本連載では、アカデミックの世界に属してCG・映像関連の研究に携わる人々の姿をインダストリーの世界に属する人々に紹介していく。第16回では、CV(コンピュータビジョン)やCGをメインテーマとし、近年は着衣人物写真の高精度な3DCG化などに取り組んでいる早稲田大学の森島繁生教授に自身の研究室について語っていただいた。
※本記事は月刊『CGWORLD + digital video』vol. 256(2019年12月号)掲載の「ACADEMIC meets INDUSTRY 早稲田大学 先進理工学部 応用物理学科 森島研究室」を再編集したものです。

TEXT_森島繁生 / Shigeo Morishima(早稲田大学)
EDIT_尾形美幸 / Miyuki Ogata(CGWORLD)
取材協力_芸術科学会
生涯、井の中の蛙
早稲田大学の森島繁生です。東京大学で博士課程を修了し、その直後の1987年から成蹊大学で研究室を運営した後、2004年に現職に就きました。通算すれば大学教員生活は32年になります。大学から一歩も外に出ておらず、このまま定年まで社会の荒波に揉まれることのない井の中の蛙として生涯を終えそうです。
-

-
森島繁生
早稲田大学 先進理工学部 応用物理学科 教授
工学博士
専門分野:知的インターフェイス、CG、コンピュータビジョン、画像処理、音声信号処理
www.mlab.phys.waseda.ac.jp
博士論文のテーマはAIアプローチでの音声認識でしたが、卒業後に知的画像通信の研究に従事し、狭帯域の通信路で人物の表情や動作を伝送して自然な会話を可能にすることに興味をもち、分析と合成を組み合わせたアバターの顔を介して対話するシステムを実現しました。その後、光ファイバーの普及で伝送帯域は拡がり、送信側の画像認識と受信側の画像合成が、CV(コンピュータビジョン)およびCGというかたちで独立し、森島研究室[1]のメインテーマになっていったという経緯があります。もともと音は専門なので、音声や音響信号処理の研究は標準で付いて来るという感じです。
[1]Webナショジオ 研究室に行ってみた。natgeo.nikkeibp.co.jp/atcl/web/18/080100014
2005年の愛・地球博では、顔CG合成の研究成果を応用するかたちで三井・東芝館の『Future Cast』の開発に本研究室の学生と共に携わり、164万人の来場者に感動体験をお届けし、人物の表情合成技術がエンターテインメントに及ぼす影響に関して多くの知見を得ることができました。これはその後ハウステンボスの『Future Cast Theater』に引き継がれ、2017年の閉館までに6万5千回以上の上映を行うという記録の樹立につながったことは記憶に新しいところです。

▲顔CG合成の研究成果を応用した『Future Cast』
SIGGRAPHデビュー時のインパクト
私のSIGGRAPHデビューはバブル景気の余韻が残る1994年(オーランド)です。当時は多い年には5万人近い参加者があり、日本からも多くの企業がExhibitionに参加していました。私はその規模に圧倒され、ここが自分のいるべき場所だと実感しました。最初の大きな貢献は、1995年に採択された『Better Face Communication』でした。これは本人そっくりのアバターを介して、遠隔地にいる人同士が音声のみの伝送で疑似TV電話をリアルタイムに体験できるというもので、音声のみからFake Videoを自動的に実時間で生成することに取り組んでいました。今のDeepfakeを使えばいとも簡単な話ですが、当時の計算機パワーでは考えられないことで、会期中はSIGGRAPHから無償で貸し出されたSGI Onyxを使用しました。また、NHKの特別番組の取材を受けたりもしました。
