
Meta社は11月19日(水)、画像セグメンテーションAIの最新モデル「Segment Anything Model 3(SAM 3)」と、単一画像から3Dモデルを再構築する「SAM 3D」を発表した。ソースコードはGitHubで公開されているが、独自ライセンスによって「SAM 3」基盤モデル、「SAM 3D Body」、「SAM 3D Objects」が明確に区分されている。データセットはHugging Faceで公開されているほか、同社AI技術のプレイグラウンド「Meta AI Demos」ではブラウザ上でSAM 3Dをテストできる。
Introducing SAM 3D, the newest addition to the SAM collection, bringing common sense 3D understanding of everyday images. SAM 3D includes two models:
— AI at Meta (@AIatMeta) November 19, 2025
SAM 3D Objects for object and scene reconstruction
SAM 3D Body for human pose and shape estimation
Both models achieve… pic.twitter.com/jLpBX2cY9P
Introducing SAM 3D, the newest addition to the SAM collection, bringing common sense 3D understanding of everyday images. SAM 3D includes two models:
SAM 3D Objects for object and scene reconstruction
SAM 3D Body for human pose and shape estimation
Both models achieve state-of-the-art performance transforming static 2D images into vivid, accurate reconstructions.SAMコレクションの最新作、「SAM 3D」を発表します。これは、日常的な画像に対して「常識的な(人間のような感覚での)」3D空間理解をもたらす技術です。SAM 3Dには以下の2つのモデルが含まれます。
SAM 3D Objects:物体およびシーンの3D再構築(復元)用
SAM 3D Body:人体のポーズおよび形状推定用
どちらのモデルも、静止した2D画像を鮮明かつ正確な3Dモデルへと変換するタスクにおいて、最先端(SOTA)の性能を達成しています。
Metaが掲げるコンピュータビジョンの基盤モデルプロジェクト「Segment Anything Model(SAM)」の第3世代「Segment Anything Model 3(SAM 3)」では、従来の「人」や「車」といった単純なラベルだけでなく、「赤いストライプの傘」といった自然言語による複雑な記述でのセグメンテーションを可能にした。このSAM 3の認識能力を3次元再構築に応用したのが「SAM 3D」となる。
