2023年3月21日(火・祝)から24日(金)、NVIDIAは春期GTC2023を開催した。AIとメタバースに関する最新技術が発表された同カンファレンスでは、多数の生成AIに関するセッションが行われた。本稿では、そうしたセッションから3つをピックアップしてその内容をまとめていく。

<1>さらに高度になるStable Diffusion
「High-Resolution Image Synthesis via Two-Stage Generative Models(2段階生成モデルによる高解像度画像合成)」と題されたセッションでは、画像生成AIのStable Diffusionを開発するStability AI社が同AIの動向について発表した。
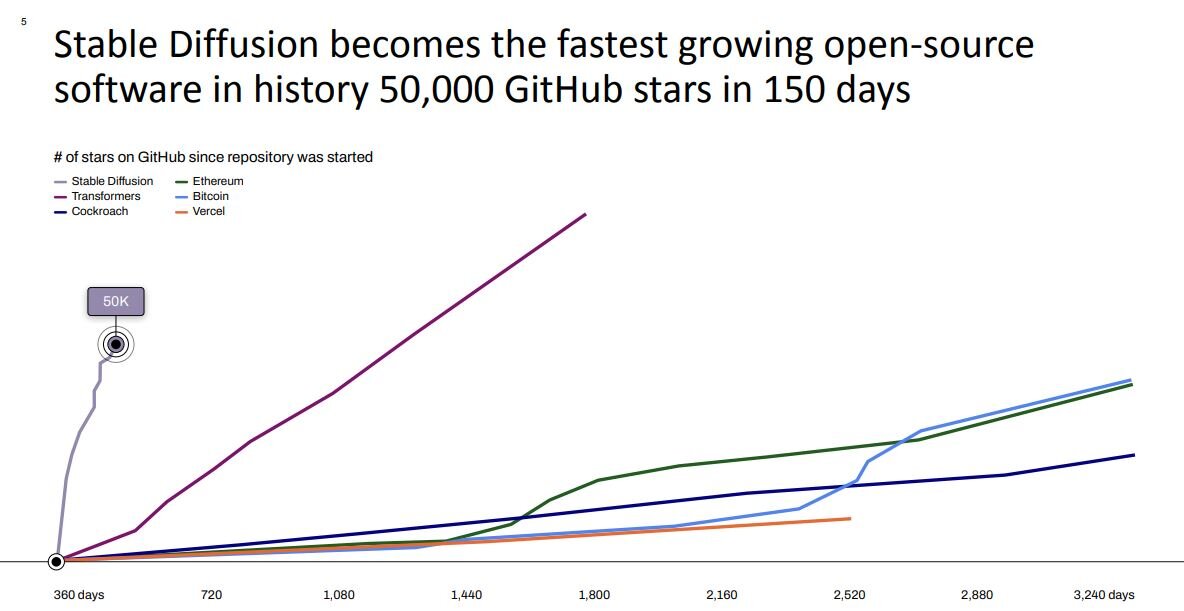
はじめにStability AIのCEO、Emad Mostaque/エマード・モスタック氏は、昨年8月に公開したStable Diffusionが驚異的な注目を浴びたことを報告した。オープンソースの同AIは開発プラットフォームのGitHubで公開されているのだが、同プラットフォームにおける注目度を示す星の数が公開後わずか150日で5万に達した。仮想通貨のビットコインやイーサリアムが約10年かけて獲得した星の数を半年足らずで達成したのだ。
ついでStability AIリードジェネレーティブAIリサーチャー、Robin Rombach/ロビン・ロンバッハ氏がStable Diffusionに関する技術的解説を行なった。同氏は同AIの基本アーキテクチャと機能を説明した後、現在研究中の機能について話した。以下ではそのなかから4つ紹介する。
1つ目の機能は、文脈に沿った画像生成である。
この機能はGoogleが2022年8月に発表した技術DreamBoothと同等のものなのだが、任意の被写体に関する数枚の画像を入力後、「泳いでいる」といった画像生成に関する文脈を与えるとその文脈に沿った画像を生成できる。

