前回、顔を検出してお面をかぶせるところまでつくってみました。今回はさらにそれを発展させ、複数人の顔を検出できるようにします。
TEXT_高田稔則 / Toshinori Takata(Codelight)
EDIT_小村仁美 / Hitomi Komura(CGWORLD)
<1>お面の位置暴れを解消する
こんにちは、Codelight株式会社の高田です。先日、東京ミッドタウンの21_21 DESIGN SIGHTで開催された「AUDIO ARCHITECTURE:音のアーキテクチャ展」に行ってきました。

小山田圭吾(Cornelius)の楽曲『AUDIO ARCHITECTURE』をベースに複数の作家が制作した映像作品が会場を大きく使ったステージに投影される、とても見ごたえのあるイベントでした。展示の中で特に気になったのは、「JIDO-RHYTHM」というiPhone X向けアプリ。これは音楽を聴きながらiPhoneで自撮りをすると、音に連動して自分の顔にエフェクトがかかるという非常に面白いもので、エフェクトの表現がユニークでしたので、次回以降このアプリをヒントにしたコンテンツをつくってみたいと思います。
さて、前回はOpenCVで顔検出を行い、お面をかぶせました。OpenCV for Unityのアセットをおもちの方は試すことができたでしょうか? このくらいならばそれほど難しくなかったのではと思います。
ただ、2人以上で試してみた方は気づいたと思いますが、今のままでは複数人にお面をかぶせることができません。またお面の位置が暴れてしまうことが多かったのではないでしょうか。
原因を考えてみましょう。OpenCVの顔検出アルゴリズム自体は複数個の顔の検出に対応しています。表示できないのはコンテンツがあえてお面の表示を1回で打ち切っているからで、お面を複数表示させるように変更する必要があります。これは主にUnityスクリプトを使っての作業になります(後述)。
