
2022年前半は、3月にGTC2022にてNVIDIAから「GH100」、4月にIntelから「Arc A」シリーズという新たなGPU製品が立て続けに発表された。さらに5月末にCOMPUTEX TAIPEI 2022が、8月にはSIGGRAPH 2022が控えており、ここでもGPUを含めた新しいプロセッサの発表がいろいろとありそうだが、このタイミングで、2022年前半のGPUの動きを一度整理してみることにしよう。
NVIDIA、60TFLOPS超のGPUを発表〜ただし、用途はGPGPU限定
3月22日(火)、NVIDIAは最新世代のGPU「GH100」を発表した。このGH100、単体GPUで60TFLOPS以上の演算性能を発揮することから、業界からは熱い視線が注がれた。
アーキテクチャが違うので比較する意味はあまりないかもしれないが、GH100の60TFLOPSは、PS5の約6倍、PS4のGPU(1.84TFLOPS)の約32倍、PS3のGPU(0.224TFLOPS)の約267倍の性能に相当する。

NVIDIAが今回発表した「GH100」という新GPUは、開発コードネーム「Hopper」として開発されたものになる。
「Hopper」の名の由来は、1950年代から1960年代に活躍した女性軍人の計算機学者で、プログラミング言語「COBOL」の開発者としても著名なGrace Hopper/グレイス・ホッパー氏から来ており、GH100のHもHopperの頭文字からとったものだ。NVIDIAは、2006年に発表されたGeForce 8800 GTX(開発コードネームFermi)以降、開発コードネームに、20世紀以前の世界的に著名な物理学者の名前を引用する傾向にある。
このGH100は、台湾の半導体製造企業のTSMC社の最新4nmプロセスで製造され、そのダイサイズは814mm^2。総トランジスタ数は単一ダイで800億に達するという。これは言うまでもなく、世界最大級の大規模プロセッサということになる。
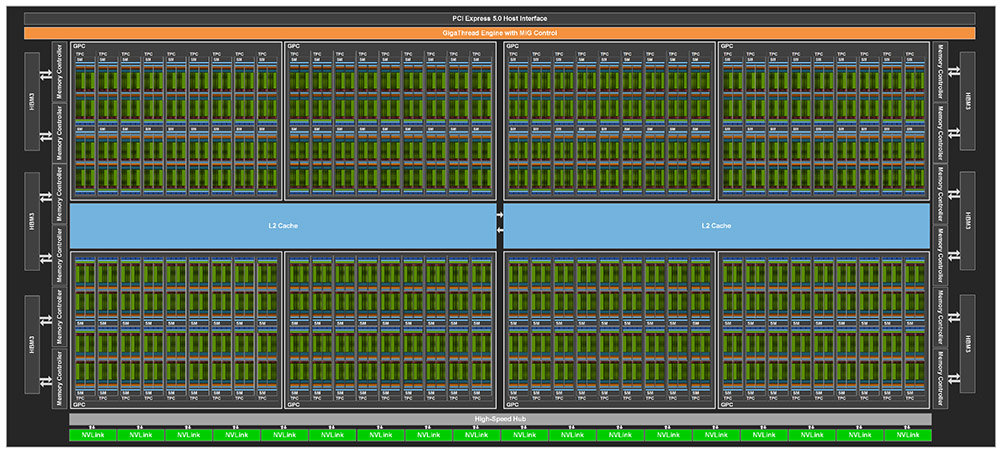
GH100が内包する総CUDAコア数は18432基。製造上の歩留まりの都合で実際の製品では16,896基のみが稼動する仕様。これが約1.8GHzで駆動されることで約60TFLOPS(≒16,896CUDAコア×16,896基×2FLOPS)の理論性能値をたたき出す。
搭載グラフィックスメモリには現状、最速級のHBM3が採用されている。
