コンピュータグラフィックスとインタラクティブ技術に関するトップカンファレンスであるSIGGRAPHの分科会SIGGRAPH Asia 2020が2020年12月4日から13日まで開催された。コロナ禍の影響によりSIGGRAPH 2020と同様にオンラインでの開催となった同カンファレンスでは、様々な分野における技術論文が合計113本発表され、そのほかにもXRコンテンツが配信された。こうした発表のなかからXRとAIに関連した注目論文を9本ほど紹介する。
TEXT_吉本幸記 / Kouki Yoshimoto
EDIT_山田桃子 / Momoko Yamada
■参考リンク集
技術論文の発表をはじめとしたSIGGRAPH Asia 2020で実施された全プログラムに関しては、以下の公式ページを参照。
sa2020.conference-program.com
同カンファレンスで公開された全論文を1本あたり数十秒にまとめたダイジェスト動画「SIGGRAPH Asia 2020 - Technical Papers Fast Forward」が、Facebook Liveで公開されている。この動画を見れば、今年の研究傾向をつかめるだろう。
www.facebook.com/watch/?v=904188407021219
注目論文に関するダイジェスト動画も公開されている。
また、非公式ながら技術論文に関する動画やサンプルコードへのリンクを集めた以下のようなWebページもある。
kesen.realtimerendering.com/siga2020Papers.htm
<1>OmniPhotos: Casual 360°VR Photography
richardt.name/publications/omniphotos
360°VRパノラマ画像の新しい撮影法を提案した論文。360°VRパノラマ画像を撮影する際、しばしば1分を超えるキャプチャ時間が必要となる。提案された撮影法は、一般消費者向け360°ビデオカメラを撮影者の頭上で3秒程度振り回すか、手動で10秒程度動かす、というもの。頭上で振り回すには、自撮り棒を使うのが推奨されている。撮影によって取得したデータは、変形可能なプロキシジオメトリ(deformable proxy geometry)と呼ばれる方法でレンダリングされる。こうして生成された360°VRパノラマ画像は、従来の撮影方法と比べて大幅に表示領域が拡大され、垂直方向の歪みも軽減されるものとなった。
<2>Optimizing Depth Perception in Virtual and Augmented Reality through Gaze-contingent Stereo Rendering
www.computationalimaging.org/publications/gcstereo
XRにおけるヴァーチャルな立体視を改善する手法を提案した論文。人間が立体視できるのはふたつの眼球があることによって生じる視差を知覚的に処理しているからであり、既存のVR機器も視差を利用してヴァーチャルな立体視を実現している。しかし、既存のVR機器は瞳孔間距離(inter-pupillary distance)の変化を考慮していないため、近い距離における深度が歪んでしまう。同論文が提案する凝視条件つきステレオレンダリング(gaze-contingent stereo rendering)は、瞳孔間距離の変化に対応するため、従来の手法より歪みの少ないヴァーチャルな立体視が可能となる。従来の手法との比較対照実験も行い、同手法によって立体視が改善されたことが実証された。
<3>Egocentric Videoconferencing