一方、お面の位置が暴れてしまう問題はどうでしょうか。これはいくつかの原因が考えられます。顔検出は主に画像の明暗差(コントラスト)を使って検出を行なっているため、検出用の画像のコントラストが低いと認識しにくくなってきます。ほかに画面に対して顔が映っている範囲が大きすぎる、小さすぎる、動きが早くてぶれてしまう、カメラのフォーカス外れ、画像にノイズが多いなど様々です。一番良いアプローチは、アルゴリズムが検出しやすい画像を取得することができるように環境を整えることです。
下記のポイントに気を付けると暴れが激減します。
●カメラの設定
・高性能のカメラを使う
・シャッタースピードをできるだけ速くする
・パンフォーカスにする
・顔がしっかり映るアングルにカメラを設置する
●照明の設定
・十分な光量を確保する
・ライトを逆光にしない
・影をつくらない
●ノイズの除去
それではひとつずつ解説していきます。
●カメラの設定
一般的に、こういったコンテンツで利用するカメラは、Webカメラと呼ばれるUSBでPCに接続するものです。筆者は、画質の高さからLogicoolのC9xx系を利用することが多いです。状況によってはいわゆる手持ちのビデオカメラや産業用カメラなどを利用することもあります。これらは撮影環境に合わせて最適なレンズを選ぶことができる利点があります。
LogicoolのHD Pro Webカメラ C920のカメラ設定例を示します。自動設定は全て外し、フォーカスは無限大にします。ゲインは最小にして画面が暗いようであればできるだけ対象に当てるライトを追加します。露出も値を上げるとシャッター速度が落ちるので、これもできるだけ小さくしておきます。
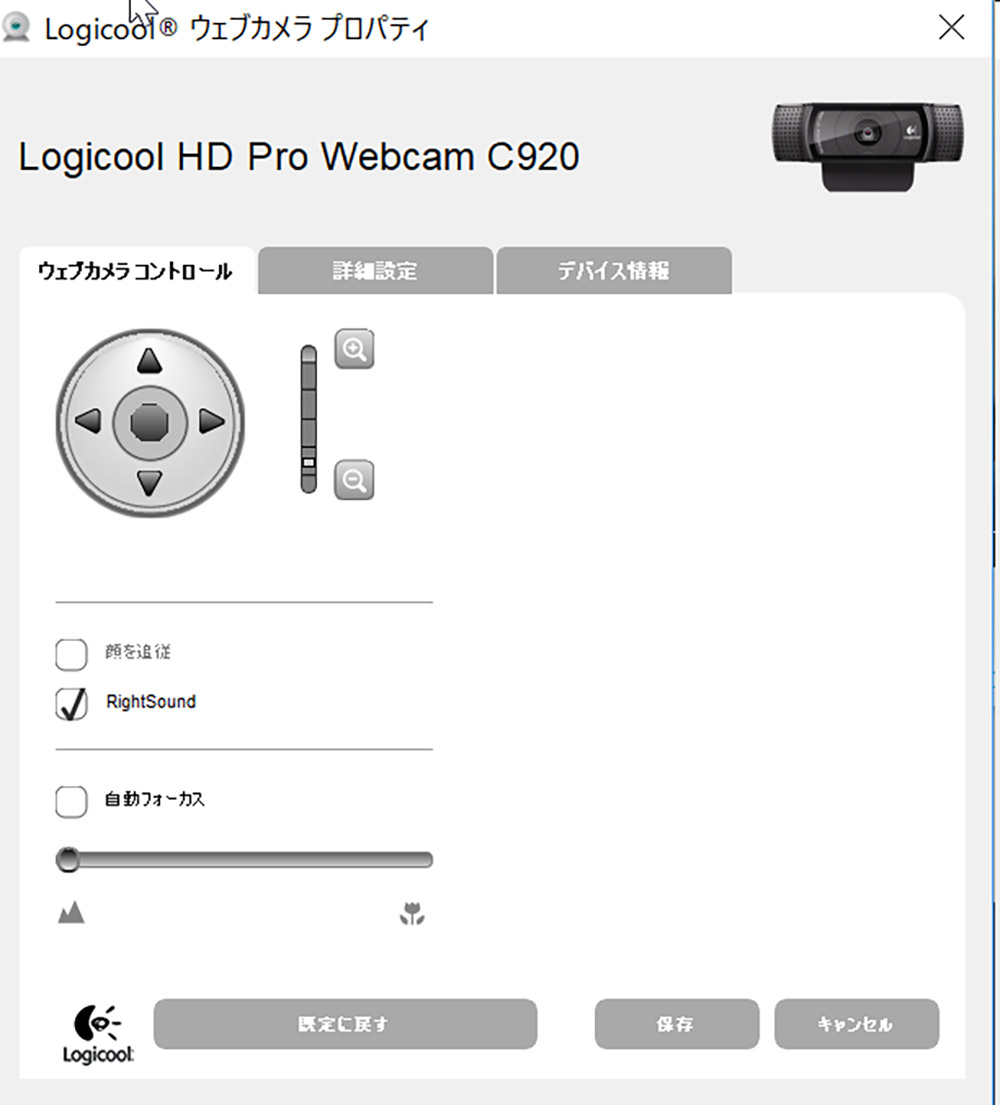

