
2025年4月10日(木)、東京都千代田区のエッサム神田にて、ボーンデジタル主催のHoudini Tech Seminarが開催された。約4時間におよんだ本イベントのハイライトを、3回に分けてお届けする。No.2では、ポリゴン・ピクチュアズの如月パベル氏(テクニカルディレクター・技術推進グループリーダー)の、「PDGによるキャッシュパブリッシュフローの自動化」と題した講演の前半部分を解説しよう。
関連記事


如月パベル氏
ポリゴン・ピクチュアズのテクニカルディレクター・技術推進グループリーダー。ロシア・ヴォログダ市出身。モスクワでCMや映画のCG制作に従事した後に来日。2012年からリンダやグリオグルーヴでHoudiniを導入したパイプライン開発に従事。2019年にポリゴン・ピクチュアズへ入社し、PDGを用いたパイプライン構築・開発を推進している。Houdiniは8.0から使用しており、PDGについては搭載された当初からのヘビーユーザー。
PDG活用の実例を、ポリゴン・ピクチュアズが初公開
本講演では、PDG(Procedural Dependency Graph)を活用したキャッシュパブリッシュフローの自動化について、実際のプロジェクト事例に基づいて解説が行われた。パベル氏は過去にもPDGをテーマに社外向けセミナーを行なってきたが、これまでは基礎的な機能説明や概念整理に留まり、具体的な事例紹介までは踏み込めていなかったという。今回の講演では、長期プロジェクトの完了を機に、PDGの本格的な実運用に関する内容が初めて公開されたかたちとなる。
パベル氏は「今回のスライドは235枚あります」と冗談めかしつつも、約4,000ショットに及ぶ大規模プロジェクトを支えたPDGワークフローの詳細を、順を追って丁寧に説明していった。まずはプロジェクトの技術的なチャレンジと、それに対応するために開発された社内ツール群の概要から紹介が始まった。

初導入のパイプライン3.0で挑んだキャッシュ運用と外部連携
今回のプロジェクトでは、数年にわたってポリゴン・ピクチュアズ(以下、PPI)の社内で開発されてきたパイプライン3.0を初めて本格運用することになり、それ自体が大きな挑戦であったという。さらに、初のキャッシュフロー運用や、Unreal Engine 4による一部レンダリング処理、国外外注とのデータ連携といった技術的・運用的な課題が重なった。
特にキャッシュフローに関しては、従来のようにMayaのシーンやアニメーションカーブ単位でデータを共有するのではなく、キャッシュデータを基点としたやりとりに切り替える必要があった。これにより、アセットの整合性やパフォーマンス管理、トラフィックの最適化といった複雑な調整が求められることになったが、PDGによる自動化フローの整備が、その実現を後押しした。