以来、SIGGRAPHには、Poster、Talk(Sketch)、E-Tech、Course、Technical Briefなどで毎年欠かさず貢献してきました。そして2015年にSIGGRAPH Asiaが神戸で開催されたとき、Workshop / Co-located Event Chairを仰せつかりました。また、その頃から本研究室のOBや現役学生の論文がTechnical Paperで採択されるようになり、やっと一人前の研究室になったのかなと実感しています。2018年の夏頃からはSIGGRAPH、CHI、CVPR、PG、ICCVなどのトップカンファレンスにフルペーパーが立て続けに採択され、1年の間に世界の最高峰を軒並み制覇するかのごとく業績を積み上げています。CVPRでBest Paper Award Finalistsにノミネートされた学生もおり、彼らの活躍は止まるところを知らず加速を続けている状態です。
2018年以降の代表的な研究成果

▲1枚の画像から顔の3次元形状、アルベド、スペキュラ、ディスプレイスメントを推定し、新たな照明環境下で再合成した結果。極端に横向きの画像でオクルージョンが発生していても、穴埋めしてそれらしくテクスチャが復元されます。カメラアングル、照明環境、表情などに左右されない確固とした推定が可能です[2]
[2]Shugo Yamaguchi, Shunsuke Saito, Koki Nagano, Yajie Zhao, Weikai Chen, Shigeo Morishima, Hao Li, "High-Fidelity Facial Reflectance and Geometry Inference from an Unconstrained Image", ACM Transactions on Graphics(Proc. SIGGRAPH 2018), Vol. 37, Issue 4, No. 162, 2018

▲音楽と歌唱の波形データから、歌手の個性ある歌い回しを自動合成します。首の回転、瞬き、表情、リップシンクを曲に合わせて自動的に制御可能。すでに故人となった歌手の個性を過去の楽曲ビデオデータから学習し、CG合成した本人のキャラクターに個性豊かに新曲を歌わせることができます[3]
[3]歌声と楽曲構造を入力とした歌唱時の表情アニメーション自動生成手法, 加藤卓哉, 深山 覚, 中野倫靖, 後藤真孝, 森島繁生, 画像電子学誌 第48巻 第2号(通巻248号), pp. 303-314, 2019
[[SplitPage]]
多くの博士を抱える、研究室体制
本研究室は応用物理学科に属しており、高校時代に宇宙や量子などに興味をもった学生が入学してきます。そして入学から研究室配属までの期間に、徹底的に物理の専門科目と数学を叩き込まれます。これが学生たちの大きなアドバンテージになっていると私は考えます。数学や物理の知識が豊富な人は、様々な応用分野でつぶしがききます。学部の3年生になり、自分の将来を考えたとき、ピュアな理学的な業績のみでは就職の選択肢が狭まるのではないかという不安を潜在的に感じ始め、本研究室を知って未来が開けるというわけです。そのため本研究室には、毎年定員を超える志願者が集まります。そこからの選抜では本研究室の全学生がリクルーターとして面接官を担当し、評価することを恒例行事としています。