HBMはHigh Bandwidth Memoryの略で、HBM3は3世代目を表す。GH100に搭載されるHBM3は1枚あたり16ギガビット(2ギガバイト)の容量のメモリチップを8枚積み重ねてTSV(Through-Silicon Via)接合して構成している。この容量16GBのHBM3ブロックをGH100のダイの上下に3つずつ配置することで、総容量96GBの大容量メモリシステムを1パッケージで構成することに成功している。メモリ帯域はなんと3TB/sと発表されており、これも現行GPUとしては最速だ。ちなみに、PS5が約448GB/s、NVIDIAのウルトラハイエンド級民生向けGPUのGeForce RTX 3090系が約1TB/sだったので、GH100のメモリ性能の3TB/sは、PS5の約6.7倍、3090系の約3倍となる。
なお、GH100は、主に科学技術計算、人工知能開発などのスーパーコンピュータ用途、サーバ向けのGPUとなっており、ハードウェアレイトレーシングユニットは非搭載だったりするなど、グラフィックス機能のポテンシャルに関しては前世代に据え置かれたままとなっている。そう、GH100は、いわゆるGPGPU用途専用のGPUというわけである。なので、GH100がGeForceブランドで発売される予定はない。なお、実際の製品の発売は2022年第3四半期として発表されている。
ダイナミックプログラミングに対応するGH100
ここまでだと「GPGPU用途のために順当に規模を大きくして性能を向上させたGPUなのね」という印象で終わってしまうが、今回のGH100は、学術界からの要望を受けて2つの大きな新機能を搭載しており、ここに熱い視線が集まっている。
1つは、ダイナミックプログラミング(動的計画法)への対応だ。
動的計画法とは、膨大なデータを対象にした組み合わせ問題などを解くときに用いられる手法だ。例えば、スーパーの開店セールなどでありそうな「棚にある商品、1,000円でこの袋に入るだけよりどり詰め込み放題」というキャンペーン。客は最も得をしそうな商品をたくさん詰め込みたくなるが、価値の高い商品は大きい。だったらサイズの小さい商品をたくさん詰め込んだ方が得か……?
こんな問題で、もし「商品の種類が数万個」のケースで最適解を導こうとすると大変だということが想像できるだろう。しかし、一方で「行うべき計算」自体はシンプルそうなのも想像ができるはず。こうした大規模な組み合わせ問題を解くために効果的なアルゴリズムが動的計画法であり、この処理系を構築するためにGPUを効果的に動かせる命令セット「DPX」がGH100に追加されたのだ。
上で挙げた「よりどり詰め込み」の例は「ナップサック問題」という動的計画法の典型事例だが、実際の学術の世界では、経路探索、グラフ解析、多変量解析、遺伝子配列解析などに、この動的計画法が用いられるため、そうした分野の最適解導出を加速化させるためにDPXが搭載されたというわけである。

トランスフォーマーエンジンを内蔵するGH100
最近、機械翻訳の品質や、音声による言語インターフェイスの精度が向上している実感はないだろうか。実はこれ、2017年にコーネル大学の研究グループが発表した「トランスフォーマー法」と呼ばれる人工知能(AI)の実現モデルに関する論文による影響の現れだったりする。