独自開発のPPI Deadline Schedulerで分散処理を最適化
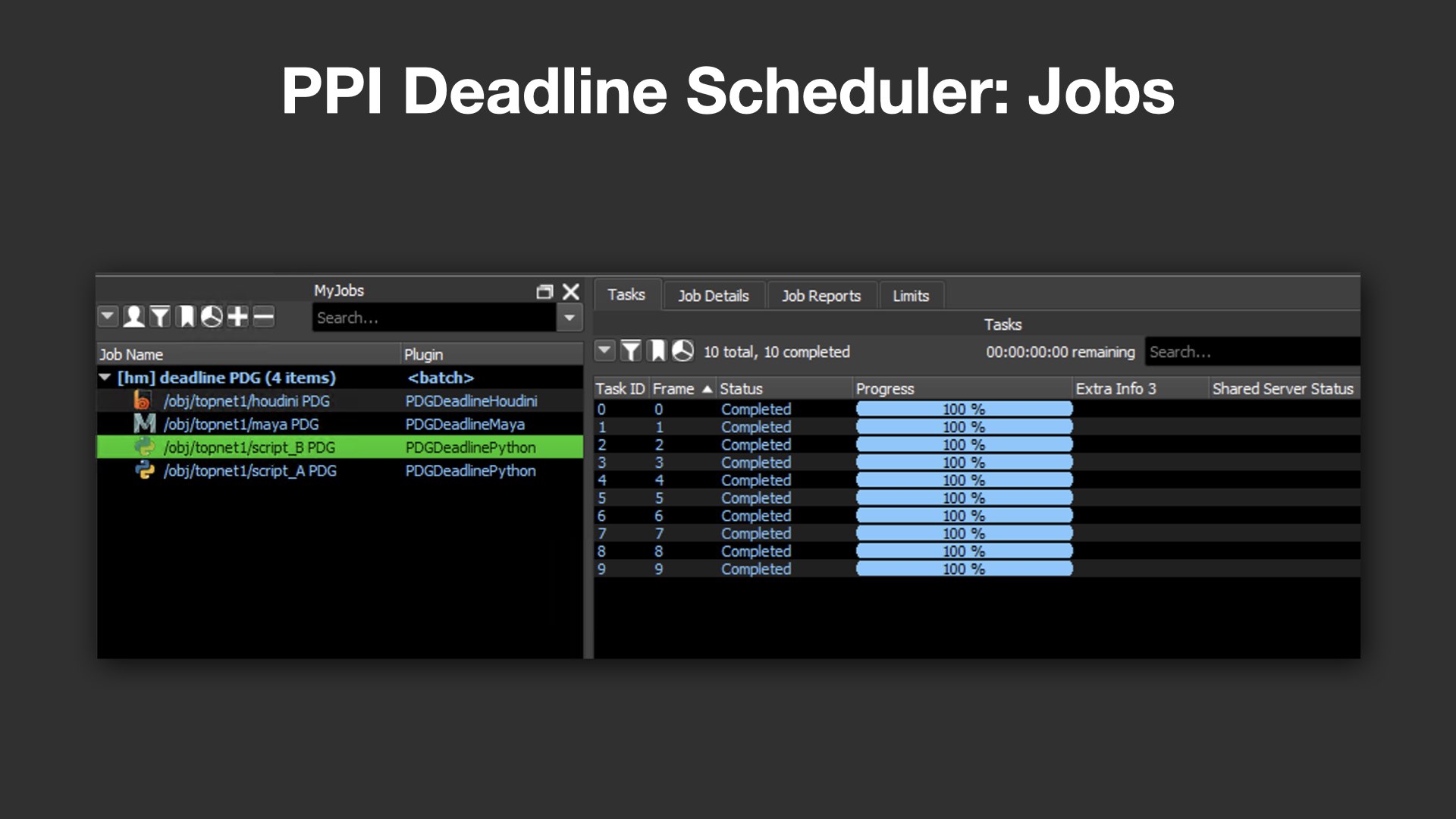
PDGの本格活用に向けて、PPIではいくつかの独自ツールも開発している。中でも重要な位置を占めるのが、ジョブのスケジューリングを担うPPI Deadline Schedulerだ。
これは、SideFXが提供するDeadline Schedulerをベースに、自社のニーズに合わせて大幅にカスタマイズされたもの。例えば、Deadlineの標準実装では一部しか対応していないDeadline Job Options全体をサポートするほか、ジョブの分割単位を柔軟に管理できるようにするなど、現場の運用に即した細かな制御が可能となっている。
パベル氏は「HoudiniのタスクとMayaのタスクが同一ジョブに混在すると、使用ライセンス数が把握できなくなってしまう」と指摘し、ジョブ単位の明確な分離の重要性を強調。また、各DCCツールの起動時に必要な環境設定を一括管理するために、PPI Launcher APIとの連携にも対応している。
さらに、HoudiniのPDGにおける分散実行で重宝されるService Block(旧:Command Chain)のサポート強化や、Deadline Web Service経由のジョブサブミット、ノードベースで直感的に扱えるスケジューラ設定など、多岐にわたる改善ポイントも網羅されており、実運用を見据えた堅実な設計がなされている。


PPI Deadline Schedulerで解決する実務上の課題
パベル氏は、独自スケジューラを開発する理由を、具体例を交えながら丁寧に解説した。
まず挙げられたのが、Deadline Job Optionsの網羅的なサポートだ。Deadline公式マニュアルには多数のジョブオプションが記載されているが、標準のスケジューラではその一部しかサポートされておらず、プロジェクトに応じた柔軟な制御が困難になるという。特にWindowsとLinuxを跨いだ環境構築では、Deadlineの初期設定自体が煩雑になりやすく、導入のハードルも高い。
また、ノードごとに異なるジョブを割り当てられない点も大きな問題だ。一般的なPDGネットワークでは、複数のタスクが同じジョブ内に集約されてしまうため、ライセンス管理やGPUリソースの割り当てが不明瞭になる。FlipbookやOpenGLレンダリングなど、特定のタスクにだけGPUを使いたいケースにおいて、適切なマシン選定が困難になるのだ。
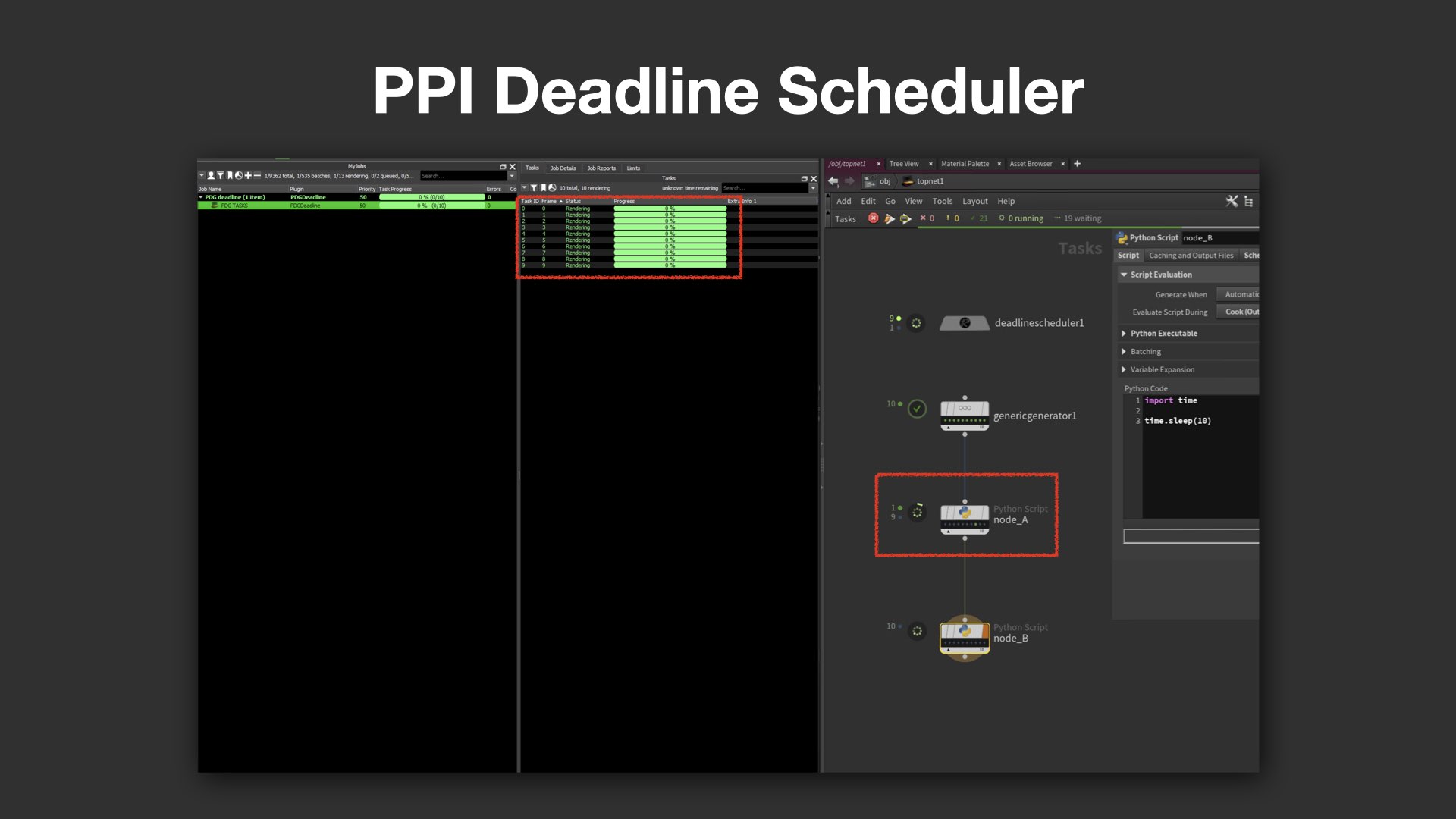
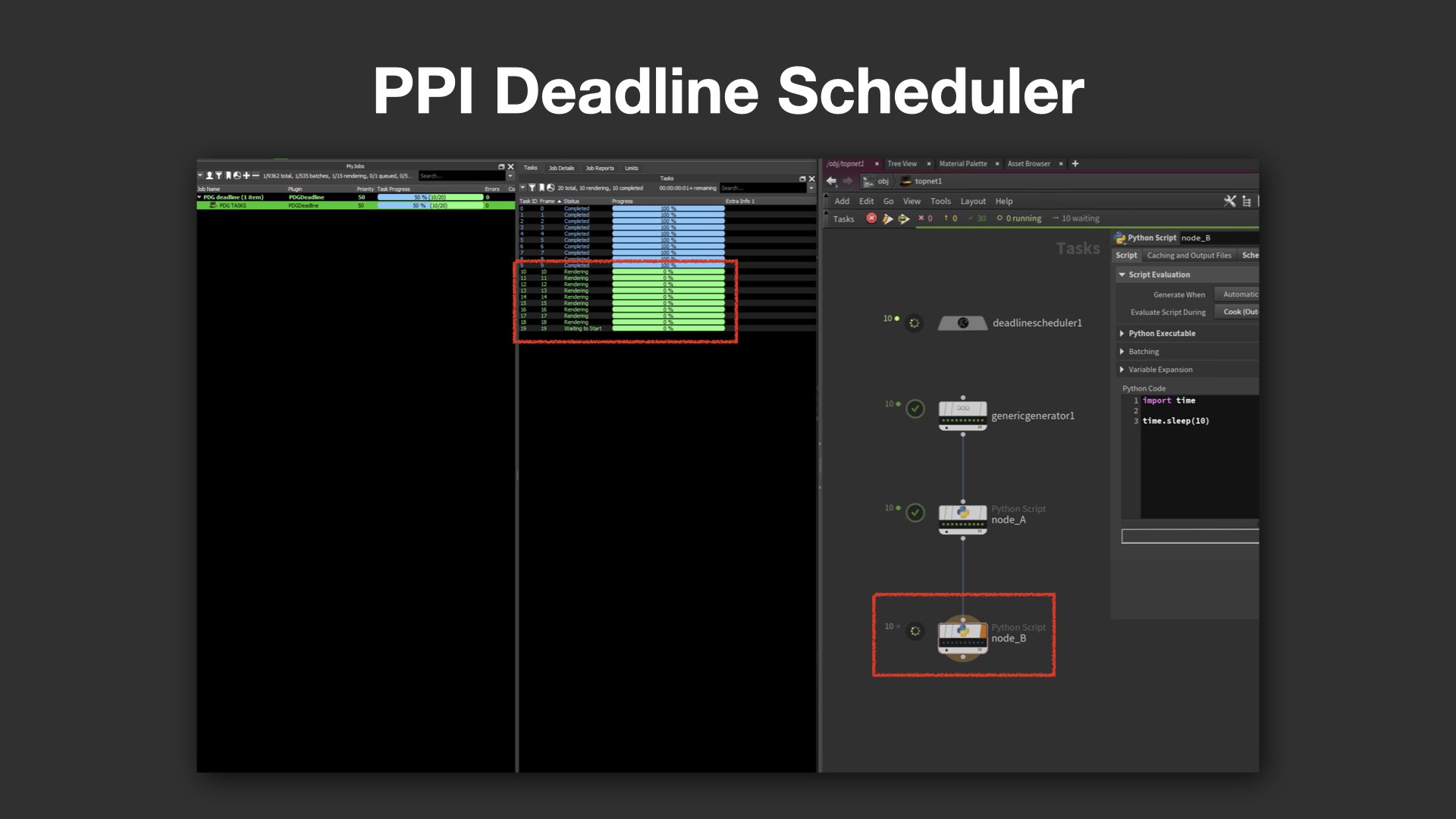
Service Blockとプロセス管理の可視化
