コンピュータグラフィックスとインタラクティブ技術に関するトップカンファレンスであるSIGGRAPHの分科会SIGGRAPH Asia 2021が2021年12月14日(火)から17日(金)まで開催された。東京都・有楽町にある東京国際フォーラムとオンラインを会場にしたハイブリッド開催となった同カンファレンスに対して270本の論文が提出され、そのうち92本が採択。そのほかには、16のXRプレゼンテーションが配信された。こうした発表のなかからXRとAIに関連した注目論文を9本ほど紹介する。
参考リンク集
技術論文の発表をはじめとしたSIGGRAPH Asia 2021で実施された全プログラムに関しては、以下の公式ページを参照。
https://sa2021.conference-program.com/
注目論文に関するダイジェスト動画も公開されている。
また、非公式ながら技術論文に関する動画やサンプルコードへのリンクを集めた以下のようなWebページもある。
https://kesen.realtimerendering.com/siga2021Papers.htm
<1>AdaptiBrush: Adaptive General and Predictable VR Ribbon Brush
https://www.cs.ubc.ca/labs/imager/tr/2021/AdaptiBrush/
カナダのブリティッシュコロンビア大学の研究チームが発表した本論文は、VRハンドコントローラによる新しい描画システムを提案している。従来のVRハンドコントローラによる3Dオブジェクトの描画では、コントローラの動きから座標情報を算出していたため、複雑な形状のオブジェクトを造形する際には手を不自然な方向に動かす必要があった。提案された新しい描画システムとは、手の動きから描画情報を予測することで、手を不自然に動かさずに複雑な造形を可能とするものである。従来の描画システムと新しいそれを比較する実験を行なったところ、新描画システムのほうが快適だと実証された。今後の研究課題としては、新描画システムを効率的に習得するためのチュートリアルの制作が挙げられる。
<2>Synthesizing Scene-Aware Virtual Reality Teleport Graphs
https://changyangli.github.io/projects/siga21teleport/project.html
アメリカのジョージ・メイソン大学の研究チームが発表した本論文は、VR空間の知覚に最適なテレポート経路を決定する方法を提案している。VR空間内の移動方法のひとつとして、同空間の特定の位置にテレポート(瞬間移動)することがある。こうしたテレポートにおいては、移動場所によってVR空間の把握が困難になることがある。本論文は適切なテレポート位置を特定するために、VR空間内の任意の場所にいる観察者とその周囲の関係を幾何学的情報に変換したシーン・パーセプション・グラフの作成を提案する。
作成された複数のシーン・パーセプション・グラフからVR空間を把握する指標である知覚スコアを算出した後、同スコアを比較して最適なテレポート位置を特定する。最適なテレポート位置をつないでVR空間を適切にナビゲートできる経路が、テレポートグラフと呼ばれる。今後の研究課題として、ユーザーの移動嗜好に合わせてテレポートグラフをカスタマイズすること等が挙げられる。
<3>Dynamic Neural Garments
http://geometry.cs.ucl.ac.uk/projects/2021/DynamicNeuralGarments/
イギリスのユニヴァーシティ・カレッジ・ロンドンとAdobe Researchの研究チームが発表した本論文は、衣服画像の折り目やしわをニューラルネットワークによって素早く描画する方法を提案する。従来の衣服画像における折り目やしわは物理シミュレーションによって算出されていたが、カメラアングルが変わるたびに負荷の高い演算が生じていた。同論文が提案するのは、あらかじめ衣服画像の折り目やしわを学習したニューラルネットワークによって、それらを素早く生成する方法である。この方法を使うと、カメラアングルが変わっても低負荷かつ高速で折り目やしわを再現できる。今後の研究課題として、様々な体型に対応した演算やリアルな影の生成が挙げられる。
