復旦大学、南洋理工大学 S-Lab、NVIDIA、清華大学、上海AIラボ、南京大学 PRLabからなる研究チームは12月21日(日)、最大で3分から5分にわたる長時間の動画を生成可能なAIモデル「LongVie 2」を発表した。GitHubではソース、Hugging Faceではウェイトが公開されているが、ライセンスについては不明。
研究チームは「LongVie 2」をマルチモーダルで制御可能な超長時間動画の世界モデル(Multimodal Controllable Ultra-Long Video World Model)と定義。テキストや画像だけでなく、深度マップや骨格情報といった複数の入力情報を組み合わせて、数分単位の連続した動画を、物理的な整合性やビジュアル品質を維持しながら生成できるという。

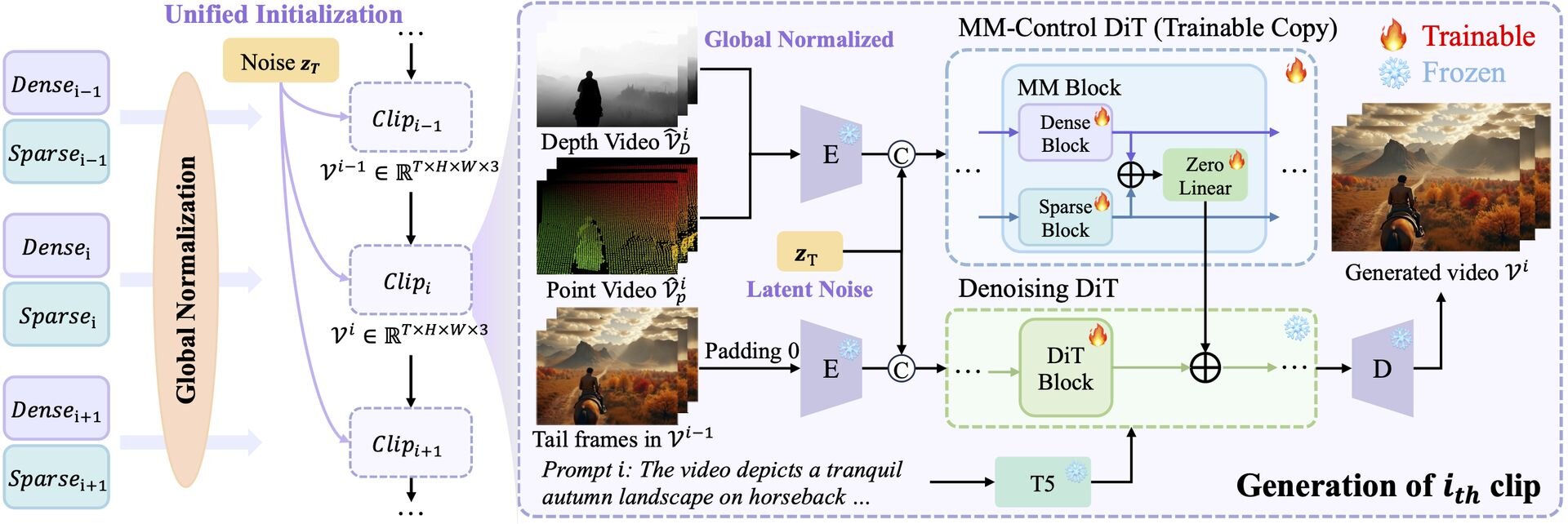
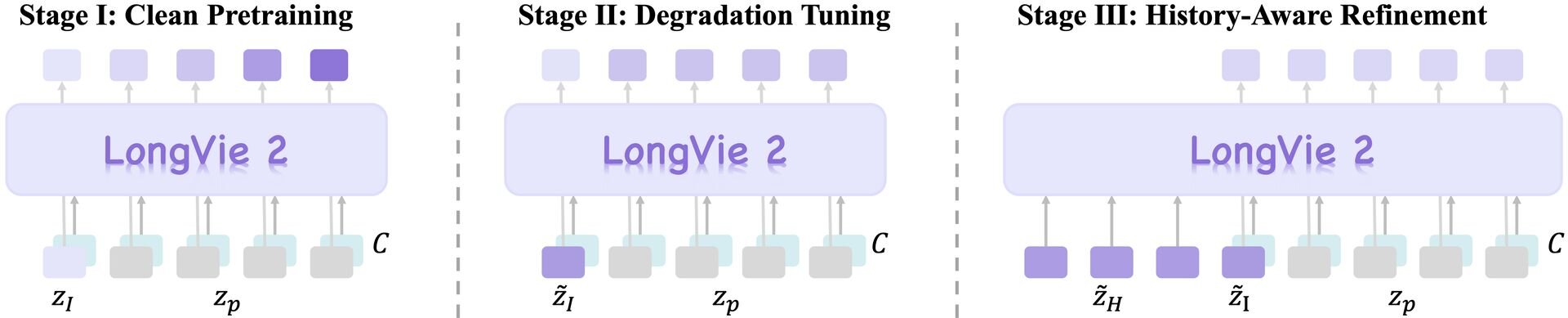
LongVie 2のコアテクノロジーは、自己回帰型フレームワーク(Autoregressive framework)に基づく3段階のトレーニングプロセス。第1段階は「マルチモーダルガイダンス」で、深度情報のような画面全体に関わる密な制御信号(Dense control signals)と、特定のポイントや動きを指定する疎な制御信号(Sparse control signals)を統合し、モデルにワールドレベルでの制御能力を学習させる。これにより、ユーザーの意図に沿った精密な操作が可能となる。
第2段階は「劣化認識トレーニング(Degradation-aware training)」。長時間の動画生成においては、時間の経過に伴い画質が崩れる劣化と、前後の文脈が繋がらなくなる不整合という課題が生じる。その点LongVie 2では、学習段階で意図的に画質劣化をシミュレーションすることにより、生成時の品質低下を防ぐ。
第3段階は「履歴コンテキストガイダンス(History-context guidance)」。過去のフレーム情報を参照しながら次のシーンを生成することで、長期間にわたる時間的一貫性(Temporal consistency)を確保する。これにより、季節の移り変わりや特定のタスク(野菜を切る、夜道を歩くなど)を、数分間破綻なく描き続けることが可能となったという。
■LongVie 2: Multimodal Controllable Ultra-Long Video World Model(プロジェクトページ、英語)
https://vchitect.github.io/LongVie2-project/
オープンソース状況とライセンス
LongVie 2のソースコードはGitHubにて公開されている。ベースモデルには「Wan2.1-I2V-14B-480P」が使用され、Hugging Faceではウェイトも提供している。ただし、ライセンスについては、GitHubリポジトリやHugging Faceにライセンスファイルや記述が存在しないことから、利用には注意が必要。
■LongVie 2: Multimodal Controllable Ultra-Long Video World Model(GitHub)
https://github.com/Vchitect/LongVie
■LongVie 2: Multimodal Controllable Ultra-Long Video World Model(Hugging Face)
https://huggingface.co/Vchitect/LongVie2
CGWORLD関連情報
●オープンソースのリアルタイム世界モデル「HY World 1.5(WorldPlay)」リリース! 720P・24fps、一人称と三人称の両視点をサポート

