
中国・アリババグループの研究開発チームTongyi-MAIは11月27日(木)、オープンソース(Apache-2.0ライセンス)の画像生成AIモデル「Z-Image」を発表し、生成用の特化モデル「Z-Image-Turbo」を公開した。フォトリアルな生成能力とバイリンガルテキストの描画を両立する60億パラメータの基盤モデルで、ソースはGitHubで、デモとモデルはHugging FaceとModelScopeで公開されている。
技術面では、テキストと画像の情報を単一のながれとして処理する「Scalable Single-Stream DiT(S3-DiT)」アーキテクチャを採用。従来の、テキストと画像を別々に処理するデュアルストリーム方式とは異なり、テキストトークン、視覚的意味トークン、画像VAEトークンを結合して統一的に扱うことで、パラメータ効率を最大化しつつ、モデルサイズ60億パラメータの規模で高度な表現力を獲得しているという。
今回公開された生成用特化モデル「Z-Image-Turbo」は、独自の高速化技術「Decoupled-DMD」と強化学習を組み合わせた「DMDR」手法により、わずか8ステップ(NFE)での高品質な画像生成を実現。H800などのエンタープライズ向けGPUでは1秒未満という高速な推論速度を達成し、一般的な16GB VRAM搭載のコンシューマ向けGPUでも快適に動作する軽量性を備えるとのことだ。
We are pleased to introduce Z-Image, an efficient 6-billion-parameter foundation model for image generation. Through systematic optimization, it proves that top-tier performance is achievable without relying on enormous model sizes, delivering strong results in photorealistic generation and bilingual text rendering that are comparable to leading commercial models.
画像生成のための高効率な60億パラメータ基盤モデル「Z-Image」を紹介します。体系的な最適化により、巨大なモデルサイズに依存せずとも最高レベルの性能が達成可能であることを実証しました。主要な商用モデルに匹敵するフォトリアルな生成能力とバイリンガルテキストの描画において、優れた結果を提供します。

At just 6 billion parameters, Z-Image produces photorealistic images on par with those from models an order of magnitude larger. It can run smoothly on consumer-grade graphics cards with less than 16GB of VRAM, making advanced image generation technology accessible to a wider audience.
We are publicly releasing two specialized models on Z-Image: Z-Image-Turbo(Released) for generation and Z-Image-Edit(to-be-released) for editing.わずか60億パラメータでありながら、Z-Imageは一桁上の規模を持つモデルに匹敵するフォトリアルな画像を生成します。VRAM 16GB未満のコンシューマー向けグラフィックスカードでもスムーズに動作し、高度な画像生成技術をより幅広いユーザー層が利用できるようにします。
今回、Z-Imageをベースとした2つの特化型モデル、生成用の「Z-Image-Turbo」(公開済み)と編集用の「Z-Image-Edit」(公開予定)をリリースします。
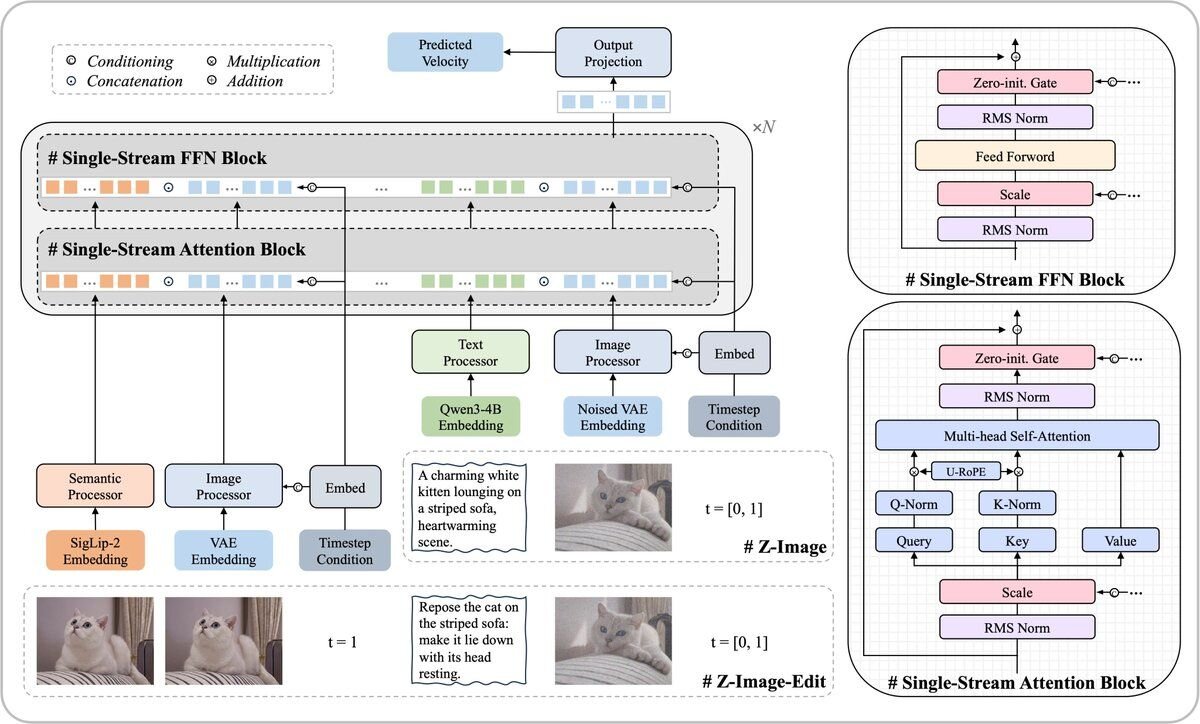
Architecture: The Z-Image model adopts a Single-Stream Diffusion Transformer architecture. This design unifies the processing of various conditional inputs (like text and image embeddings) with the noisy image latents into a single sequence, which is then fed into the Transformer backbone.
アーキテクチャ:Z-Imageモデルは、シングルストリーム拡散(Diffusion)トランスフォーマーアーキテクチャを採用しています。この設計では、様々な条件入力(テキストや画像の埋め込みなど)とノイズを含む画像ラテント(潜在変数)の処理を単一のシーケンスに統合し、トランスフォーマーバックボーンに入力します。