さらに、PDG上での分散処理に欠かせない「Service Block(旧:Command Chain)」についても、Deadline側での制御が不十分だと指摘された。例えば、Mayaサーバが裏で立ち上がって処理を行なっているにもかかわらず、Deadline側からは"何もしていない"ように見えてしまうケースがある。タスク完了後にプロセスが落ちきらず、残留プロセスがリソースを圧迫するなど、実務上のリスクにつながる。
PPI Deadline Schedulerでは、こうした課題への対応が実装されている。ノードごとにジョブを明確に分離できるため、HoudiniやMayaのタスクをそれぞれ個別に管理可能。例えば、「このジョブはLinuxマシンで処理したい」といった希望も、プールやグループの設定によって柔軟に反映できる。
また、実行中のコマンドや進捗状況がリアルタイムで確認できるShared Server Status機能も搭載されており、「今どのコマンドが動作中か」、「どのWorkItemでエラーが発生したか」といった情報をDeadlineのインターフェイス上で把握できるようになっている。
パベル氏は、「プログレスバーが止まって見えると不安になる」と冗談めかしつつ、こうした可視化の重要性を強調。「PPI Deadline Schedulerでは、動いていることが"見える"こと、そしてトラブルの原因が"追える"ことを大事にしている」と語った。

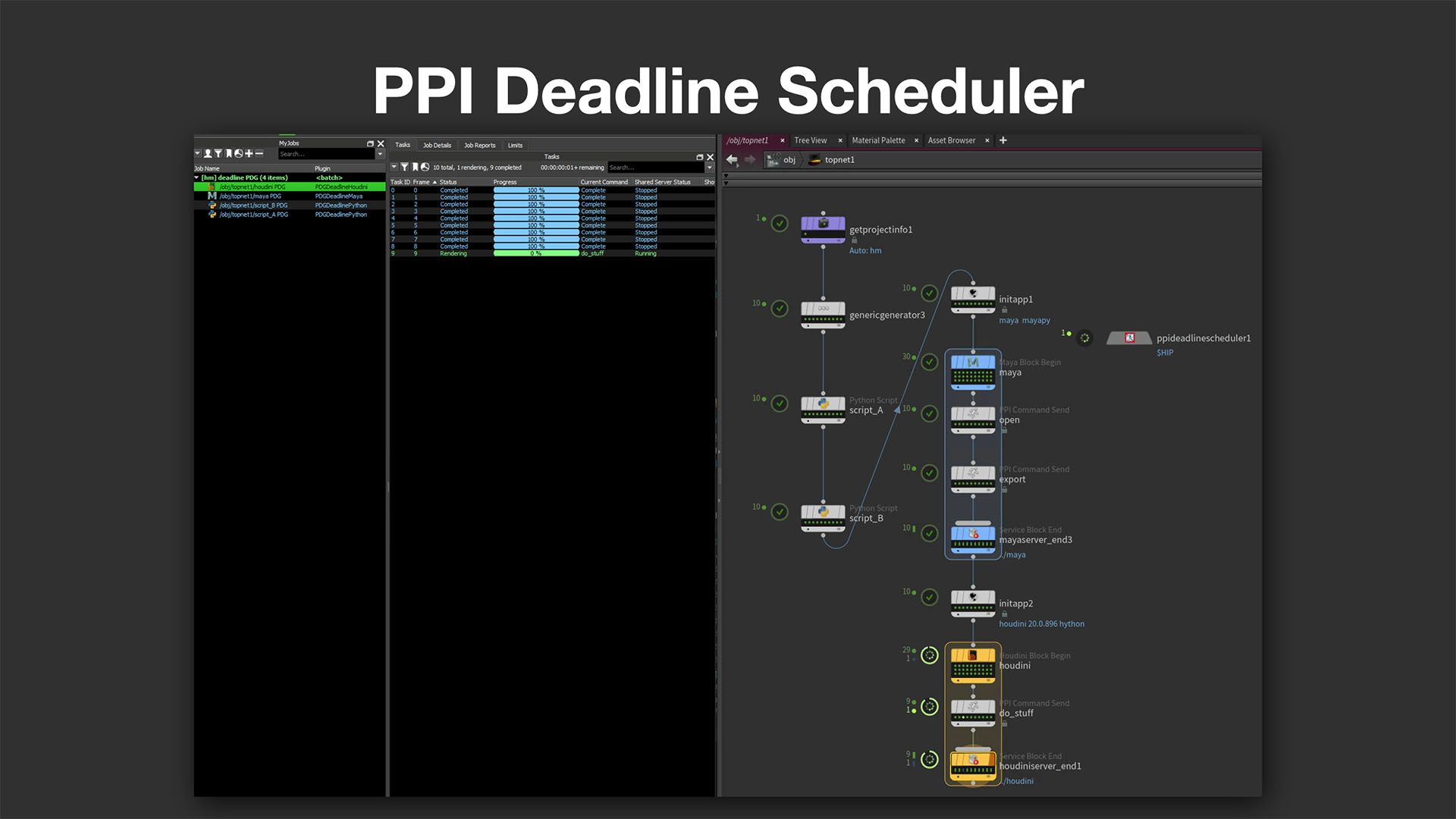
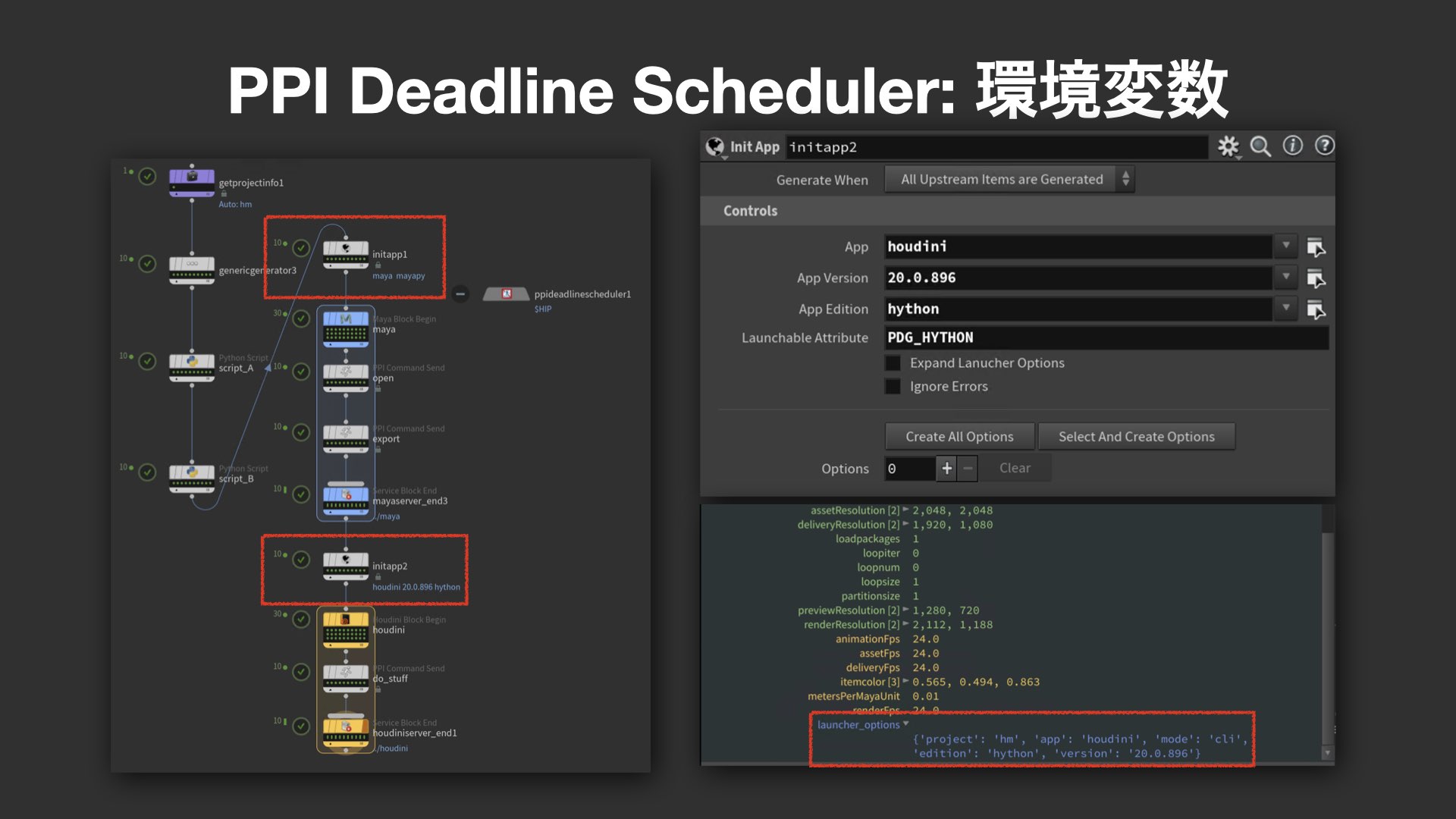
環境変数の自動生成とジョブ単位の柔軟な管理
PPI Deadline Schedulerにおける環境構築の要となるのが、initappノードだ。これはPPI Launcherのプロジェクト情報に基づき、Houdiniのバージョン指定(例:Houdini 20.0.896)や、必要な環境変数(例:PDG_HYTHONやlauncher_options)を自動で生成する役割を担う。これにより、各ノードごとに完全に独立した環境が構成され、同じHoudini設定を用いた処理が保証される。
こうした設計により、各ノードは別々のジョブとして扱われるため、Deadlineのリミット設定やマシンのグループ指定といった運用レベルでの制御も容易になる。パベル氏は「このしくみにより、Deadlineの管理機能を最大限に活用できる」と説明する。
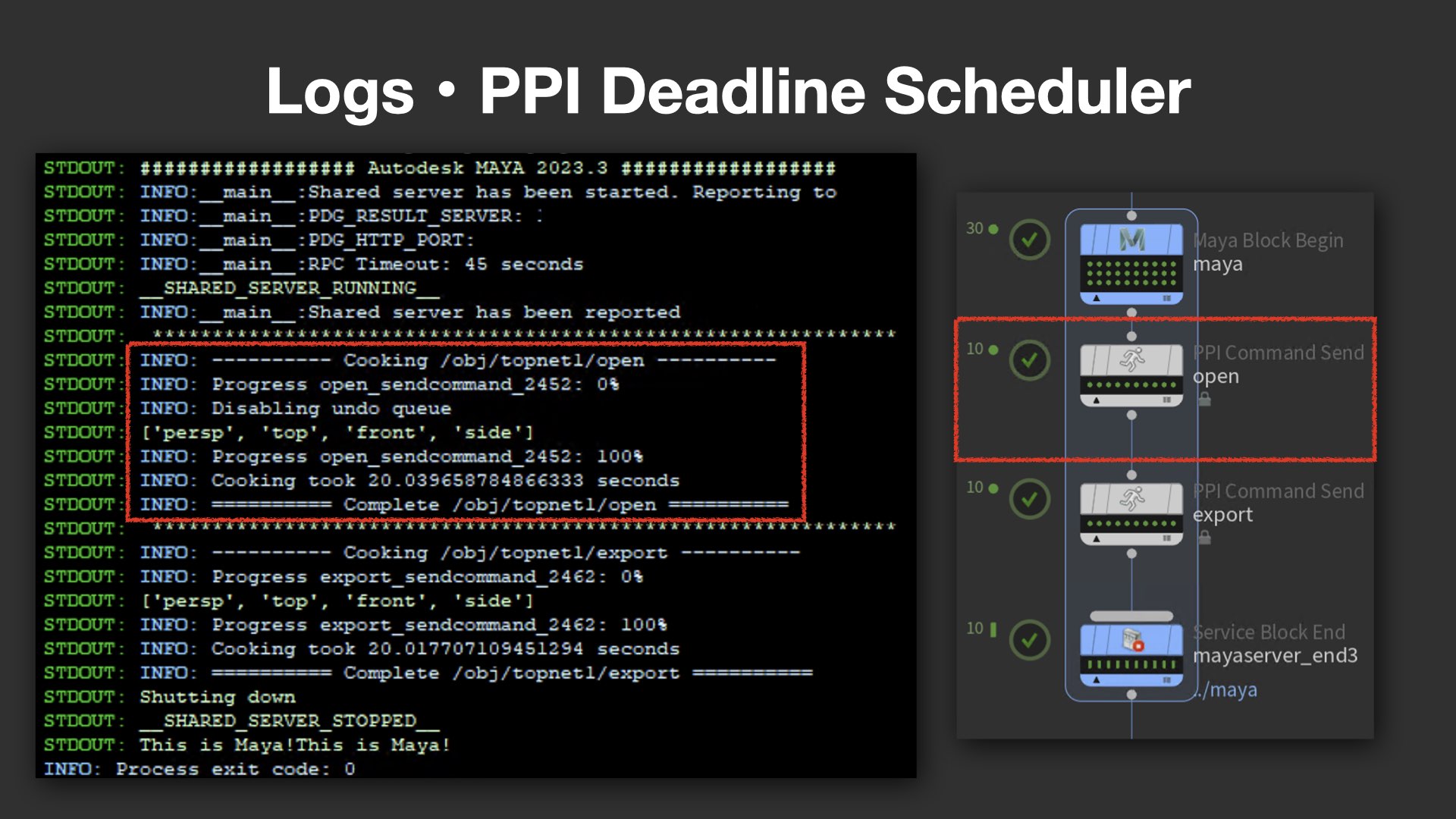
見えるログ、追えるログへ
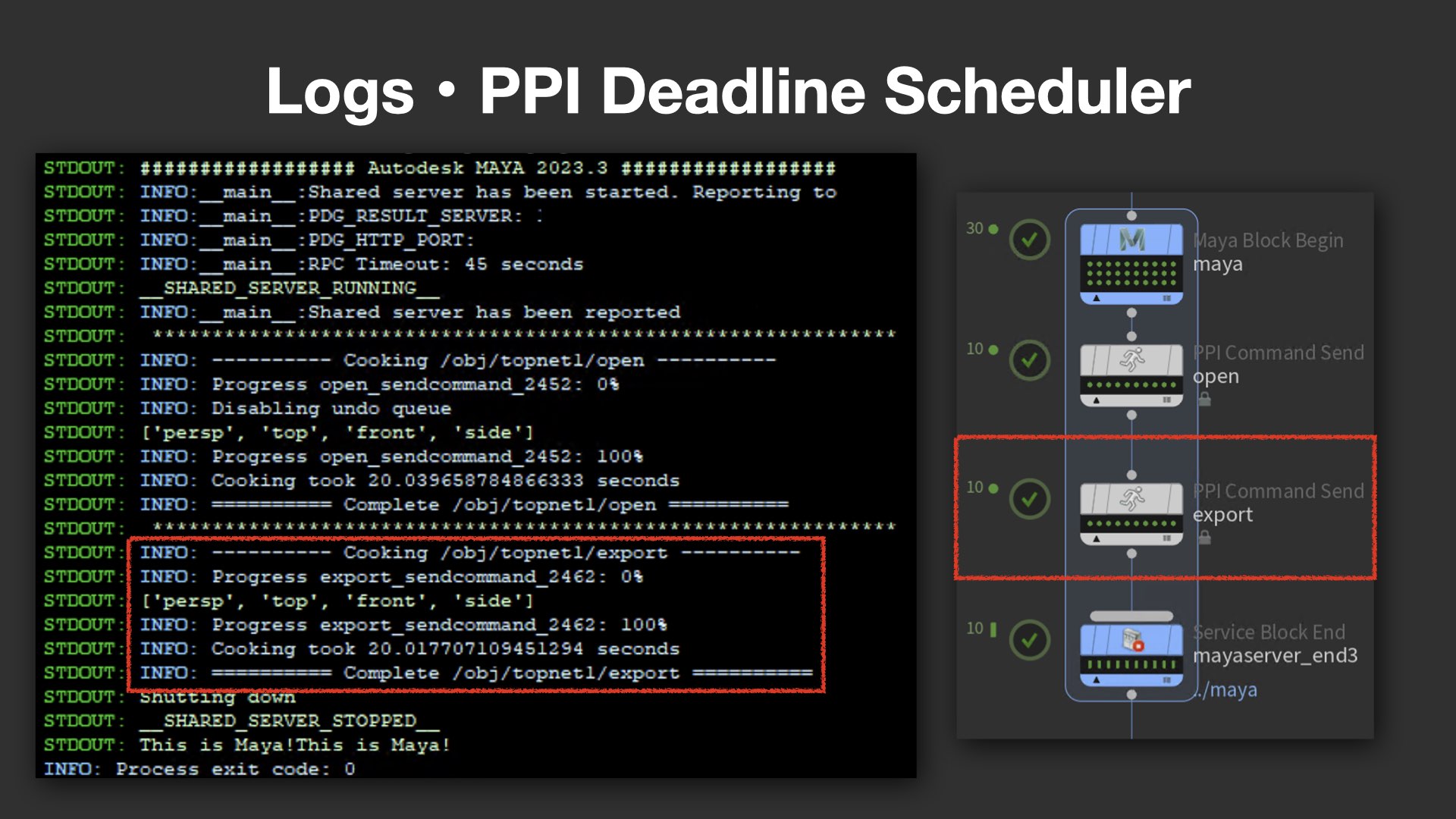
次に言及されたのは、ログ出力の改善だ。一般的なCommand Chainでは、例えば「Mayaが起動した/終了した」といった最低限の情報しかログに出力されず、トラブル発生時に詳細を追いづらい課題があった。
