
こんにちは。この連載では、AI生成技術と進化、3DCG制作現場への活用の可能性を探索していきます。今回取り上げるのは、いくつかあるモーション生成系モデルのうちのひとつ「T2M-GPT」です。
AI関連の研究は日々驚くほどのスピードで進化しています。可能な限り正確な情報を提供するよう心掛けていますが、私自身も学習中であるため、記事中に誤りが含まれる可能性があることをご理解いただければ幸いです。

赤崎弘幸
Jet Studio Inc.所属のCGディレクター。
1. T2M-GPTとは
T2M-GPTは、テキストから人間の動きを生成するフレームワークで、VQ-VAEとGPTを組み合わせたアプローチだそうです。仕組みを解説する能力は私にはありませんが、つまりテキストからモーションを生成できるものだと思って差し支えないかと思います。同じモーション生成系の比較対象として拡散モデルベースのMDMやMotionDiffuseが挙げられています。
今回はこのモデルをWindowsローカル環境で実行し、生成されたモーションをMaya内のリグにあてはめるところまでやってみます。
2. セットアップ
GitHubに導入手順が書かれていますが、Windowsではそのまま実施できませんので手動で環境構築していきます。今回は参考になる解説記事などがあまりないため準備段階から記載していきます。OSやGPUの種類によっては一部異なる場合がありますので、あくまで一例として捉えていただけますと幸いです。AnacondaとCUDAは導入済みの前提で始めます。
<テスト環境>
・Windows 10
・NVIDIA GeForce RTX 3060 12GB
・Anaconda3
・CUDA Toolkit 11.3
まずはリポジトリをクローンします。
git clone https://github.com/Mael-zys/T2M-GPT.git
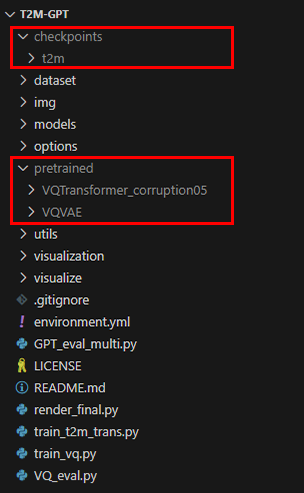
次に必要なモデルをダウンロードし、リポジトリ直下に次の画像のように配置します。
・VQTrans_pretrained(HuggingFaceにも同じものがあります)
・t2m
仮想環境を作成し、必要なパッケージのみ手動でインストールしていきます。GeForce RTX 3060に対応させるためPyTorchのみv1.12.1 CUDA 11.3に上げていますが、それ以外は environment.yml に記載のバージョンを踏襲しています。
conda create -n t2m-gpt python=3.8.11
conda activate t2m-gpt
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
pip install scipy==1.7.1
pip install matplotlib==3.4.3
pip install imageio==2.9.0
pip install git+https://github.com/openai/CLIP.git
3. モーション生成
環境が整ったら、Colabのデモを参考にテキストからモーションを生成するスクリプトを書いて実行してみます。clip_text = [“a person ○○○”] の部分をいろいろ変更して試してみてください。生成されたモーションはmotion.npyファイルに保存され、確認用としてexample.gifも合わせて保存されます。
import clip
import torch
import numpy as np
import warnings
import models.vqvae as vqvae
import models.t2m_trans as trans
import options.option_transformer as option_trans
from utils.motion_process import recover_from_ric