「"Attention" Is All You Need」(あなたに必要なのは"Attention"だけ)と題されたこの論文では、言語処理において、従来スタイルの「世の中に存在する膨大な文例そのものを学習させたAI」よりも、「単一の文章に出てくる単語同士の相関性の重要度に着目して学習させたAI」の方が、高精度でなおかつ計算量も少なくて応答性も速いAIになるということを証明し、学術界に大きなインパクトを与えたのだ。
なお、ここでいうAttentionとは、トランスフォーマー法ではキーポイントとなる概念で、何に「着目」(≒注意を払う)するかの意。この論文では、「単一の文章に出てくる単語同士の相関性の重要度にこそ"着目"しましょう」と主張している。NVIDIAによるとここ2年のAI関連の論文の70%が「トランスフォーマー法」に関するものになってしまったというから、AI関連の学術界に与えたインパクトは大きい。
GH100では、そうした学術界の動向に反応し、トランスフォーマー法の学習フェーズの演算工程において、適切な精度の浮動小数点形式を自動選択して処理を進める「Transformer Engine」を搭載したのだ。なお、この新エンジンにより、トランスフォーマー法を先代GA100で実行した際の6倍のパフォーマンスが実現できたとNVIDIAは主張している。
ところで、このトランスフォーマー法におけるAI学習工程の実装においては、演算精度よりもダイナミックレンジが担保できれば十分ということがわかってきており、8ビット浮動小数点(FP8)のハードウェア対応が有効だと叫ばれるようになる。実際、2019年には、IBMの研究グループが、トランスフォーマー法を採用したAI学習フェーズにおいて8bit浮動小数点数の有効性を訴える論文「Extending 8-bit training breakthroughs to the toughest deep learning models」を発表した。この論文が提唱した8ビット浮動小数点は仮数重視の「符号1bit,指数4bit,仮数3bit」(E4M3)型と、指数重視の「符号1bit,指数5bit,仮数2bit」(E5M2)型の2つ。GH100のTransformer Engineは、これら2つを適宜使い分けるしくみを採用した。

くり返しになるが、GH100は、GPGPU用途のGPUであるため、CGWORLD読者には直接は関係のない製品となる。ただ、近年のNVIDIAは、GPGPU専用製品を出したあとに、遅れてグラフィックス用途のGPUを発表するながれが多いので、かなり高い確率で、何らかのGeForce RTXシリーズの刷新版を出すのではないか、と噂されている。原稿執筆時点の2022年5月中旬時点では、NVIDIAからの公式アナウンスは何もないが、ネット上では、GeForce RTX 4000型番のまことしやかな噂がながれ始めている。はたして……?