これに対し、PPI版のCommand Chainでは、現在どのノードが稼働中か、どのコマンドが実行中かなど、きめ細かなステータスがログとして表示される。例えば、openやexportといった処理の段階ごとに明確な出力があり、ユーザーが状況を一目で把握できるよう工夫されている。
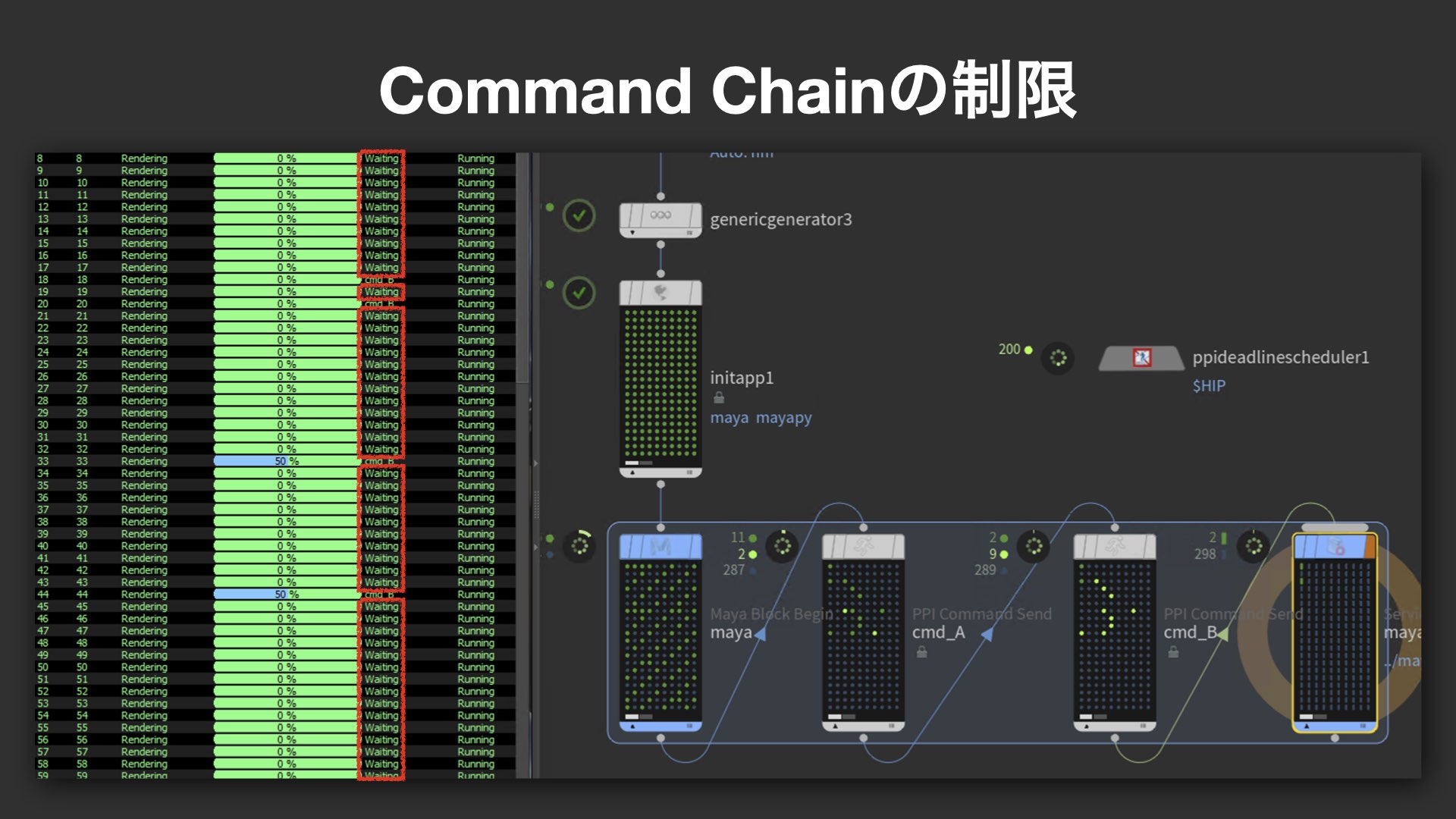
Command Chainの隠れた制限と、その突破法
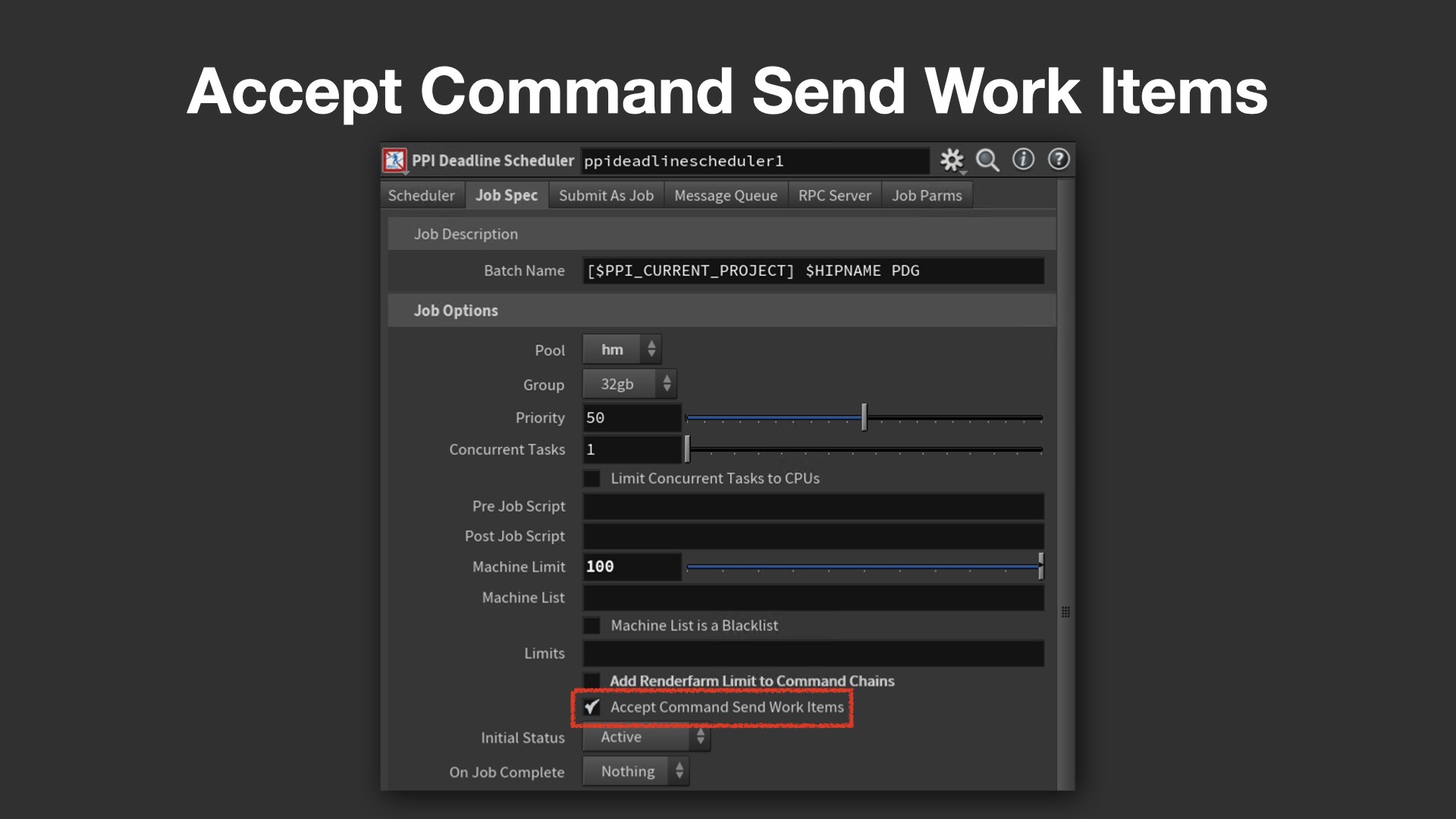
さらに、Command Chainに潜むパフォーマンス上の制限についても具体的な実例を交えて解説が行われた。大量のジョブを投げていても、実際に稼働しているタスク数が11個で頭打ちになるという現象があり、これがスレッド数に依存したIn-Process Cookingに起因することが突き止められた。
これは、Command Send自体は処理を行わず命令を送るだけにもかかわらず、内部的には同一スレッド内で処理されるため、マシンのコア数で制限されてしまうというしくみによる。PPIではこの制限を回避するため、PPI Deadline Schedulerにおいて Accept Command Send Work Items をONにし、スレッド制御のロジックを書き換えた。これにより、マシン数やコア数に制限されず、多数のタスクを並列に効率よく走らせることが可能となった。
パベル氏は、「もちろんスレッド数が増えることでオーバーヘッドは増すが、少なくとも従来のような制限には縛られない」と述べ、独自スケジューラによる柔軟な拡張性のメリットを強調した。
Deadline Web Serviceの導入による、サブミット処理の高速化
パベル氏は、Deadlineのサブミット処理におけるパフォーマンス改善についても言及した。特に注目すべきは、Deadline Web Serviceの導入と、それに付随するDeadline Python APIの活用である。
一般的なHoudiniのPDGにおけるジョブサブミットでは、Deadline Commandが使用されることが多い。しかし、Deadline Commandは処理の立ち上がりが遅く、場合によってはフリーズしてしまうこともあるという。さらに、それが原因でHoudini自体が応答しなくなるケースも報告されており、安定運用上のリスクとなっていた。
そこでPPIでは、Web Service経由でジョブを投げられるように設定を変更。DeadlineのWebサーバを1台立て、そこに対してPython APIを用いてサブミットする構成を採用したことで、起動速度や応答性が大幅に改善された。