2021年5月現在、本研究室は学部生8名、修士12名、博士9名で構成されています。特徴的なのは、博士8名が修士からの純粋培養で、日本人という点です。現在のスタッフは私と助手を兼任している博士学生3名がおります。成蹊大学時代も含めた約30年間を通して、本研究室の博士号取得者の総計が11名なのに対し、現在は在籍者だけで9名もいます。さらに修士から博士への進学を目指す人も増加傾向にあり、他大学からの配属者も1名います。世の中のながれとしては、博士進学者は減少傾向にあり、中国をはじめとする海外からの進学者が大勢を占める状況ですが、これに逆行するかたちで安定した博士進学者数をキープしています。これには、先輩たちの積み上げてきた業績や活躍に加え、博士号取得後の様々な人生の道筋を目の当たりにできる環境も大きく影響していると考えています。就職先も、AIベンチャー、産総研、外資IT企業、大学教員と多彩です。
また、学生に海外で活躍する機会を与えたいというのは私の生涯の夢であり、その実現に向けて長年努力を続け、内外の関係協力機関のバックアップ体制を確立してきました。その結果、単なる日本からの客人という地位に止まらない、強力な助人として受け入れ側から高く評価され、プロジェクトのコアメンバーや、論文の筆頭著者を担う学生が増えている点も、博士進学の動機を高める要因になっていると考えられます。このような環境の中、留学した以上は必ずトップカンファレンスに論文を通すのだという学生の高い意識が、実績という形でリアルに具現化しはじめているのが現状です。このポジティブなサイクルを継続するためには、研究室をけん引する者としての努力が不可欠です。長期の出張を支える潤沢な予算の獲得、優秀な学生の誘致、共同研究機関との綿密な連携とネゴシエーション、卒業生を幸福に導く進路指導、軽快なフットワークによる対外交渉などが私の主な役割だと実感しています。
研究テーマは自力で見つける
研究ディスカッションは現在3つのチームに分かれて実施しています。Face / CVチーム、Media / Interaction / Contentsチーム、Rendering / Simulationチームです。各チームには博士から学部生までがほぼ均等に配属されており、縦の密な構造が存在しています。どのグループでも、もはや深層学習はデフォルトの技術になっています。CG系の研究テーマでSIGGRAPH、EG、PG、MIG、SCAなどでの発表を目指す者だけでなく、CV関連でCVPR、ICCV、ECCV、インタラクション関連でCHI、UIST、VR関連でIEEE VR、VRST、音楽関連でISMIR、ICASSPなど、多種多様な研究テーマを遂行しています。
学部3年生の1月に本研究室への配属が決まると、2ヶ月の基礎トレーニング期間を経て、3月の春合宿で各チームのリクルーティングが行われ、どのチームに属するかが決まります。研究テーマは、基本的に自分のやりたいことを自力で見つけます。まずは関連研究調査を徹底的に行い、自分が描く研究テーマの新規性を見出して目標を定めていく作業から始まります。「このテーマをやれ」という指示は、どこからも出ません。先輩との連携は綿密で、原稿の推敲は言うに及ばず、ときにはチームを越えて投稿時のデモ映像作成やモデリングなどをサポートしたり、締め切りに向けて一緒に泊まり込んで議論したりするなどして、レベルアップを図っていきます。毎月1回の全員参加のミーティングでは、時間をたっぷり確保して、学部生全員が研究室の全メンバーの前で発表し、ほかのチームの先輩たちからの鋭い質問を浴びるという洗礼を受けます。このようなプロセスを経て、学部生たちはプレゼンのスキルや研究に対する姿勢を学び、知らず知らずのうちに自信をつけていきます。
論文につながる共同研究を推奨