注意するべき点として、突然カメラの設定が飛んでしまうことがあるようです。ある朝PCを起動するとカメラの設定が全てデフォルトに戻っているという事態もままあります。これを回避するためには、コンテンツの方で、起動時にカメラの設定を行う処理を加えておくのが良いでしょう。
では、どこにその処理を付け加えるかというと、いま題材として扱っているプログラムではUnityのWebCamTextureでカメラ画像の取得を行なっていますが、このクラスにフォーカスや露出を設定する機能はありません。Windowsではカメラの値を書き込むために、「videoInput」というフリーのライブラリが使われることが多いようです。これを使って、カメラに値を書き込むプログラムを作成するか、UnityのAVPro Live Cameraアセットを利用するのが良いと思います。以下のようにカメラパラメータをプログラムから変更することができるのと、パフォーマンスの向上が期待できます。
しかし、これも完璧ではないように感じています。安定した運用が必要な場合は産業用やプロ用機材の導入を検討してください。AJAの「U-TAP」やepiphanの「AV.io HD」といったUSBキャプチャカードが1つあると、様々なカメラの出力をUSBカメラとして受けられるので便利です。
●照明の設定照明を調整できる場合は、できるだけ顔にフラットに光が当たるようにしてみてください。十分な照明が確保できると、シャッター速度を上げることができるようになるので顔の動きに対する追従性が上がります。またカメラのゲインを上げる必要がなくなるので画像のノイズが減ります。これらは設置場所によって調整する必要があり、インタラクティブコンテンツの設置では必ず悩むところです。
