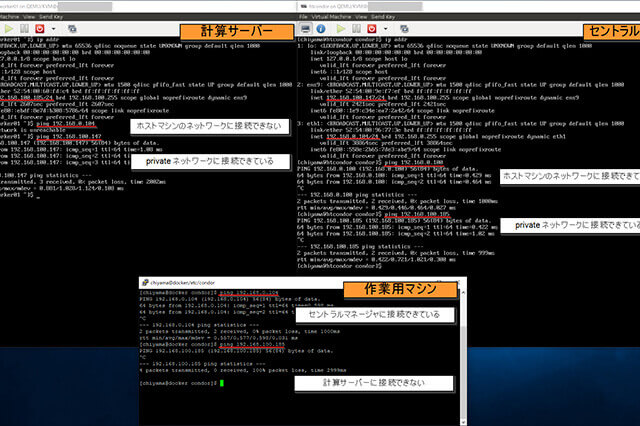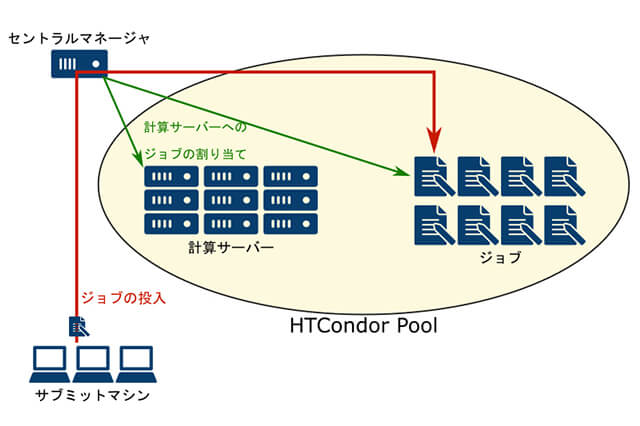
ジョブを投入する
準備ができたのでジョブを投入してみます。10個のジョブが投入され、処理が行われています。
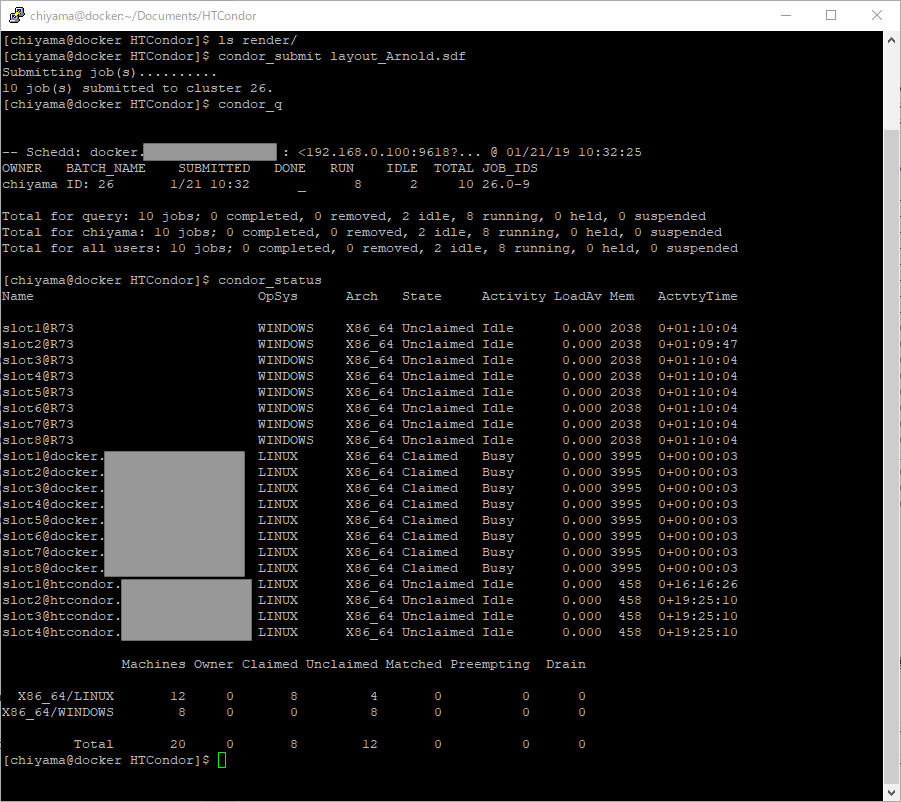
これでしばらく待つと10枚の画像がレンダリングされます。
[chiyama@docker HTCondor]$ ls render/
layout_Arnold.0000.exr layout_Arnold.0003.exr layout_Arnold.0006.exr layout_Arnold.0009.exr
layout_Arnold.0001.exr layout_Arnold.0004.exr layout_Arnold.0007.exr
layout_Arnold.0002.exr layout_Arnold.0005.exr layout_Arnold.0008.exr
[chiyama@docker HTCondor]$
これで、Gaffer+ArnoldのシーンをHTCondor上でレンダリングできました。
・データ変換処理を行う
続いて、第4回:USDシーンの作成でMayaデータからAlembicファイルに変換した処理をサーバ側で行うようにしてみます。そのときに使ったスクリプトは以下のものでした。
----
import os
import maya.cmds as cmds
src = r'/home/chiyama/Documents/usdtest/assets/Street Walk Scene/scenes'
dest = r'/home/chiyama/Documents/usdtest/assets/Street Walk Scene/cache/alembic'
def getTops():
ret = []
for t in cmds.ls(type='transform'):
p = cmds.listRelatives(t, parent=True)
if p is not None:
continue
if t in ['front', 'top', 'side', 'persp']:
continue
ret.append(t)
return ret
for f in os.listdir(src):
prfx, ext = os.path.splitext(f)
cmds.file(os.path.join(src, f), open=True, force=True)
tops = getTops()
g = cmds.createNode('transform' ,n='%s_root' % prfx )
cmds.parent(*(tops + [g]))
fname = os.path.join(dest, '%s.abc' % prfx)
cmd = '-frameRange 0 0 -uvWrite -root %s -file "%s"' % (g, fname)
cmds.AbcExport ( j = cmd )
----
これをサーバ上で実行するように書き換えます。これもいくつかの段階に処理を分割していきます。
・HTCondorにジョブを投入する
・HTCondorがジョブを解釈してMayaを実行する
・Mayaがスクリプトを実行する
・ファイルの変換を行う
前半はレンダリングのときとほとんど変わらないです。ちがうのはMayaを使用することと、Maya上で実行するスクリプトを用意することです。また、元のスクリプトは一度の実行でディレクトリ内の全てのファイルに対して処理を行うようになっていましたが、これでは効率が悪いので一度の実行でひとつのファイルを処理するようにして、複数の処理を並行して実行できるようにします。
と言ってもジョブの制御はHTCondorが行なってくれるので、われわれは一度の実行でひとつのファイルをつくるだけでよく、必要なスクリプトはむしろ単純になっています。
Maya起動時にpythonスクリプトを実行させるためにはmayapyを使用します。mayapyで指定できる引数は--helpを渡すことで確認できます。
[chiyama@docker ~]$ /usr/autodesk/maya2017/bin/mayapy --help
usage: /usr/autodesk/maya2017/bin/python-bin [option] ... [-c cmd | -m mod | file | -] [arg] ...
