
ByteDance社のAI研究チーム・ByteDance Seedは11月15日(土)、単眼深度推定技術「Depth Anything 3」を発表した。任意の数の画像入力から、カメラポーズの既知・未知を問わず、空間的に整合性の取れたジオメトリを予測する基盤モデル。ソースはGitHubで、デモはHugging Faceで公開されている。用途や規模に応じた複数のモデルシリーズが、2種類のライセンス(Apache-2.0またはCC BY-NC 4.0)で提供される。
After a year of team work, we're thrilled to introduce Depth Anything 3 (DA3)!
— Bingyi Kang (@bingyikang) November 14, 2025
Aiming for human-like spatial perception, DA3 extends monocular depth estimation to any-view scenarios, including single images, multi-view images, and video.
In pursuit of minimal modeling, DA3… pic.twitter.com/7fK5tVTE2F
Aiming for human-like spatial perception, DA3 extends monocular depth estimation to any-view scenarios, including single images, multi-view images, and video.
In pursuit of minimal modeling, DA3 reveals two key insights:
・A plain transformer (e.g., vanilla DINO) is enough. No specialized architecture.
・A single depth-ray representation is enough. No complex 3D tasks.
Three series of models have been released: the main DA3 series, a monocular metric estimation series, and a monocular depth estimation series.人間のような空間認識を目指し、Depth Anything 3(DA3)は単眼深度推定を、単一画像・多視点画像・動画を含む「あらゆる視点(Any-view)」のシナリオへと拡張しました。
最小限のモデリング(Minimal Modeling)を追求する中で、DA3は2つの重要な洞察を明らかにしました:
・プレーンなTransformer(素のDINOなど)で十分であり、特殊なアーキテクチャは不要であること
・単一の「Depth-Ray」表現で十分であり、複雑な3Dタスク設定は不要であること
今回は、メインのDA3シリーズ、単眼メトリック(実寸)推定シリーズ、単眼深度推定シリーズの3つのモデル群を公開しました。