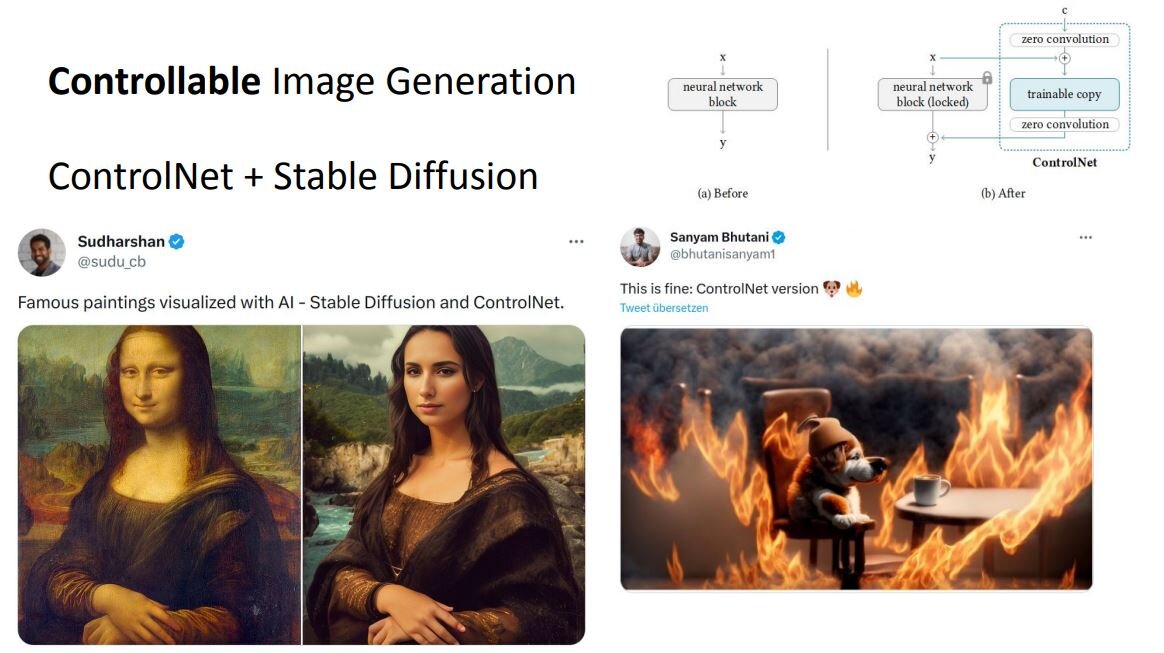
2つ目は高度な制御を伴う画像生成である。
この機能は、現在では姿勢等を指示した画像生成が可能なControlNetとStable Diffusionを組み合わせて実行できる。この機能をStable Diffusion単独で実行できるようにすることを研究している。
3つ目はテキストによる合成指示だ。
この機能は、2022年11月に発表されたInstructPix2Pixで使われた技術をStable Diffusionでも使えるようにするものだ。この機能を使えば、例えばヒマワリが描かれた画像に対して「ヒマワリをバラに置き替えよ」という合成指示が可能となる。

4つ目は人間の美的嗜好を反映した画像生成である。
現状では画像を生成する際、スタイル等を詳細に入力テキストで指定しないと、所望の画像を得られない。こうしたなか現在研究されているのは、生成画像にあらかじめ多くのユーザに好まれるようなスタイルを反映させておく機能である。この機能が実装されれば、スタイル等を詳細に入力しなくても所望の画像が得られるようになるかも知れない。

<2>ヒューマンユーザーインターフェイス時代を見据えた「D-ID」
「Generative AI Text-to-Video: Humanizing the Way We Interact with Machines(テキストから動画を生成するジェネレーティブAI:機械との対話方法を人間化する)」と題されたセッションでは、入力されたテキストを話す人間の動画を生成するサービスを開発・提供するD-ID社がビジネスの現状と今後の展望を発表した。