海外や国内の共同研究先には誰でも行けるわけではありません。しかるべきスキルや能力、実績があると判断され、受け入れ側から了解を得られた人のみに与えられる特権です。また企業からの共同研究の受け入れに関しても、既存研究の追実装で解決できるような内容ではなく、その成果を学術発表できる可能性のある内容に限っています。インターンを行う学生は毎年数名いますが、数日たらずの意義の薄いものではなく、インターンの成果が論文につながるような受け入れ先を推奨しています。2019年度からのおよそ1年間で、USC、CMU、UCLA、Edinburgh、Northumbria、Mannheimに3ヶ月から半年の滞在で、計8名の学生を留学させており、そこから大きな成果が生まれています。また、このうち2名は修士1年の段階で留学を経験し、3ヶ月という短期間で研究を立ち上げ、論文を作成し、トップカンファレンスに採択されるスピード実績を残しています。
もちろん、現在はコロナ禍にあり、海外への留学はすべてキャンセルとなってしまいましたが、オンラインでコラボレーションは継続しており、効率という面ではむしろ論文の投稿数・採択数は伸びていると思います。ただ、海外の様々な土地に学生が赴き、登壇発表したり、懇親会で議論したり、現地の文化を享受するという機会を得ることも重要な要素だったので、学生たちにとっては残念なことであります。
2018年以降の代表的な研究成果

▲周囲の歩行者の検出及び将来位置の予測結果から歩行者がユーザー(視覚障害者)と衝突する危険性を予測し、危険性のある歩行者に対して警告音を鳴らします。警告音を聞いた歩行者がユーザーの存在を認識しユーザーに道を譲ることで、歩行者と衝突しない安全な進路をユーザーに提供することが可能となります[4]
[4]Seita Kayukawa, Keita Higuchi, João Guerreiro, Shigeo Morishima, Yoichi Sato, Kris Kitani, Chieko Asakawa, "BBeep: A Sonic Collision Avoidance System for Blind Travellers and Nearby Pedestrians", ACM Conference on Human Factors in Computing Systems(CHI'19), 2019

▲2枚の画像のみから深層学習によって顔の入れ替え、髪型の入れ替えを画像処理で実現しました。属性を指定することによって、頭髪の色や性別、髭、表情を制御できます。3Dモデルを介することなく、顔の向きの制御も可能[5]
[5]Ryota Natsume, Tatsuya Yatagawa, Shigeo Morishima, "FSNet: An Identity-aware Generative Model for Image-based Face Swapping", Asian Conference of Computer Vision 2018, ACCV (6) 2018: 117-132, 2018
今後の10年でどう変わるのか
深層学習が話題になった後、あっという間に世の中に浸透し、今や深層学習なしにはCGもCVも語れない時代になっています。もちろん論文を通すことは学生が最優先すべき実績ですが、物事をやり遂げたときの達成感、学問としての深みという点で、何とも軽薄・短小な時代に突入しているなと感じます。もちろんこれまでの30年間に取り組んできた多くの未解決の研究テーマの課題が、この2、3年で質の高いデータさえ揃えればいとも簡単に解決されている事実を目の当たりにすれば、その意義や重要性を認知せざるをえません。けれどもFake Videoが容易になればなるほど、プライバシーを侵害せずにビッグデータを確保できる技術も重要になります。手作業のみでつくり込まれた作品により深い感動を憶えてしまうように、人間は表層的なものには飽き足らず、真の感動を求めていくものだとも思います。