gvv.mpi-inf.mpg.de/projects/EgoChat
ビデオ会議における顔の撮影に関する新手法を提案する論文。ビデオ会議では通常、顔の正面にカメラを置いて行う。この方法だと歩きながらビデオ会議に出席するのは困難であり、また会議中はカメラの前で着席していなければならない。提案された新手法は、将来普及すると予想されるスマートグラスのような顔に装着するウェアラブルデバイスを使う方法。具体的には、スマートグラスの側面に顔の側面を撮影するカメラを設置して、撮影された動画から正面の顔を再構成する。顔の側面から正面への再構成には、敵対的生成ネットワーク(GAN)を活用する。このGANモデルは、顔側面の動画から正面のそれをリアルに再現できるように訓練することで実現した。
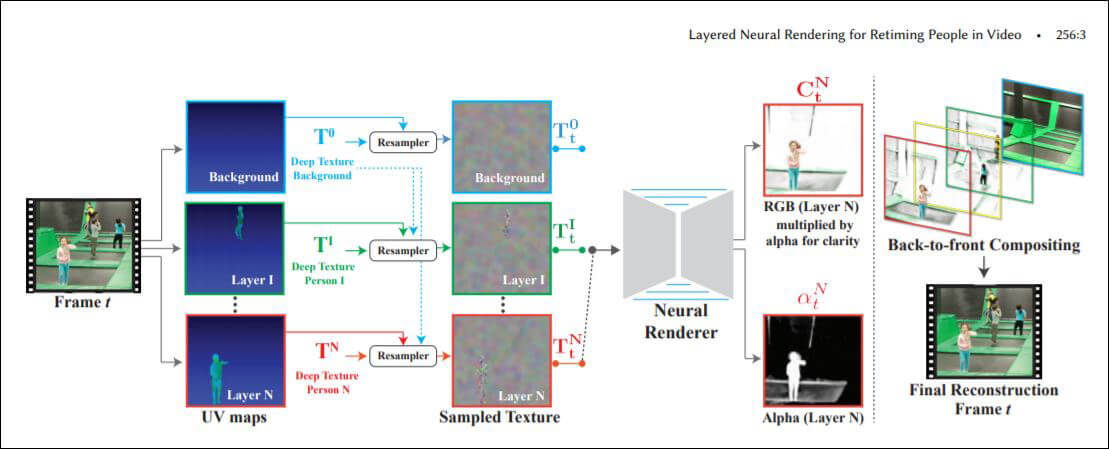
<4>Layered Neural Rendering for Retiming People in Video
Google所属の研究員らが発表した、撮影された動作のタイミングを再編集できる手法を提案した論文。同手法を使うと、ばらばらなタイミングでプールに飛び込む子供たちを撮影した動画を、同じタイミングで飛び込むように編集できる。同手法では、動画を背景と動作する人物に分離して処理するAIが活用されている(下のアーキテクチャ図を参照)。同手法の革新性は、(プールに飛び込んだときに生じる水しぶきのような)分離した人物に付随した現象も一貫して処理できるところ。この特徴により、編集後の動画が自然に見える。タイミングを編集できるだけではなく、指定した人物の削除もできる。
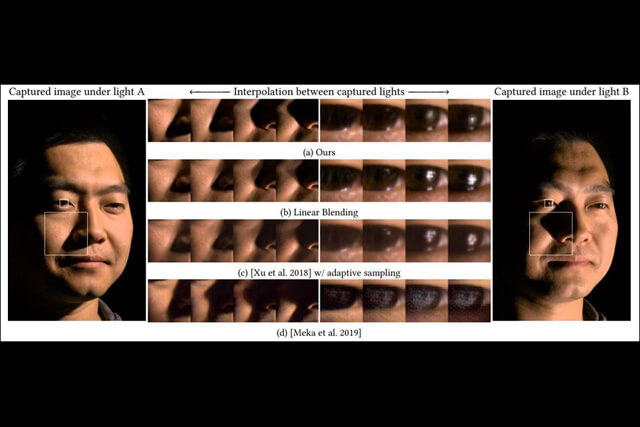
<5>X-Fields: Implicit Neural View-, Light- and Time-Image Interpolation
撮影された画像に関してカメラ位置や光源の位置を変えたり、さらには時間が経過した際に生じる変化を再現できる画像処理AIを提案している論文。同AIを活用すれば、ライティングが異なった画像を簡単に生成できる。同AIが様々な編集に対応できるのは、それぞれの変化に関して事前に学習しているから。学習済みの編集を組み合わせれば、(ポートレート画像のような)被写界深度の浅い画像(下の画像左側)や、モーションブラーを付加した画像(下の画像右側)も生成できる。

<6>Deep Relightable Textures
gvv.mpi-inf.mpg.de/projects/DeepRelightableTextures
Googleの研究チームが発表した新しい3Dレンダリング手法に関する論文。3Dオブジェクトのレンダリングの需要は増加の一途をたどり、レンダリング技術も進化している。しかし、人物のような複雑な形状をしたオブジェクトをフォトリアリスティックにレンダリングする技術には、まだ多くの改善の余地がある。同論文が提案するのは、複雑な形状をしたオブジェクトのレンダリングにAIを応用することによって、従来よりフォトリアルな結果を得るというもの。具体的には、AIによってオブジェクトの特徴を抽出したうえでレンダリングすることで、カメラ位置から見えないオブジェクト部分に関する描画処理が精確になった。論文を解説する動画を見ると、従来の方法より腕によってできる影や髪の毛のボリューム感といったディテールがレンダリングされていることが確認できる。
<7>Pixelor: A Competitive Sketching AI Agent. So you think you can sketch?