import visualization.plot_3d_global as plot_3d
clip_text = ["a person is jumping"]
args = option_trans.get_args_parser()
args.dataname = 't2m'
args.resume_pth = 'pretrained/VQVAE/net_last.pth'
args.resume_trans = 'pretrained/VQTransformer_corruption05/net_best_fid.pth'
args.down_t = 2
args.depth = 3
args.block_size = 51
warnings.filterwarnings('ignore')
print ('loading clip model \"ViT-B/32\"')
clip_model, clip_preprocess = clip.load("ViT-B/32", device=torch.device('cuda'), jit=True, download_root='./')
clip_model.eval()
for p in clip_model.parameters():
p.requires_grad = False
net = vqvae.HumanVQVAE(args,
args.nb_code,
args.code_dim,
args.output_emb_width,
args.down_t,
args.stride_t,
args.width,
args.depth,
args.dilation_growth_rate)
trans_encoder = trans.Text2Motion_Transformer(num_vq=args.nb_code,
embed_dim=1024,
clip_dim=args.clip_dim,
block_size=args.block_size,
num_layers=9,
n_head=16,
drop_out_rate=args.drop_out_rate,
fc_rate=args.ff_rate)
print ('loading checkpoint from {}'.format(args.resume_pth))
ckpt = torch.load(args.resume_pth, map_location='cpu')
net.load_state_dict(ckpt['net'], strict=True)
net.eval()
net.cuda()
print ('loading transformer checkpoint from {}'.format(args.resume_trans))
ckpt = torch.load(args.resume_trans, map_location='cpu')
trans_encoder.load_state_dict(ckpt['trans'], strict=True)
trans_encoder.eval()
trans_encoder.cuda()
mean = torch.from_numpy(np.load('./checkpoints/t2m/VQVAEV3_CB1024_CMT_H1024_NRES3/meta/mean.npy')).cuda()
std = torch.from_numpy(np.load('./checkpoints/t2m/VQVAEV3_CB1024_CMT_H1024_NRES3/meta/std.npy')).cuda()
text = clip.tokenize(clip_text, truncate=True).cuda()
feat_clip_text = clip_model.encode_text(text).float()
