
Google DeepMind、オックスフォード大学、ロンドン大学ユニバーシティ・カレッジからなる研究チームは1月22日(木)、動画から「時間と空間」の4D構造を高速に復元するAIモデル「D4RT(Dynamic 4D Reconstruction and Tracking)」を発表した。従来の3Dシーン再構成手法と比較して最大300倍の処理速度を実現し、ロボットの視覚認識やARへの応用が期待される。ソースコードは執筆時点で未公開。
「D4RT」は、トランスフォーマーをベースとした統一的なエンコーダ・デコーダ・アーキテクチャを採用したAIモデル。
従来のNeRF(Neural Radiance Fields、ニューラル放射輝度場)や3DGS(3D Gaussian Splatting)などの手法は、新しい動画を処理するたびにテスト時最適化(Test-time optimization)と呼ばれる計算プロセスを必要とし、リアルタイム性が求められる用途では大きな課題となっていた。
それに対してD4RTは、学習済みのモデルが一度の推論で結果を出すフィードフォワードモデルとして設計されている。これにより、全域的な自己注意機構(Global self-attention mechanism)を用いて動画全体の文脈を一括で解析し、シーンのジオメトリ構造と動きを即座に把握することが可能になった。このアーキテクチャの転換により、計算資源の消費を抑えながら、1分間の動画をわずか5秒、従来の最高水準の手法と比較して18倍から最大300倍の処理速度で4D復元を完了させることに成功したという。