はじめにD-IDのCEO、Gil Perry/ジル・ペリー氏が同社の業績について話した。同社は昨年だけで1億本以上の動画を制作し、現在も指数関数的に動画制作数を増やしている。また調査会社Allied Market Researchが2023年2月に発表したレポートによると、同社サービスを含むデジタルヒューマン市場は2031年までに約4,400億ドルに達すると予測されていることから、同社サービスは長期にわたり成長すると見込まれる。
続いてD-ID研究開発部門ヴァイス・プレジデントのOr Gorodissky/オール・ゴロディスキー氏が、同社が開発した音声から動画を生成するAIのしくみを解説した。このAIを開発するにあたっては、まず画像から動画を生成するAIの開発から始まった。
具体的には、任意の表情が中立的な顔画像から特定の表情をした顔の動画を生成するようにAIを訓練したのだ。特定の表情の生成にあたっては、口や目元の位置から表情の特徴を学習した。
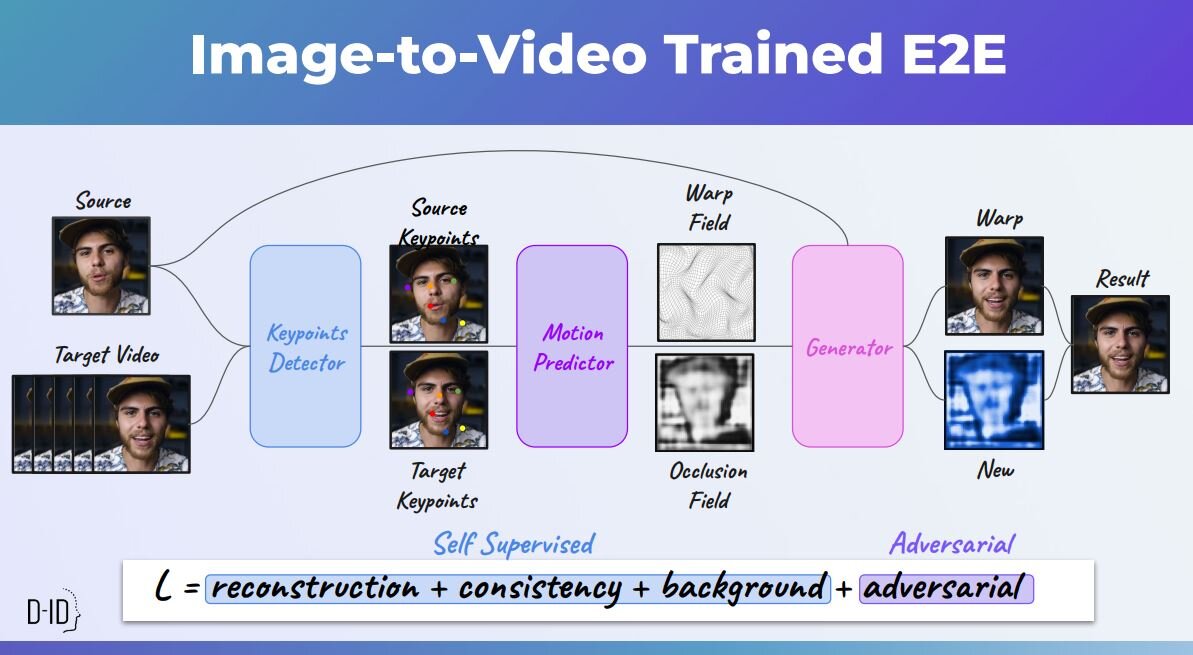
顔画像から動画を生成するAIを開発後、音声から動画を生成するAIを開発した。音声から動画を生成するには、まず音声の特徴を大規模言語モデルによって抽出する。抽出された特徴に対応する顔画像を生成して、その画像から最終出力となる動画を生成するのだ。
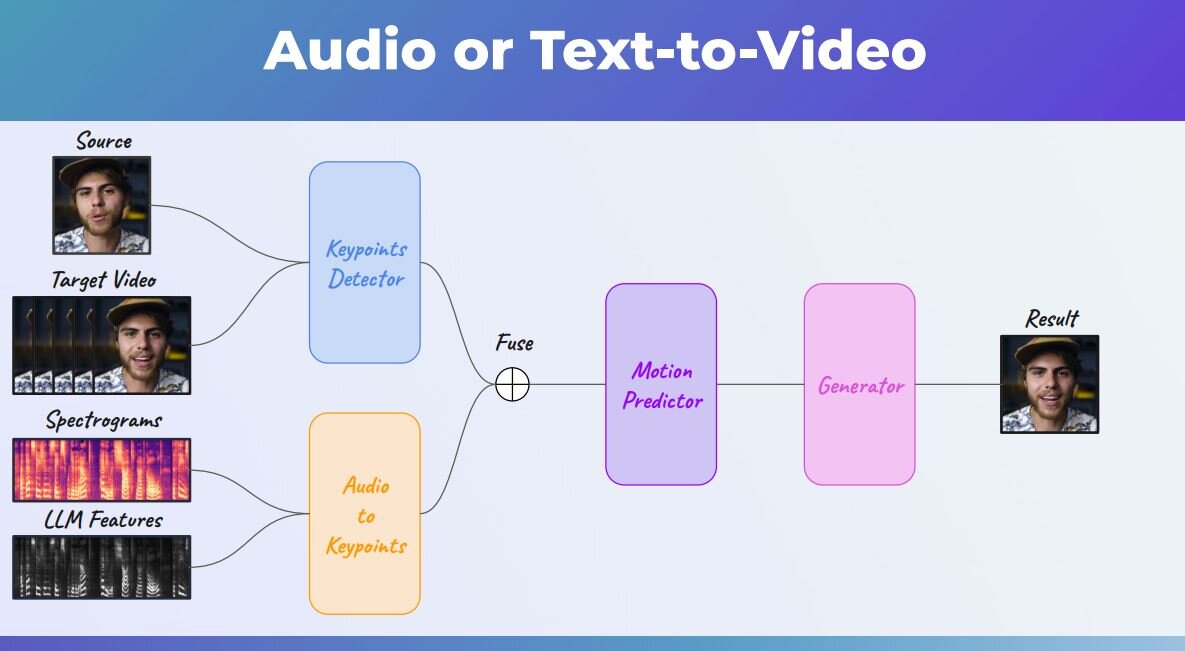
D-IDのセッションの終盤では、ペリー氏が同社の新サービスchat.D-IDを紹介した。このサービスはChatGPTと同社の動画生成技術を融合させたもので、デジタルヒューマンがChatGPTによって生成されたテキストを読み上げるものだ。
ペリー氏はChat.D-ID開発の背景にあるビジョンも語った。
同サービスで実現しようとしているのは、大規模言語モデルがもつ柔軟な会話機能と実在の人間と話しているかのような親しみやすさを兼ね備えたコミュニケーションツールである。このツールの利点は、デジタルヒューマンを活用しているので多言語に容易にスケーリングできるところだ。
同氏はこのようなビジョンを「ヒューマンユーザーインターフェイス」と呼び、次世代デジタルコミュニケーションの主流になると考えている。