index_motion = trans_encoder.sample(feat_clip_text[0:1], False)
pred_pose = net.forward_decoder(index_motion)
pred_xyz = recover_from_ric((pred_pose*std+mean).float(), 22)
xyz = pred_xyz.reshape(1, -1, 22, 3)
xyz_np = xyz.detach().cpu().numpy()
np.save('motion.npy', xyz_np)
pose_vis = plot_3d.draw_to_batch(xyz_np, clip_text, ['example.gif'])
4. Mayaへ読み込み
出力されたnpyファイルにはサイズが(1, フレーム数, 22, 3)のnumpy.ndarrayが保存されており、これは22個ある関節の位置x,y,zがフレーム数ぶん記録されているということになります。このデータをMayaへlocatorの位置アニメーションとして読み込んでみます。
npyファイルのロードにnumpyを使用しますので、こちらを参考に事前にMayaへnumpyをインストールしておきます。今回はMaya 2024 を使用します。
cd C:\Program Files\Autodesk\Maya2024\bin
mayapy -m pip install numpy --target C:/Users/<username>/Documents/maya/2024/scripts/site-packages
Mayaを起動し以下のスクリプトを実行すると、locatorと視覚化用のcurveが作成され、locatorのtranslateにキーフレームが打たれます。すでにlocator等が存在した場合はキーフレームの置き換えのみを行います。速度調整の関係でキーフレームは20fpsで作成されます。npyのパスは適宜変更してください。
from typing import List
import numpy as np
from maya import cmds
from maya.api import OpenMaya, OpenMayaAnim
# ジョイントのラベルリスト
JOINT_LABELS = [
"Hip",
"LeftLeg",
"RightLeg",
"Spine1",
"LeftKnee",
"RightKnee",
"Spine2",
"LeftFoot",
"RightFoot",
"Spine3",
"LeftToe",
"RightToe",
"Neck",
"LeftShoulder",
"RightShoulder",
"Head",
"LeftArm",
"RightArm",
"LeftElbow",
"RightElbow",
"LeftHand",
"RightHand",
]
# キネマティックチェーンの名前、インデックス、カラーを定義
KINE_CHAIN = [
("Spine", [0, 3, 6, 9, 12, 15], 1),
("LeftLeg", [0, 1, 4, 7, 10], 6),
("RightLeg", [0, 2, 5, 8, 11], 13),
("LeftArm", [9, 13, 16, 18, 20], 6),
("RightArm", [9, 14, 17, 19, 21], 13)
]
def get_locators():
"""
ジョイントラベルに基づいてlocatorとcurveを取得または作成します。
Returns:
tuple: locatorのリストとcurveのリスト
"""
locators = []
chains = []
grp = "loc_grp"
if not cmds.objExists(grp):