Efficient Photorealistic Quality: Z-Image-Turbo excels at producing images with photography-level realism, demonstrating fine control over details, lighting, and textures. It balances high fidelity with strong aesthetic quality in composition and overall mood. The generated images are not only realistic but also visually appealing.
効率的かつフォトリアルな画質:Z-Image-Turboは、ディテール、ライティング、テクスチャを緻密に制御し、写真レベルのリアリズムを持つ画像の生成に優れています。また、高い忠実度と、構図や全体的な雰囲気における優れた美的品質をバランスよく両立させています。生成される画像は、単にリアルなだけでなく、ビジュアル面での魅力も兼ね備えています。

Excellent Bilingual Text Rendering: Z-Image-Turbo can accurately render Chinese and English text while preserving facial realism and overall aesthetic composition, with results comparable to top-tier closed-source models. In poster design, it demonstrates strong compositional skills and a good sense of typography. It can render high-quality text even in challenging scenarios with small font sizes, delivering designs that are both textually precise and visually compelling.
優れたバイリンガルテキスト描画能力:Z-Image-Turboは、顔のリアリズムや全体的な美的構成を維持したまま、中国語と英語のテキストを正確にレンダリングできます。その性能はトップクラスのクローズドソースモデルに匹敵します。
ポスターデザインにおいては、強力な構成力と優れたタイポグラフィ(文字デザイン・配置)のセンスを発揮します。小さなフォントサイズなどの難しい条件下でも高品質なテキスト描画が可能で、テキストの正確さと視覚的な訴求力を兼ね備えたデザインを提供します。

Rich World Knowledge and Cultural Understanding: Z-Image possesses a vast understanding of world knowledge and diverse cultural concepts. This allows it to accurately generate a wide array of subjects, including famous landmarks, well-known characters, and specific real-world objects.
豊富な世界知識と文化的理解:Z-Imageは、世界に関する膨大な知識と多様な文化的概念への深い理解を有しています。これにより、有名なランドマーク、著名なキャラクター、特定の現実世界の物体など、幅広い被写体を正確に生成することができます。

