
コンピュータグラフィックスとインタラクティブ技術に関するトップカンファレンスであるSIGGRAPHの分科会SIGGRAPH Asia 2022が2022年12月6日(火)から9日(金)まで韓国・大邱(テグ)で開催された。同カンファレンスでは175本の技術論文が発表されたほか、XRに関する展示会やコンピュータアニメーションフェスティバルも催された。こうした発表のなかから、XRとAIに関連した注目論文を10本ほど紹介する。
関連リンク

●発表された技術論文に関する全プログラム(公式ページ)
https://sa2022.siggraph.org/en/full-program/
●カンファレンスで発表された注目すべき論文をピックアップしたダイジェスト動画
●技術論文に関する動画やサンプルコードのリンク集(非公式)
https://kesen.realtimerendering.com/siga2022Papers.htm
1.表情を編集可能なAIモデル「FDNeRF」
FDNeRF: Few-shot Dynamic Neural Radiance Fields for Face Reconstruction and Expression Editing
https://fdnerf.github.io/
香港城市大学とテンセントAIラボの共同研究チームが発表した本論文は、表情を編集可能なAIモデル「FDNeRF」を提案している。
従来のNeRFは2D顔画像から3D顔画像を生成していたが、多数の2D画像が必要であり、多様な表情を生成できなかった。こうしたなかFDNeRFは、少数の2D顔画像から多様な表情の3D顔画像を生成することを実現した。現時点の制限事項としては、顔とつながっている髪や胴体などの生成においてぼやけが生じることがある。また、生成素材となる2D画像において照明設定の不一致がある場合も、画像生成に失敗することがある。FDNeRFはディープフェイク動画制作に悪用される可能性があるのだが、既存の偽造検出技術を使うことで悪用を緩和できる。
2.任意の画像を着色するAIモデル「Unicolor」
UniColor: A Unified Framework for Multi-Modal Colorization with Transformer
https://luckyhzt.github.io/unicolor
香港城市大学らの研究チームが発表した本論文は、任意の画像に対してテキストや模範画像、(「ゴッホ風」のように)様式を入力としてわたして着色できるAIモデル「UniColor」を提案している。
同モデルを使えば、例えば自動車と木が写っているモノクロ画像に対して、自動車を(スポーツカーの)ポルシェ風に着色した後、木に対して「桜色の木」とテキスト入力して木を着色できる。同モデルにはテキスト入力に対応した画像認識モデルと、様々な様式に対応できる画像生成モデルの両方が実装されている。様々なモダリティで着色できる同モデルは、時として着色処理の衝突が生じて期待された結果が得られない場合がある。この問題は、着色処理の衝突を検出するアルゴリズムを追加実装することで解決すると考えられる。このように、同モデルにはUXを向上させる余地が十分にある。
3.テキスト入力から3Dオブジェクトを生成するAIモデル「CLIP-Mesh」
CLIP-Mesh: Generating textured meshes from text using pretrained image-text models
https://www.nasir.lol/clipmesh

カナダ・コンコルディア大学らの研究チームが発表した本論文は、テキスト入力から3Dオブジェクトを生成するAIモデル「CLIP-Mesh」を提案している。
従来の3Dオブジェクト生成モデルは、3Dオブジェクトに関する学習を必要としていた。対してCLIP-Meshは、メッシュパラメータ(3D形状に関する数値情報)を学習し、メッシュパラメータに対応した形状とテクスチャを生成する。上記に引用した本論文のプロジェクトページにアクセスすると、同モデルで生成した部屋を操作できる。現時点では同モデルで生成された3Dオブジェクトにテキストや不要な図柄が混入してしまう不具合が生じることがあるので、さらなる改善が求められる。
4.仮想Light Stageを用いた新しいライティング学習データセット
Learning to Relight Portrait Images via a Virtual Light Stage and Synthetic-to-Real Adaptation
