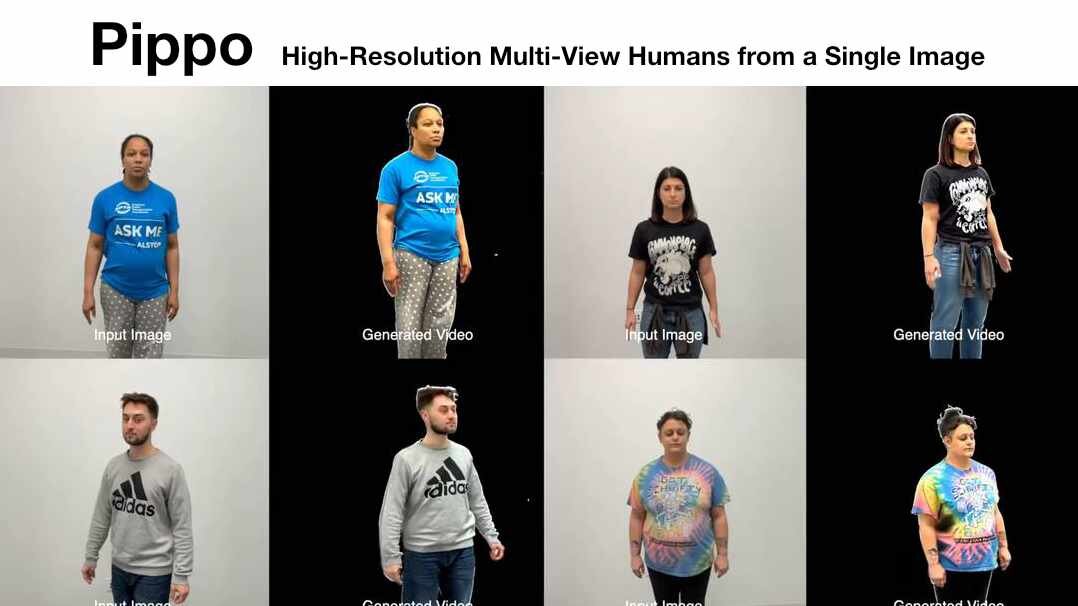
Meta Reality Labsやトロント大学らの研究チームは2月11日(火)、画像生成AI技術「Pippo : High-Resolution Multi-View Humans from a Single Image」の論文を発表し、GitHubでトレーニングコードを公開した。本技術は、トランスフォーマーをベースにした拡散モデル(DiT、Diffusion Transfomer)により、1枚の人物写真から複数アングルを推定し、1K解像度のマルチビュー画像を生成するもの。
Last week, we announced Pippo - a DiT that generates 1K res. turnarounds from a single iPhone photo (even occluded ones)!
— Yash Kant (@yash2kant) February 19, 2025
Here’s the deep dive thread unpacking everything we learned! pic.twitter.com/GNHdo9PNzb
本プロジェクトのゴールは「純粋な2Dの拡散(diffusion)をスケールアップすることにより、可能な限りベストな3Dデジタルヒューマンのジェネレータをつくること」。技術的には、これまで重要視していたキーポイントやデプス、ノーマルなどを用意せずに、1K解像度のマルチビュー拡散モデルを生成することだったという。
We had one goal: create the best 3D human generator possible by scaling up pure 2D diffusion!
— Yash Kant (@yash2kant) February 19, 2025
Technically, this translated into creating: a 1K resolution multi-view diffusion model without any traditional priors (ie keypoints, depth, normals, etc). pic.twitter.com/eYL3AL8TAX
Pippo is a tiny beast and nothing limits it to humans!
— Yash Kant (@yash2kant) February 19, 2025
Pippo is only 1.5B params - ie. 8x smaller than Flux-pro!
It can be scaled a lot further! And, extended to a 4d world simulator (eg. Genie-2)! pic.twitter.com/LCyEtM7JOW
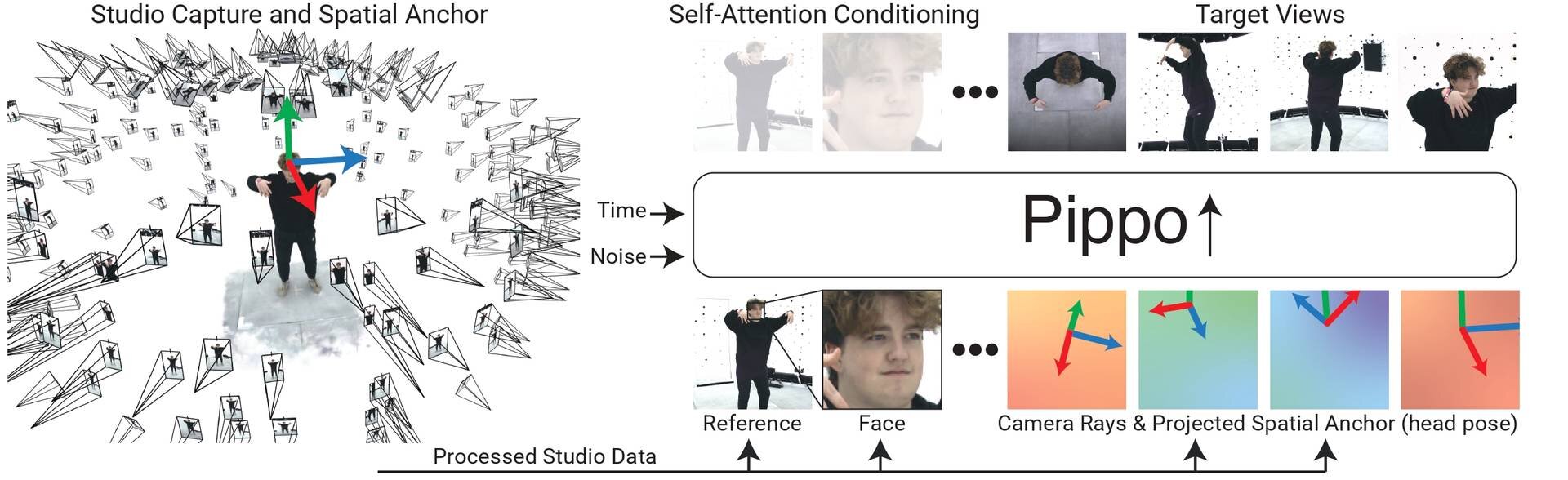
How does Pippo understand 3D?
— Yash Kant (@yash2kant) February 19, 2025
A simple idea - we put a 3D anchor in space, and just show Pippo how it looks from the desired viewpoints.
Anchor images pass into VAE + a lite ControlMLP branch and interact with image tokens in pixel-aligned manner via shift-scale modulation. pic.twitter.com/a8QDiR5b6s
Pippoのトレーニングは3段階に分けて行われた。まずは30億枚の人物写真(キャプションなし)で事前トレーニングを行い、次にスタジオのキャプチャデータによるトレーニングだが、ここでは小さな解像度で、48ビューの長いコンテキストを用いる。そして最後に1K解像度のスタジオキャプチャデータによるトレーニング。コンテキストは2ビューのみ用いている。
またPippoでは、最適なエントロピー減衰(entropy attenuation)のために、アテンションバイアスの範囲を1.4~1.6に設定したグロースファクターハイパーパラメータ(Growth Factor hyperparameter)を導入。これによりビュー(トークン)数が増えた際の生成のぼやけが軽減される。