<3>仮想空間を豊かにするNVIDIAの3DモデリングAI技術
「3D by AI: Using Generative AI and NeRFs for Building Virtual Worlds(AIによる3D:仮想世界構築のための生成AIとNeRFの活用)」と題されたセッションでは、NVIDIAシミュレーション&AI部門シニア・ディレクター、Gavriel State/ガブリエル・ステート氏が同社開発中のAIによる3Dモデリング技術を発表した。
周知のようにNVIDIAはNVIDIA Omniverseの開発・提供を通じて、メタバースやデジタルツインのような仮想空間の拡大に注力している。こうした動向において重要になるのが、仮想空間を満たすコンテンツである。仮想空間のなかに何もなければ、そうした空間は魅力に欠けてしまい過疎に陥る。そのため同社は仮想空間を満たす3Dコンテンツ制作技術を熱心に開発しており、そうした技術についてAIは大きな貢献を果たしている。
ステート氏はAIを活用した3Dコンテンツ制作技術を多数発表したが、そうしたなかから以下では注目すべき5つを紹介する。
2020年に発明された多数の2D画像から3Dシーンを生成するNeRF(「Neural Radiance Field」の略称)はすでに多くの研究成果を上げており、2022年にはNVIDIAがレンダリング時間を大幅に短縮したInstant NeRFを発表している。
この技術の欠点として、3Dシーン生成時の照明設定を変えられないことがある。同社はNeRFによる生成後にも照明設定をオブジェクトごとに変えられる改善を進めていて、いずれ実用化される見込みだ。

一般に3Dオブジェクトは、形状を定義したメッシュと表面の図柄が描かれたマテリアルを素材としてレンダリングされる。こうしたレンダリング過程を逆転させる技術が、3D MoMaあるいはnvdiffrecと呼ばれる技術だ。この技術を使えば、オブジェクトを撮影した多数の2D画像からメッシュとマテリアルを復元できる。もっとも、この技術はまだ処理に時間がかかるため、すぐには実用化できないようだ。