●ノイズの除去次に検出データのノイズを除去します。今回の処理では前後フレームでの検出位置が大きく移動しすぎた場合の対処だけで十分です。「ノイズ除去」で調べると移動平均、最小二乗法、カルマンフィルタなどのワードが出てくると思いますが、今回は非常にシンプルなローパスフィルタの1種でいきましょう。
p_cur = Vector2.Leap(p_cur, p_new, 0.8f);
p_cur 現在の位置
p_new 新しく検出された位置
0.8 線形補間でp_curとp_newを混ぜる割合
現在の位置と新しい位置を一定の重みでブレンディングするだけですが、十分な効果が得られます。値を小さくしすぎると動きがどんどん鈍くなります。
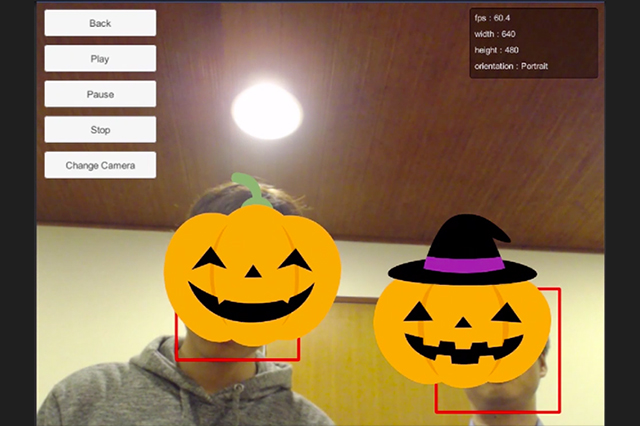
赤の枠はOpenCVが検出した生の領域を示しています。smoothの値を小さくしていくとお面のブレが収まっていることがわかると思います。
[[SplitPage]]<2>お面の複数表示に対応させる
1人しか認識できないと面白くないですよね。複数人に対応できるようにしていきましょう。処理としては2つ必要です。1つは、お面を複数出せるようにすること、もう1つは顔検出した位置に同じお面を表示し続けるようにすること。
1つずつ考えていきます。まず、表示できるお面の画像を増やしていきます。素材は前回と同じフリー素材配布サイト「Frame illust」の「[ハロウィン]カボチャランタン(ジャックランタン)のイラスト」から、前回とは別バージョンのイラストを使わせてもらいます。画像を保存して、jack2.png、jack3.pngとしてUnityのImageフォルダにインポートしましょう。
前回、FaceDetectionWebCamTextureExample .csに以下のように追記しましたね。
[SerializeField] private UnityEngine.UI.Image _mask;