Options and arguments (and corresponding environment variables):
-B : don't write .py[co] files on import; also PYTHONDONTWRITEBYTECODE=x
-c cmd : program passed in as string (terminates option list)
-d : debug output from parser; also PYTHONDEBUG=x
-E : ignore PYTHON* environment variables (such as PYTHONPATH)
-h : print this help message and exit (also --help)
-i : inspect interactively after running script; forces a prompt even
if stdin does not appear to be a terminal; also PYTHONINSPECT=x
-m mod : run library module as a script (terminates option list)
-O : optimize generated bytecode slightly; also PYTHONOPTIMIZE=x
-OO : remove doc-strings in addition to the -O optimizations
-R : use a pseudo-random salt to make hash() values of various types be
unpredictable between separate invocations of the interpreter, as
a defense against denial-of-service attacks
-Q arg : division options: -Qold (default), -Qwarn, -Qwarnall, -Qnew
-s : don't add user site directory to sys.path; also PYTHONNOUSERSITE
-S : don't imply 'import site' on initialization
-t : issue warnings about inconsistent tab usage (-tt: issue errors)
-u : unbuffered binary stdout and stderr; also PYTHONUNBUFFERED=x
see man page for details on internal buffering relating to '-u'
-v : verbose (trace import statements); also PYTHONVERBOSE=x
can be supplied multiple times to increase verbosity
-V : print the Python version number and exit (also --version)
-W arg : warning control; arg is action:message:category:module:lineno
also PYTHONWARNINGS=arg
-x : skip first line of source, allowing use of non-Unix forms of #!cmd
-3 : warn about Python 3.x incompatibilities that 2to3 cannot trivially fix
file : program read from script file
- : program read from stdin (default; interactive mode if a tty)
arg ...: arguments passed to program in sys.argv[1:]
Other environment variables:
PYTHONSTARTUP: file executed on interactive startup (no default)
PYTHONPATH : ':'-separated list of directories prefixed to the
default module search path. The result is sys.path.
PYTHONHOME : alternate directory (or :).
The default module search path uses /pythonX.X.
PYTHONCASEOK : ignore case in 'import' statements (Windows).
PYTHONIOENCODING: Encoding[:errors] used for stdin/stdout/stderr.
PYTHONHASHSEED: if this variable is set to 'random', the effect is the same
as specifying the -R option: a random value is used to seed the hashes of
str, bytes and datetime objects. It can also be set to an integer
in the range [0,4294967295] to get hash values with a predictable seed.
[chiyama@docker ~]$
helpを見ると、
mayapy /path/to/script.py 引数
で実行できそうです。
mayapy実行時にいくつか環境変数を設定したかったので、mayapy.shを作成しています。
[chiyama@docker HTCondor]$ cat ~/mayapy.sh
#!/bin/sh
export MAYA_ROOT=/usr/autodesk/maya2017
export MAYA_DISABLE_CIP=1
$MAYA_ROOT/bin/mayapy "$@"
[chiyama@docker HTCondor]$
ではmayapyを試してみましょう。mayapytest.pyを用意します。
[chiyama@docker HTCondor]$ cat mayapytest.py
import sys
import maya.standalone
maya.standalone.initialize()
import maya.cmds as cmds
print(sys.version_info)
print(cmds.about(version=True))
print(sys.argv)
cmds.quit(force=True)
[chiyama@docker HTCondor]$
