン大学(CMU)、ソウル大学校(SNU)の研究者らが、リアルタイムかつインタラクティブな制御が可能な動画生成技術「MotionStream」を発表。単一のNVIDIA H100 GPU上で最大29fpsの生成速度と0.4秒以下の低遅延を実現し、無限長のストリーミングを可能にしたという。執筆現在でGitHubリポジトリは存在するが、コードやモデルは公開されていない。
https://cgworld.jp/flashnews/01-202511-MotionStream.html
●動画生成AIモデル「Hailuo 2.3」リリース! 物理動作・スタイライズ・キャラクターの表情描写などが改善、高速・低価格モデル「Hailuo 2.3 Fast」も提供

MiniMaxが動画生成AIモデル「Hailuo 2.3」をリリース。Hailuo AIのWebサイト、モバイルアプリ、Open Platform APIで利用可能にした。Hailuo 2.3はHailuo 2.0モデルを基盤とし、よりリアルで安定したビジュアルとダイナミックな表現力を備えたモデル。提供されるのは「Hailuo 2.3」と高速・低価格な「Hailuo 2.3 Fast」の2種類。
https://cgworld.jp/flashnews/01-202511-Hailuo23.html
●オープンソースの動画生成AIエンジン「LTX-2」リリース! ネイティブ4K対応、50fps・20秒の音声付きシーンを生成

LightricksがオープンソースのAIクリエイティブエンジン「LTX-2」をリリース。プロダクション向けに設計され、音声と同期したネイティブ4K・50fps、20秒の連続的なシーンの生成を可能とする。公式ワークスペースのLTX Studio API Playground、ComfyUIなどサードパーティ製ツールとの統合を通じて利用できる。コードとウェイトは11月下旬にGitHubで公開予定。
https://cgworld.jp/flashnews/01-202511-LTX-2.html