Deep Semantic Understanding with Priori Knowledge: The powerful prompt enhancer (PE) uses a structured reasoning chain to inject logic and common sense, enabling the model to handle complex tasks like the "chicken-and-rabbit problem" or visualizing classical Chinese poetry. In editing tasks, even when faced with ambiguous user instructions, the model can apply its reasoning capabilities to infer the underlying intent and ensure a logically coherent result.
事前知識に基づく深い意味理解:強力なプロンプトエンハンサー(PE)は、構造化された推論チェーンを使用して論理と常識を組み込み、「つるかめ算」のような複雑な問題や、漢詩の視覚化といったタスクの処理を可能にします。
編集タスクにおいては、ユーザーの指示が曖昧な場合でも、モデルが推論能力を駆使してその背後にある意図を読み取り、論理的に整合性の取れた結果を確実に提供します。

Strong Instruction-Following and Creative Editing: Z-Image-Edit can precisely execute complex instructions, such as simultaneously changing and brightening the background. It can also modify text at specified locations and maintain character consistency during significant image transformations, demonstrating fine-grained control over image elements.
強力な指示従順性と創造的な編集:Z-Image-Editは、背景を変更しながら同時に明るくするといった複雑な指示を正確に実行できます。また、指定した位置のテキストを修正したり、画像を大幅に変換する際にもキャラクターの一貫性を維持したりすることができ、画像の各要素に対して緻密な制御が可能であることを示しています。
■Z-Image: Efficient Image Generation Model with Single-Stream Diffusion Transformer(公式ページ)
https://tongyi-mai.github.io/Z-Image-blog/
■Z-Image(GitHub)
https://github.com/Tongyi-MAI/Z-Image
■Z-Image Generation Demo(Hugging Face)
https://huggingface.co/spaces/Tongyi-MAI/Z-Image-Turbo
■Z-Image-Turbo(ModelScope)
https://modelscope.ai/models/Tongyi-MAI/Z-Image-Turbo/
CGWORLD関連情報
●画像生成AIモデル「FLUX.2」リリース! 最大10枚のリファレンス画像を用いたキャラクターやスタイルの一貫性維持、最大4メガピクセルでの画像編集など

Black Forest Labsが画像生成AIモデルファミリー「FLUX.2」を発表。複数の参照画像(最大10枚)を用いたキャラクターやスタイルの一貫性維持、複雑なテキストレンダリング、ブランドガイドラインの遵守、最大4メガピクセルの高解像度での画像編集など、プロユースの要件を満たす機能を備える。FLUX.2はプロ向けAPIから開発者向けのオープンウェイトモデルまで4種のラインナップで展開される。同社FLUX PlaygroundとAPI、各パートナープラットフォームを通じて利用できる。
https://cgworld.jp/flashnews/01-202512-FLUX2.html
●テンセント、オープンソースの動画生成AIモデル「HunyuanVideo 1.5」公開! 超軽量8.3Bパラメータで14GB VRAMのGPUにデプロイ可能

テンセントのHunyuanチームがオープンソースの動画生成AIモデル「HunyuanVideo-1.5」を公開。パラメータ数83億(8.3B)の軽量モデルで最小14GBのVRAMで動作し、Text-to-VideoとImage-to-Videoの生成に対応する。ライセンスは独自のTENCENT HUNYUAN COMMUNITY LICENSEが適用され、原則として商用利用可能だが、欧州連合(EU)・イギリス韓国は適用外(事実上の利用不可)となっている。
https://cgworld.jp/flashnews/01-202512-HunyuanVideo15.html
●Adobeら、リアルタイム動画生成AI「MotionStream」発表! マウスのドラッグ&クリックに即座に反応するインタラクティブな動画を無限長ストリーミング

Adobe Research、カーネギーメロン大学(CMU)、ソウル大学校(SNU)の研究者らが、リアルタイムかつインタラクティブな制御が可能な動画生成技術「MotionStream」を発表。単一のNVIDIA H100 GPU上で最大29fpsの生成速度と0.4秒以下の低遅延を実現し、無限長のストリーミングを可能にしたという。執筆現在でGitHubリポジトリは存在するが、コードやモデルは公開されていない。
https://cgworld.jp/flashnews/01-202511-MotionStream.html