注意点としては、mayapyでMayaの機能を使用するときにはmaya.standalone.initialize()が必要なことです。また、cmds.quitできちんと終了処理することも忘れないようにしましょう。
このスクリプトを実行してみます。
[chiyama@docker HTCondor]$ ~/mayapy.sh mayapytest.py foo bar baz
sys.version_info(major=2, minor=7, micro=11, releaselevel='final', serial=0)
2017
['mayapytest.py', 'foo', 'bar', 'baz']
[chiyama@docker HTCondor]$
正常に実行できました。引数もきちんと扱うことができていますね。
・ファイルの変換処理を用意する
ファイル変換用スクリプトを用意します。元のスクリプトをちょっと改造して、変換元のパスと変換先のパスを指定したら元ファイルを読み込んで必要な処理を行なってファイルを保存するようにします。今回は以下の内容でmaya2abc.pyを作成しました。
----
import sys
import os
import maya.standalone
maya.standalone.initialize()
import maya.cmds as cmds
def getTops():
ret = []
for t in cmds.ls(type='transform'):
p = cmds.listRelatives(t, parent=True)
if p is not None:
continue
if t in ['front', 'top', 'side', 'persp']:
continue
ret.append(t)
return ret
def maya2abc(src, dest):
d, f = os.path.split(src)
prfx, ext = os.path.splitext(f)
cmds.file(src, open=True, force=True)
tops = getTops()
g = cmds.createNode('transform' ,n='%s_root' % prfx )
cmds.parent(*(tops + [g]))
cmd = '-frameRange 0 0 -uvWrite -root %s -file "%s"' % (g, dest)
cmds.AbcExport ( j = cmd )
if __name__ == '__main__':
cmds.loadPlugin('AbcExport.mll')
maya2abc(sys.argv[1], sys.argv[2])
cmds.quit(force=True)
----
AbcExportをMaya起動時に自動ロードするようになっていないとエラーになるので、明示的にロードしています。それ以外はほとんどそのままです。
以上を用いてコマンドラインから実行してみます。
----
[chiyama@docker HTCondor]$ ls abc/
[chiyama@docker HTCondor]$ ~/mayapy.sh maya2abc.py ~/Documents/HTCondor/mb/Fiat1500.mb ~/Documents/HTCondor/abc/Fiat1500.abc
AbcExport v1.0 using Alembic 1.5.8 (built Dec 24 2015 17:39:02)
Warning: Unrecognized node type for node 'vraySettings'; preserving node information during this session.
Viewport 2.0 floating point render target is turned off.
Warning: Errors have occurred while reading this scene that may result in data loss.
File read in 0.47 seconds.
Error: line 1: Plug-in, "vrayformaya", was not found on MAYA_PLUG_IN_PATH.
# Traceback (most recent call last):
# File "", line 1, in
# RuntimeError: Plug-in, "vrayformaya", was not found on MAYA_PLUG_IN_PATH.
[chiyama@docker HTCondor]$ ls abc/
Fiat1500.abc
[chiyama@docker HTCondor]$
----
スクリプト実行前にはなかったFiat1500.abcがabcディレクトリ内にできています。
これで、
・HTCondorにジョブを投入する
・HTCondorがジョブを解釈してMayaを実行する
・Mayaがスクリプトを実行する
・ファイルの変換を行う
この4つのパーツが揃いました。では組み上げて動かしてみましょう。
まず、Mayaを起動してファイルの変換を行うコマンドは
/home/chiyama/mayapy.sh /home/chiyama/Documents/HTCondor/maya2abc.py %(src)s %(dest)s
になります。
この処理をHTCondor上でひとつのファイルに対して実行するためのsdfは
----
executable = /bin/sh
output = /home/chiyama/Documents/HTCondor/log/%(prfx)s.out
error = /home/chiyama/Documents/HTCondor/log/%(prfx)s.err
log = /home/chiyama/Documents/HTCondor/log/%(prfx)s.log
arguments = /home/chiyama/mayapy.sh /home/chiyama/Documents/HTCondor/maya2abc.py %(src)s %(dest)s
initialdir = /home/chiyama/Documents/HTCondor
requirements = TARGET.OpSys == "LINUX" && TARGET.FileSystemDomain == "XXX.XXX.XXX" && TARGET.UidDomain == "XXX.XXX.XXX" && TARGET.Machine == "docker.XXX.XXX.XXX"
should_transfer_files = no
queue
----
このように書くことができます(prfx, src, destは後から適切な値を入れます)。
これだけでは処理したいファイル毎にsdfをつくらなければいけないので、sdf生成用のスクリプトを用意します。
※新しいHTCondorならPython対応しているのでsdfを生成しなくても直接Pythonからジョブが投げられるとは思うんですが、それをやってると紙面がいくらあっても足りなくなってくるのでサクッといきます。