深層学習でも解明できない感性の深みを表現したり、解明したりすることが、今後のアカデミックの役割になるのではと感じています。そうなれば、それっぽいCGの時代は終わりを告げ、真に深く心に染み渡るCG表現の具現化が課題となるでしょう。今後の10年でどう変わるのか、どう変えられるのか楽しみではあります。
[[SplitPage]]
RESEARCH 1:層状面光源を用いたボリュームの実時間間接照明法
・研究目的、背景
今日のゲームやVRに代表されるリアルタイムアプリケーション(以下、実時間アプリ)において、爆発や煙の表現はCG映像の写実性を向上する上で非常に重要な要素です。そのため、これらボリュームを高速かつ写実的に描画するための研究が数多くなされてきました。しかし、多くの既存研究はカメラから直接見えるボリュームの描画にのみ着目しており、爆発などの発光するボリュームのほかの物体表面に対する間接照明(映り込み)に関しては実用レベルで機能する技術が考案されていません。これはボリュームの間接照明の実現には、ボリューム内での複雑な光伝達の実時間での計算が求められることに起因しています。今日の実時間アプリでは、物理的に正確な表現には限界があるため、あらかじめ計算されたテクスチャを用いるなどの手法がとられています。
これらの問題に対処すべく、本研究ではボリュームの間接照明を実時間で描画する方法を開発しました[1]。本技術の特長は、任意のラフネス(粗さ)や形状をもった物体表面への映り込みを高速に描画できる汎用性にあり、幅広い分野での応用が期待できます。
・主な先行研究
前述したように爆発や煙の表現に関しては、その需要の高さから様々な技術が確立されています。例えば一般的な手法として、仮想的な光子(photon)をボリューム内に散布し、それら光子の寄与を累積するVolumetric Photon Mapping[2]があります。本手法はボリュームの映り込みも含めた写実的な画像生成が可能ですが、描画時間が長くなる傾向にあり、実時間アプリでの運用が困難です。
一方、実時間での描画を実現する手法として、シーン内を細かいグリッド状に分割し、それらグリッド内での光伝達を近似的に計算するLight Propagation Volume[3]があります。しかし、本手法はカメラから直接見えるボリュームの描画を重視しており、これらボリュームの映り込みを正確に評価できません。ほかにも、カメラから出射した光線(レイ)上の輝度を累積していくRay Marching[4]という手法がありますが、鏡面での映り込みの描画のみが可能で、任意のラフネスをもった物体表面への映り込みは描画できません。以上の理由により、既存の技術では、実時間かつ映り込みの対象を選ばない、ボリュームの間接照明の実現は困難でした。
・研究方法
写実的な爆発や煙の映り込みを表現するためには、ボリューム全体からの放射光が映り込みの起こる場所にどれだけ入射するかを正しく評価する必要があります。このときの計算を最も単純な方法で行うなら、ボリュームを無数の細かい点光源の集合だと考え、これら点光源からの寄与をボリュームの存在する領域上で体積積分する方法が考えられます。しかし、この積分を正しく評価するにはボリューム内での複雑な光伝達を考慮する必要があるため、最新のハードウェアを用いても実時間で計算することは非常に困難です。
そこで本研究では、ボリュームをある角度で切断すると、その切断面が面光源として扱えることに注目しました。この考えに基づくと、互いに平行な面光源が幾重にも積層したもの(層状面光源)としてボリュームを解釈することが可能です。本技術では、層状面光源から映り込みの起こる場所に到達する放射光を解析的に計算することで、非常に高速な描画を可能にしました。