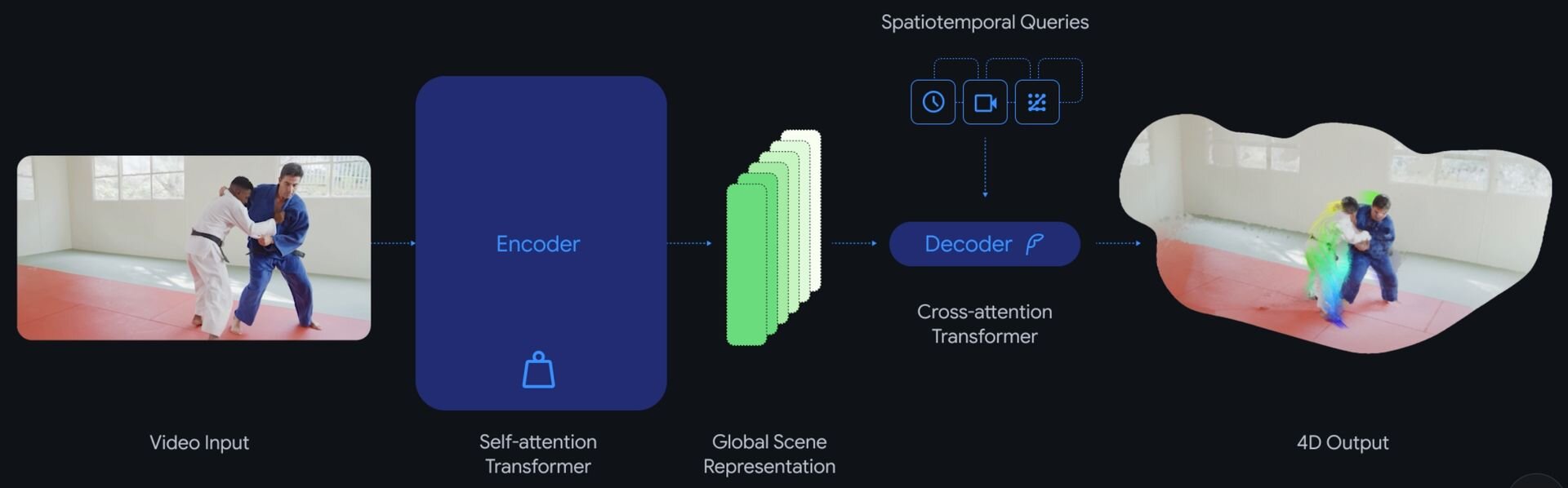

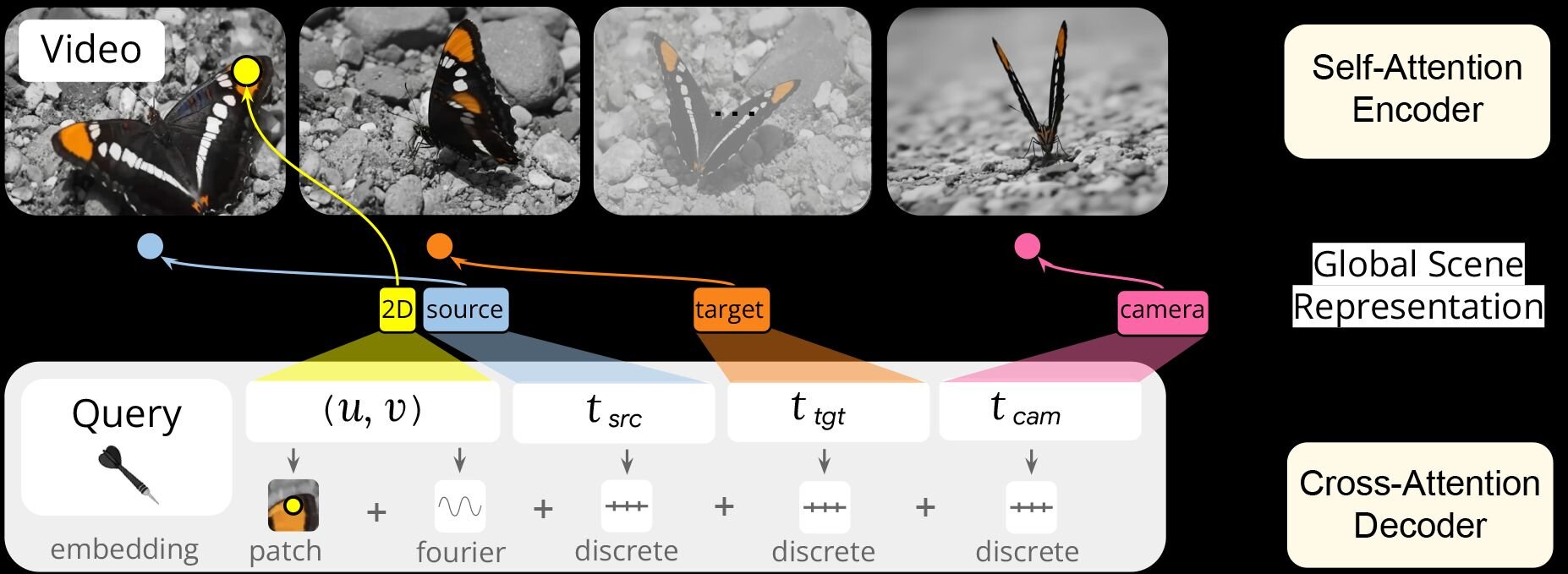
解析精度と柔軟性の両立にあたってD4RTでは、独自のクエリ(質問)メカニズムを導入。エンコーダが動画から生成した「潜在的なシーン表現(Latent scene representation)」に対し、デコーダが「特定の画素が、任意の時間に3D空間のどの座標に存在するか」という具体的なクエリを投げかける。
従来モデルでは、画面全体の情報を一度に強引に処理しようとしていたのに対して、D4RTは必要な箇所をピンポイントかつ並列的に問い合わせるため、計算の無駄が削減される。この仕組みにより、カメラの動きとオブジェクトの独立した動き、そして静止した背景のジオメトリ構造を同時かつ矛盾なく推定することが可能となったという。
また、時空間対応付け(Spatio-temporal correspondence)の能力向上により、オブジェクトのオクルージョン(遮蔽)や一時的な画面外への消失が生じた場合でも、AIはそれまでの動きの法則性から、そのオブジェクトの見えない位置を予測し、正確な軌跡を描き続けるポイントトラッキング性能を実現している。
4D reconstruction often fails on dynamic objects, resulting in ghosting artifacts or processing lag.