<4>Learning to Reconstruct Botanical Trees from Single Images
https://storage.googleapis.com/pirk.io/projects/single_tree_reconstruction/index.html
アメリカのパデュー大学やGoogle Researchの研究チームが発表した本論文は、1枚の樹木画像から樹木の3Dオブジェクトを生成するニューラルネットワークを提案している。従来では単一の方向から撮影された樹木画像から樹木の3Dオブジェクトを生成するのは困難であった。というのも、単一方向から見ただけでは可能な樹木の種類が複数あり得るからである。提案された方法では、3つのニューラルネットワークを使って、以上の問題を解決する。その3つとは以下の通り。
1.樹木画像から樹木マスク画像を生成するネットワーク
2.マスク画像から樹木の種類を特定するネットワーク
3.特定された樹木の種類に合致するように樹木オブジェクトの体積を求めるネットワーク
以上の3つのニューラルネットワークは、背景が複雑な樹木画像からでも樹木の3Dオブジェクトを生成できることが確認された。今後の研究課題として、複数の樹木オブジェクトの生成や葉や枝のような特定の器官オブジェクトの生成が挙げられる。
<5>DeepVecFont: Synthesizing High-quality Vector Fonts via Dual-modality
https://yizhiwang96.github.io/deepvecfont_homepage/
中国の北京大学の研究チームが発表した本論文は、任意の文字フォントからフォントセットを生成するディープラーニングモデルを提案している。提案されたモデルは、以下のような3つのステップを実行して高品質な独自フォントを生成する。
1.(例えばデザイナーが制作した)任意のユニークなフォント文字からラスタ画像とベクター情報に関する特徴を抽出する。
2.ステップ1で抽出した特徴に基づいて、ユニークなデザインのフォントセットを生成する。
3.ステップ2で生成したフォントセットを一般公開されているデータセットを使って品質に関する評価を行う。
以上の3ステップを実行することで、ユニークなデザインで高品質なフォントセットを自動的に生成できるようになった。今後の研究課題として、より精緻かつ芸術的なフォントの生成が挙げられる。
<6>SuperTrack: Motion Tracking for Physically Simulated Characters using Supervised Learning
大手ゲームパブリッシャーUbisoftの研究チームが発表した本論文は、バーチャルなキャラクターを制御する新手法を提案している。バーチャルキャラクターの動きを制御する場合、機械学習モデルによって正しい動きを予測する手法が知られている。この手法では動きが複雑になると予測誤差が蓄積して、制御不能に陥る可能性があった。
提案された新手法では、予測した動きと正しい動きの誤差を機械学習モデルにフィードバックするようにした。つまり、予測を直ちに修正するプロセスを追加したのだ。その結果、複雑な動きを正確に予測できるようになったうえに、予測性能を獲得するのに必要な学習データを減らすことにも成功した。今後の研究課題として、長期予測(遠い未来の動きの予測)の安定性向上が挙げられる。
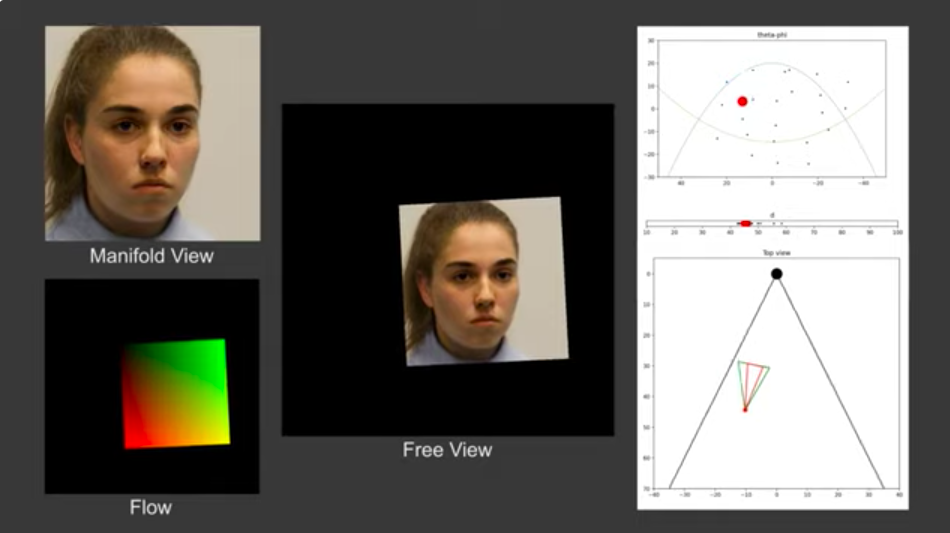