IntelがGeForce、Radeonへ対抗する単体GPUをついに発表へ?
「Intel入ってる」の合言葉で有名な、世界最大級の半導体企業のIntel。特にCPU製品で絶大なる存在感をPC業界に対して放っており、USB、PCI-Express、Thunderboltなどの様々なPCプラットフォームを支えるほとんどの基盤技術の規格策定にも関与してきた実績もあり、もはやPCを語る上でIntelを避けることは不可能なくらいである。
しかし、そんなIntelも苦手な分野があった。それはグラフィックスプロセッサ、GPUだ。
Intelは1998年に「Intel 740」という単体GPUをリリースするも、当時、頭角を現し始めていたNVIDIAのRIVA 128、RIVA TNTに性能・商品力において敗北。このときの敗北は衝撃的で、その後、2020年に「Iris Xe MAX」をリリースするまで、Intelが単体GPUを発売することはなかった。今回発表された新単体GPUはその後継となる製品。果たして、どのような仕上がりになっているのだろうか。
Intelの錬金術師?〜Arc Aシリーズ
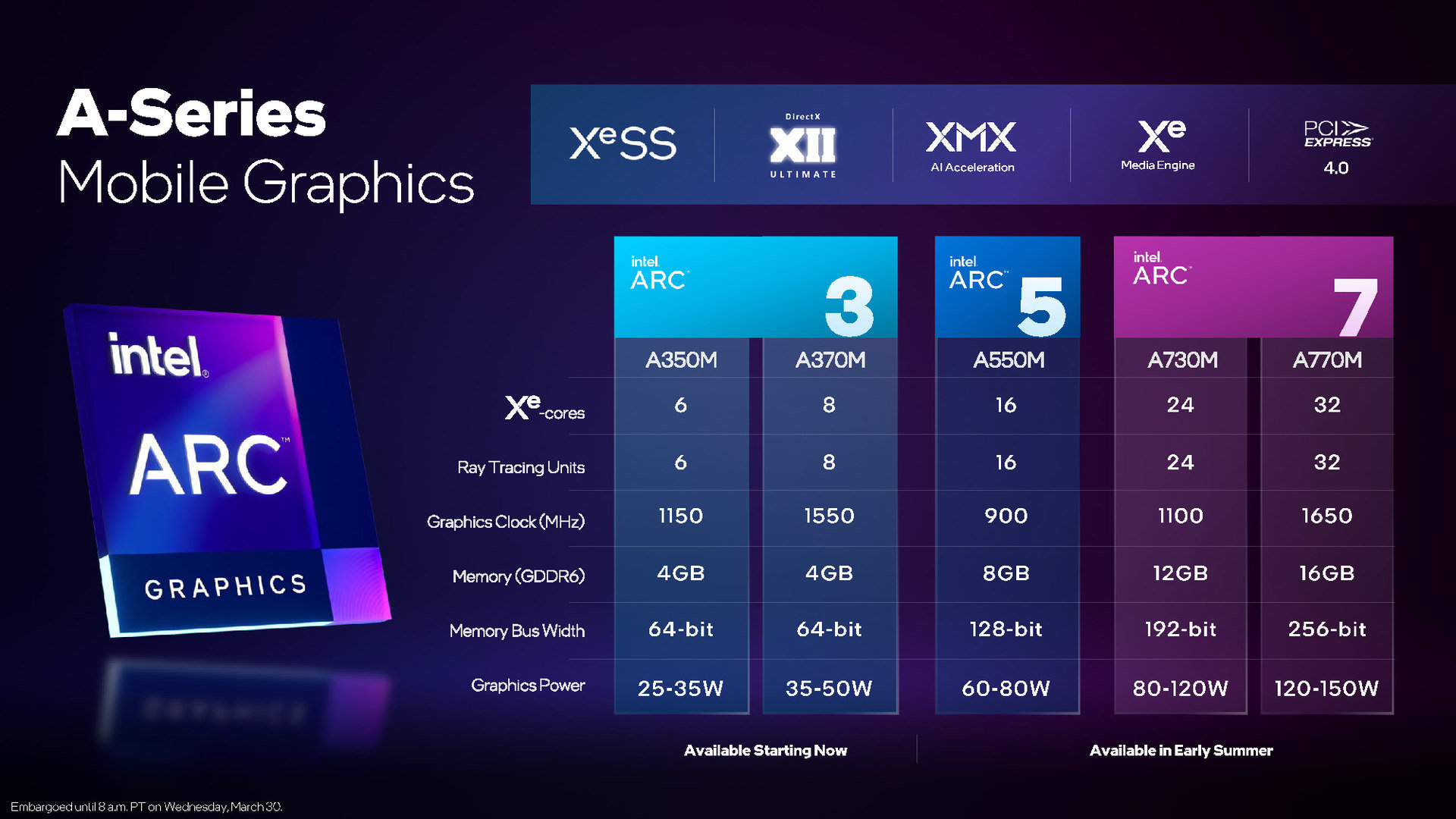
Intelが発表した新単体GPUは「Arc」シリーズと名付けられ、今後、デスクトップPCやサーバ向けなどの製品展開も予定されてはいるが、2022年は、ノートPC向け製品として投入していく方針を明らかにした。ターゲット範囲は薄型高性能ノートPCから性能重視のゲーミングノートPCくらいまでが想定されており、Arc3、5、7の3シリーズが投入される。そう、3、5、7という数値型番はIntel製CPUのCore i3、i5、i7になぞらえたブランディングとなっており、初心者にもわかりやすい配慮がある。
今回発表されたArcシリーズは「Aシリーズ」とブランディングされ、今後、前述したような別の製品ジャンルに対してはAに続くアルファベット文字、B、C、Dで展開される。では、なぜ、今回はAシリーズなのかというと、それは開発コードネームが「Alchemist」だから。
Alchemistは錬金術師の意。ちなみに、今後のB、C、Dの開発コードネームも決まっており、「Battlemage(魔闘士)」、「Celestial(神聖官)」、「Druid(妖術師)」になるという。どうやら『ダンジョン&ドラゴンズ(D&D)』に代表されるテーブルトークRPGのような「ファンタジー世界観における魔道師系職種縛り」で決めているようだ。この"縛り"で、今後のE、F、G、H……が見つかるかどうかについても注目である(笑)。