grp = cmds.createNode("transform", n=grp)
# 各ジョイントラベルに対してlocatorを作成または取得
for lbl in JOINT_LABELS:
loc = 'loc_{}'.format(lbl)
# オブジェクトが存在しない場合、新しく作成
if not cmds.objExists(loc):
loc = cmds.spaceLocator(n=loc)[0]
cmds.parent(loc, grp, r=False)
locators.append(loc)
# キネマティックチェーンに基づいてcurveを作成または取得
for name, indices, color in KINE_CHAIN:
crv = 'chain_{}'.format(name)
if not cmds.objExists(crv):
p = []
k = []
for i in range(len(indices)):
p.append((0,0,0))
k.append(i)
crv = cmds.curve(d=1, p=p, k=k, n=crv)
cmds.parent(crv, grp, r=False)
crv_shape = cmds.listRelatives(crv, s=True, f=True)[0]
cmds.setAttr(crv_shape + '.overrideEnabled', True)
cmds.setAttr(crv_shape + '.overrideColor', color)
for j, idx in enumerate(indices):
loc_shape = cmds.listRelatives(locators[idx], s=True, f=True)[0]
cmds.connectAttr('{}.worldPosition[0]'.format(loc_shape), '{}.controlPoints[{}]'.format(crv_shape,j), f=True)
chains.append(crv)
cmds.select(cl=True)
return locators, chains
def get_trans_animCurve(node :str):
"""
指定されたノードのtx,ty,tzのanimCurveを取得または作成します。
Args:
node (str): ノード名
Returns:
list: animCurveのリスト
"""
anim_curves = []
# animCurveを取得または作成
for attr in ['translateX', 'translateY', 'translateZ']:
attr_name = '{}.{}'.format(node, attr)
anim_curve = cmds.ls(cmds.listConnections(attr_name, s=True, d=False), type="animCurveTL")
if anim_curve:
anim_curves.extend(anim_curve)
if not anim_curve:
anim_curve = cmds.createNode('animCurveTL')
cmds.connectAttr('{}.output'.format(anim_curve), attr_name, f=True)
anim_curves.append(anim_curve)
cmds.select(cl=True)
return anim_curves
def plot(data :List[List[List[float]]], scale :float=1.0):
"""
与えられたデータを使用してアニメーションをプロットします。
Args:
data (List[List[List[float]]]): アニメーションデータ