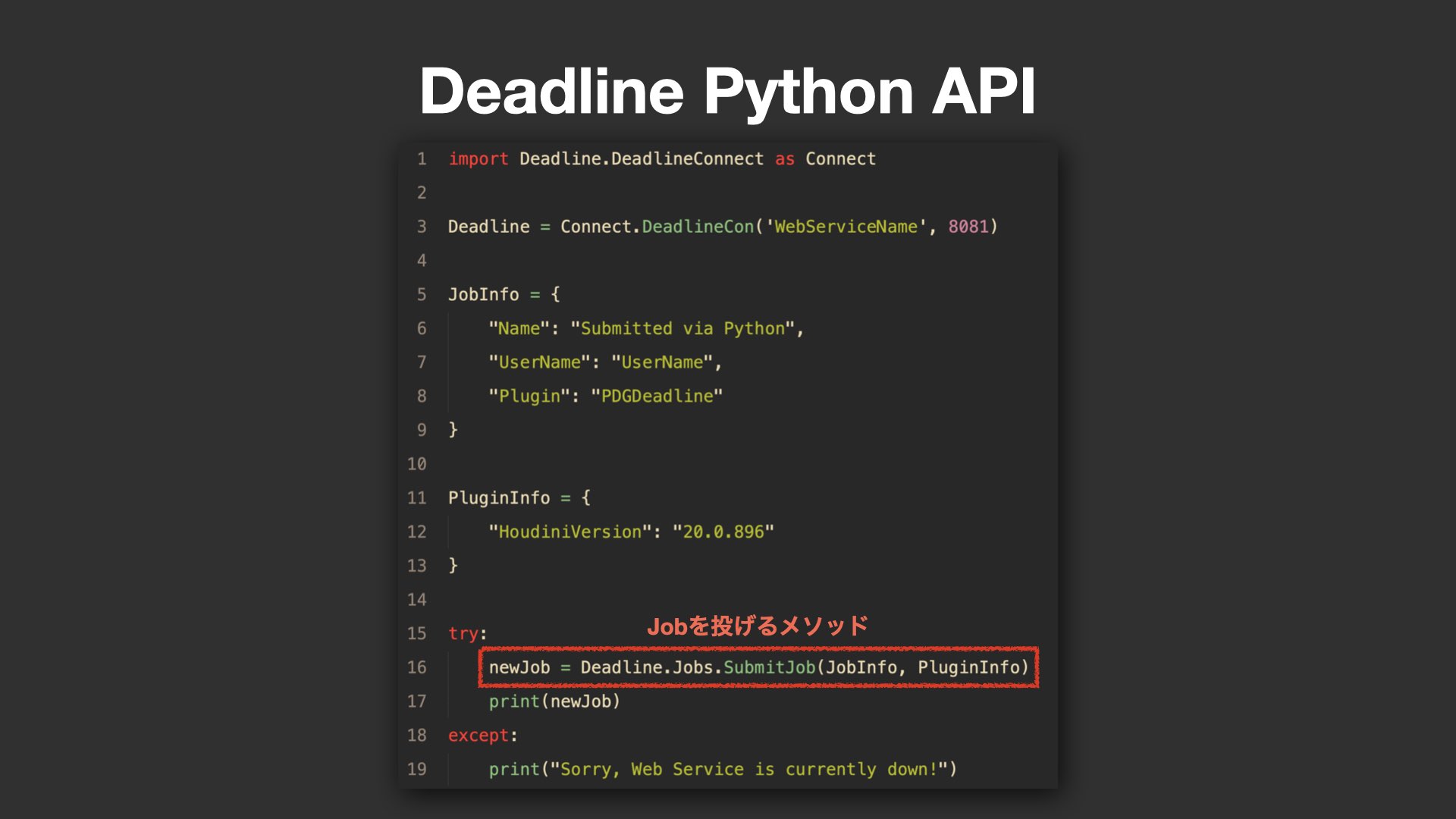
Deadline Python APIでシンプルかつ安全にサブミット
Deadline Python APIでは、ジョブ情報(JobInfo)やプラグイン情報(PluginInfo)を、ファイル出力を介さずにPythonの辞書(Dictionary)として直接渡すことが可能だ。これにより、ファイル入出力に起因する待機時間が不要となり、スクリプト全体の処理も高速化された。
加えて、APIベースのアプローチでは、処理失敗時にPythonの例外として返されるため、Houdini本体のフリーズといった致命的な問題も回避しやすくなる。実装も非常にシンプルで、数行のコードで完結するため、今後Deadlineを使ったサブミットを検討する現場にとっては有効な選択肢となるだろう。
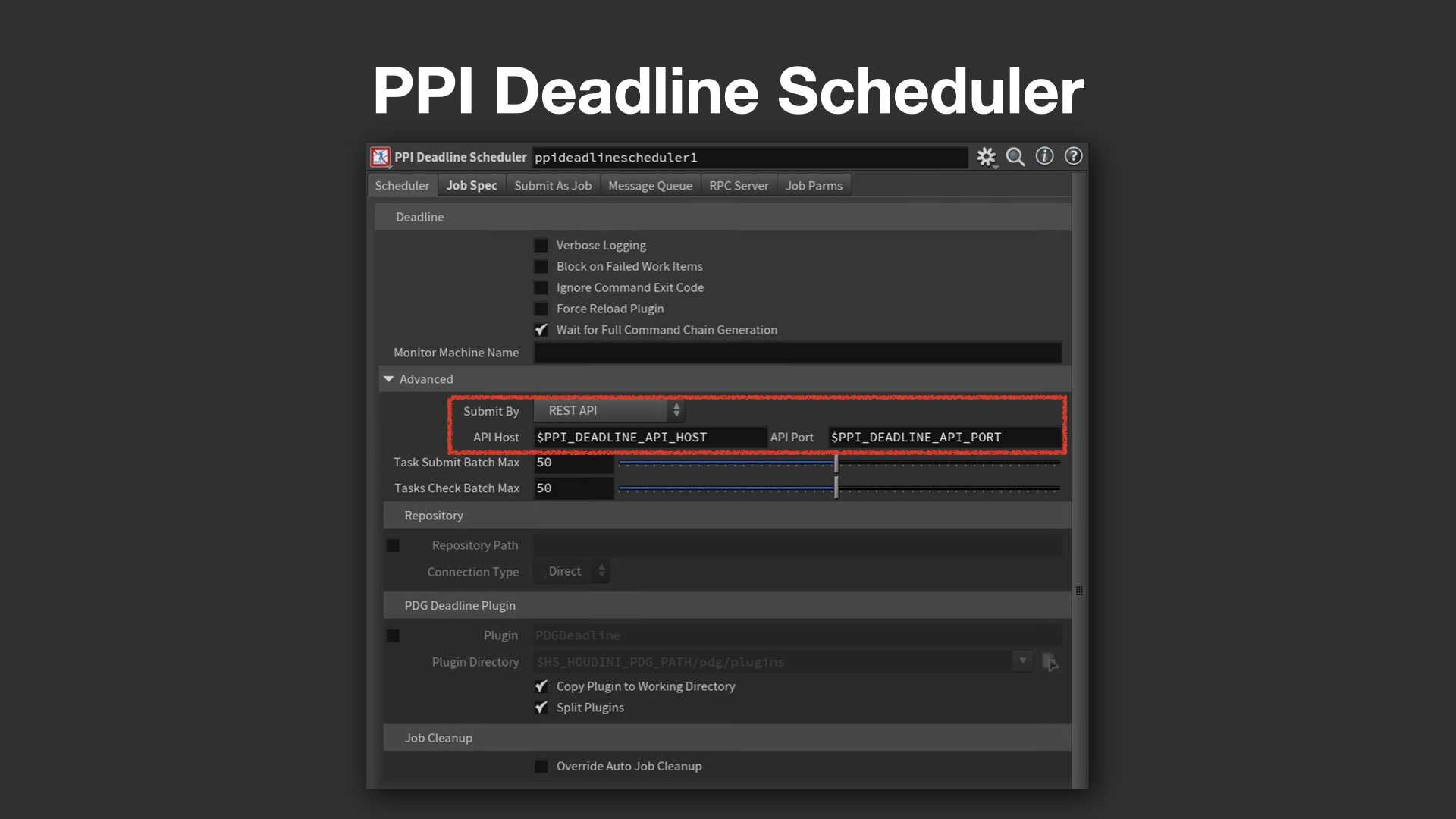
PPI Deadline Schedulerでは、ジョブの送信方法を制御するSubmit Byというパラメータを実装。ここでは、Web Serviceのホスト名やポート番号が格納された環境変数 PPI_DEADLINE_API_PORT を参照している。もしWebサーバに接続できない場合には、Fallbackとして自動的にDeadline Commandを使用する処理も組み込まれており、耐障害性にも配慮された設計となっている。

PDGパブリッシュフローの中核、PPI Publishとは
ここからは、PPIにおけるキャッシュパブリッシュの中核機構である、PPI Publishのしくみが詳しく紹介された。
PPI Publishは、各工程をフェーズ(Phases)としてフォルダ単位で管理するしくみだ。例として、アニメーション(anm)、コンポジット(cmp)、ライティング(lgt)、リール(rel)などのほか、Unreal Engineのリアルタイムレンダリング用のrta(Real Time Animation)などが挙げられた。これらフェーズの内部には、さらにComponents(要素)が分類されており、例えばanmフェーズでは、アニメーションカーブ(anm)、ベイク済みシーン(anmBake)、カメラ(anmCam)、アニメーションシーン(anmScn)、そしてタイムドライバー(anmTimeDrv)と呼ばれるアニメーションのコマ落としの情報などが含まれる。
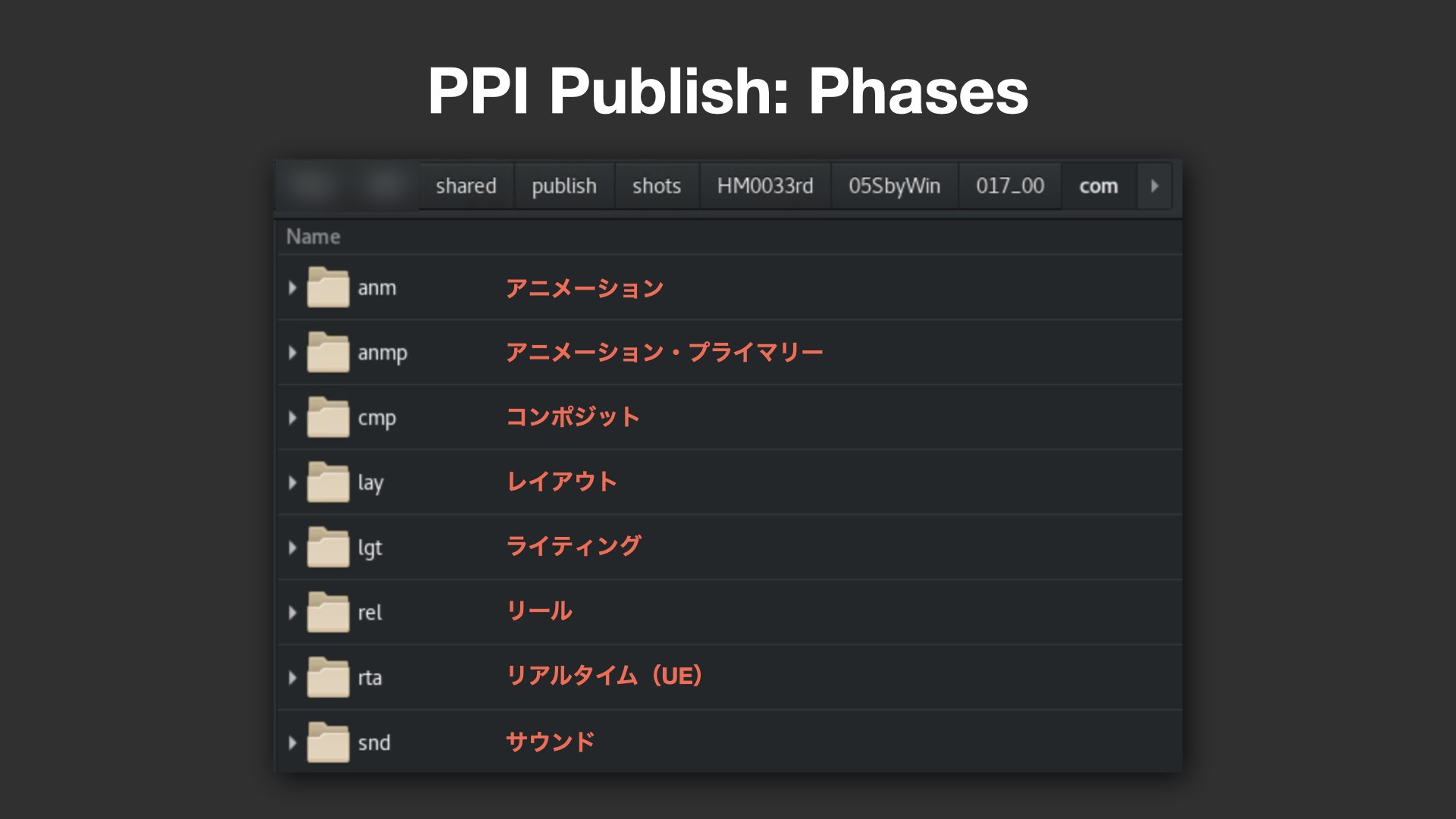
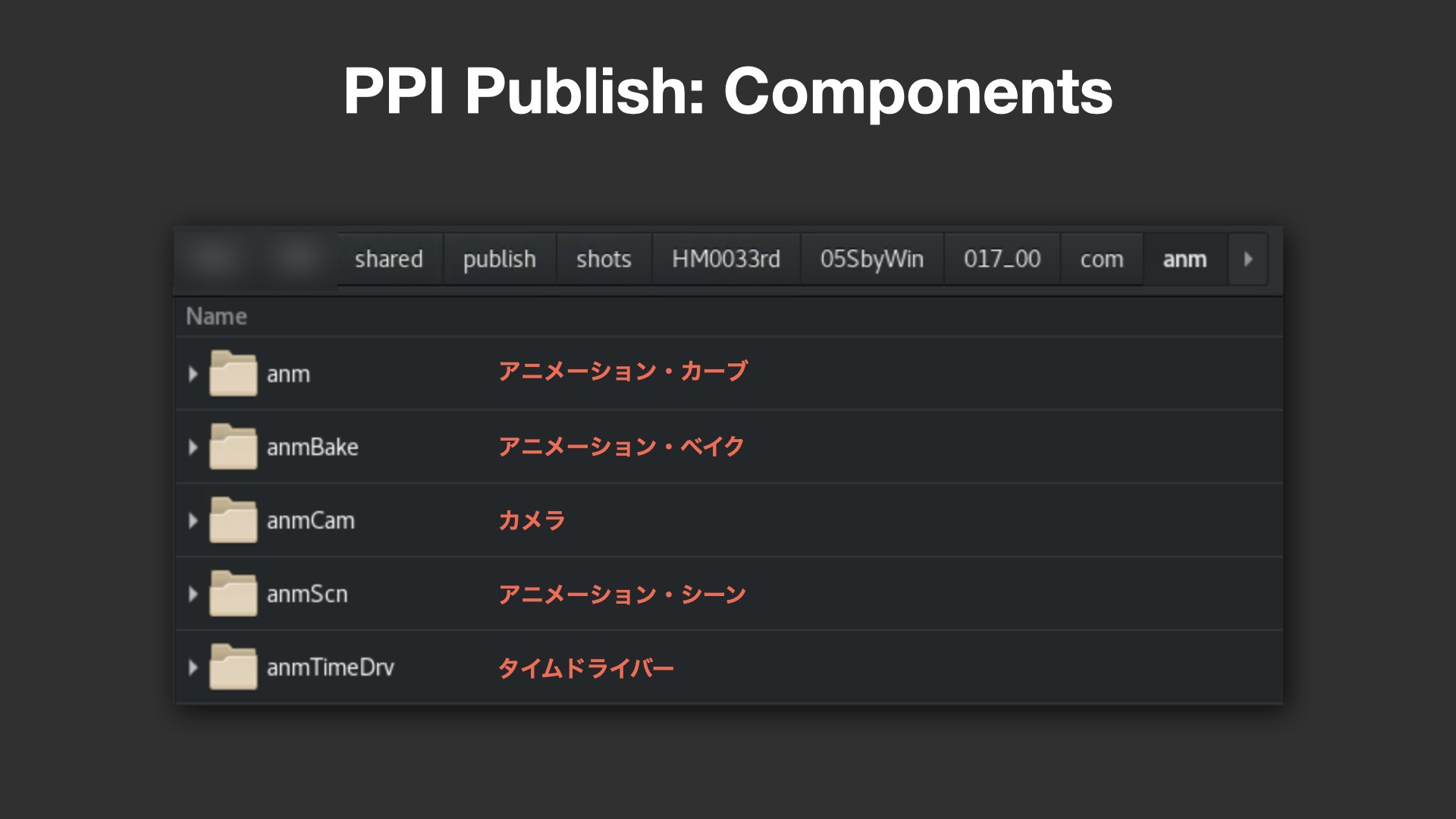
メタデータに支えられた柔軟な運用設計