さて、Arc Aシリーズは、前述したようにArc 3、5、7といった製品展開が行われるが、チップ(ダイ)としてはACM-G10、ACM-G11の2種類が存在する(以下、G10、G11と略記)。上位機に相当するのは型番の小さいACM-G10の方で、そのダイサイズは406mm^2、総トランジスタ数は217億。下位のACM-G11はそれぞれ157mm^2、72億だ。G10とG11のちがいは、内包されるコア数(≒演算器の数)にあり、上位ダイのG10はArc5、7として、下位ダイのG11はArc3として製品化される。なお、Intelは自社製造工場をもつが、今回のAシリーズの製造は台湾TSMC 6nmプロセスで行われる。なかなか興味深い。
Arc Aシリーズは全て、PCI-Express Gen4接続に対応するが、前述したようにノートPC製品に搭載されるため、基本的にはデスクトップPC向けのグラフィックスカード製品バリエーションはないとされる。しかし、Intelは、今夏、例外的に、数量限定モデルのようなかたちで、Arc AシリーズのPCI-Expressバス接続対応の拡張カード版を発売(ないしは発表)する計画があるようだ。


Arc Aシリーズはどのくらいの性能なのか
さて、多くの人が気になる「どのくらいの性能なの?」ということについて見ていきたい。
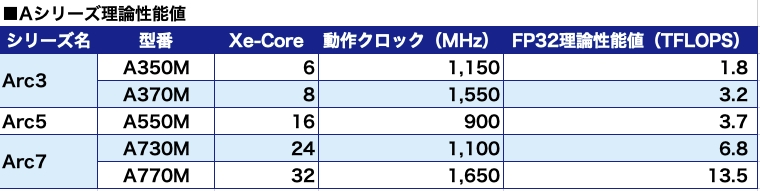
高性能版のG10の方で見ていくと、G10の場合、Xe-Coreと名付けられたGPUコアが32基搭載されている。このXe-Core1基あたりが16基の浮動小数点演算器「Xe Vector Engine」(XVE)を内包しており、このXVE自体が256ビットのSIM演算器だそうなので、32ビット浮動小数点(FP32)の積和算を8個分同時に計算できると見繕えることになる。となれば理論性能値は、Arc7のA770Mの動作クロック1,650MHzで計算すれば
32Xe-Core×16XVE×SIMD8×2FLOPS(積和算)×1,650MHz=13.5TFLOPS
となる。
アーキテクチャが異なるため同列に比較はできないが、参考値として今世代ゲーム機のGPUの理論性能値を示すと、PS5が10.3TFLOPS、Xbox Series Xが12.1TFLOPSなので、なかなか優秀といえそうだ。ただ、NVIDIAやAMDの超ハイエンド級GPU達が、既に23.7TFLOPS(Radeon RX 6950 XT)や40.0TFLOPS(GeForce RTX 3090Ti)に到達していることを考えると、まだまだ及ばない。ただ、今回発表されたArc Aシリーズ用はノートPC向けGPUなのでデスクトップPC向けGPUと対比するのはフェアじゃないかもしれない。頂上決戦については、いずれ出てくるかもしれないBシリーズ以降に期待したい。
Arcはレイトレ対応でAIチップも搭載
Arcは、単体GPUとしては後発も後発なので、機能面で劣っていてはIntelの面目が立たぬ……ということで、機能面においても力が入っている。