dasayan05.github.io/pubs/2020/07/30/pub-8.html
Pictionary(出題されたテーマに関する絵を描いて当ててもらう絵描き連想ゲーム)で人間を凌駕するAI「Pixelor」の開発を解説した論文。同AIを開発するにあたっては、2段階の学習を実施した。1段階目は、任意のテーマに関して人間が絵を描くときの筆順に関する学習。2段階目は、絵のテーマを早く認識してもらえるように筆順を並び替えることに関する学習。注目すべきは、人間が直感的に描く筆順は絵のテーマを早くわかってもらうように最適化されていないこと(下の画像参照。1行目がPixelor、2行目が人間)。なお、絵のテーマを認識するジャッジには、画像認識AIを採用した。実際にPixelorとゲームがプレイできるWebページも用意されている。

<8>Manga Filling Style Conversion with Screentone Variational Autoencoder
www.cse.cuhk.edu.hk/~ttwong/papers/screenstyle/screenstyle.html

日本マンガをアメコミ調に、あるいはアメコミを日本マンガ調に変換するAIモデル開発に関する論文。世界的に人気のある日本マンガとアメコミは、前者がデフォルメされたモノクロな絵柄、後者は前者と比較してリアルな絵柄でカラーが基本、と様式が著しく異なっている。同論文では両者を変換するにあたり、描線のつながりといった絵柄の構造を抽出するスクリーントーンVAEというAIモデルを開発した。同モデルで任意の絵柄の特徴を抽出した後、モノクロな日本マンガをカラーリングすればアメコミになり、反対にアメコミをモノクロにすれば日本マンガのようになる(上の画像参照)。モノクロな絵柄をカラーリングするにあたっては色調を指定できるので、様々なカラーバリエーションを試作できる(下の画像参照)。さらには写真からコミック調の画像を生成することも可能だ。

<9>Light Stage Super-Resolution: Continuous High-Frequency Relighting
cseweb.ucsd.edu/~ravir/tianchengsiga.pdf
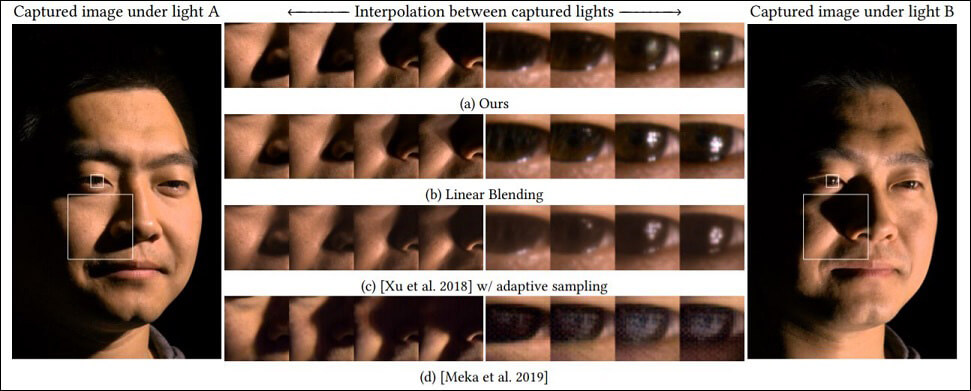
Light Stageによるキャプチャ画像の画質を改善する方法を提案した論文。球状にライトが配置された3DキャプチャデバイスであるLight Stageは、配置されたライト数が有限であるために、キャプチャした位置やライトの設定によってはキャプチャ画像の品質が劣化する。提案された改善方法は、AIが生成した仮想的なライトをキャプチャデータに追加する、というもの。同論文に掲載された比較画像を見ると、改善方法を適用したキャプチャ画像は、従来の方法で生成された画像よりも自然な仕上がりとなっている(上の画像参照。最上段が改善方法による画像。以下、従来の方法によるもの)。こうした改善方法を活用すれば、現実のライト数が少ない状況でも高画質のキャプチャ画像を生成できる。
SIGGRAPH Asia 2020で発表されたAI関連論文は20本近くあり、以上に紹介したものはその一部に過ぎません。AIのグラフィック技術に対する応用は多岐にわたりますが、その傾向として従来は人間が行っていたタスクをAIが自動化する、というのが指摘できます。こうした傾向がさらに進むと、人間のクリエイターは「どのように画像を編集・生成するか」という制作コンセプトの立案に専念できるようになるかも知れません。