各ComponentsにはRevisions(バージョン管理)フォルダがあり、その中にはデータファイルと共にメタデータ(JSON形式)が格納される。メタデータは、単なる補助情報に留まらず、下流工程の自動化や最適化を支える極めて重要な情報源となっている。
例えばアニメーションシーンにおいては、「どのアセットが含まれているか」という情報をメタデータとしてもたせることで、Mayaを起動しなくても事前にアセットリストを取得可能となる。また、キャッシュ出力に必要な依存関係(dependencies)情報も明記されており、例えばほかのキャラクターにコンストレインされた小物(プロップ)など、正しく出力するために必要な読み込み対象が事前に判断できるようになっている。
さらに、Referenceファイルに対するEdits(編集)の有無によって、実際にキャッシュ出力が必要か否かの判断も可能。これらのしくみにより、重たいシーンの読み込みや無駄な処理を大幅に削減できるという。
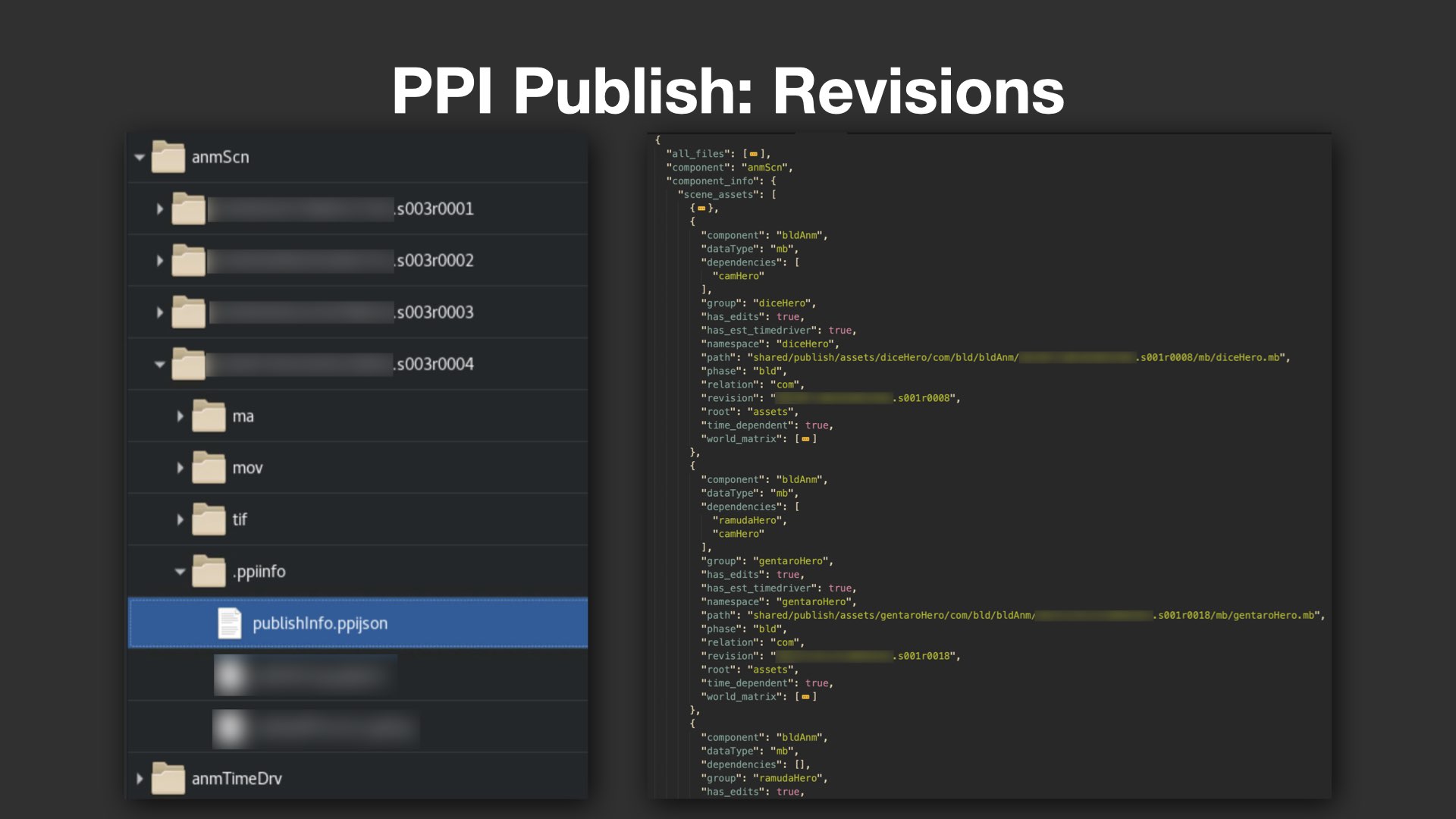

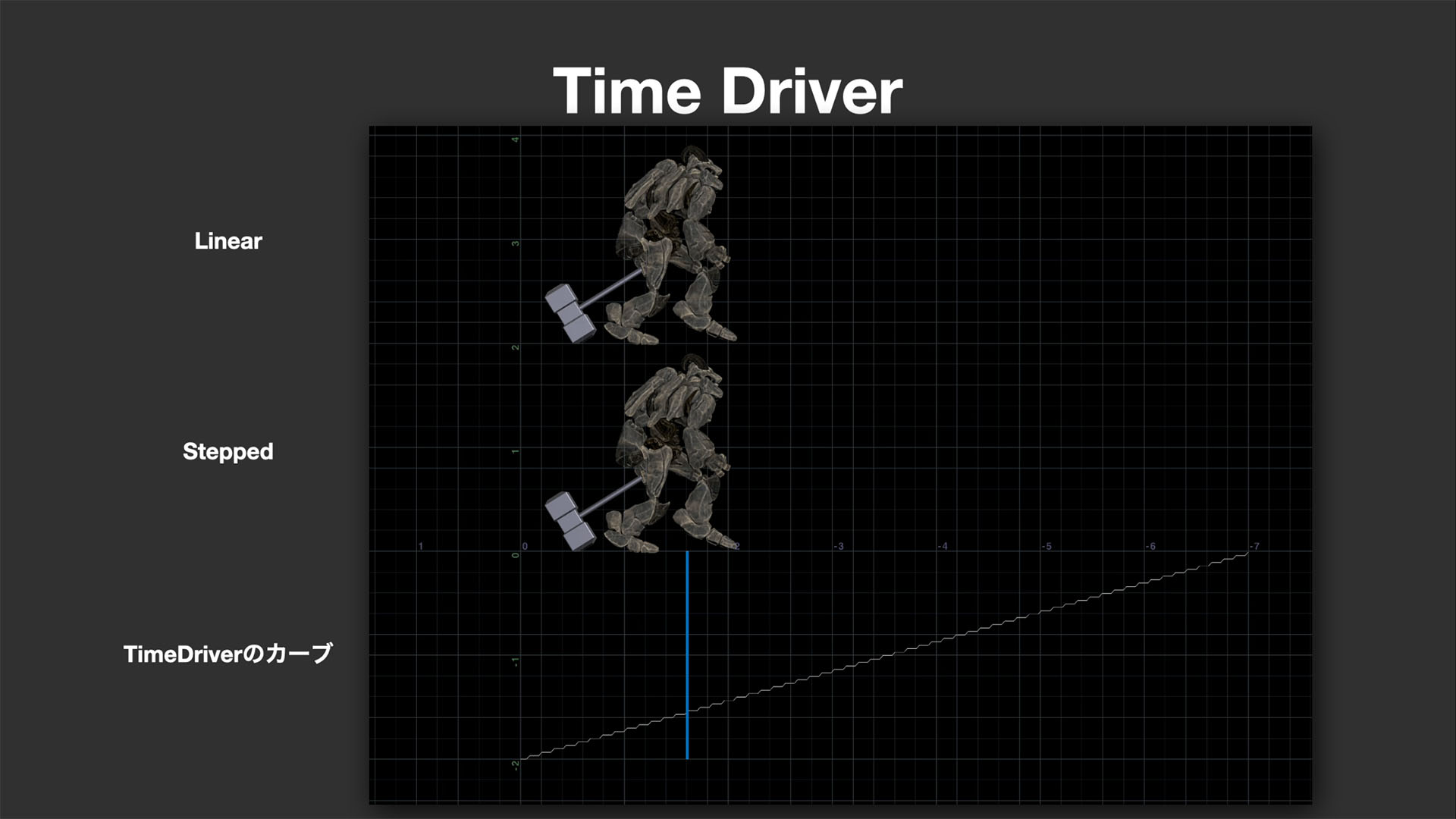
タイムドライバーとキャッシュ整合性の維持
PPIのワークフローにおける大きな特徴のひとつが、タイムドライバーだ。これはアニメーションカーブのコマ落としの情報を保持するしくみであり、例えばLinearアニメーション(通常再生)とSteppedアニメーション(間引き再生)を切り替えるタイミングや、どの部位にコマ落としが適用されているかを明示できる。
このしくみによって、例えばクロスシミュレーションのような物理演算を行う際にはLinearデータを、確認用やレンダリングにはSteppedデータを使う、といった柔軟な切り分けが可能になる。また、プロジェクトによってはリグの各部(手足やRoot Transform)に異なるタイミングでタイムドライバーが適用される場合もあり、そうした複雑な再生制御にも対応できる。
メタデータにはそのほかにも、Maya内のnamespace情報や、アセットが時間に依存する動きをもっているかどうかを示すtime_dependent属性、そしてワールドトランスフォーム(変換行列)などが記録されている。これらの情報は、アセットが静的に配置されているだけか、実際にアニメーションを伴うかを判別する助けとなり、不要なキャッシュ出力の回避や、正確な位置情報の保持に役立っている。
データの共有範囲を制御するPPI DataSync
社内外の制作メンバー間で、正確かつ効率的にデータや設定情報を共有・制御するための要となる、PPI DataSyncと、Pipeline Parametersについても解説された。