まず、グラフィックスレンダリング関連機能として、Arcはハードウェアレイトレーシングに対応してきている。DirectX12 UltimateのDirectX Ray Tracingにも当然対応する。レイトレ対応のPCゲームはゆっくりではあるが増えてきているので、この点は大きく歓迎されそうだ。
そして、俗称"AIチップ"とも言われることもある推論アクセラレータをもArcは搭載する。Arcが搭載するXe Matrix Engine(XMX)がまさにそれで、ArcユーザーにはAIベースのアンチエイリアス/超解像処理ソリューション「XeSS(Xe Super Sampling)」が利用できる。
高機能ビデオプロセッサも搭載しており、H.264、H.265などの主要コーデックに対応したデコーダ、エンコーダを搭載する。また、新鋭コーデックのAV1エンコーダを業界初搭載しており、こちらは映像編集/制作の現場からは大歓迎の声が飛んでいる。
HDMI2.1には未対応な点は何とも残念だが、概ね全方位に死角はない。Aシリーズの評判次第ではBシリーズ以降の展開にも注目が集まることだろう。
2022年前半はマイナーチェンジ中心だったAMD Radeon
GPUといえばAMDのRadeonシリーズを忘れることはできないが、2022年の前半は、2020年からリリースされているRadeon RX 6000シリーズのマイナーチェンジ版を中心とした製品の発表に留まっている。
2022年1月には、新規コアのNAVI24(開発コードネーム)を採用したエントリークラスのRadeon RX 6400/6500シリーズを発表。NAVI24は、TSMCの6nmプロセスで製造される徹底的なコストパフォーマンスに振った製品で、近年のGPUの割には珍しく、ハードウェアビデオエンコーダを搭載しないことを特徴としている。エンコーダを採用しないということは、映像制作/編集には向かないGPUということになる。なお、デコーダは搭載する。
総トランジスタ数は54億、総ストリーミングプロセッサ(シェーダプロセッサ)数はRadeon RX 6400系で768基、同6500系で1,024基。理論性能値はRadeon RX 6400系で3.6TFLOPS、同6500系で約5.8FLOPS。グラフィックスメモリはGDDR6が4GB。グラフィックメモリバスは64ビットだ。
性能イメージとしては「4K解像度でのゲームプレイは想定しないが、フルHDでのゲームプレイには支障なし」といったところ。際立った高性能GPUということではないが、ローエンドクラスでありながら、一応、リアルタイムレイトレーシングユニットも搭載し、未だ半導体不足が叫ばれる2022年5月時点でも、価格が日本円で2万円台に収まっているため、確かにコストパフォーマンスはいい。
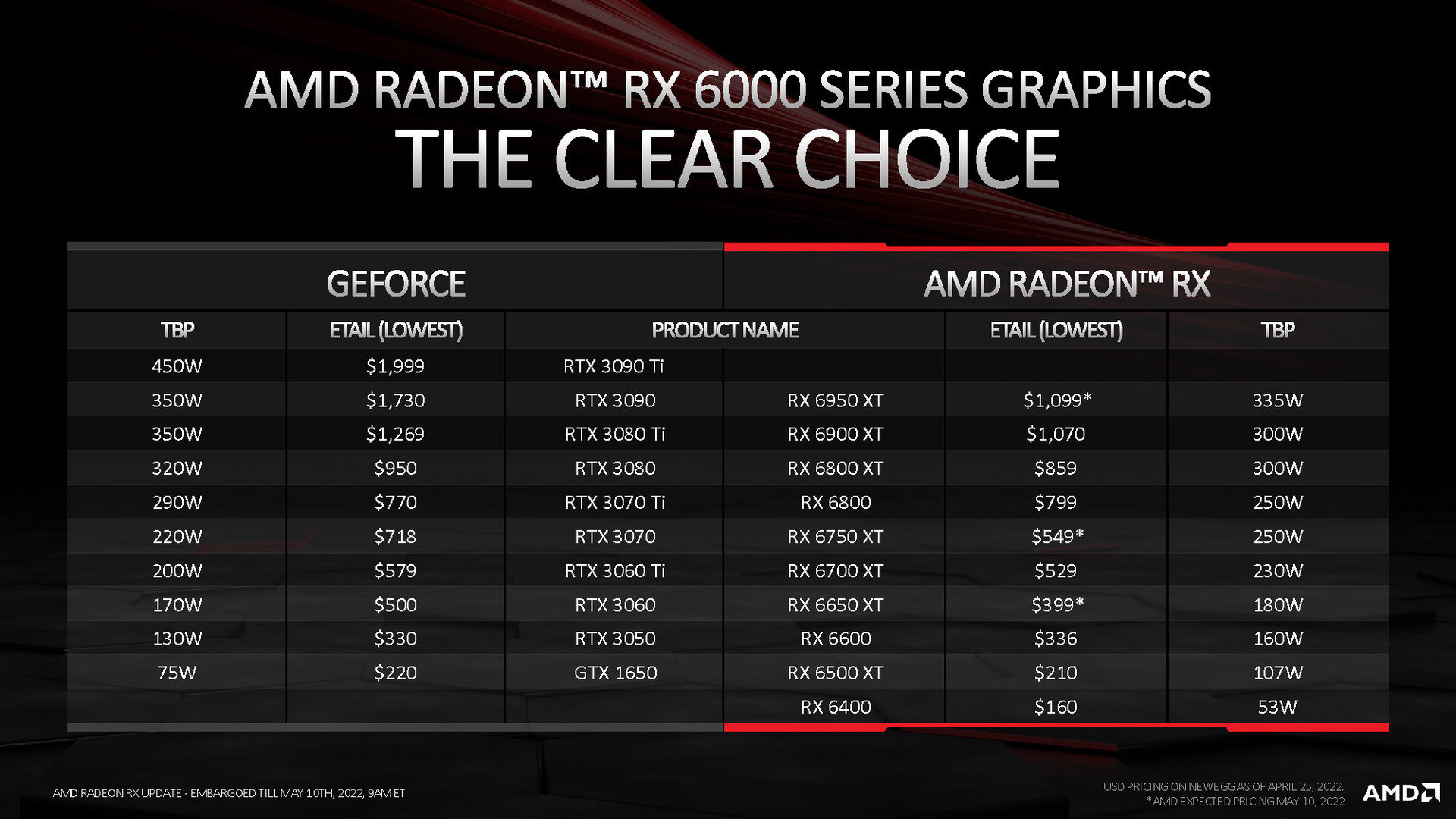