▲床面、壁面、カーテンなど、性質のちがう様々な物体が存在するシーンにおける描画結果。本技術は、【上】爆発のような自己発光するボリュームだけでなく、【下】煙のような外部光源によって照らされたボリュームにも適用できます。また、【上】【下】の下段の拡大図にあるように、曲面を有するカーテンや、ラフネスの高い床面への映り込みも計算できます

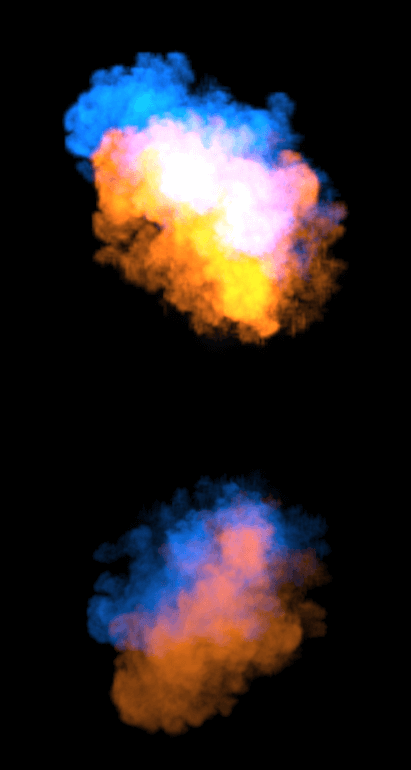
-
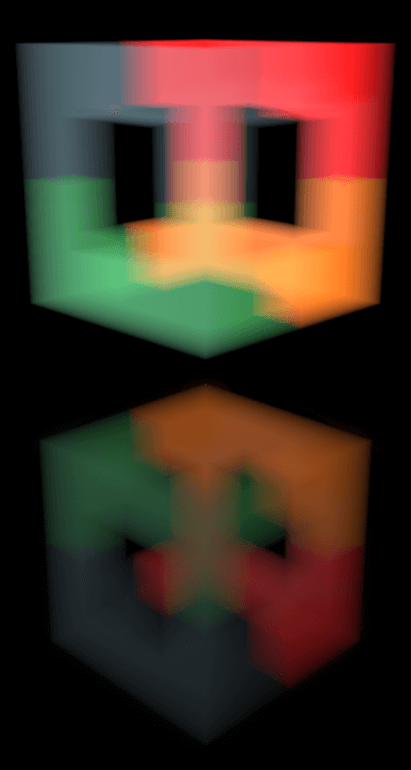
- ◀▲様々な状態のボリュームが、ラフネスの低い床面(鏡面)に映り込んでいるシーンにおける描画結果。【左上】爆発の手前に球体の煙(ボリューム)があり、これによる映り込みの遮蔽も考慮されています/【右上】赤い爆発と青い爆発が同時に存在しており、複数の爆発(ボリューム)が合わさった状態の映り込みも考慮されています/【下】ボリューム内に空洞がありますが、このような形状の映り込みも描画できます。以上のように、本技術はボリュームの個数や形状を問わず、正確な映り込みを描画できます
・研究の新規性
本研究の最たる新規性は、ボリュームを層状面光源と捉える新解釈にあります。実際の計算では、ある程度間隔を置いて離散的にボリュームを切断し、隣り合う2枚の切断面(面光源)に挟まれた小領域ごとに放射光の大きさを評価します。そして、これら小領域から映り込みの場所に到達する入射光を逐次的に足していくことで、ボリューム全体からの入射光を近似的に計算します。
さらに本研究では、厚みのある小領域から映り込みの起こる場所に到達する入射光の強さを、解析的に評価できる関数として求められることも発見しました。画像生成時にはこの関数を評価するだけで映り込み点の明るさを計算できるため、非常に高速かつ安定したパフォーマンスを発揮します。加えて、本技術は任意のラフネス・形状をもつ物体表面への映り込みを描画することも可能で、従来の技術では獲得しえなかった高い汎用性を有しています。
・実用の可能性、今後の課題
爆発や煙の表現は今日の実時間アプリでは決して珍しくないので、それらの高精細な映り込みを実現する本研究の需要は非常に高いと言えます。特に、その描画速度や映り込み対象を選ばない汎用性から、ゲームやVRなどでの活用がおおいに期待できます。加えて、提案手法のシンプルさに起因する実装の容易さは、本技術が様々な制作現場において大きな障害なく導入できることを意味しています。また、実際にユーザーが本技術を利用する際は、ボリュームの分割数を変更することで描画の品質と時間を調整できる点も非常に有用です。ユーザーが使用するハードウェアの性能に合わせて描画の品質と時間を調整できるため、ユーザーの望むパフォーマンスをストレスフリーに実現することが可能です。
今後の課題としては、本技術をより一般的なボリュームの間接照明へと拡張することが挙げられます。現時点では、爆発や煙といった気体状のボリュームの間接照明にのみ対応可能です。したがって、半透明物体などの固体状のボリュームの間接照明に拡張することが、大きな課題のひとつと言えます。
・参考文献
[1]Takahiro Kuge, Tatsuya Yatagawa, Shigeo Morishima, "Real-time Indirect Illumination of Emissive Inhomogeneous Volumes using Layered Polygonal Area Lights", Pacific Graphics, 2019
[2]Henrik Wann Jensen et al., "Efficient simulation of light transport in scenes with participating media using photon maps", ACM SIGGRAPH, 1998
