RESEARCH 2:PlFuを用いた着衣人物写真の高精度な3DCG化
・研究目的、背景
近年、拡張現実(AR)や仮想現実(VR)などの没入型の映像体験が流行していますが、それらの映像に必要な3DCGコンテンツを制作するためには、現実世界の3次元物体をデジタル化する必要があります。着衣人物の3DCG化の場合は、何十台ものカメラを用いた緻密なスキャン装置や、非常に複雑な長時間の撮影作業が必要となります。
もし、着衣人物の写真を1枚撮影するだけで、それを3DCG化できるなら、従来の高コストなキャプチャ技術は不要となります。実は人間の顔や体型に限れば、テンプレートモデルと深層学習を組み合わせることで、比較的正確な3次元形状の復元が可能となってきています。一方で、3DCG分野での深層学習の発達により、テンプレートモデルを用いずに3次元形状を復元する手法も提案されています。しかし、2次元情報よりも多くのメモリ容量を必要とする3次元情報を効率良く表現する手法は確立されておらず、深層学習を用いた3次元形状の復元における解像度や精度には限界がありました。
そこで本研究では、Pixel-Aligned Implicit Function(PIFu)と名付けた3次元情報の新しい表現方法を提案し、1枚または複数枚の画像から着衣人物の3次元形状とテクスチャを高精度かつ効率的に復元する手法を開発しました[1]。
・主な先行研究
2次元の画像処理のタスクに深層学習を適用する場合は、Fully Convolutional Networkの入力と出力の空間的な位置情報を維持できる特性が多用されます。一方で、3次元情報を扱うタスクへの、Fully Convolutional Networkの応用には課題が残されていました。Fully Convolutional Networkをボクセルで表現された3次元形状に適用することは可能ですが、3次元空間中の全ての点を同時に扱う必要があり、GPUメモリの消費量が高くなるという問題があるため、高解像度でのシワやヒールなどの詳細情報を含めた復元は困難でした。
ほかにも、画像からグローバルな特徴量を抽出することで、ボクセル表現よりもメモリを効率的に使う手法が提案されていますが、入力画像の詳細情報の保持が難しいという課題が残されていました。Implicit Functionを用いて、画像から3次元形状を復元する手法も提案されていますが、入力画像の空間的な位置情報を上手く利用できていないという欠点がありました。
・研究方法
PIFuではFully Convolutional Networkを用いて、入力画像の各ピクセルごとに空間的な位置情報を保った局所特徴量を抽出します。続いて、3次元空間中の各点に対応する局所特徴量をImplicit Functionに入力していくことで、全体の形状を復元します。この提案手法は、ボクセル表現とは異なり、全ての点を同時に処理する必要がないため、多くのメモリ容量を使わずに、高解像度の3次元情報を扱うことが可能です。入力画像の情報を最大限に活用し、各点に対して独立した処理を行うことで、様々な形状の、詳細情報を含む着衣人物の復元が可能となりました。

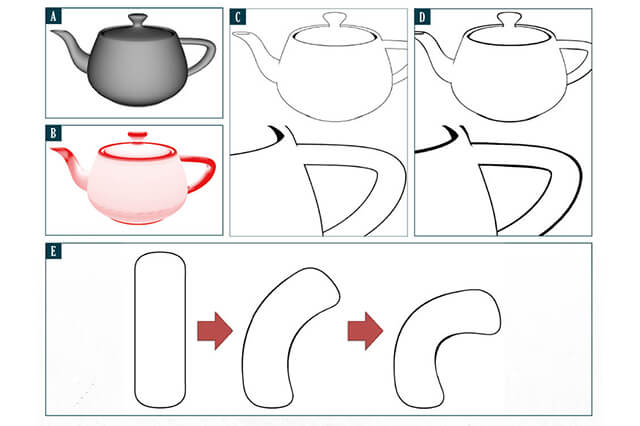
▲入力画像を与えると、PIFuは、3次元形状の内部か外部かを判定する連続的な確率場を予測します。Tex-PIFuは、復元された3DCGモデルの各面に対して、RGB値を推定するために用いられます
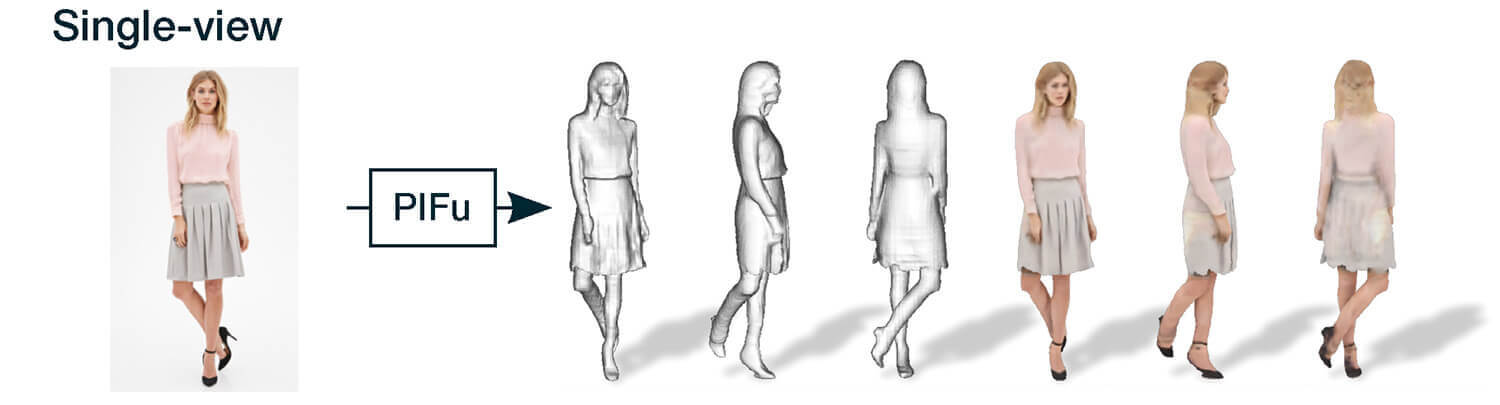