scale (float, optional): スケール値。デフォルトは1.0。
Returns:
list: プロットされたlocatorのリスト
"""
locators, _ = get_locators()
frames = len(data)
print("frames: {} / points: {} / params: {}".format(frames, len(data[0]), len(data[0][0])))
# アニメーション設定
cmds.currentUnit(t="ntsc")
cmds.playbackOptions(min=1, max=int(frames*1.5), ast=1, aet=int(frames*1.5))
cmds.currentTime(1)
# animCurveにキーフレームを追加
for i, loc in enumerate(locators):
# animCurve名を取得
mslist = OpenMaya.MSelectionList()
for anim_curve in get_trans_animCurve(loc):
mslist.add(anim_curve)
mfn_curves :List[OpenMayaAnim.MFnAnimCurve] = []
# MFnAnimCurveを取得
for j in range(3):
mfn_curve = OpenMayaAnim.MFnAnimCurve(mslist.getDependNode(j))
# 既存のキーフレームを削除
for k in range(mfn_curve.numKeys):
mfn_curve.remove(0)
mfn_curves.append(mfn_curve)
# frame数ぶんキーフレームを追加
for frame in range(frames):
k_time = OpenMaya.MTime(frame+1, OpenMaya.MTime.k20FPS)
for m, k_value in enumerate(data[frame][i]):
mfn_curves[m].addKey(k_time, k_value * scale)
return locators
if __name__ == "__main__":
data = np.load("motion.npy")
plot(data.tolist()[0], scale=100)
以下のGIFはスクリプト実行後のMayaビューポートです。
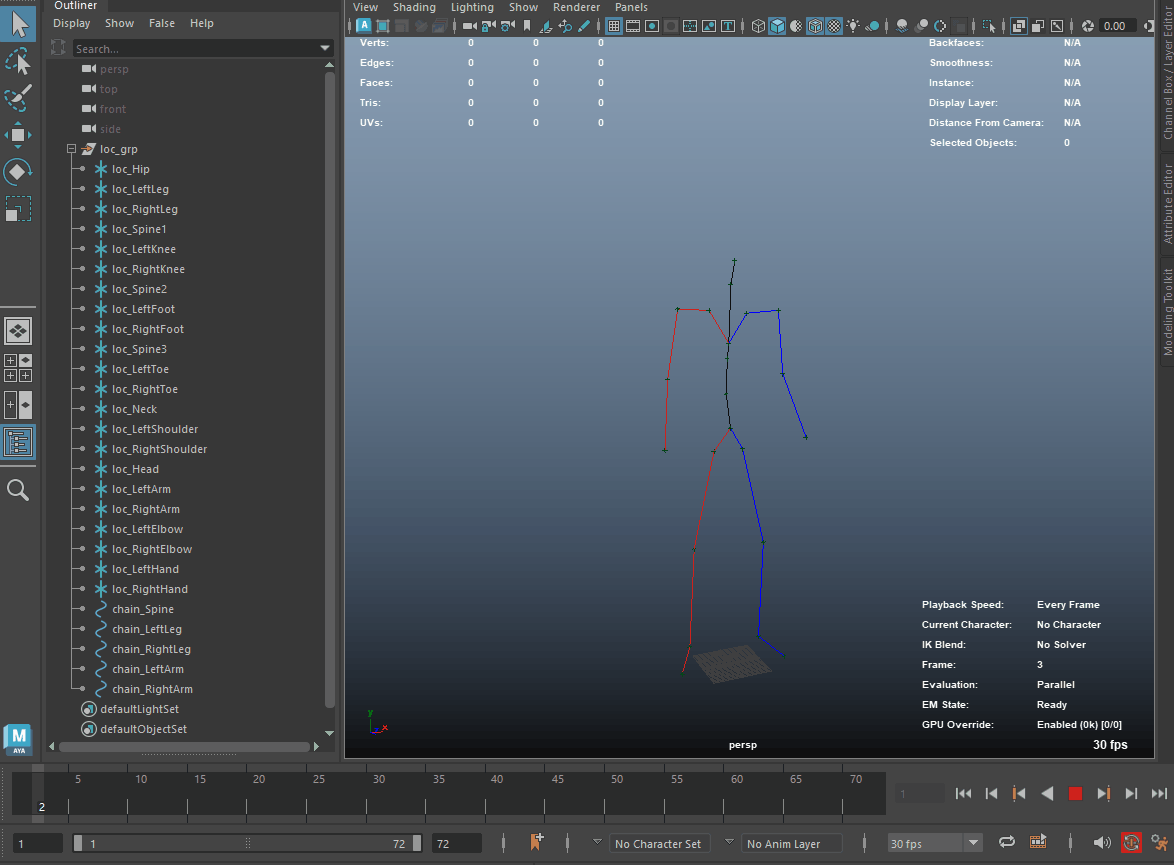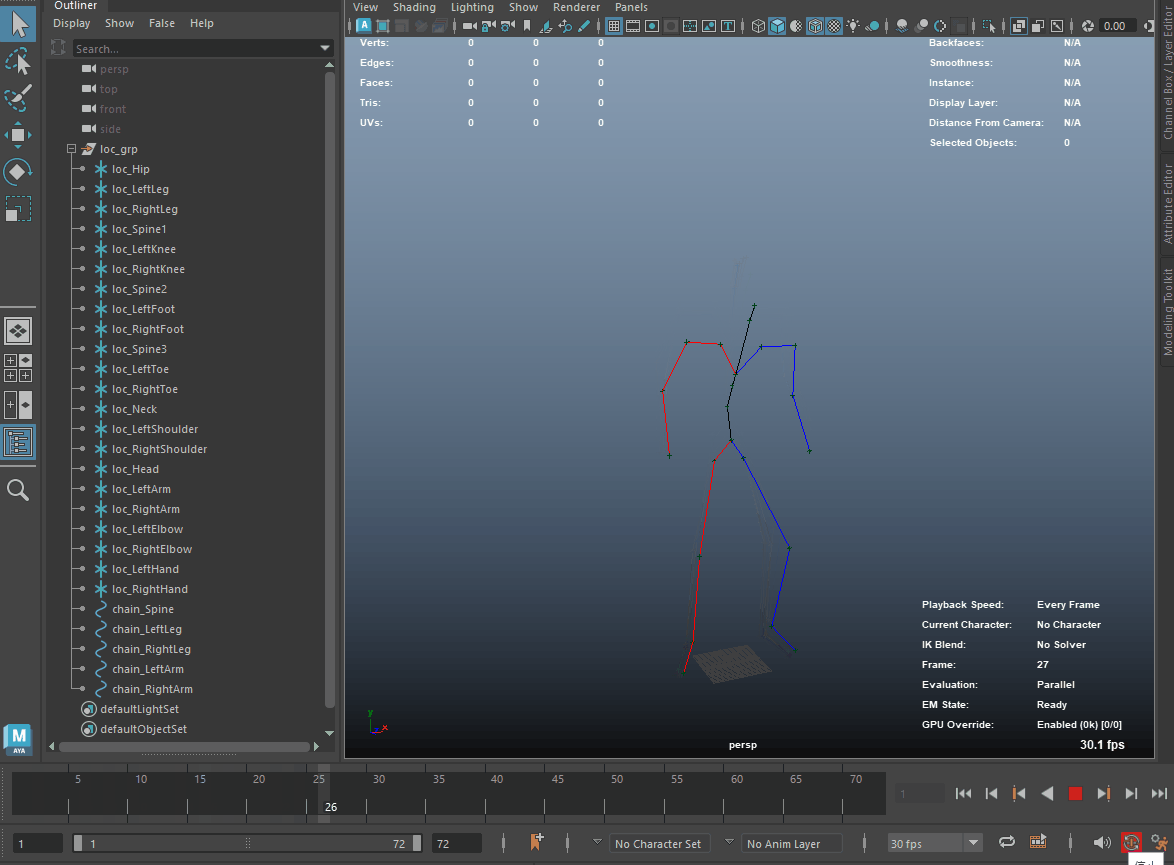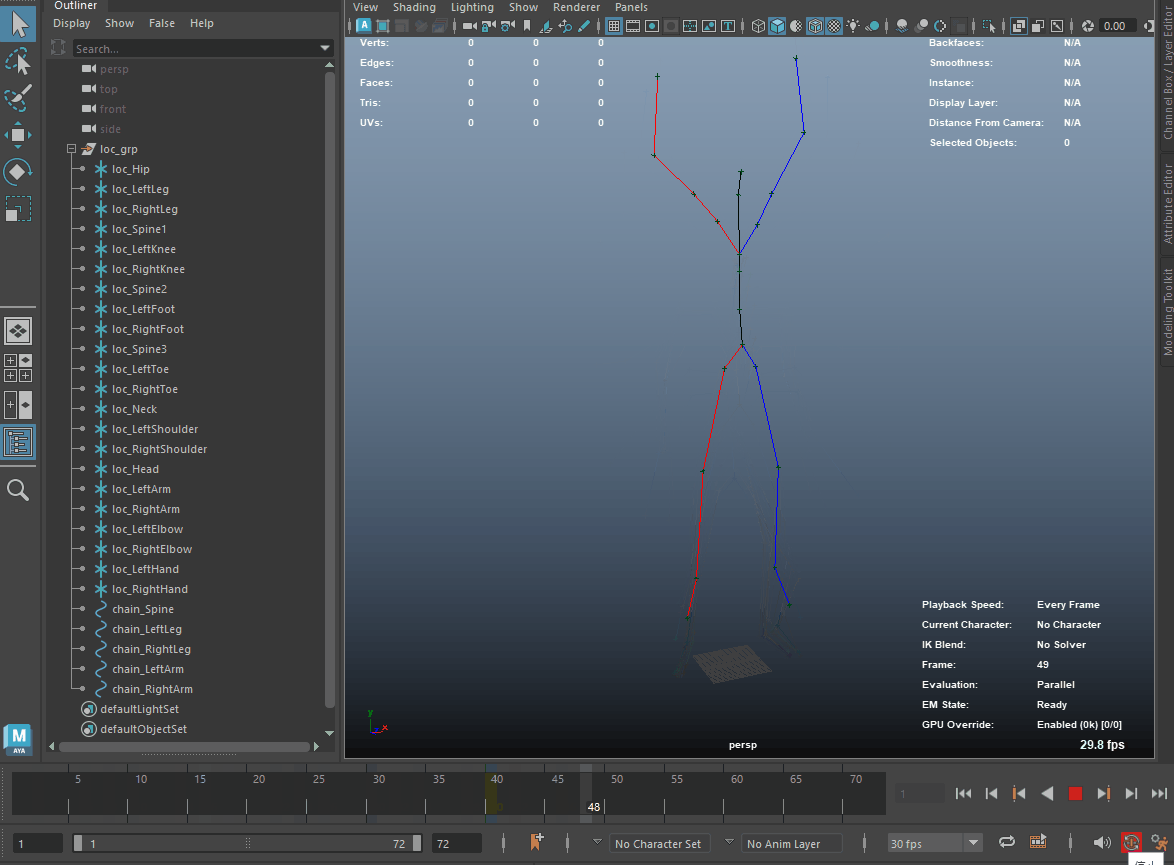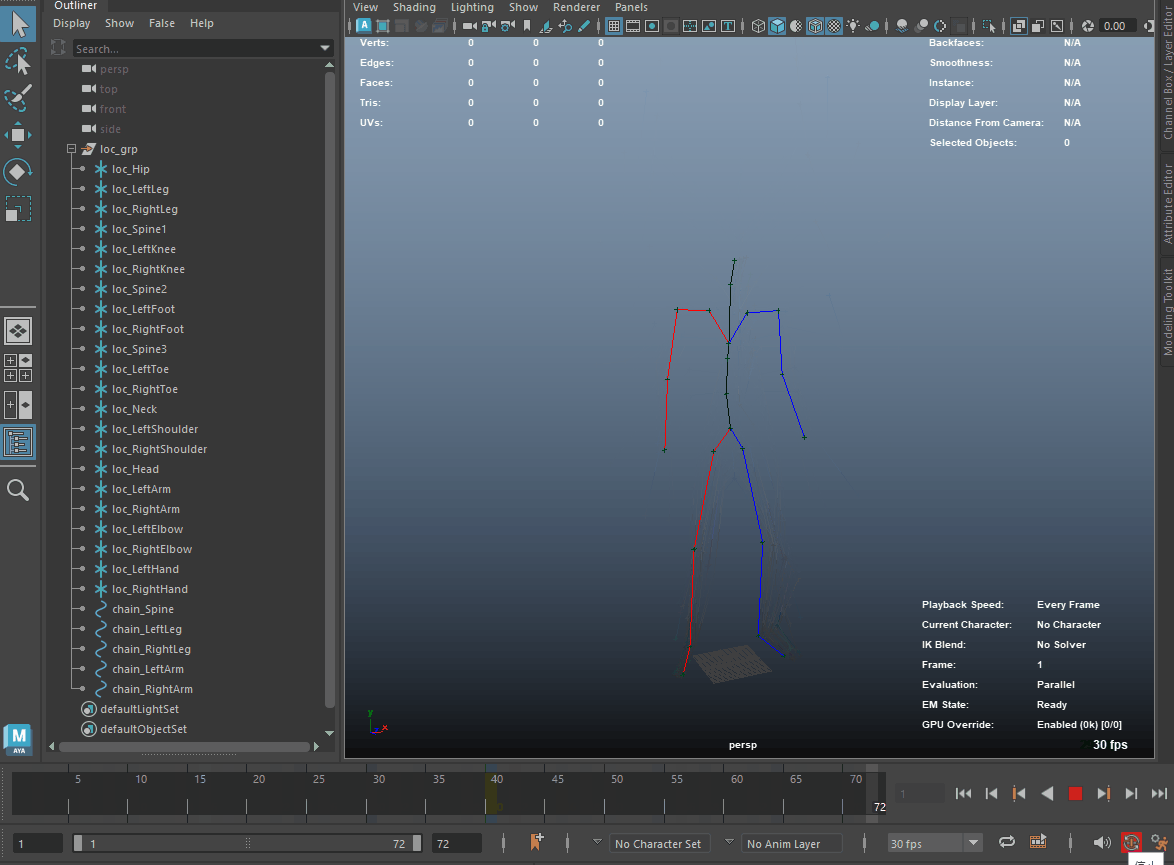
5. リターゲット
前項で読み込んだアニメーションをキャラクターリグにリターゲットしてみます。リターゲットと言っても、ここでは各IKコントローラをlocatorでコンストレイントする程度の少々強引なやり方です。体格が大きく異なると多少無理が生じますが、今回は目をつむります。
前項のlocatorは各関節の位置情報だけしかありませんので、腰や胸など一部パーツにおいてはaimConstraintで事前に向きを取得出来るようにしておきます。3点あればaimVectorとupVectorでしっかり固定できるかと思います。
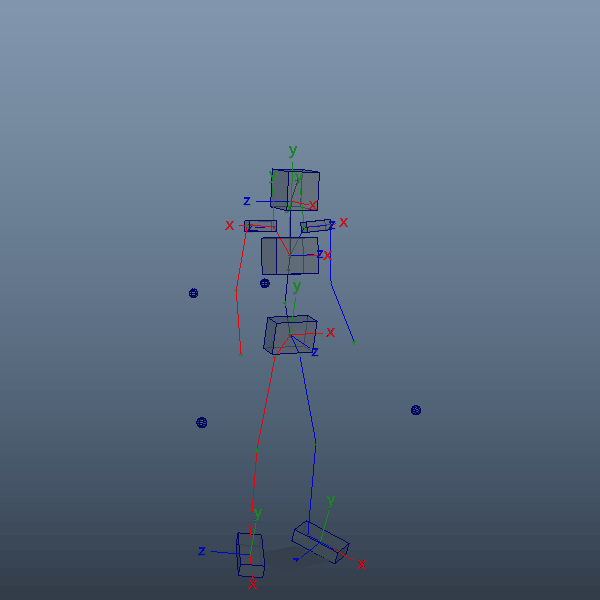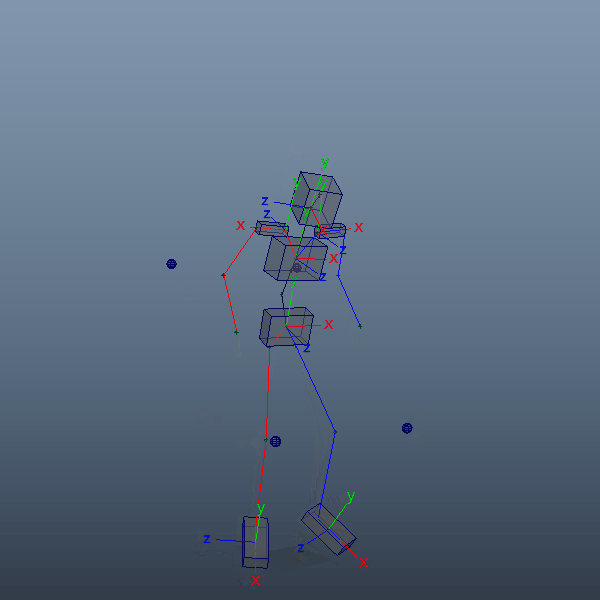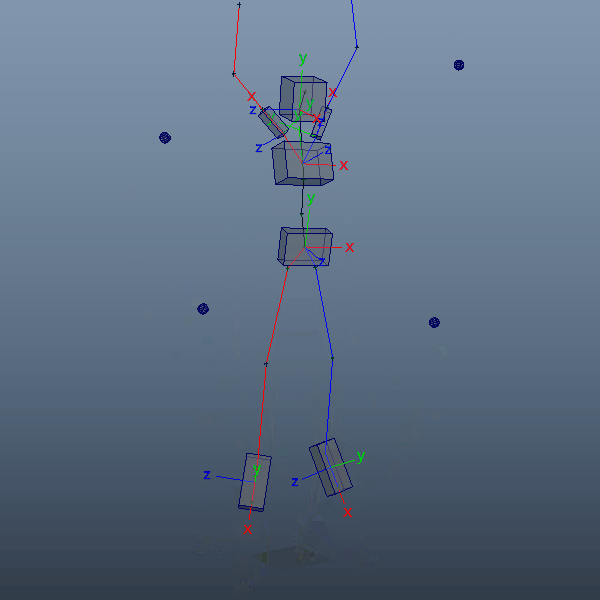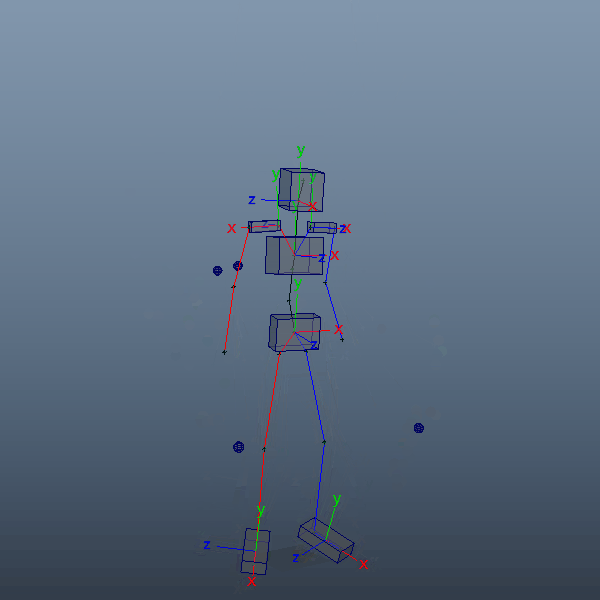