[3]Anton Kaplanyan et al., "Cascaded light propagation volumes for real-time indirect illumination", ACM SIGGRAPH, 2010
[4]Ken Perlin et al., "Hypertexture", ACM SIGGRAPH, 1989
次ページ:
PlFuを用いた着衣人物写真の高精度な3DCG化
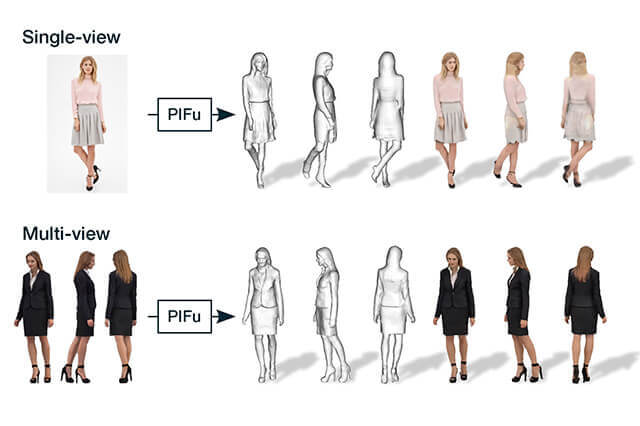
RESEARCH 2:PlFuを用いた着衣人物写真の高精度な3DCG化
・研究目的、背景
近年、拡張現実(AR)や仮想現実(VR)などの没入型の映像体験が流行していますが、それらの映像に必要な3DCGコンテンツを制作するためには、現実世界の3次元物体をデジタル化する必要があります。着衣人物の3DCG化の場合は、何十台ものカメラを用いた緻密なスキャン装置や、非常に複雑な長時間の撮影作業が必要となります。
もし、着衣人物の写真を1枚撮影するだけで、それを3DCG化できるなら、従来の高コストなキャプチャ技術は不要となります。実は人間の顔や体型に限れば、テンプレートモデルと深層学習を組み合わせることで、比較的正確な3次元形状の復元が可能となってきています。一方で、3DCG分野での深層学習の発達により、テンプレートモデルを用いずに3次元形状を復元する手法も提案されています。しかし、2次元情報よりも多くのメモリ容量を必要とする3次元情報を効率良く表現する手法は確立されておらず、深層学習を用いた3次元形状の復元における解像度や精度には限界がありました。
そこで本研究では、Pixel-Aligned Implicit Function(PIFu)と名付けた3次元情報の新しい表現方法を提案し、1枚または複数枚の画像から着衣人物の3次元形状とテクスチャを高精度かつ効率的に復元する手法を開発しました[1]。
・主な先行研究
2次元の画像処理のタスクに深層学習を適用する場合は、Fully Convolutional Networkの入力と出力の空間的な位置情報を維持できる特性が多用されます。一方で、3次元情報を扱うタスクへの、Fully Convolutional Networkの応用には課題が残されていました。Fully Convolutional Networkをボクセルで表現された3次元形状に適用することは可能ですが、3次元空間中の全ての点を同時に扱う必要があり、GPUメモリの消費量が高くなるという問題があるため、高解像度でのシワやヒールなどの詳細情報を含めた復元は困難でした。
ほかにも、画像からグローバルな特徴量を抽出することで、ボクセル表現よりもメモリを効率的に使う手法が提案されていますが、入力画像の詳細情報の保持が難しいという課題が残されていました。Implicit Functionを用いて、画像から3次元形状を復元する手法も提案されていますが、入力画像の空間的な位置情報を上手く利用できていないという欠点がありました。
・研究方法
PIFuではFully Convolutional Networkを用いて、入力画像の各ピクセルごとに空間的な位置情報を保った局所特徴量を抽出します。続いて、3次元空間中の各点に対応する局所特徴量をImplicit Functionに入力していくことで、全体の形状を復元します。この提案手法は、ボクセル表現とは異なり、全ての点を同時に処理する必要がないため、多くのメモリ容量を使わずに、高解像度の3次元情報を扱うことが可能です。入力画像の情報を最大限に活用し、各点に対して独立した処理を行うことで、様々な形状の、詳細情報を含む着衣人物の復元が可能となりました。