そして、2022年5月には、2020年に発表された既存のRadeon RX 6000シリーズを、型番を「+50」したマイナーチェンジ版をリリースした。
AMD自身もダイ(チップ)自体は完全に旧モデルと同一ということを明言しており、「基本動作クロックを上方向へ仕様変更しただけのモデル」というのが、この+50型番モデルの正体になる。このタイミングで仕様改善が可能になったのは「2020年の初期ロット時から約2年が経ち、製造技術が成熟して良品割合が増えたこと」が直接の理由だ。

オリジナルモデルとは基本仕様に変更はなく、異なるのは「GPUコアの動作クロック」と「グラフィックスメモリのクロック」のみで、ストリームプロセッサ数などの基本仕様に変更はなし。よって理論性能値も、以下のように"微増"といった感じに留まる。

AMDは今回のオリジナルモデルと+50型番の新モデル、そして競合NVIDIA製品との基準価格比較表を公開しているので下記に示しておこう。
PCシステムを買い替えるのはいつがいい?
ここまでを踏まえて「PCシステムの買い換えはいつがいいのか」という疑問をもつ人も多いだろう。筆者の私見を含むが、この問いに対する回答っぽいものを記しておく。
まず、GPUの買い換えに関しては、NVIDIAもAMDも次期モデルの発表が、COMPUTEX TAIPEI 2022からSIGGRAPH 2022のタイミングからそれ以降に行われるのではないか、という憶測が飛んでいるので、そうした発表が落ち着いてから決断するのがいいだろう。
ところで、今年2022年は、PCシステム全体が刷新される年になる、ということを忘れてはならない。
Intelは昨年の2021年11月にAlder-Lake世代の新Coreプロセッサを発売。CPUソケットはLGA1700へと刷新され、メモリシステムはDDR5へ。そしてバスシステムもPCI-Express Gen.5.0(以下、PCIe5)への対応を果たした。
AMDもCOMPUTEXのタイミングでの発表が期待されている新CPU、ZEN4世代の新Ryzenで、DDR5対応、PCIe5対応となる見込みで、合わせてCPUソケットもAM5へと世代公開が予告されている。

おそらく、噂されている新GeForceや新Radeonは全てPCIe5対応になることだろう。つまり、今年後半でのPCシステム刷新を考えている人は、
・CPUソケットの刷新(≒既存マザーボードは使えなくなる)
・DDR5へのメモリシステムの世代交代(既存のDDR4は使えなくなる)
・PCIe5への世代交代(旧世代PCIeシステムとの互換性はあるが旧世代システムで接続した場合はフル性能は出せない)
といったあたりを意識しておく必要があるということだ。
TEXT_西川善司 / Zenji Nishikawa
EDIT_小村仁美 / Hitomi Komura(CGWORLD)