PPI DataSyncは、社内制作データと、協力会社とのやり取りを管理するためのしくみで、データをsharedとunsharedの2つに分類する。sharedに属するもの、例えばパブリッシュされたデータやツールなどはクラウド上のPPI CENTRALにアップロードされ、協力会社がそこからダウンロードして使用できる。一方、unsharedに分類されたデータ(作業中の一時ファイルやキャッシュなど)はクラウド上にアップされず、社内のみで管理される。
このようなしくみにより、機密性や作業中の安定性を保ちつつ、効率的なデータ連携が実現されている。

上書き階層をもつPipeline Parameters
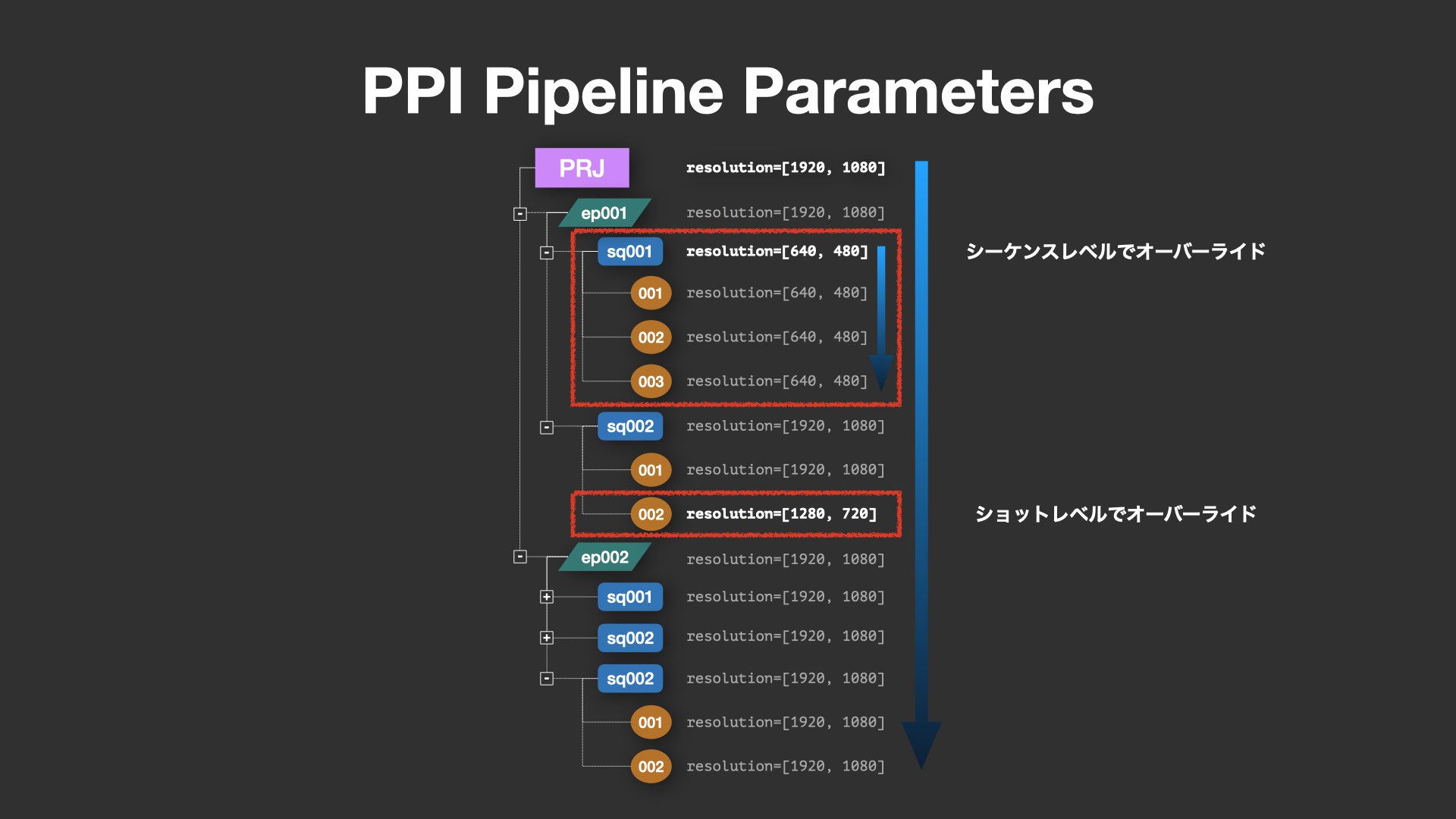
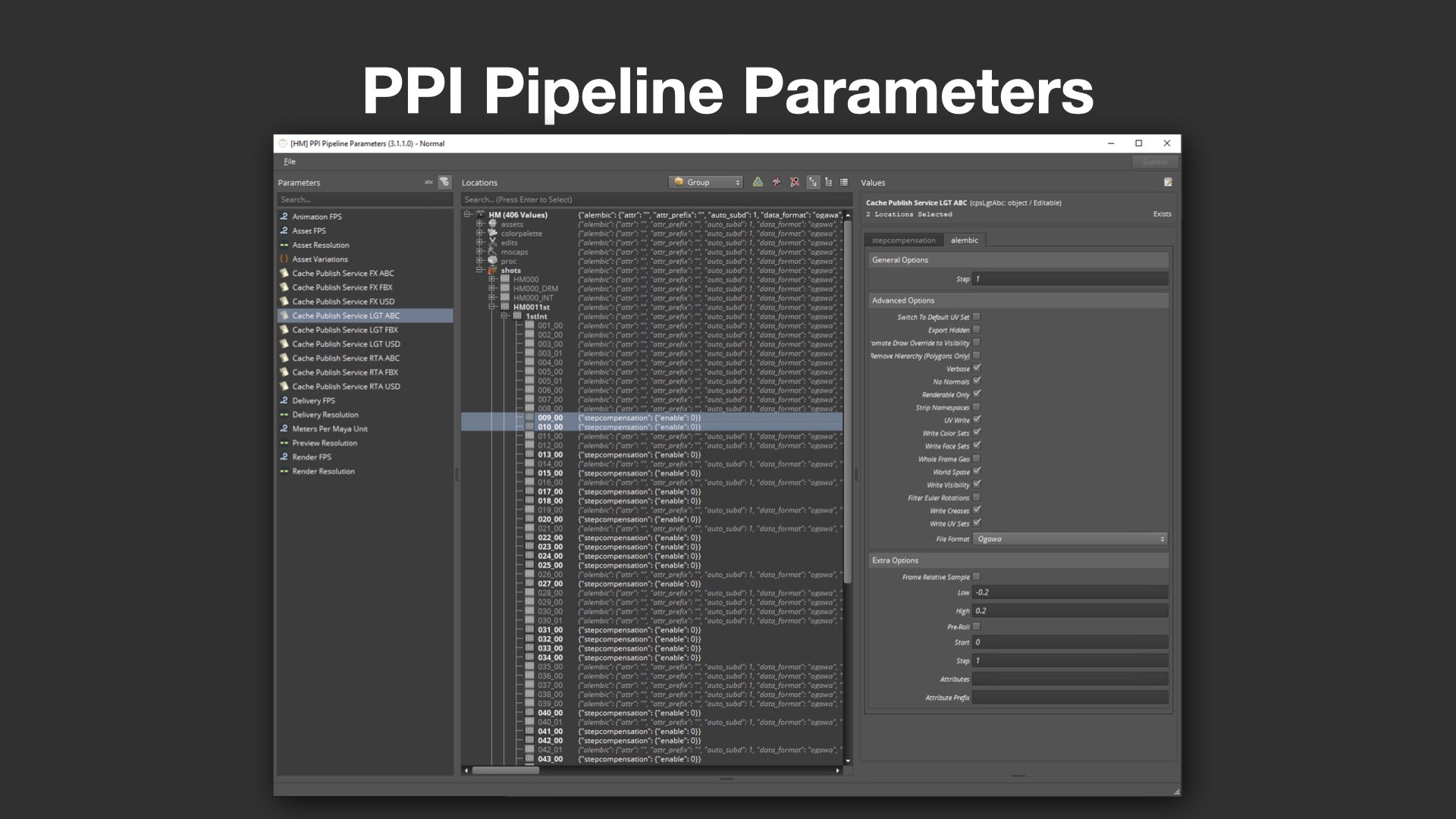
次に紹介されたのが、PPI Pipeline Parametersだ。これは、解像度やアセットリスト、出力設定といったパラメータ情報を階層構造で管理する独自のメタデータ機構である。PPIではプロジェクトの進捗やデータの管理にFlow Production Tracking(以下、Flow PT)も使っており、PPI Pipeline ParametersはFlow PTの下層に増設するかたちで運用している。
特徴的なのはオーバーライド階層(Override Hierarchy)のしくみで、例えばシーケンス単位で設定された解像度が、その配下のショットに自動的に継承される構造になっている。一方で、個別のショットで特定のパラメータを上書き(オーバーライド)することも可能。これにより、全体の整合性を保ちつつ、例外的な設定変更にも柔軟に対応できる。
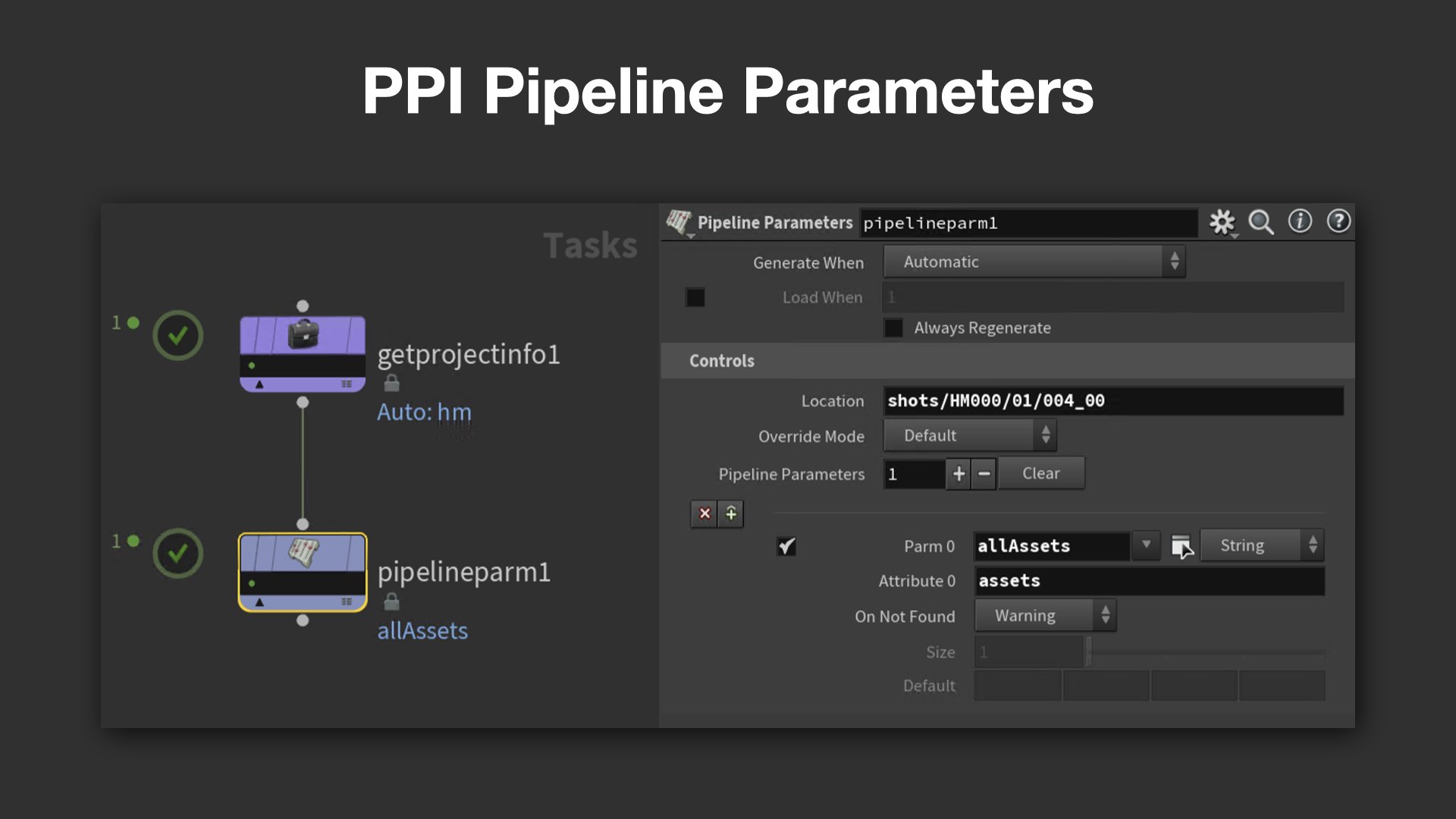
Pipeline Parametersは、PDG上の処理にも活用されている。専用ノードを通じてパラメータ情報を読み込み、指定されたアトリビュートに値を設定することで、PDGネットワーク上のWorkItemに対して動的な処理分岐が可能になる。
さらに、パベル氏がペットプロジェクトとして開発した独自の編集UIも紹介された。もともと存在しなかった編集画面を自ら実装し、例えばAlembicの書き出し設定などもGUIから手軽に行えるようにするなど、開発・運用両面での改良を積極的に進めている姿勢が垣間見えた。
メタデータを軸に構築される高度な自動化フロー
講演前半の最後には、PPIが構築したPDGベースの自動化フローにおいて重要な役割を果たす、メタデータ取得用ノードやMaya関連ノード群の解説が行われた。
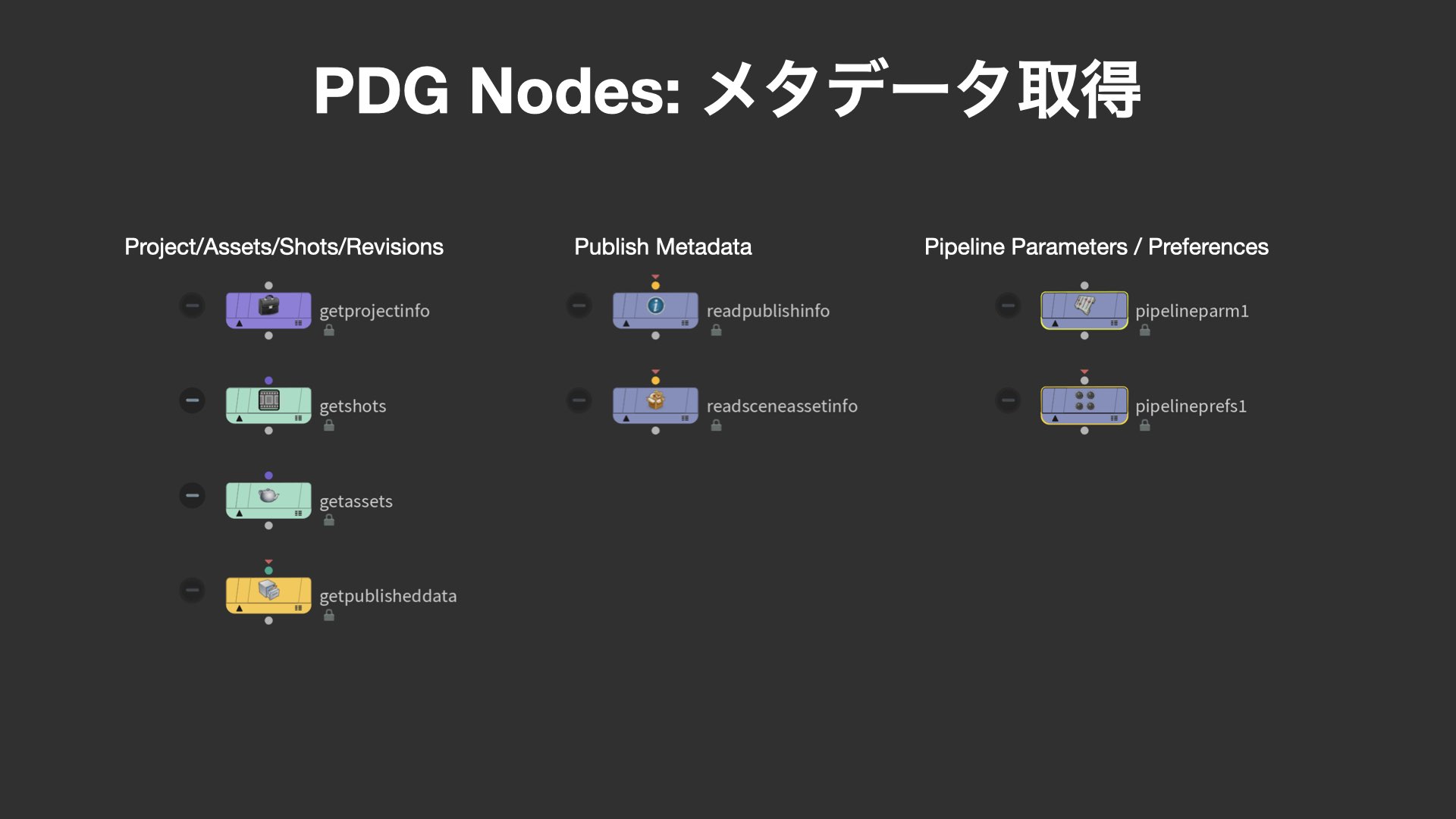
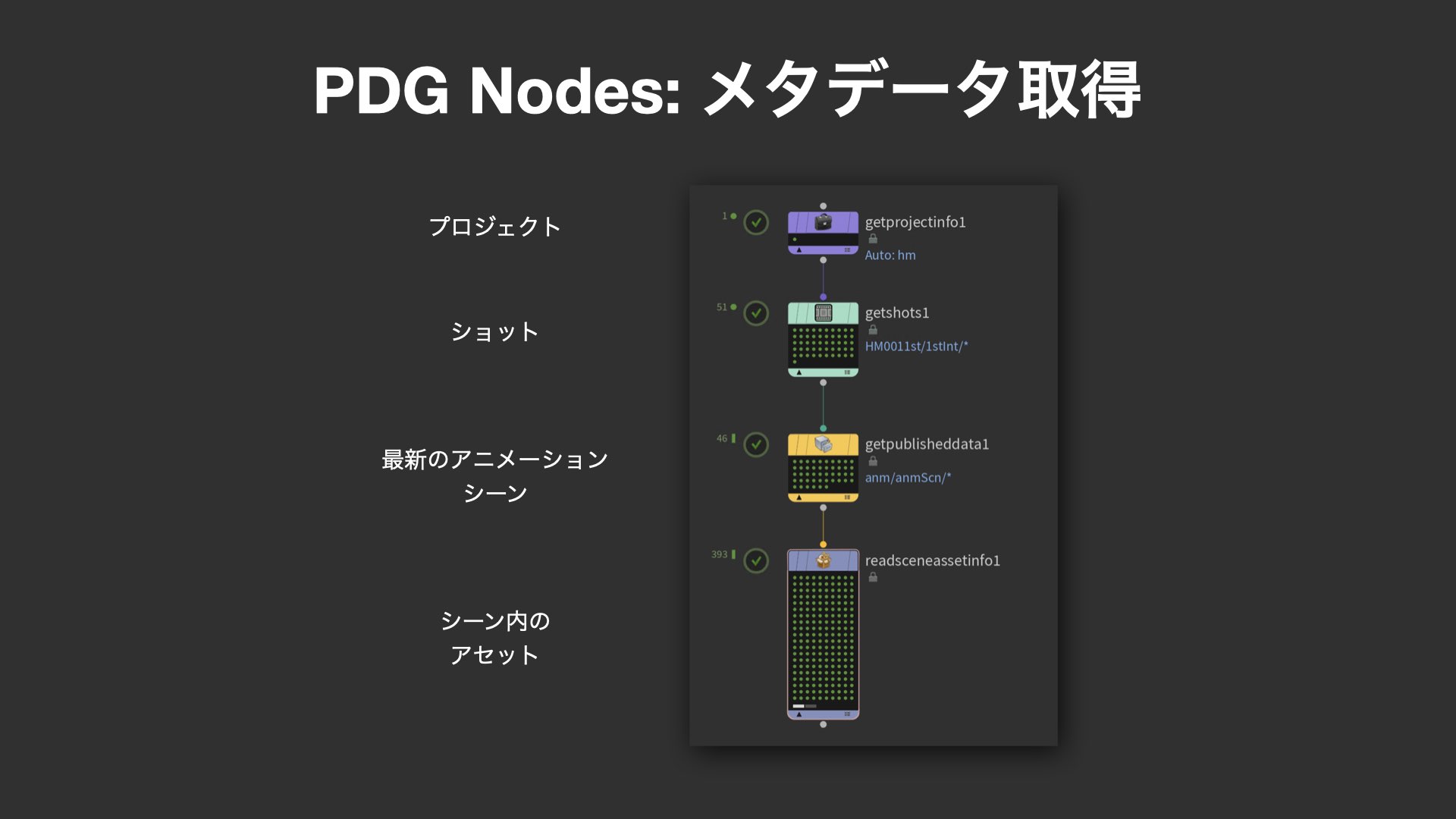