SAM 3Dは1枚の静止画から対象物の3D形状・ポーズ・テクスチャを数秒で復元する。従来のフォトグラメトリが多数の画像を必要としたのに対し、SAM 3Dは推論によって不可視部分(オクルージョン)を補完し、立体化する。
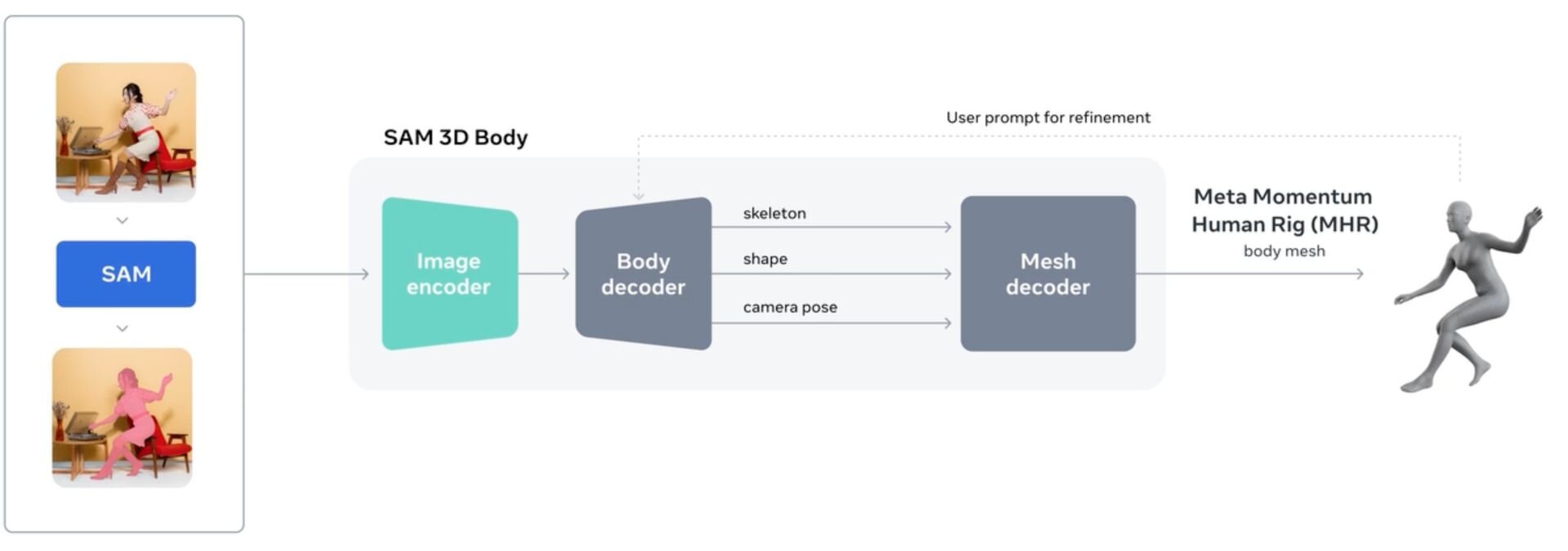
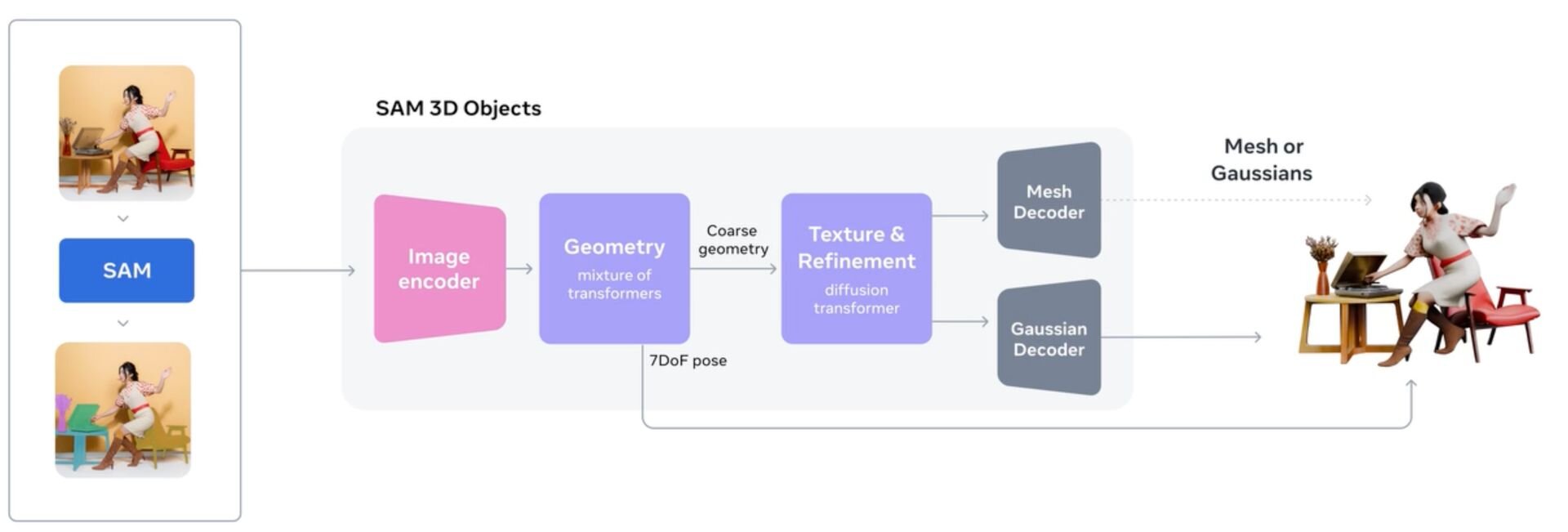
SAM 3Dは、画像内の人物を認識して体型・骨格・ポーズを正確に3Dメッシュ化する「SAM 3D Body」と、家具・雑貨・自然物などの一般物体を対象に3Dメッシュ化を行う「SAM 3D Objects」という2つの特化型モデルからなる。SAM 3Dの3Dモデル再構築は、SAM 3が備えるセグメンテーション能力を活用し、背景から対象を綺麗に分離した上で立体化する。テクスチャにはシャドウ情報もベイクされる。
SAM 3D Bodyのコア技術は、骨格構造と表面形状を分離して扱う新たなパラメトリック表現「Momentum Human Rig(MHR)」の導入。さらにSAMの強みであるプロンプト機能を統合し、2Dキーポイントやマスクによる入力補助を可能にした。これにより、従来のモデルでは難しかった複雑なポーズや群衆シーンでも、ユーザーが推論を対話的に修正・制御できる。
SAM 3D Objectsは、大規模な合成データによる事前学習と、実データを用いた微調整(Human-in-the-loop)を組み合わせたマルチステージ学習が特徴。これにより、高品質な3Dデータ不足を克服し、複雑な遮蔽や背景の乱れがある実画像に対しても、文脈から不可視部分を補完して立体化を可能にする。

SAM 3D enables accurate 3D reconstruction from a single image, supporting real-world applications in editing, robotics, and interactive scene generation.
— AI at Meta (@AIatMeta) November 20, 2025
Matt, a SAM 3D researcher, explains how the two-model design makes this possible for both people and complex environments.… pic.twitter.com/wt6wPSmdou
SAM 3D enables accurate 3D reconstruction from a single image, supporting real-world applications in editing, robotics, and interactive scene generation.
Matt, a SAM 3D researcher, explains how the two-model design makes this possible for both people and complex environments.SAM 3Dは、単一の画像から正確な3D再構築を可能にし、編集、ロボティクス、そしてインタラクティブなシーン生成といった実世界でのアプリケーションをサポートします。