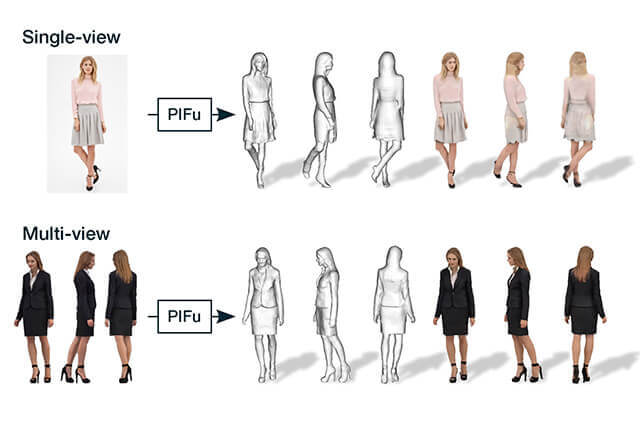
▲【上】PIFuによって、1枚の入力画像から、着衣人物の3次元形状とテクスチャを高精度かつ効率的に復元しました。本研究の提案手法は様々な形状に対応でき、画像に写っていない背面領域の復元も可能です/【下】本提案手法は、同時に撮影された複数枚の画像に適用することもでき、より詳細な情報の復元が可能となります
・研究の新規性
本研究の提案手法では、まずイメージエンコーダを用いて、入力画像の各ピクセルの位置情報に基づくグローバルなコンテキストと、隣接ピクセルとの関係性を考慮した特徴量を抽出するように学習します。続いて、あるピクセルに特徴量ベクトルとZ深度を適用したときに、このz深度が3次元形状の内部か外部かを判定するためのImplicit Functionを学習します。このように、各ピクセルに空間的な位置情報を保持した特徴量ベクトルを適用することで、入力画像の局所的な詳細情報を保ちつつ、見えない背面領域のもっともらしい形状の推定も可能にしています。また、提案手法では、同時に撮影された複数枚の画像を入力することもでき、入力画像が1枚の場合よりも詳細な情報の復元も可能です。PIFuが3次元形状の内部か外部かを判定する代わりに、RGBを値の推定に用いることで、テクスチャの高精度な復元も実現しました。
・実用の可能性、今後の課題
本研究を応用すれば、ARやVRなどの没入型の映像体験に用いる3DCGモデルを、スマホ1台で誰でも簡単に作成できることが期待されます。そうなればゲームやビデオチャットなどにユーザー自身が登場できるため、体験の幅が大きく向上すると考えらえれます。しかし、本研究によって復元された3DCGモデルにはリグ情報が入っておらず、すぐにモーションを付けられないことが現状の問題点です。そのため、今後の課題のひとつとして、復元や後処理工程の中にリグ情報の組み込みを加えることが挙げられます。
また、ほかの応用先として、3DCGモデル制作によるクリエイター支援が考えられます。クオリティの高いプロダクト用の3DCGモデルをイチから制作すると、多くのコストが発生します。本研究を用いることで、そのコストの軽減が期待できます。本研究の復元結果の形状やテクスチャの質は、クリエイターが手作業で制作した3DCGモデルに比べると劣る場合があります。しかし、PIFuは入力画像に忠実な復元を行うため、これを初期値として、クリエイターが編集していくことで、制作コストを大きく軽減することが可能だと考えられます。
さらに、PIFuを用いて復元されたテクスチャは解像度が低いということも現状の問題点です。そこで、Generative Adversarial Networkを用いることで、高解像度のテクスチャ復元も可能にするといった拡張も考えられます。
・参考文献
[1]Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Morishima, Angjoo Kanazawa, Hao Li, "PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization", ICCV, 2019
info.
-

-
月刊CGWORLD + digital video vol.256(2019年12月号)
第1特集:今気になる、男性アイドル
第2特集:CGエフェクト再考
定価:1,540円(税込)
判型:A4ワイド
総ページ数:144
発売日:2019年11月9日
cgworld.jp/magazine/cgw256.html