— Google DeepMind (@GoogleDeepMind) January 22, 2026
D4RT can continuously understand what's moving while running 18x–300x faster than previous methods - processing a 1-minute video in roughly 5 seconds on a single TPU chip. pic.twitter.com/sPEcd9b4oD
4D reconstruction often fails on dynamic objects, resulting in ghosting artifacts or processing lag.
D4RT can continuously understand what's moving while running 18x–300x faster than previous methods - processing a 1-minute video in roughly 5 seconds on a single TPU chip.従来の4D復元技術では、激しく動く動的な物体を正確に捉えきれず、像が二重に重なって見えるゴースト現象や、処理の遅延といった課題が頻繁に発生していました。
これに対しD4RTは、動いている対象を継続的に正しく理解しながら、従来手法と比較して18倍から300倍という驚異的な高速化を実現しています。実際に、AIの演算処理に特化した専用プロセッサである単一のTPUチップを用いた検証では、1分間の動画をわずか約5秒で処理することに成功しました。
■D4RT(プロジェクトページ)
https://d4rt-paper.github.io/
■D4RT: Teaching AI to see the world in four dimensions(公式ブログ)
https://deepmind.google/blog/d4rt-teaching-ai-to-see-the-world-in-four-dimensions/
CGWORLD関連情報
●Metaら、3Dシーン生成AIモデル「ShapeR」リリース! ラフな日常撮影の動画シーケンスからロバストな3Dシーンを再構築

Meta Reality Labs Researchとサイモンフレーザー大学からなる研究チームが、ラフな撮影映像から高品質な3Dオブジェクトを生成する基盤モデル「ShapeR」を発表。ARグラスなどで撮影された、障害物や背景の写り込みが多い「日常的なキャプチャ(Casual Captures)」から、特定のオブジェクトを正確に3Dモデル化できるAI技術。ソースコードはGitHubで、学習済みモデルはHugging Faceで公開され、ライセンスは研究・非商用目的での利用に限定されたCC BY-NC 4.0が主に適用されている。
https://cgworld.jp/flashnews/01-202602-ShapeR.html
●3D生成AIモデル「Tencent HY 3D 3.1」リリース! HY 3D Studio 1.2とHY 3D Global上で利用可能

テンセントのHunyuanチームが3Dアセット生成モデル「Tencent HY 3D 3.1」をリリース。アップデートされた同社3Dアセット生成プラットフォーム「Tencent HY 3D Studio 1.2」および、グローバル向けワークスペース「Tencent HY 3D Global」とAPI経由で利用できる。HY 3D Globalでは期間限定で1日20回まで無料で生成を試すことができるほか、高度な機能を利用できる有料サブスクリプションも提供される。
https://cgworld.jp/flashnews/01-202602-TencentHY3D.html
●3D生成AIモデル「Meshy-6」リリース! ジオメトリ構造改善、ハードサーフェスのシャープなエッジ表現、ローポリモード、マルチカラー3Dプリント、自由なポーズのモデル生成など

Meshyが3D生成AIモデル「Meshy-6」を公式にリリース。本アップデートでは、生成モデルのジオメトリ構造が改善され、より直感的な編集や出力が可能となった。また、キャラクターなどの有機的な形状におけるアナトミー的正確性が向上したほか、メカニカルオブジェクトのハードサーフェスのエッジをよりシャープに表現できるようになった。また、21日にはImage-to-3Dの機能が拡張され、自由なポーズのモデル生成に対応している。公式ワークスペースおよびAPIを通じて提供される。
https://cgworld.jp/flashnews/01-202601-Meshy-6.html