自身のキャラクターリグをインポートし、腰、胸、首、手足のIK、腕脚のupVectorなど各コントローラをコンストレイントしていきます。ここでは、リグはmGearで作成したものを使用しています。手足だけでなく腰、胸、首など全体にIKが用意されているためこちらを選択しました。
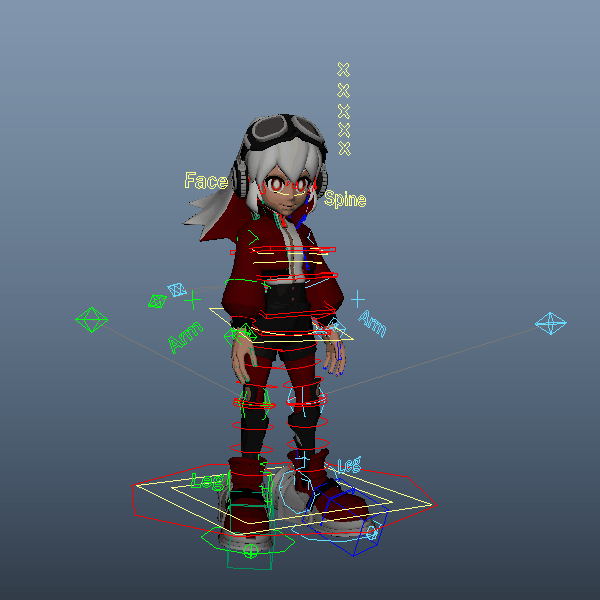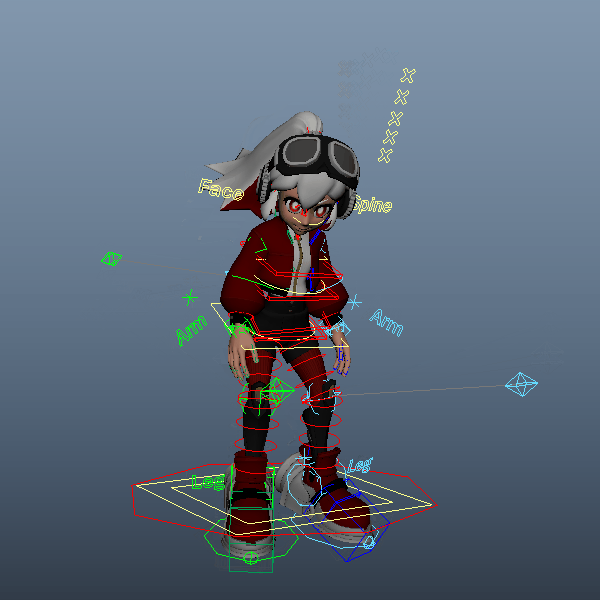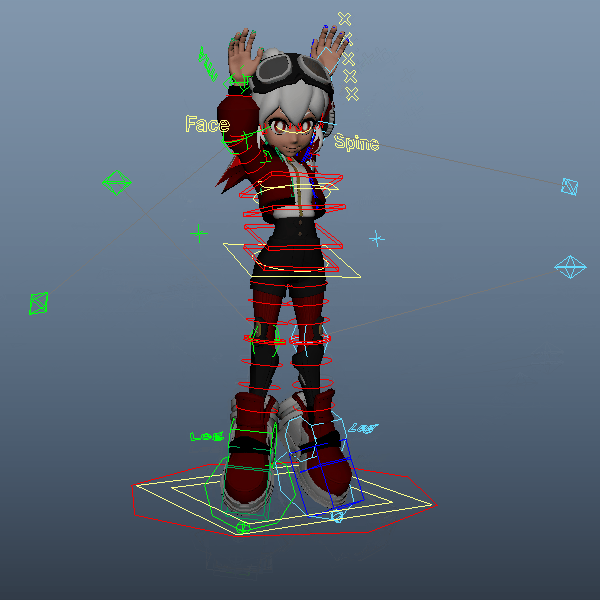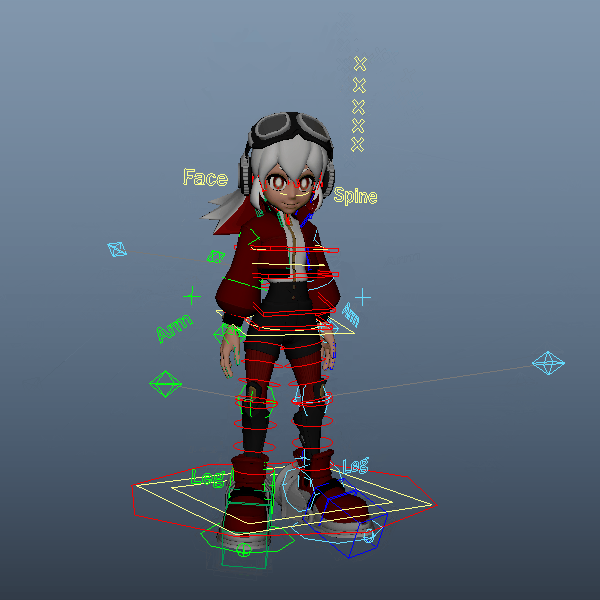
一度拘束してしまえば、前項のスクリプトで別のモーションを読み込んでもそのまま差し変わるかと思います。試しに「a person is skipping rope.」で生成したmotion.npyを読み込み直してみました。ちなみに、髪の毛が勝手に揺れているのはリグの影響ですので今回のモーション生成とは関係ありません。

6. モーション生成サーバを立ててみる
せっかくここまで来たので、Mayaから直接テキストを打ち込みそのままキャラクターへ反映させてみたくなってきました。「3. モーション生成」で作成したスクリプトをFastAPIでサーバ化し、Mayaからリクエストできるようにしてみます。サーバはテキストを受け取りモーションを生成したら、npyやgifの保存は行わずにモーションデータ(floatのリスト)のみを即座に返すように設計してみます。仮想環境に追加でfastapiとuvicornをインストールし、次のようにスクリプトを改変します。
pip install fastapi uvicornimport clip
import torch
import numpy as np
import warnings
from fastapi import FastAPI
from pydantic import BaseModel
import uvicorn
import models.vqvae as vqvae
import models.t2m_trans as trans
import options.option_transformer as option_trans
from utils.motion_process import recover_from_ric
args = option_trans.get_args_parser()
##(中略)##
## args = の行から std = の行まで [3. モーション生成] のスクリプトと同じ ##
std = torch.from_numpy(np.load('./checkpoints/t2m/VQVAEV3_CB1024_CMT_H1024_NRES3/meta/std.npy')).cuda()
# リクエストデータを定義
class RequestData(BaseModel):
text: str
# FastAPIのアプリインスタンスを作成
app = FastAPI()
# /t2mgpt/エンドポイントにPOSTリクエストを実行した場合の処理を定義
@app.post("/t2mgpt/")
async def t2mgpt(request_data: RequestData):
# リクエストデータを取得
data = request_data.model_dump()
# テキストからモーションを生成
text = clip.tokenize([data["text"]], truncate=True).cuda()
feat_clip_text = clip_model.encode_text(text).float()
index_motion = trans_encoder.sample(feat_clip_text[0:1], False)
pred_pose = net.forward_decoder(index_motion)