▲入力画像を与えると、PIFuは、3次元形状の内部か外部かを判定する連続的な確率場を予測します。Tex-PIFuは、復元された3DCGモデルの各面に対して、RGB値を推定するために用いられます
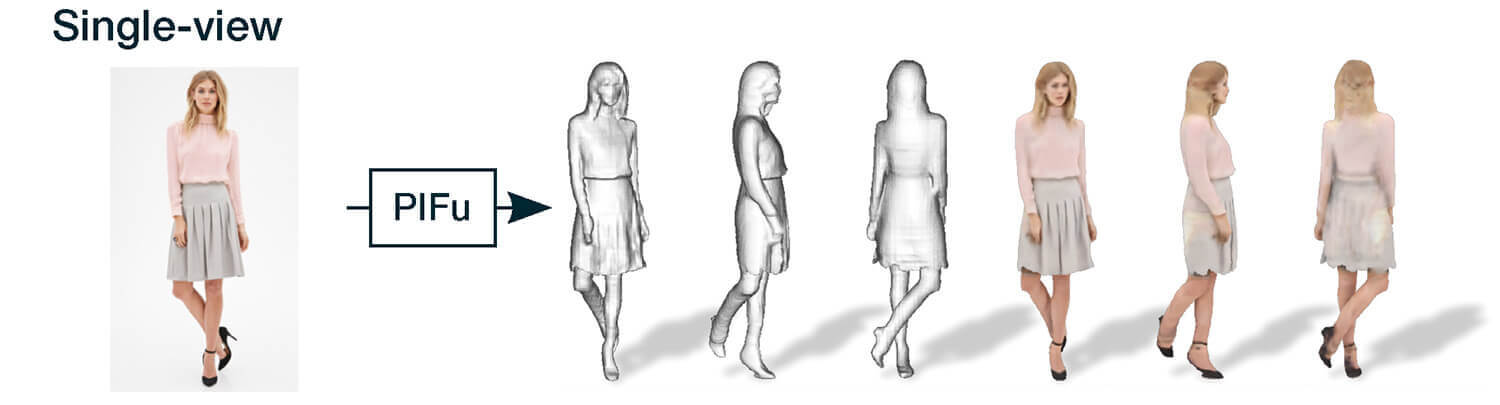

▲【上】PIFuによって、1枚の入力画像から、着衣人物の3次元形状とテクスチャを高精度かつ効率的に復元しました。本研究の提案手法は様々な形状に対応でき、画像に写っていない背面領域の復元も可能です/【下】本提案手法は、同時に撮影された複数枚の画像に適用することもでき、より詳細な情報の復元が可能となります
・研究の新規性
本研究の提案手法では、まずイメージエンコーダを用いて、入力画像の各ピクセルの位置情報に基づくグローバルなコンテキストと、隣接ピクセルとの関係性を考慮した特徴量を抽出するように学習します。続いて、あるピクセルに特徴量ベクトルとZ深度を適用したときに、このz深度が3次元形状の内部か外部かを判定するためのImplicit Functionを学習します。このように、各ピクセルに空間的な位置情報を保持した特徴量ベクトルを適用することで、入力画像の局所的な詳細情報を保ちつつ、見えない背面領域のもっともらしい形状の推定も可能にしています。また、提案手法では、同時に撮影された複数枚の画像を入力することもでき、入力画像が1枚の場合よりも詳細な情報の復元も可能です。PIFuが3次元形状の内部か外部かを判定する代わりに、RGBを値の推定に用いることで、テクスチャの高精度な復元も実現しました。
・実用の可能性、今後の課題
本研究を応用すれば、ARやVRなどの没入型の映像体験に用いる3DCGモデルを、スマホ1台で誰でも簡単に作成できることが期待されます。そうなればゲームやビデオチャットなどにユーザー自身が登場できるため、体験の幅が大きく向上すると考えらえれます。しかし、本研究によって復元された3DCGモデルにはリグ情報が入っておらず、すぐにモーションを付けられないことが現状の問題点です。そのため、今後の課題のひとつとして、復元や後処理工程の中にリグ情報の組み込みを加えることが挙げられます。
また、ほかの応用先として、3DCGモデル制作によるクリエイター支援が考えられます。クオリティの高いプロダクト用の3DCGモデルをイチから制作すると、多くのコストが発生します。本研究を用いることで、そのコストの軽減が期待できます。本研究の復元結果の形状やテクスチャの質は、クリエイターが手作業で制作した3DCGモデルに比べると劣る場合があります。しかし、PIFuは入力画像に忠実な復元を行うため、これを初期値として、クリエイターが編集していくことで、制作コストを大きく軽減することが可能だと考えられます。
さらに、PIFuを用いて復元されたテクスチャは解像度が低いということも現状の問題点です。そこで、Generative Adversarial Networkを用いることで、高解像度のテクスチャ復元も可能にするといった拡張も考えられます。
・参考文献
[1]Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Morishima, Angjoo Kanazawa, Hao Li, "PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization", ICCV, 2019
info.
-

-
月刊CGWORLD + digital video vol.256(2019年12月号)
第1特集:今気になる、男性アイドル
第2特集:CGエフェクト再考
定価:1,540円(税込)
判型:A4ワイド
総ページ数:144
発売日:2019年11月9日
cgworld.jp/magazine/cgw256.html