SAM 3Dの研究者であるMatt氏が、この2つのモデルによる設計が、いかにして「人物」と「複雑な環境」の両方においてこの性能を実現しているかについて解説します。
■Introducing SAM 3D: Powerful 3D Reconstruction for Physical World Images(Meta Blog、英語)
https://ai.meta.com/blog/sam-3d/
■SAM 3D(SAM 3D Body: Robust Full-Body Human Mesh Recovery、SAM 3D Objects)(GitHub)
https://github.com/facebookresearch/sam-3d-body
■SAM-3D-Body Data(Hugging Face)
https://huggingface.co/datasets/facebook/sam-3d-body-dataset
■Meta AI Demos(ブラウザ上でSAM 3D、SAMのテストが可能)
https://aidemos.meta.com/
■SAM 3D: 3Dfy Anything in Images(論文、英語)
https://ai.meta.com/research/publications/sam-3d-3dfy-anything-in-images/
■SAM 3D Body: Robust Full-Body Human Mesh Recovery(論文、英語)
https://ai.meta.com/research/publications/sam-3d-body-robust-full-body-human-mesh-recovery/
Segment Anything Model 3について
Today we’re excited to unveil a new generation of Segment Anything Models:
— AI at Meta (@AIatMeta) November 19, 2025
SAM 3 enables detecting, segmenting and tracking of objects across images and videos, now with short text phrases and exemplar prompts.
Learn more about SAM 3: https://t.co/tIwymSSD89
SAM 3D… pic.twitter.com/kSQuEmwH33
Today we’re excited to unveil a new generation of Segment Anything Models:
1:SAM 3 enables detecting, segmenting and tracking of objects across images and videos, now with short text phrases and exemplar prompts.