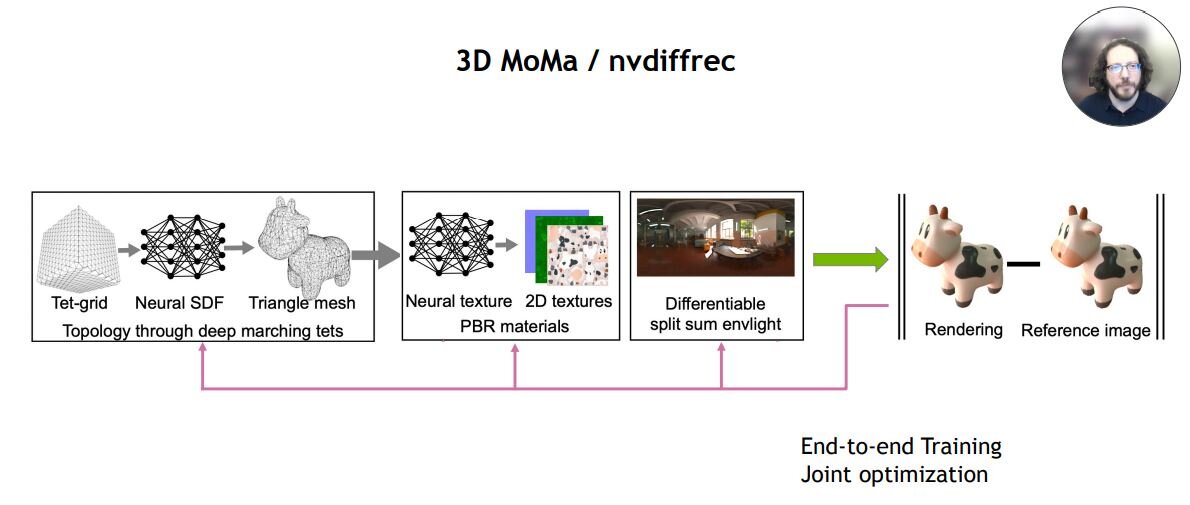
1枚の2D画像から3Dオブジェクトを生成する技術には、GANVerse3Dがある。この技術については、2021年4月にNVIDIAジャパン公式ブログ記事で解説されている。
同技術には、例えば自動車の3Dオブジェクトを生成する場合には、生成前にAIが自動車について学習する必要があるという制限事項がある。裏を返せば、AIが学習していないオブジェクトは生成できないのだ。同技術は、Omniverseのエクステンションとして利用できる。
GET3Dも3Dオブジェクトを生成する技術であり、2022年10月のNVIDIAジャパン公式ブログ記事で紹介された。この技術を使うと、GANVerse3Dより複雑な形状の3Dオブジェクトを生成できる。同技術は近い将来にOmniverseのエクステンションとして利用できるようになるようだ。
現状におけるNVIDIAの生成AI技術の集大成とも言えるものが、テキスト入力から3Dオブジェクトを生成するMagic3Dである。この技術は、Googleが開発した同種の技術DreamFusionより高品質な3Dオブジェクトをより速く生成できる。
以上のように、生成AIは高度な画像生成処理が研究開発されると同時に、動画や3Dオブジェクトも生成できるように進化している。ChatGPTのようなテキスト生成AIも含めた生成AI市場は、今後数年間にわたり大きく成長すると考えられる。そのため、デザイナーやアーティストは生成AIの動向に注目し、「生成AIが使える人材」としてキャリアを形成することも選択肢のひとつになるだろう。
TEXT_吉本幸記 / Kouki Yoshimoto
EDIT_小村仁美 / Hitomi Komura(CGWORLD)