pred_xyz = recover_from_ric((pred_pose*std+mean).float(), 22)
xyz = pred_xyz.reshape(1, -1, 22, 3)
# listにして返す
return xyz.detach().cpu().tolist()
# FastAPIのアプリを起動
uvicorn.run(app, host="127.0.0.1", port=8000)上記スクリプトを「t2mgpt_server.py」と言う名前(他の名前でも大丈夫です)で保存し実行します。
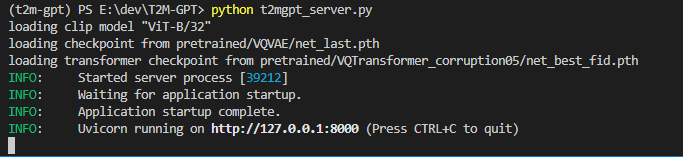
python t2mgpt_server.py最初に一度だけ各種モデルがロードされるので数秒はかかると思います。次の画像のような表示になれば起動成功です。
Mayaからサーバへリクエストを送信するため「4. Mayaへ読み込み」のスクリプトを改変します。先ほどはnpyファイルからモーションデータをロードしていましたが、今回はテキストをサーバへ送信しモーションデータを直接受け取ります。ついでに簡単なUIも用意してしまいましょう。受け取ったデータは同じくlocatorのキーフレームとして適用します。
mayapy -m pip install requests --target C:/Users/<username>/Documents/maya/2024/scripts/site-packagesfrom typing import List
import time
import requests
import json
from maya import cmds, OpenMayaUI
from maya.api import OpenMaya, OpenMayaAnim
from PySide2 import QtWidgets
from shiboken2 import wrapInstance
JOINT_LABELS = [
## [4. Mayaへ読み込み] のスクリプトと同じ ##
KINE_CHAIN = [
## [4. Mayaへ読み込み] のスクリプトと同じ ##
def get_locators():
## [4. Mayaへ読み込み] のスクリプトと同じ ##
def get_trans_animCurve(node :str):
## [4. Mayaへ読み込み] のスクリプトと同じ ##
def plot(data :List[List[List[float]]], scale :float=1.0):
## [4. Mayaへ読み込み] のスクリプトと同じ ##
def maya_main_window():
ptr = OpenMayaUI.MQtUtil.mainWindow()
return wrapInstance(int(ptr), QtWidgets.QWidget)
# UIクラス
class UI(QtWidgets.QDialog):
def __init__(self, parent=None, *args):
super(UI, self).__init__(parent, *args)
self.setWindowTitle('T2M-GPT Request')
# テキスト入力フィールド
label = QtWidgets.QLabel("text:")
self.text_field = QtWidgets.QLineEdit()
self.text_field.setStyleSheet("QLineEdit {font-size: 15px;}")
self.text_field.setText("a person is jumping")
# 生成ボタン
button = QtWidgets.QPushButton("Generate")
