
清華大学、生数科技、カリフォルニア大学バークレー校からなる研究チームは12月16日(火)、動画生成AIの推論速度を向上させる新技術「TurboDiffusion」を公開した。単一のNVIDIA GeForce RTX 5090を用いて数秒で動画生成が行えるという。ソースコードはGitHubで、学習済みモデルのチェックポイントはHugging Faceで公開されている。ライセンスはApache-2.0。
TurboDiffusion: 100–205× faster video generation on a single RTX 5090
— Jintao Zhang (@Jintao_Zhang_) December 15, 2025
Only takes 1.8s to generate a high-quality 5-second video.
The key to both high speed and high quality?
SageAttention + Sparse-Linear Attention (SLA) + rCM
Github: https://t.co/ybbNBjgHFP
Technical… pic.twitter.com/6d6foxEQ9Z
「TurboDiffusion」は、動画生成の高速化実現のため、アテンション機構の最適化、ステップ蒸留による効率化、量子化技術の導入という3つの技術を中核に据えている。アテンション処理については、その高い計算コストを効率化するため、「SageAttention」と「SLA(Sparse-Linear Attention、疎線形注意機構)」を採用。SageAttentionは低ビットでの計算を行い、SLAは学習可能な疎な線形アテンションを用いることで、品質を保ちつつ計算量を大幅に削減する。
ステップ蒸留の効率化については、ステップ数削減のために「rCM(Score-Regularized Continuous-Time Consistency Model、スコア正則化連続時間一貫性モデル)」という技術を導入。これは、拡散モデルの生成プロセスを少数のステップで模倣・完了させる蒸留手法だ。そして量子化技術については、モデルのパラメータとアクティベーション(活性化関数)を8ビットに量子化する「W8A8量子化」技術を適用。これにより、線形層の計算が加速されると共に、モデルのメモリ使用量が圧縮され、ハードウェアリソースを効率的に活用できるという。


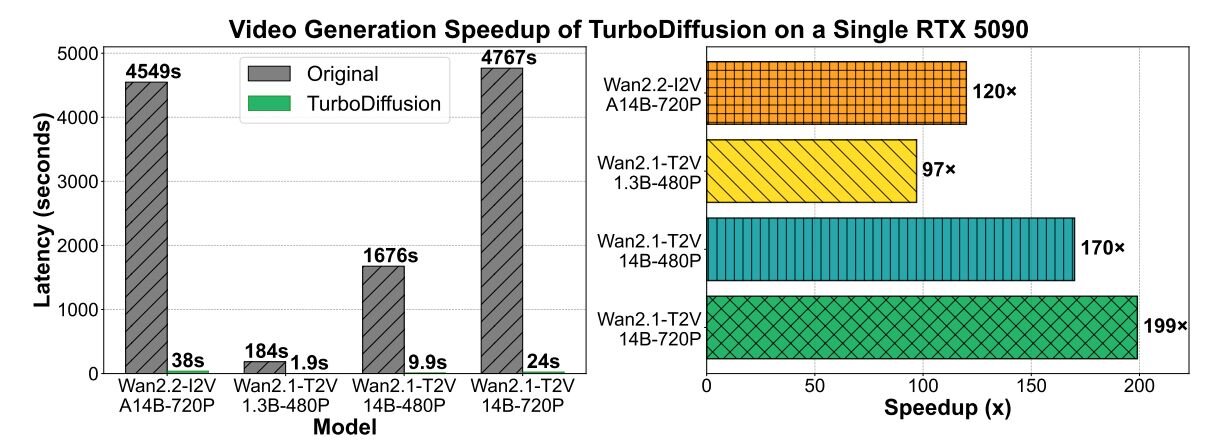
ソースコードはGitHub上で公開され、学習済みモデルのチェックポイントはHugging Faceにて提供されている。モデルはText-to-Video「Wan2.1-T2V」ベースのモデルや、Image-to-Video「Wan2.2-I2V」ベースのモデルなどが含まれる。また、GeForce RTX 5090などのコンシューマー向けGPUに適した量子化(Quantization)モデルと、H100などのデータセンター向けGPUを想定した非量子化モデルの双方が用意されている。
■TurboDiffusion: Accelerating Video Diffusion Models by 100–200 Times(論文PDF、英語)
https://jt-zhang.github.io/files/TurboDiffusion_Technical_Report.pdf
■TurboDiffusion(GitHub)
https://github.com/thu-ml/TurboDiffusion
■TurboDiffusion(Hugging Face)
https://huggingface.co/TurboDiffusion
CGWORLD関連情報
●マルチモーダル生成AIモデル「Wan2.6」リリース! 1080p15秒、リファレンスキャラクターのインポート、マルチショット生成によるストーリーの自動構築など

Tongyi Labがテキスト・画像・音声入力を統合し、リアルな画像と動画を生成するマルチモーダル生成AIモデル「Wan2.6」をリリース。特定のリファレンスキャラクターを異なるシーンへ一貫性を保ったまま配役する「Starring」機能、単純な指示から複数のカットで構成される物語を自動構築する「マルチショット・ナラティブ」機能、ネイティブレベルでのA/V同期による自然な対話シーン、1080p、緻密なライティング制御などの特徴を備える。Wan2.6は公式プラットフォームやサードパーティ製プラットフォーム、APIから利用可能。
https://cgworld.jp/flashnews/01-202512-Wan2.6.html
●マルチモーダル動画生成AIモデル「Kling O1」リリース! テキスト・画像・動画・特定の被写体を組み合わた入力に対応、動画生成から編集・スタイル変換まで1モデルに統合

快手がマルチモーダル動画生成AIモデル「Kling O1 動画モデル」をリリース。テキストと参照画像、既存の動画、特定の被写体(エレメント)を混在させて指示を出し、3秒から10秒までの動画を生成できる。チャットによる複雑な動画編集やスタイル変換の機能も統合。公式Webアプリでは無料・有料プラン共に利用できるほか、各種サードパーティ製プラットフォームで提供されている。
https://cgworld.jp/flashnews/01-202512-KlingO1.html
●Runwayの動画生成AIモデル「Gen-4.5」リリース! リアルな物理挙動の再現、複雑な演出指示への忠実な追従性を実現

Runwayが動画生成AIの最新基盤モデル「Gen-4.5」を発表し、有料プランのサブスクリプションユーザーに対して提供を開始した。複雑で連続的な指示を正確に理解し実行でき、リアルな物理挙動の再現も可能となった。基本解像度は1,280×720(16:9、9:16)または960×960で、4Kへのアップスケーリングが行える。まずはText to Videoが提供され、今後Image to Video、Keyframes、Video to Videoなども順次提供するとのこと。
https://cgworld.jp/flashnews/01-202512-Gen-4.5.html