テンセントのHunyuanチームが、リアルタイム世界モデルフレームワーク「HY World 1.5 (WorldPlay)」を発表。オープンソース(TENCENT HY-WORLDPLAY COMMUNITY LICENSE)で公開した。720P・24fpsのリアルタイム生成、一人称と三人称視点をサポートし、フォトリアルな環境からスタイライズされた空想的な世界まで、多様なシーンの生成が可能。また、テキストプロンプトによって特定のイベントを発生させる機能を備え、世界を無限に拡張していく応用もできるとのこと。
https://cgworld.jp/flashnews/01-202601-HYWorld15.html
●Apple、単一画像から高品質な3DGSを生成する技術「SHARP」公開! 一般的GPU環境で高速3Dシーン構築可能

Appleが1枚の静止画から高品質な3D表現を瞬時に生成する新たな技術「SHARP(Sharp Monocular View Synthesis in Less Than a Second)」を公開。コードとモデルウェイトはGitHubとHugging Faceで公開されており、それぞれApple独自ライセンスの下で提供される。
https://cgworld.jp/flashnews/01-202601-SHARP.html
●3Dワールド生成モデル「Echo」発表! 独自の空間基盤モデルを用いて、メートル法ベースのジオメトリに裏付けされた物理空間の描画・編集を実現、クローズドβ中

SpAItialがテキストや1枚の画像から一貫性のある3D世界を生成する新モデル「Echo」を発表。Webデモでは3DGS(3D Gaussian Splatting)を採用し、低スペックな機材でもリアルタイムでジオメトリに裏付けされた空間の描画・編集、Webブラウザ上での自由な移動や探索を実現している。現在はクローズドベータ版の登録を受付中。
https://cgworld.jp/flashnews/01-202512-Echo.html