<7>FreeStyleGAN: Free-view Editable Portrait Rendering with the Camera Manifold
https://repo-sam.inria.fr/fungraph/freestylegan/
フランスのコートダジュール大学とINRIA(フランス国立情報学自動制御研究所)の研究チームが発表した本論文は、フォトリアルな顔画像を生成するStyleGANモデルを改善したことを報告している。同モデルが生成する顔画像は、通常は一方向(多くは正面)から見えたものである。
同論文は、「カメラマニフォールド」という新概念を導入する。この概念は、顔画像を正しく生成されるカメラアングルの範囲を意味する。さらにカメラマニフォールドの範囲内で精細な顔画像を生成できる新機能を開発した。この新機能を使えば、様々なカメラアングルや照明条件における非実在の顔画像が生成できるようになる。今後の研究課題として、同論文ではStyleGANを学習してから後処理を実行して新機能を追加したのだが、同モデルに対する学習とファインチューニングで機能拡張を実現することが挙げられる。
<8>Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
https://pose-with-style.github.io/
アメリカのバージニア工科大学とAdobe Researchの研究チームが発表した本論文は、1枚の人物画像から様々な姿勢の画像を生成する手法を提案している。単一の方向からひとつの姿勢を撮影した画像から様々な姿勢の画像を生成するにあたり、まず画像の姿勢と人体構造的に左右対称な画像を生成して、姿勢の裏側を表示できるようにする。次いで、姿勢の裏側にStyleGANで生成したフォトリアルな画像を貼り付ける。貼り付ける際には、姿勢の部位を考慮した歪みを付加する。この新手法を使えば、例えば正面から撮影した人物画像から横向きの人物画像を生成できる。今後の研究課題として、新手法開発に使った学習データには肌の色が濃いモデルが少ないという欠点があったので、学習データに多様性を導入することが挙げられる。
<9>Barbershop: GAN-based Image Compositing using Segmentation Masks
https://zpdesu.github.io/Barbershop/
アメリカのマイアミ大学とサウジアラビアのキング・アブドラ科学技術大学(KAUST)の研究チームが発表した本論文は、複数の画像の特徴を保持しながら1枚の画像を生成する手法を提案している。提案された手法を使うと、1枚の基準となる顔画像の髪型をほかの画像のそれに変えたり、さらに髪の色を別の画像のそれに変えたりできる。
この手法を可能としているのが、各画像の特徴を保持しながら基準となる画像に特徴をなじませるGAN埋め込みアルゴリズムである。同手法で生成した画像に関してアンケートによる評価を実施したところ、従来の手法より好まれることもわかった。今後の研究課題として、顔にかかった髪の毛のようなオクルージョン(手前のオブジェクトが奥のそれを覆い隠している状態)がある場合には期待する画像が生成されない傾向にあるので、こうした場合でも正しく画像生成できるようにすること等が挙げられる。
以上の論文からわかるようにCG分野におけるAIの応用は、フォトリアルな顔画像の生成からさらに発展して、複数の顔の特徴の混合や見えない姿勢の推測のようにより自由な発想に基づいて追求されるようになっている。こうした自由な発想に基づいたAIのCGへの応用は、今後も進むことだろう。またXRに関しては、近年のメタバースの台頭に呼応してCG研究の中心的テーマになる可能性がある。いずれにしろ、今年のSIGGRAPH 2022とSIGGRAPH Asia 2022でもXRとAIは注目すべき研究分野であり続けるだろう。
TEXT_吉本幸記 / Kouki Yoshimoto
EDIT_小村仁美 / Hitomi Komura(CGWORLD)