2:SAM 3D brings the model collection into the 3rd dimension to enable precise reconstruction of 3D objects and people from a single 2D image.
These models offer innovative capabilities and unique tools for developers and researchers to create, experiment and uplevel media workflows.本日、私たちは新世代の「Segment Anything Models」を発表します。
1:SAM 3 画像および動画内における物体の検出、セグメンテーション、トラッキングを可能にします。今回新たに、短いテキストフレーズや、例示プロンプト(見本による指示)に対応しました。
2:SAM 3D 本モデルコレクションを「3次元」へと拡張し、単一の2D画像から3Dの物体や人物を精密に再構築することを可能にします。
これらのモデルは、開発者や研究者が制作や実験を行い、メディアワークフローを一段上のレベルへ引き上げるための、革新的な機能とユニークなツールを提供します。
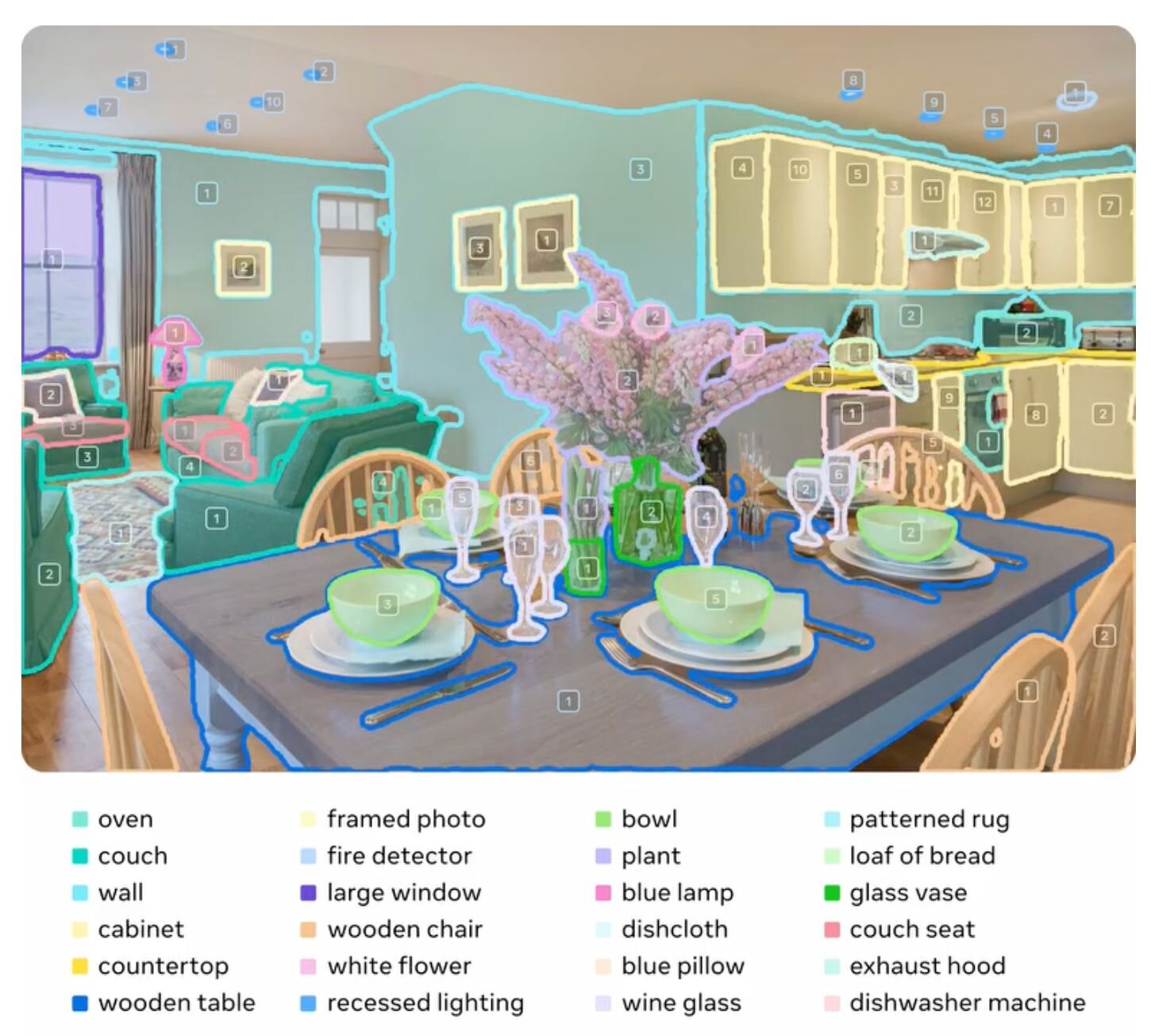
「Segment Anything Model 3」は、Metaの最新セグメンテーション基盤モデル。画像や動画内の物体を検出・追跡する従来機能に加え、新たに短文や画像例示によるプロンプトに対応する。これにより、自然言語を用いた柔軟な物体の指定が可能になった。上記「SAM 3D」のバックボーンとしても機能する。
■Introducing Meta Segment Anything Model 3 and Segment Anything Playground(Meta Blog、英語)
https://ai.meta.com/blog/segment-anything-model-3/
CGWORLD関連情報
●ByteDanceの3Dアセット生成基盤モデル「Seed3D 1.0」発表! 画像1枚から物理シミュレーションに対応可能な高品質アセットを生成

ByteDance Seedが3Dアセット生成基盤モデル「Seed3D 1.0」を発表。単一の画像から物理シミュレーションに対応可能な高品質3Dアセットを生成できる。Seed3D 1.0は同社運営の企業向けクラウドサービスプラットフォーム「Volcano Engine」で利用できる。