▲アテンションバイアスの修正による生成の明瞭化
■Pippo : High-Resolution Multi-View Humans from a Single Image(プロジェクトページ、英語)
https://yashkant.github.io/pippo/
■Pippo(GitHub)
https://github.com/facebookresearch/pippo
CGWORLD関連情報
●NVIDIAらによるAIベースのレンダリング手法「DiffusionRenderer」発表! ジオメトリとマテリアルバッファの正確な推定によりシーンをフォトリアルにリライト

NVIDIA Research・NVIDIA Toronto AI Lab・トロント大学らが、インバースレンダリングとフォワードレンダリングの二重の問題に取り組むニューラルアプローチ「DiffusionRenderer」の研究論文を発表。
https://cgworld.jp/flashnews/202502-NVIDIA-DiffusionRenderer.html
●「NVIDIA RTX Kit」発表! GeForce RTX 50シリーズ時代のリアルなゲームキャラ作成を可能にするニューラル・レンダリング技術群

NVIDIAがゲームキャラクター作成用の新しいニューラル・レンダリング技術群「NVIDIA RTX Kit」を発表。本技術群は、ゲームアセットのAIによるレイトレース、パフォーマンスの向上したパストレーシングの利用、フォトリアルなゲームキャラクターのビジュアル生成などに活用できる。
https://cgworld.jp/flashnews/202501-NVIDIA-RTX-Kit.html
●NVIDIA、メッシュ生成モデル「Meshtron」発表! アーティストが制作するような高品質・実用的なトポロジーを生成可能

NVIDIAが機械学習アルゴリズムを用いた3Dモデルのメッシュ生成モデル「Meshtron」を発表。Meshtronは入力されたポイントクラウドデータから、アーティストが制作するような整理されたトポロジーを持つ3Dメッシュを生成する。1,024レベルの座標解像度・最大64K面のメッシュの生成に対応する、新しい自己回帰モデルとなる。
https://cgworld.jp/flashnews/202412-NVIDIA-Meshtron.html