これを配列に変更する必要があります(前回private指定を忘れていました)。3種類の画像を表示できるようにしたFaceDetectionWebCamTextureExample.csをGitHub Gistに置きましたので、このコードを使用してください。Unity Editorに戻るとMaskのパラメータが下画像のように変化しているはずです。
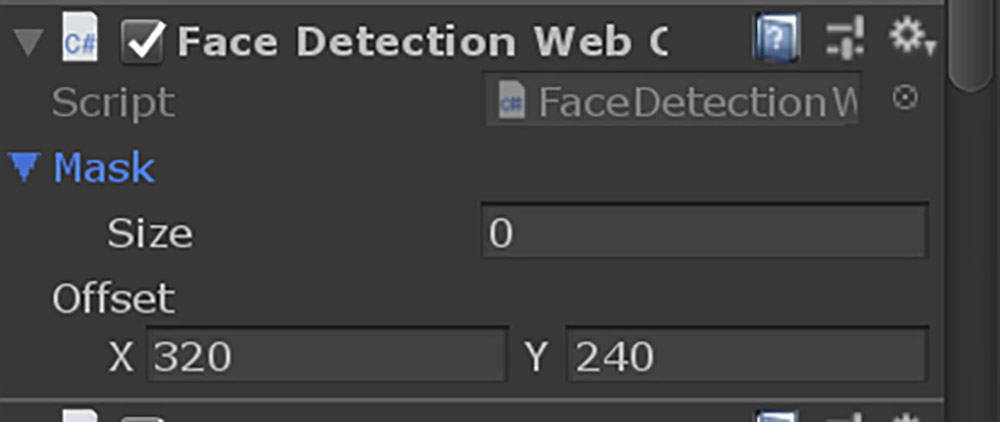
これはMaskが複数の画像を扱えるようになったことを示します。Sizeに3を指定してください。
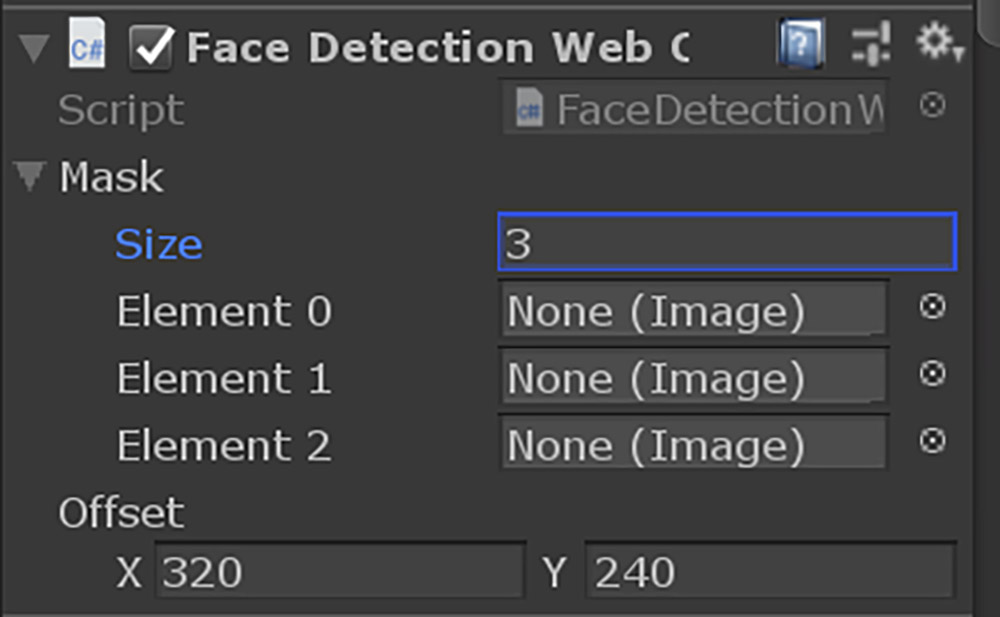
次にHierarchyに移動して、Maskを2つ複製してそれぞれMask2、Mask3と名前を付けます。
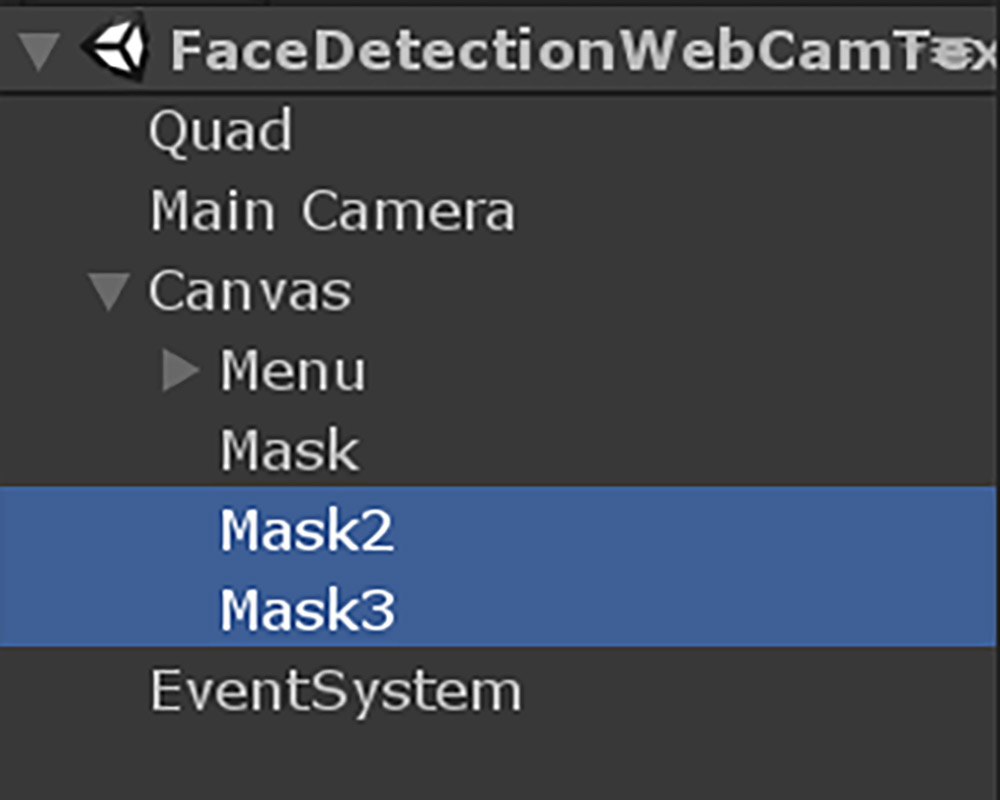
これまでの手順を全て行うと以下のような状態になります。
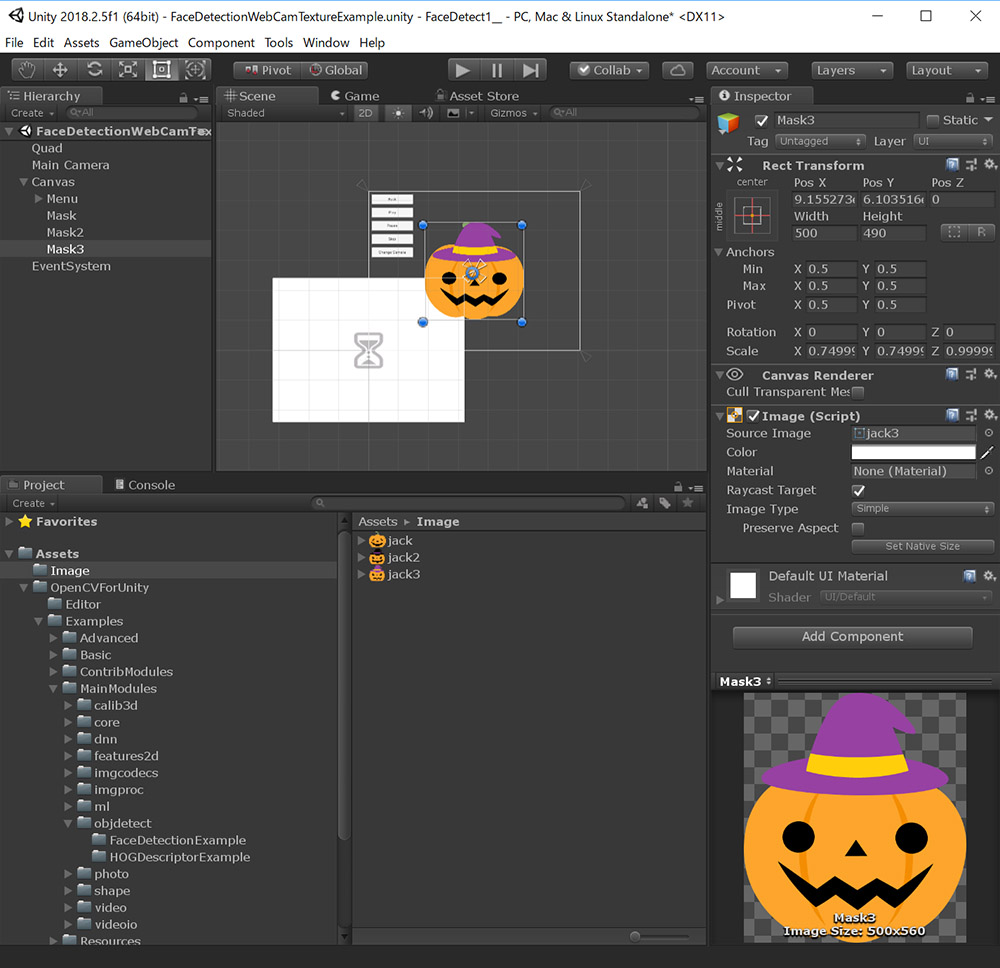
その後Quadゲームオブジェクトを選択し、Mask、Mask2、Mask3ゲームオブジェクトをそれぞれFace Detection Web Cam Texture ExampleコンポーネントのElement 0、Element 1、Element 2にアサインします。
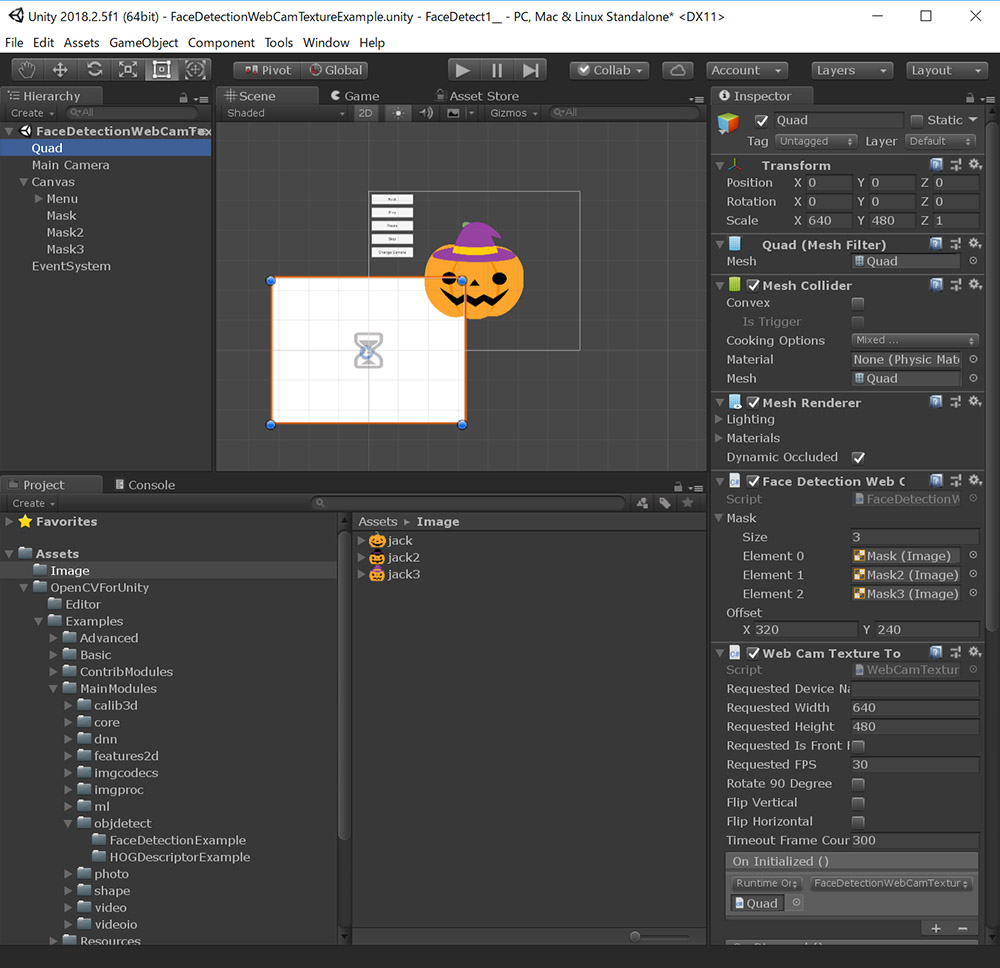
これで、Unityに3種類の画像を登録することができました。
<3>それぞれの顔をトラッキングする
2人以上で試すとすぐに気が付くと思いますが、頻繁にお面が入れ替わってしまうはずです。Aの人にはAのお面、Bの人にはBのお面をかぶせ続けたいですよね。これを行うためにはそれぞれの顔をトラッキングする必要があります。様々な方法がありますが、良いまとめがありましたので紹介します。