https://cgworld.jp/flashnews/01-202511-Seed3D.html
●3D生成AIモデル「Meshy 6 Preview」リリース! メッシュ品質向上、ワークフロー強化、Text-to-3DとImage-to-3Dを同社ワークスペースとAPIで提供開始

Meshyが3Dモデル生成AI「Meshy 6 Preview」を公開。キャラクターなどの有機的なモデルとハードサーフェスモデルの両方でメッシュ品質と精度向上を実現し、ワークスペースではワークフローを強化する新機能を提供する。同社運営のワークスペースとAPIで利用可能となった。ワークスペースでは1生成タスクにつき20クレジットを消費する。
https://cgworld.jp/flashnews/01-202510-Meshy6Preview.html
●3Dモデル生成AI「Hunyuan3D 3.0」リリース! 精度3倍、36億ボクセル、1日20回まで無料生成可能、AI搭載3D制作ツール「Hunyuan 3D Studio」クローズドテストもスタート

テンセントが3Dアセット生成AI「Hunyuan3D 3.0」をリリース。公式ワークスペースのTencent Hunyuan 3D AI Creation Engineで利用でき、1日20回まで無料で生成が行える。
https://cgworld.jp/flashnews/01-202509-Hunyuan3D-30.html
●3D生成AI「Tripo 3.0」ベータ版リリース! アルゴリズム刷新でジオメトリ&テクスチャ品質向上、自動リギング、パーツ分割、ブラシによるテクスチャ修正機能など

Vastが3Dモデル生成AI「Tripo 3.0」ベータ版をリリース。新アルゴリズム(3.0)の搭載によりジオメトリとテクスチャの処理方法が刷新されたほか、忠実度を高めた「ウルトラモード」、Flux/GPT-4oとの連携、スケッチからの生成、Tポーズモデルと自動リギング、より直感的な編集が可能になったMagic Brush 2.0、スマートなパーツ分割機能などを備える。Webアプリ「Tripo Studio」と「Tripo ライト版」、そしてAPIプラットフォームで利用可能。
https://cgworld.jp/flashnews/01-202509-Tripo3beta.html