https://deepimagination.cc/Lumos/
アメリカ・サンディエゴ大学とNVIDIAの共同研究チームが発表した本論文は、ポートレート照明に関する新しい学習データセットを提案している。
ポートレート照明を任意に変更できるAIモデルの開発には、Light Stageと呼ばれる高価な撮影設備が必要となり、潤沢な予算がないと開発できなかった。提案された学習データセットは、Light Stageを使わなくても高品質なポートレート照明に関するAIモデルの開発を可能とするものである。もっとも特定の照明条件においては、正しい照明状況を生成できない。例えば、強い光源によって照らされた髪のハイライトを正しく変更できない。また、眼鏡の反射や衣服によってできた影も除去できない。こうした制限事項は、既存照明合成技術を併用することで改善できる。
5.描画速度の速いAIモデル「ENeRF」
Efficient Neural Radiance Fields for Interactive Free-viewpoint Video
https://zju3dv.github.io/enerf/
浙江大学の研究チームが発表した本論文は、描画速度の速いAIモデル「ENeRF」を提案している。
多数の2D画像から自由視点の3D画像を生成するNeRFは3D合成に時間がかかるため、インタラクティブなコンテンツ制作には不向きな技術であった。こうしたなかENeRFはシーンの描画を効率化した結果、従来のNeRFと比較して最大60倍の描画速度を実現した。描画速度を高速化したので、同モデルを使えばインタラクティブな3D空間コンテンツを2D画像から制作できるようになる。なお、同モデルは個体の表面を処理対象として想定しているため、複数の表面が外観に寄与しているシーンを合成できない。こうしたシーンには、表面が透明で何かが写り込んでいたり、透けて見えたりするようなものが挙げられる。
6.効率的なボリューム型NSTによる煙シミュレーション
Efficient Neural Style Transfer for Volumetric Simulations
https://studios.disneyresearch.com/2022/11/30/efficient-neural-style-transfer-for-volumetric-simulations/
Disney Researchが発表した本論文は、煙シミュレーションの改善を提案している。
従来の煙シミュレーションには、ボリューム型NST(Neural Style Transfer)技術が使われている。本論文が提案する煙シミュレーション用ニューラルネットワークは、従来の技術より高速かつ高品質な描画を実現した。このニューラルネットワークは、従来はビュー(視点)に依存していたのに対して、ビューに依存しない処理をするのを特徴としている。提案技術は、煙のシミュレーションの際に水蒸気や火、さらには画家のゴッホが描く渦巻のようにスタイルを指定できる。もっとも指定するスタイルによってシミュレーションの品質にばらつきがあるので、今後はスタイルとシミュレーション品質の関係に関する研究が期待される。
7.筋電センサによる高精度の触覚デバイス
Force-Aware Interface via Electromyography for Natural VR/AR Interaction
https://www.immersivecomputinglab.org/publication/force-aware-interface-via-electromyography-for-natural-vr-ar-interaction/
アメリカ・ニューヨーク大学と香港中文大学の共同研究チームが発表した本論文は、ユーザーの触覚を高精度に再現する手法を提案している。
既存のXR触覚デバイスは、ユーザの触覚を忠実に再現できない上にユーザ体験を損なうデバイス設計となっている。こうしたなか上記研究チームは、ブレスレットのような筋電センサを使ってユーザーのバーチャルな触覚体験を可能とした。このセンサは、筋電センサから得られた生体情報をAIが学習することで高精度な触覚体験を実現した。この提案技術はXR体験を拡張する大きなポテンシャルをもっているが、今回の研究で利用した学習データセットは初歩的なものであったため、複雑な形状のオブジェクトを操作するときに生じるような複雑な触覚を再現できていない。今後は学習データセットを充実させて、複雑な触覚体験を再現できるようにすると同時に四肢に障がいのあるユーザの利用にも対応する予定である。