Depth Anything 3(DA3)は、どのような視点からでも視覚空間を正確に復元することを目的として開発されたAIモデル。その設計思想の根幹は、高度な3D処理能力を維持しつつ、モデルの構造を極限まで単純化することにある。従来の手法では、複数の画像から立体感を計算するために「コストボリューム」と呼ばれる複雑な仕組みが必要だったが、DA3はこれを撤廃し、画像認識で標準的に用いられるTransformer(DINOv2)のみで構成している。
このシンプルな構造の実現には、「Depth-Ray」という独自のデータ表現が用いられている。これは奥行き(Depth)と視線方向(Ray)を統合したものであり、この単一の指標を学習させるだけで、本来は別々の処理が必要な「1枚の画像からの奥行き推定」「複数画像からの立体構築」「カメラ位置の特定」といった多様なタスクを、1つのモデルで統一的にこなすことが可能となった。
DA3は新しい視点からの画像を生成する3D Gaussian Splatting(3DGS)技術や、ロボットが移動しながら地図を作成するSLAM技術などにも適用できる。特に大規模な空間認識においては、従来の手法で課題となっていた位置情報のズレ(ドリフト)を劇的に低減できることが確認されているとのことだ。
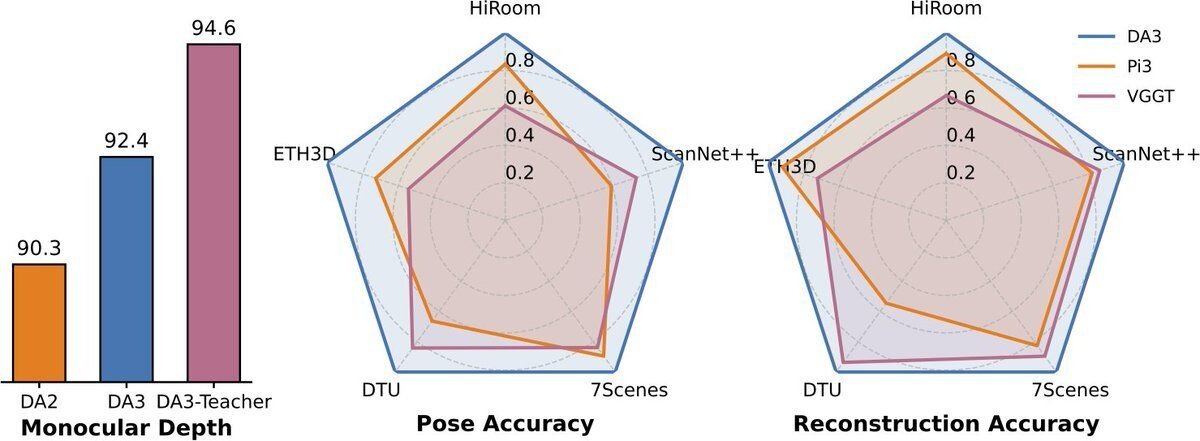
We establish a new visual geometry benchmark covering camera pose estimation, any-view geometry (TSDF reconstruction) and visual rendering.
DA3 sets a new SOTA across all 10 tasks, surpassing prior SOTA VGGT by an average of 35.7% in camera pose accuracy and 23.6% in geometric accuracy.
Moreover, it outperforms Depth Anything V2 in monocular depth estimation while being comparable in detail and robustness.
There are multiple abilities enabled by Depth Anything 3:私たちは、カメラポーズ推定、任意視点ジオメトリ(TSDF再構成)、そして視覚的レンダリングを網羅する、新たな視覚幾何学ベンチマークを確立しました。
DA3は、これら全10タスクにおいて新たなSOTA(最高水準)を達成しており、従来のSOTAであるVGGTと比較して、カメラポーズ精度で平均35.7%、幾何学的精度で平均23.6%上回る結果を出しています。
さらに、単眼深度推定においてはDepth Anything V2を凌駕する性能を示しつつ、ディテール(詳細さ)やロバスト性(堅牢性)においても同等のレベルを維持しています。
Depth Anything 3によって、以下のような複数の機能が実現可能となります:
SLAM for large-scale scenes
— Bingyi Kang (@bingyikang) November 14, 2025
Accurate visual geometry estimation improves SLAM performance. DA3 significantly reduces drift in large-scale environments, even better than COLMAP, which takes more 48 hours to complete.
(3/n) pic.twitter.com/T4edonNLW2
SLAM for large-scale scenes
Accurate visual geometry estimation improves SLAM performance. DA3 significantly reduces drift in large-scale environments, even better than COLMAP, which takes more 48 hours to complete.大規模シーンにおけるSLAM
正確なビジュアルジオメトリ(視覚的な幾何形状)の推定は、SLAMのパフォーマンスを向上させます。DA3は大規模な環境においてドリフトを大幅に低減し、処理完了までに48時間以上を要するCOLMAPをも凌ぐ性能を発揮します。
Feed-forward gaussian splatting
— Bingyi Kang (@bingyikang) November 14, 2025
By freezing the entire backbone and training a DPT head on several datasets to predict 3DGS parameters, our model achieves very strong and generalizable novel view synthesis capability.
(4/n) pic.twitter.com/i3IkIOtYiU
Feed-forward gaussian splatting
By freezing the entire backbone and training a DPT head on several datasets to predict 3DGS parameters, our model achieves very strong and generalizable novel view synthesis capability.フィードフォワード型Gaussian Splatting
バックボーン全体を凍結(固定)し、複数のデータセットを用いて3DGSパラメータを予測するようDPTヘッドを学習させることで、当モデルは非常に強力かつ汎用性の高い新規視点合成(Novel View Synthesis)能力を実現しています。
Spatial perception from multiple cameras
— Bingyi Kang (@bingyikang) November 14, 2025
Given several images of different viewpoints from a vehicle, DA3 estimates stable and fusible depth maps, enhancing autonomous vehicles' environmental understanding.
We believe this is also achievable in robotics.
(5/n) pic.twitter.com/2p32E2CrHY
Spatial perception from multiple cameras
Given several images of different viewpoints from a vehicle, DA3 estimates stable and fusible depth maps, enhancing autonomous vehicles' environmental understanding.
We believe this is also achievable in robotics.マルチカメラによる空間認識
車両から撮影された異なる視点の画像が複数与えられた場合、DA3は安定的かつ融合可能な(fusible)深度マップを推定し、自動運転車の環境理解能力を向上させます。 私たちは、これがロボティクス(ロボット工学)の分野においても実現可能であると考えています。
■Depth Anything 3: Recovering the Visual Space from Any Views(プロジェクトページ、英語)
https://depth-anything-3.github.io/
■Depth Anything 3: Recovering the Visual Space from Any Views(GitHub)
https://github.com/ByteDance-Seed/Depth-Anything-3
■Depth Anything 3: Recovering the Visual Space from Any Views(Hugging Face)
https://huggingface.co/spaces/depth-anything/depth-anything-3
CGWORLD関連情報
●Metaの3D生成AI技術「SAM 3D」発表! 単一の2D画像から精密な3Dオブジェクトや人物を再構築、GitHubとHugging Faceでコード&データ公開

Metaが画像セグメンテーションAIの最新モデル「Segment Anything Model 3(SAM 3)」と、単一画像から3Dモデルを再構築する「SAM 3D」を発表。ソースコードはGitHubで公開されているが、独自ライセンスによって「SAM 3」基盤モデル、「SAM 3D Body」、「SAM 3D Objects」が明確に区分されている。データセットはHugging Faceで公開されているほか、同社AI技術のプレイグラウンド「Meta AI Demos」ではブラウザ上でSAM 3Dをテストできる。
https://cgworld.jp/flashnews/01-202511-Meta-SAM3D.html
●ByteDanceの3Dアセット生成基盤モデル「Seed3D 1.0」発表! 画像1枚から物理シミュレーションに対応可能な高品質アセットを生成

ByteDance Seedが3Dアセット生成基盤モデル「Seed3D 1.0」を発表。単一の画像から物理シミュレーションに対応可能な高品質3Dアセットを生成できる。Seed3D 1.0は同社運営の企業向けクラウドサービスプラットフォーム「Volcano Engine」で利用できる。
https://cgworld.jp/flashnews/01-202511-Seed3D.html
●NVIDIAが3DGS技術「LongSplat」発表! スマホで撮影したカジュアルな動画から空間の3DGSモデルを生成し、自由な視点の映像をつくり出す

国立陽明交通大学とNVIDIAの研究チームが、スマートフォンなどで気軽に撮影した長尺かつ複雑な動きを含む動画から3D Gaussian Splattingモデルを生成し、新しい視点の画像を生成するフレームワーク「LongSplat」を発表。GitHubではNVIDIAライセンスでコードが公開されている。
https://cgworld.jp/flashnews/01-202509-LongSplat.html