以下のようなgensdf.pyを作成しました。
[chiyama@docker HTCondor]$ cat gensdf.py
import os
import sys
tmpl = '''
executable = /bin/sh
output = /home/chiyama/Documents/HTCondor/log/%(prfx)s.out
error = /home/chiyama/Documents/HTCondor/log/%(prfx)s.err
log = /home/chiyama/Documents/HTCondor/log/%(prfx)s.log
arguments = /home/chiyama/mayapy.sh /home/chiyama/Documents/HTCondor/maya2abc.py %(src)s %(dest)s
initialdir = /home/chiyama/Documents/HTCondor
requirements = TARGET.OpSys == "LINUX" && TARGET.FileSystemDomain == "XXX.XXX.XXX" && TARGET.UidDomain == "XXX.XXX.XXX" && TARGET.Machine == "docker.XXX.XXX.XXX"
should_transfer_files = no
queue
'''
def gensdf(src_dir, dest_dir, fname):
prfx, ext = os.path.splitext(fname)
src = os.path.join(src_dir, fname)
dest = os.path.join(dest_dir, '%s.abc' % prfx)
return tmpl % {'prfx' : prfx,
'src' : src,
'dest' : dest}
if __name__ == '__main__':
src_dir = os.path.abspath(sys.argv[1])
dest_dir = os.path.join(os.path.dirname(src_dir), 'abc')
sdf = sys.argv[2]
fp = open(sdf, 'w')
for f in os.listdir(src_dir):
fp.write(gensdf(src_dir, dest_dir, f))
fp.close()
[chiyama@docker HTCondor]$
sdfファイルには複数のジョブ情報を記述できるので、ひとつのファイルにまとめて全ての情報を記述しています。こうすることでcondor_submitを一度実行するだけで全てのジョブを投入することができます。
このスクリプトはMayaシーンファイルの置かれているディレクトリを第一引数に、生成するsdfファイルのパスを第二引数にとって実行するので、そのように実行してみます。
[chiyama@docker HTCondor]$ python gensdf.py mb maya2abc.sdf
maya2abc.sdfができるので中を見てみます。
----
executable = /bin/sh
output = /home/chiyama/Documents/HTCondor/log/PappyTruck.out
error = /home/chiyama/Documents/HTCondor/log/PappyTruck.err
log = /home/chiyama/Documents/HTCondor/log/PappyTruck.log
arguments = /home/chiyama/mayapy.sh /home/chiyama/Documents/HTCondor/maya2abc.py /home/chiyama/Documents/HTCondor/mb/PappyTruck.mb /home/chiyama/Documents/HTCondor/abc/PappyTruck.abc
initialdir = /home/chiyama/Documents/HTCondor
requirements = TARGET.OpSys == "LINUX" && TARGET.FileSystemDomain == "XXX.XXX.XXX" && TARGET.UidDomain == "XXX.XXX.XXX" && TARGET.Machine == "docker.XXX.XXX.XXX"
should_transfer_files = no
queue
executable = /bin/sh
output = /home/chiyama/Documents/HTCondor/log/ActingStage.out
error = /home/chiyama/Documents/HTCondor/log/ActingStage.err
log = /home/chiyama/Documents/HTCondor/log/ActingStage.log
arguments = /home/chiyama/mayapy.sh /home/chiyama/Documents/HTCondor/maya2abc.py /home/chiyama/Documents/HTCondor/mb/ActingStage.mb /home/chiyama/Documents/HTCondor/abc/ActingStage.abc
initialdir = /home/chiyama/Documents/HTCondor
requirements = TARGET.OpSys == "LINUX" && TARGET.FileSystemDomain == "XXX.XXX.XXX" && TARGET.UidDomain == "XXX.XXX.XXX" && TARGET.Machine == "docker.XXX.XXX.XXX"
should_transfer_files = no
queue
executable = /bin/sh
output = /home/chiyama/Documents/HTCondor/log/ParkEntrance_PayStation.out
error = /home/chiyama/Documents/HTCondor/log/ParkEntrance_PayStation.err
log = /home/chiyama/Documents/HTCondor/log/ParkEntrance_PayStation.log
(以下略)
----
これで準備ができました。ジョブを投入してみます。
[chiyama@docker HTCondor]$ condor_submit maya2abc.sdf
Submitting job(s).......................................................................................................