8.様々な筆致を指定できるAIモデル「Neural Brushstroke Engine」
Neural Brushstroke Engine: Learning a Latent Style Space of Interactive Drawing Tools
https://nv-tlabs.github.io/brushstroke_engine/
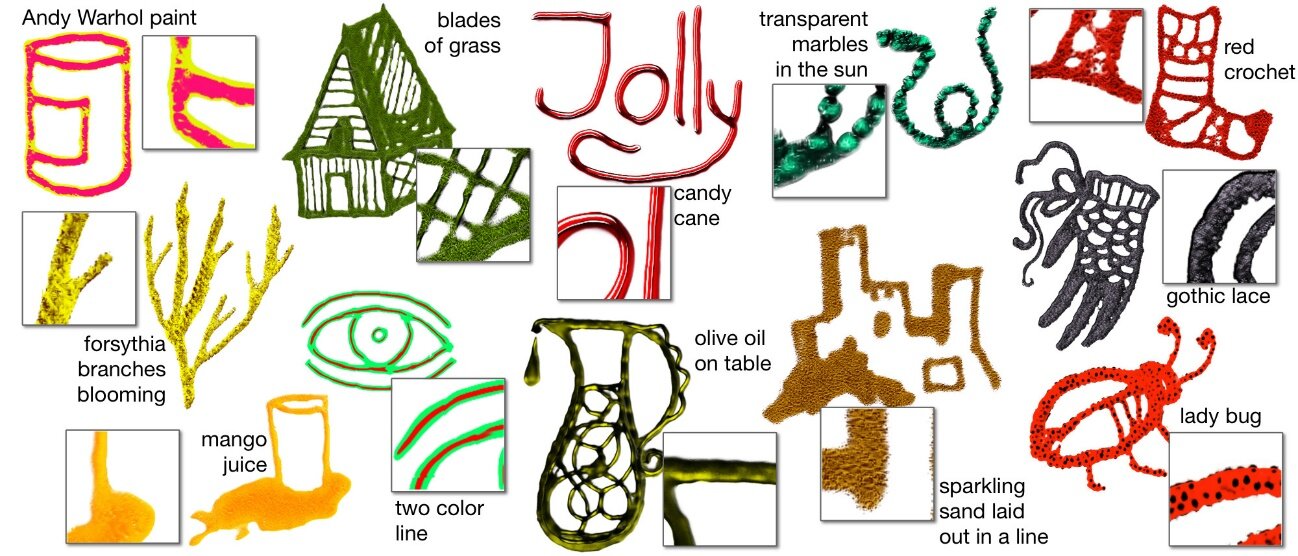
NVIDIAらの研究チームが発表した本論文は、様々な筆致を指定できるAIモデル「Neural Brushstroke Engine」を提案している。
同モデルを使うと、例えば「マンゴージュース」とテキスト入力するとマンゴージュースの色と質感のあるデジタルブラシで描画できる。さらに任意のスケッチからデジタルブラシの筆致を生成したり、(有名アーティストが制作した画像のような)任意の画像から筆致をコピーしたりもできる。同モデルは画像生成モデルのGANを拡張して開発された。同モデルを実装したペイントアプリをプロレベルのデジタルアーティストに試用してもらったところ、「マンゴージュース」のような物理的なアイテムをブラシにしたものが好評であった一方で、同モデルによるブラシは既存のそれを代替するものではないという感想を得た。こうした感想から、同モデルは既存のデジタルブラシによる表現を拡張するものと考えられる。
9.2D画像や動画をほかの平面・曲面に写像するAIモデル「NeuralKarker」
NeuralMarker: A Framework for Learning General Marker Correspondence
https://drinkingcoder.github.io/publication/neuralmarker/
香港中文大学らの研究チームが発表した本論文は、2D画像あるいは2D動画内の任意の座標をほかの平面や曲面に写像するAIモデル「NeuralKarker」を提案している。
この技術を使えば、曲面上に動画を再生できたり、動画の一部をほかの動画に差し替えたりできる。この技術を開発するにあたっては、写像を実行するAIモデルを訓練するためにFlyingMakersと命名した独自の学習データセットを用意した。同技術はARコンテンツなどへの応用を想定している。制限事項として、オクルージョン(遮蔽)が認められる表面への写像には対応していない。この制限は、複数の表面に写像できるように再設計することで克服できると考えられる。
10.HDRIをテキスト入力から生成するAIモデル「Text2Light」
Text2Light: Zero-shot Text-driven HDR Panorama Generation
https://frozenburning.github.io/projects/text2light/
シンガポール・南洋理工大学が発表した本論文は、ハイダイナミックレンジ画像(High Dynamic Range Images:以後「HDRI」と略記)をテキスト入力から生成するAIモデル「Text2Light」を提案している。
テキスト入力から画像を生成する技術は現在では広く普及しているが、HDRIを生成する技術はなかった。こうしたなかText2lightはまずテキスト入力から通常の画像を生成して、その画像を高解像度に変換するという2段階の生成によってHDRIの生成を実現した。同モデルの画像生成能力は、同モデルに実装されているAIモデルCLIPに由来する制限がある。例えば「シルエット(silhouette)」を含むテキストを入力すると、純粋な暗部のみが生成される。また、「木とオーロラ」というテキストを入力すると、木のみが生成される。こうした制限があるものも、Text2Lightにはテキスト入力によるVRコンテンツの生成などの応用が期待される。
以上のようにSIGGRAPH Asia 2022では、DALL-E 2をはじめとする画像生成AIの流行を受け、テキスト入力から様々なコンテンツを生成する研究が多数発表された。こうしたテキスト入力からのコンテンツ生成は、今後は動画や3Dオブジェクトの制作にも応用されるようになり、さらに普及すると予想される。そして、クリエイティブ業界におけるAI技術の活用はますます盛んになるだろう。
TEXT_吉本幸記 / Kouki Yoshimoto
EDIT_小村仁美 / Hitomi Komura