button.clicked.connect(self.generate)
# 情報表示用
self.info = QtWidgets.QLabel("")
# UIレイアウト
hlayout = QtWidgets.QHBoxLayout()
hlayout.addWidget(label)
hlayout.addWidget(self.text_field)
vlayout = QtWidgets.QVBoxLayout()
vlayout.addLayout(hlayout)
vlayout.addWidget(self.info)
vlayout.addWidget(button)
self.setLayout(vlayout)
# ボタンクリック時に実行する関数
def generate(self, *args):
# 現在の時間取得(計測用)
st = time.time()
# テキストフィールドから入力テキストを読み取って整形
data = {"text": self.text_field.text()}
# サーバーにリクエストを送信
response = requests.post(
"http://127.0.0.1:8000/t2mgpt/",
data=json.dumps(data),
headers={'Content-type': 'application/json'})
# サーバ返答までにかかった時間
generate_time = time.time() - st
# 現在の時間取得(計測用)
st = time.time()
# サーバから帰ってきたモーションデータを使用してMayaシーン内にプロット
plot(response.json()[0], scale=100)
# プロットにかかった時間
plot_time = time.time() - st
# UIに時間を表示
self.info.setText("Generate : {:.03f} sec / Plot : {:.03f} sec".format(generate_time, plot_time))
if __name__ == "__main__":
widget = UI(parent=maya_main_window())
widget.show()1〜3秒程度でモーションが生成され、すぐにキャラクターに反映させることができました。なかなかの速度ですね!
余談ですが、MDMでも同じく(1, フレーム数, 22, 3)のnumpy.ndarrayが得られますのでMayaへ読み込むスクリプトは同じものを使いまわせます。以下の動画はMDMのText to Motionを同様にAPIサーバにしてみたものです。
7. 最後に
今回の実験では、モーションを生成するだけでなく実際の利用をイメージしてDCCツールと連携するところまでやってみました。生成モーションのバリエーションはある程度限界がありそうでしたが(扱いに慣れていなかっただけかもしれませんが)、生成スピードと軽量さは特に魅力的に感じました。欲を言えば、もう少し何らかのキャラクター性を反映させたモーションが出したかったりもしますし、テキストによって無限にバリエーションが作れるような汎用性が欲しかったりもします。このあたりは学習データの内容や量で変わってくるような気がします。
また、同じ生成系モデルではモーションを言語のように扱うMotionGPT、他にも検索にフォーカスしたTMR、MotionMatchingを応用し事前学習不要のGenMM、など人物モーションに限ってもいろいろなアプローチが出てきています。近々モーションライブラリやリアルタイムキャラクターコンテンツの形に影響が出てくるかもしれません。
最後までお読みいただき、ありがとうございます。今回は3Dキャラクターモーションの生成について紹介させていただきました。次回以降もさまざまなAI技術と3DCGの応用について探求していきますので、お楽しみに!