まず紹介されたのは、プロジェクトやショット、アセット情報などのメタデータを取得する一連のPDGノード群だ。Get Project Infoノードを起点に、Get Shotsノードでプロジェクト内の特定ショットをパターンマッチで抽出し、Get Published Dateによって該当ショット内の最新のアニメーションシーン(Revisions)を取得。その後 Read Scene Asset Infoノードを使って、該当シーンに含まれるアセットの一覧を取得できる。
これらのメタデータは、後続のPDG処理や作業ノードを正しく構築するための初期セットアップにおいて極めて重要な役割を果たす。
Mayaの処理を自動化する専用ノード群
続いて解説されたのは、PDG内でMayaの操作を自動化するための豊富なノード群だ。Mayaノードには、以下のような分類が存在する:
・File/Reference:ファイルの読み込みやリファレンス管理
・Export:Alembic、USD、ASS、社内レンダラ形式(PPixel)などの出力
・Import:HoudiniからMayaへのデータ受け渡し
・Edit:レンダーレイヤーやアトリビュート編集
・Utility:任意のMELスクリプトの実行
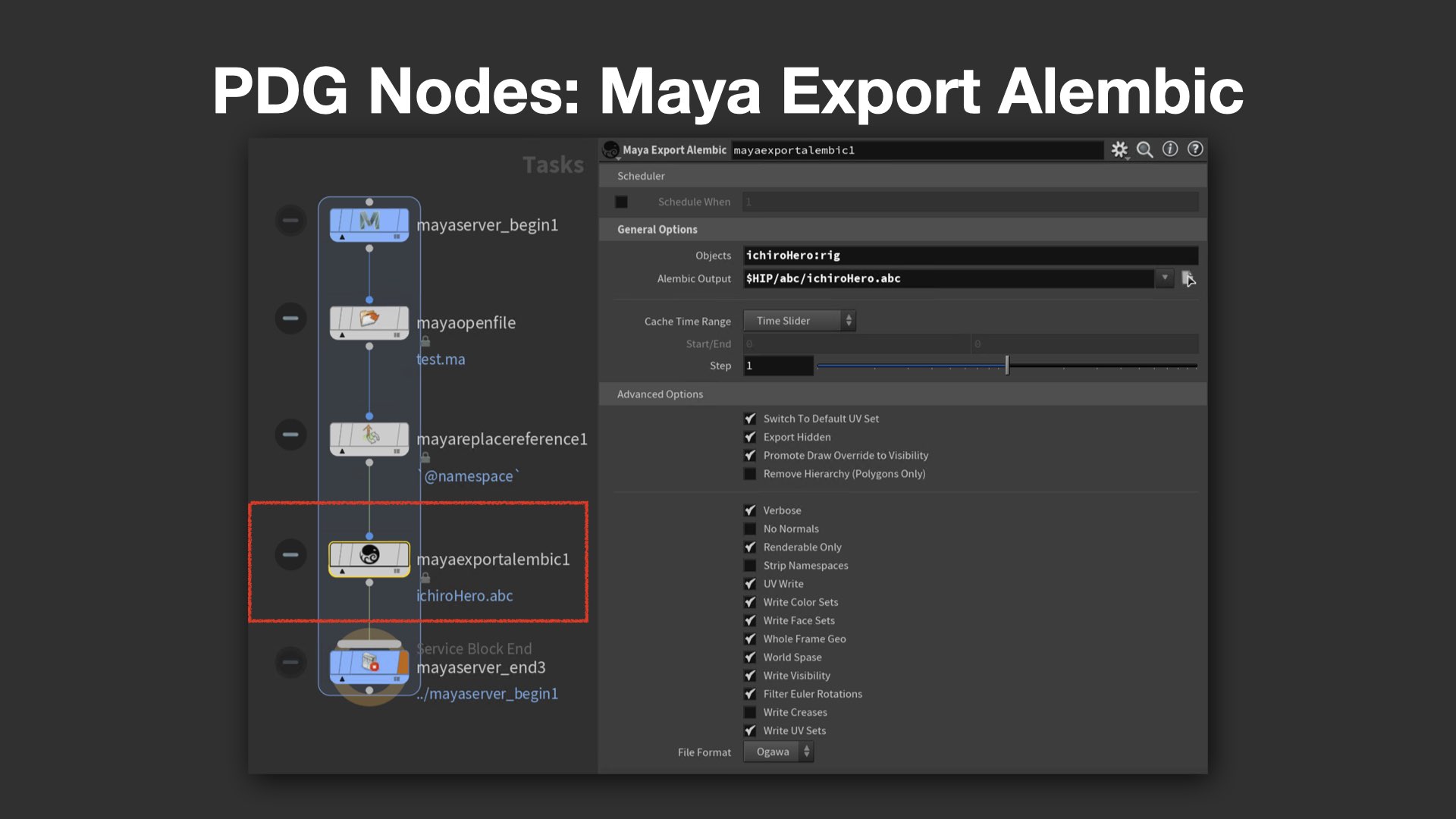
これらの中から代表的なノードとして、Maya Open File、Maya Replace Reference、Maya Export Alembicの3つが紹介された。
例えばMaya Replace Referenceノードでは、Namespace情報を指定し、アニメーション用のアセットからレンダリング用アセットへの差し替えを自動で実行できる。さらに Maya Export Alembicノードでは、指定ノードを正確に抽出してAlembicに書き出す処理が自動で行われ、PDGによる大量処理の自動化に直結している。

講演前半のまとめ
本講演の前半では、PPIにおけるPDGの本格導入事例として、パイプライン構築・キャッシュパブリッシュ・データ共有・メタデータ活用・Mayaの自動化ノードのしくみなどが、実例を交えて丁寧に紹介された。
約1時間におよぶ解説を通して、同社が「アーティストが意識せずとも使えるPDG運用」を目指して、細部までチューニングしている様子が随所にうかがえた。特に、DeadlineやPDGの制限に対してカスタム開発で対処する姿勢は、受講者にとって大きな示唆となったはずだ。
この続きとなる「Houdini Tech Seminarレポート No.3」では、より実践的な事例を通してPDGによる運用の実態と、今後の展望が語られる。ぜひご期待いただきたい。
TEXT&EDIT_尾形美幸/Miyuki Ogata(CGWORLD)
文字起こし_遠藤大礎/Hiroki Endo
PHOTO_大沼洋平/Yohei Onuma