103 job(s) submitted to cluster 21.
[chiyama@docker HTCondor]$
ジョブの投入は一瞬でおわります。condor_statusやcondor_qを使用して状況を確認します。
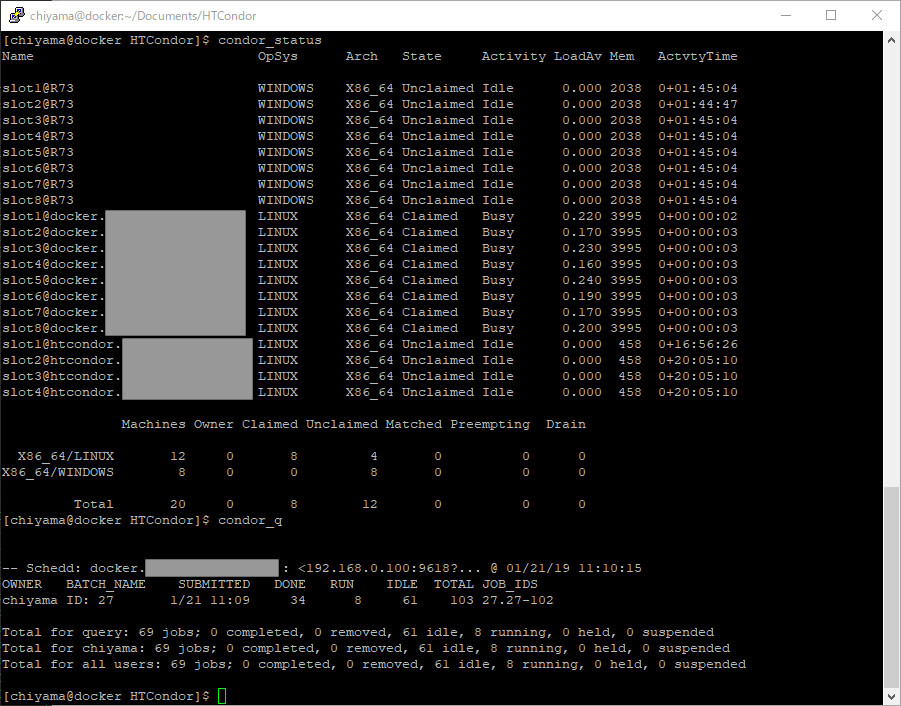
8つの処理が並列して行われており、2分ほどで全ファイルの処理が完了しました。ログはlogディレクトリ以下にファイルごとに出力されています。
GUIから103個のジョブを投入するとなるとめんどくさくて手元のマシンで済ませようかなと考えてしまいますが、このようにジョブファイルを生成して投入する方法ならどれだけファイルが多くても苦にならないです。
また、並列処理を行うことでマルチコアで動作させる恩恵を手軽に受けることができます。これはとても強力で、例えば8つの処理を同時に行えば単純なスクリプトを走らせると8時間かかる処理が1時間で終わることになります。一日がかりの処理が昼休みに終わるものになってしまうということです。
次回予告
condor_statusやcondor_qは十分な機能を備えていますし、ジョブの実行中に出力されるログファイルを見れば必要な情報を確認することはできるのですが、やっぱりもうちょっと手軽にわかりやすく管理できる画面はほしいです。そこで、次回はHTCondorの管理を行うための環境をつくっていきます。
第10回の公開は、2019年3月を予定しております。
プロフィール