●Object Tracking using OpenCV
https://www.learnopencv.com/object-tracking-using-opencv-cpp-python/
このサイトにも書いてありますが、顔検出をする場合は画像ベースでのトラッキングを行う必要はあまりありません。前フレームでの検出位置と新しい検出位置を比べて、最も近い者同士が対応すると考えるのが妥当そうです。
処理のながれとしては以下のようになります。
1:OpenCVで顔検出を行う
2:トラッキング可能な数だけ検出点を割り当て、トラッキング状態にする
3:トラッキングされている位置から最も近い検出点を新しい位置とみなす
4:トラッキングされている位置の周りに新たな検出点がなければトラッキングをやめる
5:上記をループする
上記の処理をざっとコードにしたものをGitHub Gistに置きましたので、実行してみてください。下記のような結果になれば成功です。
これでお面コンテンツの基本はできました。次回はこのコードの簡単な解説と、JIDO-RHYTHMのようなコンテンツをつくるには何が必要かを考えていきたいと思います。
Profile.
高田稔則/Toshinori Takata(Codelight)Codelight株式会社 代表取締役・インタラクションエンジニア
フリーランス、株式会社TBSテレビ等で映画CG制作、株式会社ソニー・コンピュータエンタテインメント(現 ソニー・インタラクティブエンタテインメント)でPS4のOSD開発などを経て2006年にCodelight株式会社を設立。インタラクティブコンテンツの制作を中核として、製造業向けのプロトタイプ開発なども行う
www.codelight.co.jp













